LLMs之LCM:《MemLong: Memory-Augmented Retrieval for Long Text Modeling》翻译与解读
导读:MemLong 是一种新颖高效的解决 LLM 长文本处理难题的方法,它通过外部检索器获取历史信息,并将其与模型的内部检索过程相结合,从而有效地扩展了上下文窗口,提升了模型的性能。MemLong 具有分布一致性、训练高效、扩展上下文窗口等优势,为 LLM 处理长文本提供了新的思路和解决方案。该方案通过结合记忆和检索机制,不仅解决了长文本生成中的瓶颈问题,还在不损失原有模型能力的情况下,实现了更长的上下文处理能力。
>> 背景痛点:
大语言模型 (LLM) 在处理长文本时面临巨大挑战,主要原因是:
● 传统注意力机制的时间和空间复杂度为平方级,生成过程中键值缓存的内存消耗不断增加,导致内存消耗大。
● 长文本生成任务,如长文档摘要和多轮对话,要求模型具备长上下文处理能力。现有解决方案存在不足:
● 稀疏注意力机制会牺牲模型能力
● 基于 token 级别的记忆选择会导致语义信息的截断
● 检索增强语言模型存在分布偏移、需要重新训练、处理长文本会损害模型原始能力等问题
>> 解决方案:
MemLong:一种高效轻量级的长文本建模方法,通过外部检索器获取历史信息来增强 LLM 的长文本处理能力。MemLong 利用外部检索器进行历史信息的检索,将其组合到模型中。MemLong 主要包含两个部分:使用一个非可微的ret-mem模块结合部分可训练的解码器。引入细粒度可控的检索注意力机制,利用语义相关的文本块。
● Ret-Mem 模块:用于记忆和检索历史信息
● 部分可训练的解码器语言模型:用于整合检索信息
>> 核心思路步骤:将超过模型处理长度的文本存储为上下文信息。使用检索器从记忆库中检索过去的信息,以获取额外的上下文。在生成过程中,结合局部和记忆信息进行语言建模。
(1)、构建记忆库: 将历史文本块存储在非可训练的记忆库中,并将其编码为键值对和表示嵌入。
(2)、检索相关信息: 使用检索器根据当前输入文本块的表示嵌入,从记忆库中检索出最相关的键值对。
(3)、融合检索信息: 在模型的上层,将检索到的键值对与当前输入上下文进行融合,并微调模型参数以校准检索偏好。
(4)、动态记忆更新: 当记忆库溢出时,根据检索频率对记忆库进行动态更新,保留更频繁使用的信息,删除不太相关的条目。
>> 优势:
● 分布一致性: 记忆库中的信息分布保持一致,避免了模型训练过程中分布偏移问题。
● 训练高效: 冻结模型的下层,只需微调模型的上层,大幅降低了计算成本。
● 扩展上下文窗口: 由于只存储一层模型的键值对,在单个3090 GPU上,MemLong 可以轻松将上下文窗口扩展到 80k 个 token。
● 性能提升: MemLong 在多个长文本建模基准测试中表现优于其他最先进的 LLM,尤其是在检索增强上下文学习任务中,性能提升高达 10.2 个百分点。
● 高效利用资源:存储效率高,避免OOM问题,具备更强的泛化能力。
目录
《MemLong: Memory-Augmented Retrieval for Long Text Modeling》翻译与解读
Abstract
1 Introduction
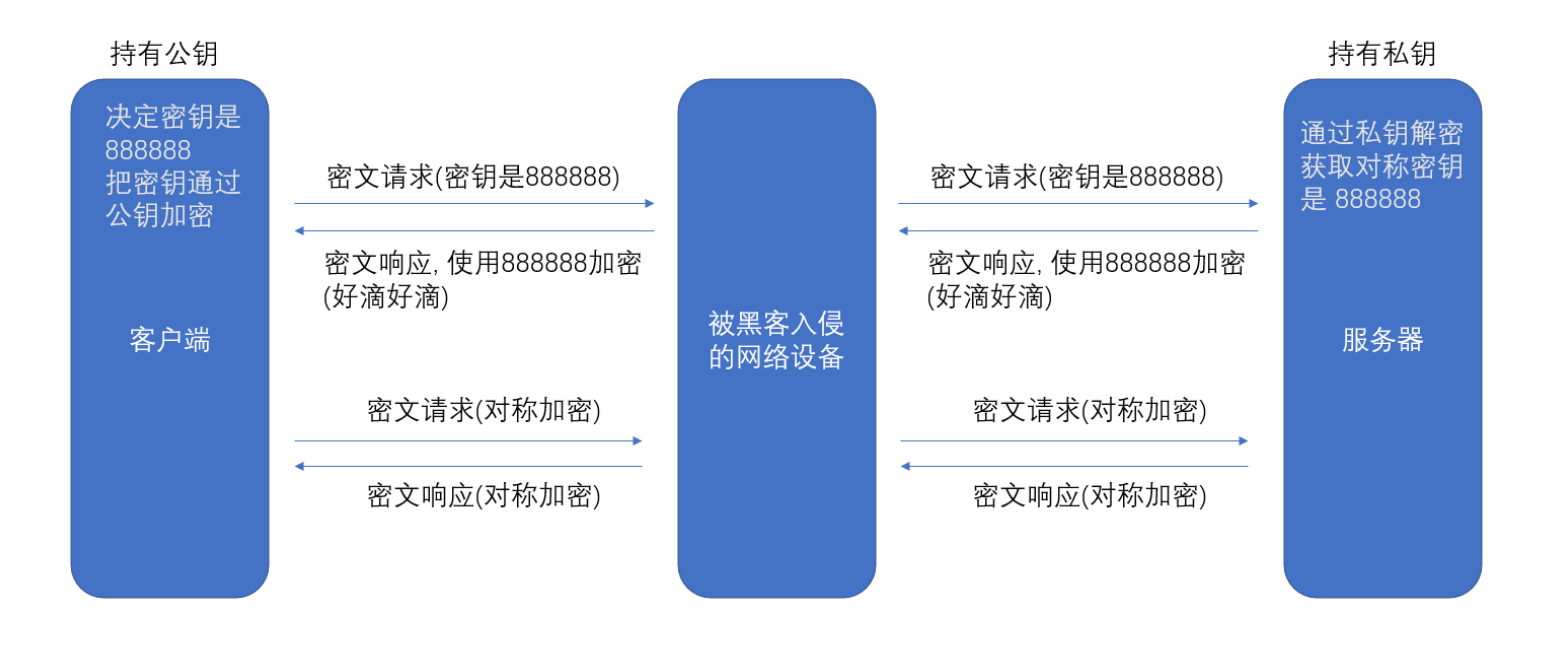
Figure 1: Illustration of Retrieval-Augment Genera-tion(RAG) and Memory-Retrieval flow of MemLong.(a) RAG can even degrade the generation performance (yellow) when the length of the retrieved information exceeds the model’s processing capacity. (b) Our ap-proach utilizes an external retriever to fetch historical information, which is then passed into the model as K-V pairs rather than in text form.图1:检索增强生成(RAG)与MemLong的记忆-检索流程的示意图。(a) 当检索到的信息长度超过模型处理能力时,RAG甚至可能会降低生成性能(黄色部分表示)。(b) 我们的方法利用外部检索器来获取历史信息,然后将这些信息以键值对(K-V pairs)的形式而非文本形式传递给模型。
7 Conclusion
《MemLong: Memory-Augmented Retrieval for Long Text Modeling》翻译与解读
| 地址 | 论文地址:https://arxiv.org/pdf/2408.16967 |
| 时间 | 2024 年8月30 |
| 作者 | 苏州大学、哈尔滨工业大学 |
Abstract
| Recent advancements in Large Language Models (LLMs) have yielded remarkable success across diverse fields. However, handling long contexts remains a significant challenge for LLMs due to the quadratic time and space complexity of attention mechanisms and the growing memory consumption of the key-value cache during generation. This work introduces MemLong: Memory-Augmented Retrieval for Long Text Generation, a method designed to enhance the capabilities of long-context language modeling by utilizing an external retriever