引言
一觉睡西天,谁知梦里乾坤大。只身眠净土,只道其中日月长。

小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖铁观音的小男孩。今天这篇小作文主要介绍这几天网上狂吹的开源新晋王者Reflection 70B,该模型号称在多个基准测试中超越GPT-4o和Llama 3.1。
模型下载:https://huggingface.co/mattshumer/Reflection-Llama-3.1-70B
核心
Reflection 70B,其实是一种反思型的 Llama-3.1 70B。它采用了一种名为反思微调(Reflection-Tuning )的技术进行训练,该技术教会 LLM 检测其推理中的错误并给予纠正。使用Reflection-Tuning技术,使得模型能够在最终确定回复之前,先检测自身推理的错误并纠正。但是,关于该技术,以当下的眼光看,都感觉平平无奇,比如在2023年就有一篇名为Reflection-Tuning:Data Recycling Improves LLM Instruction-Tuning的文章。或者在模型推理阶段,使用各种奇技淫巧的Prompt工程,兴许也可以获取差不多的效果。
此外,Reflection 70B使用的训练数据来自于 Glaive 合成的数据。Reflection 70B官方也借此机会安利了Glaive公司,想必Glaive确实可以提供高质量的数据。据了解,Glaive公司去年获得了一轮350万美元的种子轮融资,曾以高质量、任务特定数据帮助一些小型模型取得过成功。
模型说明
Reflection 70B基于 Llama 3.1 70B Instruct 训练而来,因此可以使用与任何其他 Llama 模型相同的代码、pipeline等来使用反思型 Llama-3.1 70B(即Reflection 70B) 。Reflection 70B使用标准的 Llama 3.1 聊天模板格式,但是训练了一些新的特殊token来辅助推理和反思。
在采样过程中,模型将首先在<thinking> 和 </thinking> token内输出推理,然后一旦对推理满意,它将在<output>和</output> token内输出最终答案。这些token都是经过训练的特殊标记。这使得模型能够将内部思考和推理与最终答案分开,从而改善用户体验。
在<thinking>部分内,模型可能会输出一个或多个<reflection> 标签,这表示模型发现了推理中的错误,并将在提供最终答案之前尝试纠正它。
System Prompt
用于训练该模型的系统提示是:
You are a world-class AI system, capable of complex reasoning and reflection. Reason through the query inside <thinking> tags, and then provide your final response inside <output> tags. If you detect that you made a mistake in your reasoning at any point, correct yourself inside <reflection> tags.
官方建议使用这个完全相同的系统提示来从反思型 Llama-3.1 70B 获得最佳结果。用户也可以尝试将此系统提示与自己自定义指令结合使用,以定制模型的行为。
Chat Format
如上所述,该模型使用标准的 Llama 3.1 聊天格式。以下是一个示例:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a world-class AI system, capable of complex reasoning and reflection. Reason through the query inside <thinking> tags, and then provide your final response inside <output> tags. If you detect that you made a mistake in your reasoning at any point, correct yourself inside <reflection> tags.<|eot_id|><|start_header_id|>user<|end_header_id|>
what is 2+2?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
另外,官方建议温度设置为 0.7,top_p 设置为 0.95。
Benchmarks结果
所有测试的基准都已通过运行 LMSys 的 LLM 去污染器进行了污染检查。在基准测试时,只对<output>部分进行隔离并基准测试。
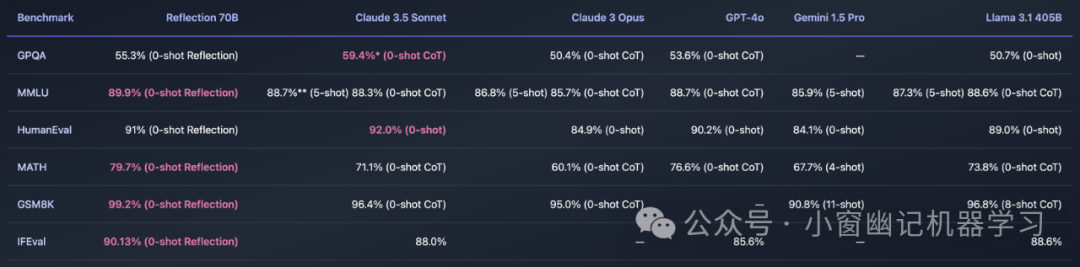
Reflection 70B 在 GSM8K 数学推理测试中,它取得了99.2%的惊人成绩,这个分数已经接近人类专家的水平。需要注意的是,GSM8K 测试集中可能存在超过1%的错误答案,这意味着 Reflection 70B 的表现几乎完美无缺。不仅如此,在 MMLU、MATH、IFEval 等多个权威基准测试中, Reflection 70B 都全面超越了 GPT-4o、Claude 3 Opus、Gemini 1.5 Pro 等顶级商业模型,以及 Llama 3.1 405B 等强大的开源模型。所以,单纯从榜单看,Reflection 70B确实挺能打的!既然这么能打,以下我们进行简单实测。
实测
以下本着公平、公正的原则,从数学角度对GPT-4o、Reflection 70B进行测试。主要的case:
"蔡坤在踩缝纫机",一共多少个字?请用中文回答。
"我是中国人,想考公务员",一共多少个字?请用中文回答。
先看看Reflection 70B的表现:


