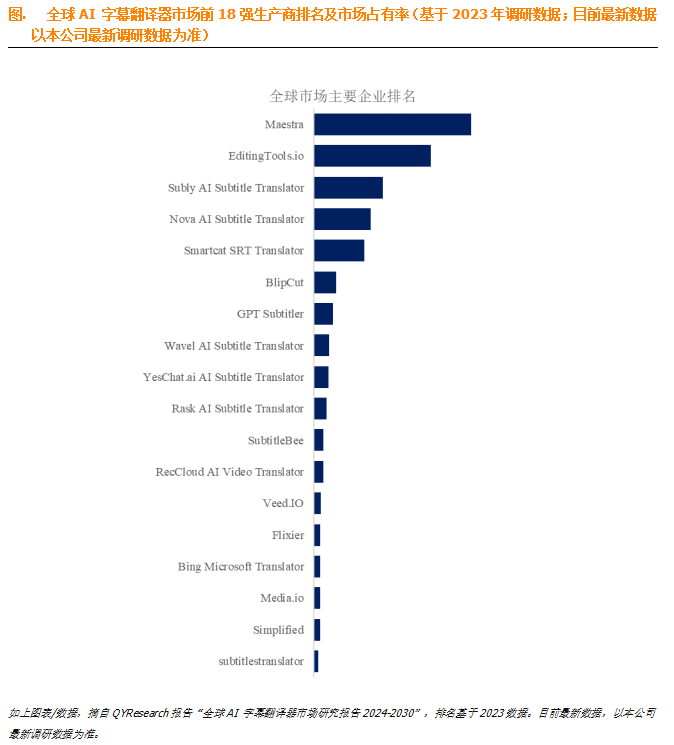
数据入口:数字营销转化数据集 - Heywhale.com
数据集记录了客户与数字营销活动的互动情况。它涵盖了人口统计数据、营销特定指标、客户参与度指标以及历史购买数据,为数字营销领域的预测建模和分析提供了丰富的信息。
数据说明:
| 字段 | 说明 |
|---|---|
| CustomerID | 每个客户的唯一标识符。 |
| Age | 客户的年龄。 |
| Gender | 客户的性别(男性/女性)。 |
| Income | 客户的年收入,以美元计。 |
| CampaignChannel | 营销活动传递的渠道:电子邮件(Email)、社交媒体(Social Media)、搜索引擎优化(SEO)、付费点击(PPC)、推荐(Referral))。 |
| CampaignType | 营销活动的类型:意识(Awareness)、考虑(Consideration)、转化(Conversion)、留存(Retention)。 |
| AdSpend | 在营销活动上的花费,以美元计。 |
| ClickThroughRate | 客户点击营销内容的比率。 |
| ConversionRate | 点击转化为期望行为(如购买)的比率。 |
| AdvertisingPlatform | 广告平台:保密。 |
| AdvertisingTool | 广告工具:保密。 |
| WebsiteVisits | 访问网站的总次数。 |
| PagesPerVisit | 每次会话平均访问的页面数。 |
| TimeOnSite | 每次访问平均在网站上花费的时间(分钟)。 |
| SocialShares | 营销内容在社交媒体上被分享的次数。 |
| EmailOpens | 营销电子邮件被打开的次数。 |
| EmailClicks | 营销电子邮件中链接被点击的次数。 |
| PreviousPurchases | 客户之前进行的购买次数。 |
| LoyaltyPoints | 客户累积的忠诚度积分数。 |
| Target Variable | 目标变量:二元变量,表示客户是否转化(1)或未转化(0)。 |
本文将通过支持向量机(SVM)分类进行客户转化预测,以及利用相关性分析进行关键因素识别。
一:客户转化预测
import pandas as pd
file_path = 'digital_marketing_campaign_dataset (1).csv'
data = pd.read_csv(file_path)
data.info()
观察到数据集中没有缺失值,随后进行标签编码和建立支持向量机分类模型:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from imblearn.over_sampling import RandomOverSampler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc
import matplotlib.pyplot as plt
from sklearn import metrics
new_data = data.drop(['CustomerID', 'Age', 'Gender', 'Income', 'SocialShares', 'AdvertisingPlatform', 'AdvertisingTool'], axis=1)
label_encoder = LabelEncoder()
new_data['CampaignType_encoded'] = label_encoder.fit_transform(new_data['CampaignType'])
label_encoder = LabelEncoder()
new_data['CampaignChannel_encoded'] = label_encoder.fit_transform(new_data['CampaignChannel'])
new_data = new_data.drop(['CampaignType', 'CampaignChannel'], axis=1)
x = new_data.drop(['Conversion'], axis=1)
y = new_data['Conversion']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=15)
oversampler = RandomOverSampler()
x_train, y_train = oversampler.fit_resample(x_train, y_train)
svm_clf = SVC(random_state=15, probability=True)
svm_clf.fit(x_train, y_train)
y_pred_svm = svm_clf.predict(x_test)
class_report_svm = classification_report(y_test, y_pred_svm)
print(class_report_svm)
y_pred_proba_svm = svm_clf.predict_proba(x_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba_svm)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='SVM (AUC = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()
conf_matrix_svm = confusion_matrix(y_test, y_pred_svm)
print("Confusion Matrix for SVM:")
print(conf_matrix_svm)