for historical information retrieval. MemLong combines a non-differentiable ``ret-mem'' module with a partially trainable decoder-only language model and introduces a fine-grained, controllable retrieval attention mechanism that leverages semantic-level relevant chunks. Comprehensive evaluations on multiple long-context language modeling benchmarks demonstrate that MemLong consistently outperforms other state-of-the-art LLMs. More importantly, MemLong can extend the context length on a single 3090 GPU from 4k up to 80k. Our code is available at this https URL | 近期,大型语言模型(LLMs)在各个领域取得了显著的成功。然而,由于注意力机制的二次时间和空间复杂性以及生成过程中键值缓存不断增长的内存消耗,处理长上下文对LLMs来说仍然是一个重大挑战。本文介绍了MemLong:一种用于长文本生成的记忆增强检索方法,该方法通过利用外部检索器来检索历史信息,旨在提高长上下文语言建模的能力。MemLong结合了一个不可微分的“ret-mem”模块与部分可训练的仅解码器语言模型,并引入了一种细粒度、可控的检索注意力机制,利用语义级别的相关片段。通过对多个长上下文语言建模基准的全面评估表明,MemLong在性能上持续优于其他最先进的LLMs。更重要的是,MemLong可以在单个3090 GPU上将上下文长度从4k扩展到80k。 我们的代码可在该链接获取。 |
1 Introduction
| Large Language Models (LLMs) have achieved re-markable success in various fields. However, due to the quadratic time and space complexity of vanilla attention mechanisms (Vaswani et al., 2017), it is challenging to extend the context length consider-ably, which poses significant limitations for applica-tions involving long-sequence tasks, such as long-document summarization (Koh et al., 2022) and multiple rounds of dialogue (Wang et al., 2024a). As a result, LLMs are often expected to maintain a long working capability (a.k.a. long context LLMs) to effectively handle these demanding scenarios. To tackle the computational bottleneck, numer-ous efforts have been made. The first line of work focuses on reducing the computation of vanilla at-tention mechanisms (Vaswani et al., 2017) by em-ploying sparse attention operations (Beltagy et al., 2020; Wang et al., 2020; Kitaev et al., 2020; Xiao et al., 2023a; Chen et al., 2023b; Lu et al., 2024). Although these types of works can reduce com-putational complexity to approximately O(n), it often comes with trade-offs in model capability. Therefore, Some works shift their focus to mem-ory selection (Dai et al., 2019; Bertsch et al., 2024; Yu et al., 2023). These approaches, as token-level memory selection, can result in the truncation of se-mantic information. Another recent line of work is Retrieval-Augment Language Modeling (Wu et al., 2022; Wang et al., 2024b; Rubin and Berant, 2023). These works usually introduce a retrieval mecha-nism to enhance the model’s ability to handle long texts. However, these methods have several draw-backs. Firstly, the information stored in memory may experience distribution shifts due to changes in model parameters during training. Secondly, these