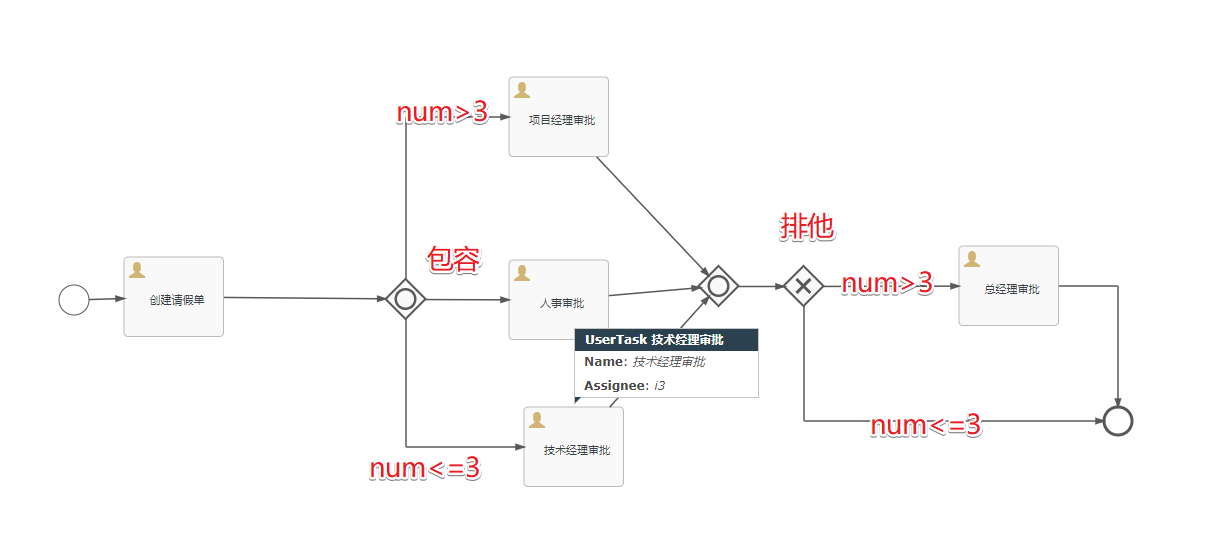
代码功能
主要功能:
加载数据集:
代码使用 load_iris() 函数加载了鸢尾花数据集(Iris dataset)。这个数据集包含 150 条样本,每条样本有 4 个特征,对应于 3 种不同的鸢尾花。
KMeans 聚类:
使用 KMeans 聚类算法将样本数据分为 3 个聚类(即3类),尝试发现数据中的自然分组,而不使用标签。
KMeans 将根据数据特征进行迭代计算,最终找到每个类的聚类中心,并为每个数据点分配一个类标签。
PCA 降维:
由于数据集有 4 个特征,不便于可视化,代码使用 PCA(主成分分析)将数据降维至 2 维。这样我们可以在二维平面上更直观地展示聚类结果。
可视化:
使用 Matplotlib 库绘制聚类结果。代码将每个数据点根据其聚类标签着色,并用红色标记聚类中心的位置。
主要步骤:
KMeans 聚类:根据数据的分布,寻找数据的三个聚类中心。
降维可视化:将数据从高维降到二维,便于展示。
绘制图形:用不同颜色表示不同类的数据点,红色圆圈代表聚类中心。

代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
# 加载鸢尾花数据集
iris = load_iris()
data = iris.data
# 创建KMeans模型,设定聚类为3类(对应于鸢尾花的3个品种),并显式设置n_init参数
kmeans = KMeans(n_clusters=3, n_init=10, random_state=42)
# 训练模型并进行聚类
kmeans.fit(data)
# 获取聚类结果
labels = kmeans.labels_
centers = kmeans.cluster_centers_
# 使用PCA将数据降维至2维进行可视化
pca = PCA(n_components=2)
data_2d = pca.fit_transform(data)
# 绘制聚类结果
plt.scatter(data_2d[:, 0], data_2d[:, 1], c=labels, cmap='viridis', label="Data points")
plt.scatter(pca.transform(centers)[:, 0], pca.transform(centers)[:, 1], s=300, c='red', label="Cluster centers")
plt.title('KMeans Clustering on Iris Dataset')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.legend()
plt.show()