可以看出模型的预测效果和准确率较好,可以通过该模型去识别一个用户是否转化。
这段代码是一个使用Python的scikit-learn库进行监督学习的示例,具体来说,它使用了支持向量机(SVM)分类器来预测某些数据集中的目标变量。以下是代码的具体解释:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from imblearn.over_sampling import RandomOverSampler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix, roc_curve, auc
import matplotlib.pyplot as plt
from sklearn import metrics
- 导入必要的库。包括模型选择、数据预处理、过采样技术、SVM分类器、性能评估指标、绘图工具以及额外的scikit-learn工具。
new_data = data.drop(['CustomerID', 'Age', 'Gender', 'Income', 'SocialShares', 'AdvertisingPlatform', 'AdvertisingTool'], axis=1)
- 从原始数据集
data中删除一些列,这些列可能是通过axis=1参数指定的。剩下的数据存储在new_data中。
label_encoder = LabelEncoder()
new_data['CampaignType_encoded'] = label_encoder.fit_transform(new_data['CampaignType'])
label_encoder = LabelEncoder()
new_data['CampaignChannel_encoded'] = label_encoder.fit_transform(new_data['CampaignChannel'])
new_data = new_data.drop(['CampaignType', 'CampaignChannel'], axis=1)
- 创建
LabelEncoder对象,用于将非数值的类别标签编码为整数。这里它被用来转换CampaignType列和CampaignChannel列的数据。
x = new_data.drop(['Conversion'], axis=1)
y = new_data['Conversion']
- 将数据分为特征(
x)和目标变量(y)。特征是除去Conversion列的所有列,而目标变量是Conversion列。
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=15)
- 将数据集分为训练集和测试集,其中测试集占总数据的30%,
random_state参数用于确保可重复性。
oversampler = RandomOverSampler()
x_train, y_train = oversampler.fit_resample(x_train, y_train)
- 使用
RandomOverSampler来处理训练集中的类别不平衡问题。它会通过随机过采样少数类别来平衡类别分布。
svm_clf = SVC(random_state=15, probability=True)
svm_clf.fit(x_train, y_train)
- 创建一个SVM分类器实例,设置
random_state以确保结果的可重复性,并启用概率估计(probability=True)。然后使用训练数据来训练分类器。
y_pred_svm = svm_clf.predict(x_test)
- 使用训练好的SVM分类器对测试集的特征进行预测。
class_report_svm = classification_report(y_test, y_pred_svm)
print(class_report_svm)
- 计算并打印分类报告,它提供了精确度、召回率、F1分数等性能指标。
y_pred_proba_svm = svm_clf.predict_proba(x_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba_svm)
roc_auc = auc(fpr, tpr)
- 获取测试集的预测概率,并使用这些概率来计算接收者操作特性(ROC)曲线的假阳性率(FPR)和真阳性率(TPR)。同时计算曲线下面积(AUC)。
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='SVM (AUC = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()
- 使用matplotlib绘制ROC曲线,并显示AUC值。
conf_matrix_svm = confusion_matrix(y_test, y_pred_svm)
print("Confusion Matrix for SVM:")
print(conf_matrix_svm)
- 计算并打印混淆矩阵,它显示了模型在测试集上的分类性能,包括真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。
二:渠道与活动分析
我们需要根据y'CampaignChannel'和'ConversionRate'两列来进行渠道与活动分析。为了评估不同营销渠道和活动类型对客户转化的影响,我们可以进行以下分析:
- 分析各个营销渠道(如Social Media、Email、PPC等)的客户转化率。
- 分析不同活动类型(如Awareness、Retention、Conversion等)的客户转化率。
让我们首先分析各个营销渠道的客户转化率。
df = data
campaign_channel_conversion = df.groupby('CampaignChannel')['ConversionRate'].mean().reset_index()