methods often require retraining, which is im-practical in the era of large models. Finally, these models are often prone to processing long text in-puts at the expense of the original capabilities of the pre-trained model. To address the limitations of previous research, we posed the following ques-tion: Can we utilize the explicit retrieval capa-bilities of a retriever to approximate the implicit retrieval processes within the model? | 大型语言模型(LLMs)在各种领域取得了显著的成功。然而,由于基础注意力机制(Vaswani等人, 2017)的时间和空间复杂度为二次方,很难大幅延长上下文长度,这给涉及长序列任务的应用带来了重大限制,如长文档摘要(Koh等人, 2022)和多轮对话(Wang等人, 2024a)。因此,人们期望LLMs能够保持较长的工作能力(即所谓的长上下文LLMs),以有效应对这些需求场景。 为了克服计算瓶颈,已经做出了许多努力。第一类工作集中在通过使用稀疏注意力操作(Beltagy等人, 2020; Wang等人, 2020; Kitaev等人, 2020; Xiao等人, 2023a; Chen等人, 2023b; Lu等人, 2024)减少基础注意力机制(Vaswani等人, 2017)的计算量。尽管这类工作可以将计算复杂度降低至大约O(n),但它通常伴随着模型能力的折衷。因此,有些工作转向了记忆选择(Dai等人, 2019; Bertsch等人, 2024; Yu等人, 2023)。作为词元级记忆选择的方法可能会导致语义信息被截断。另一条近期的研究方向是检索增强的语言建模(Wu等人, 2022; Wang等人, 2024b; Rubin和Berant, 2023)。这些工作通常会引入一种检索机制来增强模型处理长文本的能力。但是,这些方法有几个缺点。首先,在训练过程中模型参数的变化可能导致存储在记忆中的信息经历分布偏移。其次,这些方法往往需要重新训练,在大模型时代这是不切实际的。最后,这些模型常常以牺牲预训练模型的原始能力为代价来处理长文本输入。为了解决先前研究的局限性,我们提出了以下问题:我们能否利用检索器的显式检索能力来近似模型内部的隐式检索过程? |
| In this work, we propose MemLong, an efficient and lightweight method to extending the context window of LLMs. The key idea is to store past contexts and knowledge in a non-trainable mem-ory bank and further leverages these stored em-beddings to retrieve chunk-level key-value (K-V) pairs for input into the model.. MemLong is ap-plicable to any decoder-only pretrained language models by incorporating (1) an additional ret-mem component for memory and retrieval, and (2) a retrieval causal attention module for integrating local and memory information. The memory and retrieval process of MemLong is illustrated in Fig-ure 1(b). During generation,one text that exceeds the model’s maximum processing length is stored as context information in a Memory Bank. Sub-sequently, given a recently generated text chunk in a long document, we use the retriever to explic-itly retrieve past information, obtaining additional context information through index alignment. | 在这项工作中,我们提出了一种高效且轻量级的方法MemLong,用以扩展LLMs的上下文窗口。其核心思想是在非训练的记忆库中存储过去的上下文和知识,并进一步利用这些存储的嵌入来检索块级键值(K-V)对以供模型输入。通过添加(1)额外的ret-mem组件用于记忆和检索,以及(2)一个检索因果注意模块来整合局部和记忆信息,MemLong适用于任何仅解码器的预训练语言模型。图1(b)展示了MemLong的记忆和检索过程。在生成过程中,超过模型最大处理长度的文本被作为上下文信息存储在记忆库中。随后,对于长文档中最近生成的文本段落,我们使用检索器明确地检索过去的信息,通过索引对齐获得额外的上下文信息。 |