再看看GPT4o的表现:

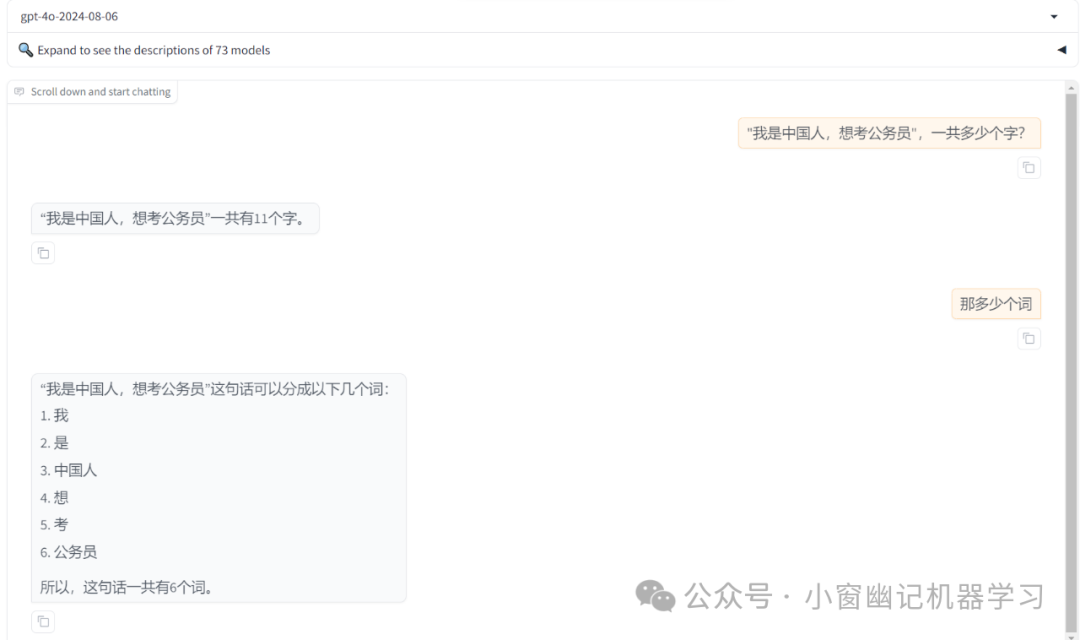
综上,简单测试,Reflection 70B在部分case上效果确实不错,但是在一个case翻车明显,存在装模作样,一本正经假装反思。因为,即使引入反思微调,其实还是难以避免幻觉,体现在这里就是反思幻觉。那么如何在反思阶段,避免幻觉?