campaign_channel_conversion = campaign_channel_conversion.sort_values(by='ConversionRate', ascending=False)
campaign_channel_conversion根据营销渠道的客户转化率分析结果,我们可以看到:
- Social Media 的客户转化率最高,为 10.655%。
- Email 的客户转化率为 10.488%。
- PPC (Pay-Per-Click) 的客户转化率为 10.413%。
- SEO (Search Engine Optimization) 的客户转化率为 10.353%。
- Referral 的客户转化率为 10.305%。
接下来,我们可以分析不同活动类型的客户转化率。
campaign_type_conversion = df.groupby('CampaignType')['ConversionRate'].mean().reset_index()
campaign_type_conversion = campaign_type_conversion.sort_values(by='ConversionRate', ascending=False)
campaign_type_conversion根据不同活动类型的客户转化率分析结果,我们可以看到:
- Consideration 的客户转化率最高,为 10.507%。
- Conversion 的客户转化率为 10.486%。
- Awareness 的客户转化率为 10.437%。
- Retention 的客户转化率为 10.321%。
这些结果表明,不同的营销渠道和活动类型对客户转化率有显著影响。例如,Social Media渠道的转化率最高,而Consideration类型的活动转化率最高。
三:关键因素识别
为了确定哪些因素最能促进客户的参与度和转化率,我们可以使用统计方法(如相关性分析或回归分析)来分析这些因素与参与度和转化率之间的关系。
首先,我们可以进行相关性分析,以查看这些因素与客户转化率之间的相关性,在进行相关性分析时,由于数据中既含有数值变量也含有分类变量,为了解决这个问题,我们可以采取以下步骤:
- 对于分类变量(如
CampaignChannel和CampaignType),我们可以使用虚拟变量(或独热编码)来表示它们。- 对于其他数值型变量,我们可以直接使用它们进行相关性分析。
让我们首先对分类变量进行虚拟变量编码,然后进行相关性分析。
relevant_columns = [
'CampaignChannel', 'CampaignType', 'AdSpend', 'ClickThroughRate',
'WebsiteVisits', 'PagesPerVisit', 'TimeOnSite', 'SocialShares',
'EmailOpens', 'EmailClicks', 'PreviousPurchases', 'LoyaltyPoints'
]
df_encoded = pd.get_dummies(df, columns=['CampaignChannel', 'CampaignType'], drop_first=True)
relevant_columns_encoded = [
col for col in df_encoded.columns if col in relevant_columns or col.startswith('CampaignChannel') or col.startswith('CampaignType')
]
correlation_matrix_encoded = df_encoded[relevant_columns_encoded + ['ConversionRate']].corr()
correlation_matrix_encoded['ConversionRate']
根据相关性分析的结果,我们可以看到以下因素与客户转化率的相关性:
- AdSpend (广告支出):与转化率呈轻微的负相关(-0.02),这意味着广告支出越高,转化率并不一定越高。
- ClickThroughRate (点击率):与转化率呈轻微的负相关(-0.008),这可能表明高点击率并不总是导致高转化率。
- WebsiteVisits (网站访问量):与转化率呈轻微的负相关(-0.0121),这意味着网站访问量越高,转化率并不一定越高。
- PagesPerVisit (页面浏览量):与转化率呈轻微的正相关(0.0188),这可能表明客户在网站上浏览的页面越多,他们转化的可能性越高。
- TimeOnSite (网站停留时间):与转化率呈轻微的正相关(0.0087),这可能表明客户在网站上停留的时间越长,他们转化的可能性越高。
- SocialShares (社交媒体分享):与转化率呈轻微的正相关(0.0087),这可能表明社交媒体上的分享有助于提高转化率。
- EmailOpens (电子邮件开启次数) 和 EmailClicks (电子邮件点击次数):与转化率呈轻微的正相关,这可能表明电子邮件营销对提高转化率有一定的积极影响。
- PreviousPurchases (之前的购买次数):与转化率呈轻微的负相关(-0.0232),这可能表明之前的购买次数并不总是直接导致更高的转化率。
- LoyaltyPoints (忠诚度积分):与转化率的相关性非常小(-0.0005),这可能表明忠诚度积分对转化率的影响不大。
- CampaignChannel (营销渠道) 和 CampaignType (活动类型):不同渠道和活动类型与转化率的相关性各不相同,其中Social Media渠道和Consideration类型的活动与转化率呈轻微的正相关。
此外,上述相关性值的大小表明这些因素与转化率之间的关联性普遍较弱。
想要探索多元化的数据分析视角,可以关注之前发布的相关内容。