| MemLong offers several benefits: (1) Distribu-tional Consistency: Unlike previous models that experienced a distribution shift when information was stored in memory, MemLong ensures the dis-tribution of cached information remains consistent.(2) Training Efficient: We freeze the lower layers of the model and only need to finetune the upper layers which greatly reduced computational cost. In our experiments, finetuning a 3B parameter ver-sion of MemLong on 0.5B tokens requires only eight 3090 GPUs for eight hours. (3) Extensive Context Window: Since only a single layer’s K-V pairs need to be memorized, MemLong is capable of extending the context window up to 80k tokens easily on a single 3090 GPU. Extensive experiments have demonstrated that MemLong exhibits superior performance in several aspects when compared with other leading LLMs. MemLong outperforms OpenLLaMA (Touvron et al., 2023) and other retrieval-based models on several long-context language modeling datasets. In retrieval-augmented in-context learning tasks, MemLong achieves an improvement of up to 10.2 percentage points over OpenLLaMA. | MemLong提供了几个优点:(1) 分布一致性:与以前在信息存储于记忆时经历分布偏移的模型不同,MemLong确保了缓存信息的分布保持一致。(2) 训练效率:我们冻结了模型的下层并只需要微调上层,这大大降低了计算成本。在实验中,只需八个3090 GPU八小时即可完成对具有30亿参数版本的MemLong进行0.5亿个标记的微调。(3) 广泛的上下文窗口:因为只需要记住单一层的K-V对,MemLong能够在单个3090 GPU上轻松将上下文窗口扩展至80k个标记。 广泛的实验表明,与其他领先的LLMs相比,MemLong在多个方面表现出优越的性能。在几个长上下文语言建模数据集上,MemLong的表现超过了OpenLLaMA(Touvron等人, 2023)和其他基于检索的模型。在检索增强的上下文学习任务中,MemLong相对于OpenLLaMA实现了高达10.2个百分点的改进。 |
Figure 1: Illustration of Retrieval-Augment Genera-tion(RAG) and Memory-Retrieval flow of MemLong.(a) RAG can even degrade the generation performance (yellow) when the length of the retrieved information exceeds the model’s processing capacity. (b) Our ap-proach utilizes an external retriever to fetch historical information, which is then passed into the model as K-V pairs rather than in text form.图1:检索增强生成(RAG)与MemLong的记忆-检索流程的示意图。(a) 当检索到的信息长度超过模型处理能力时,RAG甚至可能会降低生成性能(黄色部分表示)。(b) 我们的方法利用外部检索器来获取历史信息,然后将这些信息以键值对(K-V pairs)的形式而非文本形式传递给模型。

7 Conclusion
| We introduce MemLong, an innovative approach that significantly enhances the capability of lan-guage models to process long texts by leveraging an external retriever. MemLong utilizes a profi-cient retriever to swiftly and accurately access text relevant to the distant context with minimal mem-ory overhead. MemLong successfully expands the model’s context window from 2k to 80k tokens. We demonstrate that MemLong exhibits consider-able competitive advantages in long-distance text modeling and comprehension tasks. MemLong can achieve up to a 10.4 percentage point improvement in performance compared to the full-context model. | 我们介绍了一种创新的方法MemLong,它通过利用外部检索器显著增强了语言模型处理长文本的能力。MemLong使用高效的检索器快速准确地访问与远距离上下文相关的文本,同时最小化内存开销。MemLong成功地将模型的上下文窗口从2k扩展到了80k个标记。我们证明了MemLong在长距离文本建模和理解任务中展现出相当大的竞争优势。与全上下文模型相比,MemLong的性能最多可以提高10.4个百分点。 |