最近新入手了一台 arm 开发板,希望打造一款有温度、有情怀的陪伴式 AI 对话机器人。
大体实现思路如下:
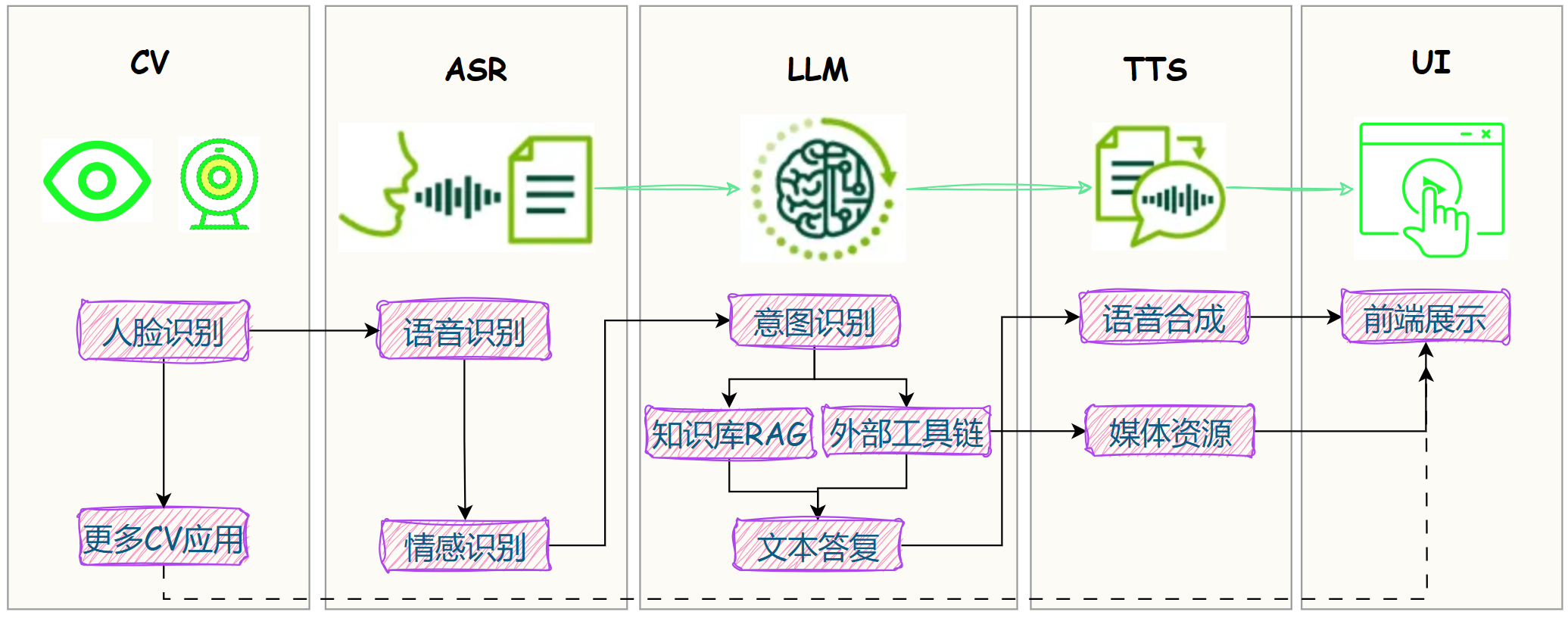
前几篇,给板子装上LLM 大脑、耳朵和嘴巴装上:
- 如何在手机端部署大模型?
- 手机端跑大模型:Ollma/llama.cpp/vLLM 实测对比
- AIoT应用开发:给板子装上’耳朵’,实现实时音频录制
- AIoT应用开发:给板子装上’嘴巴’,实现音频播放
昨天,成功实现三者串联:
- AIoT应用开发:搞定语音对话机器人=ASR+LLM+TTS
还缺啥?
我们希望它不仅能听会道,还能眼观八方!
对应到设备上:
耳朵== 麦克风;大脑== 大语言模型;嘴巴== 扬声器;眼睛== 摄像头;

今日分享,带大家实操:如何给板子接入 AI 视觉能力(CV),实现人脸识别,机器人终于可以知道在和谁聊天了。
有小伙伴问:没有 arm 开发板怎么办?准备一台 Android 手机就行。
友情提醒:本文实操,请确保已在手机端准备好 Linux 环境,具体参考教程:如何在手机端部署大模型?
1. 开发板简介
最近一直在更新AIoT应用开发的文章,很多小伙伴问:用的什么开发板?
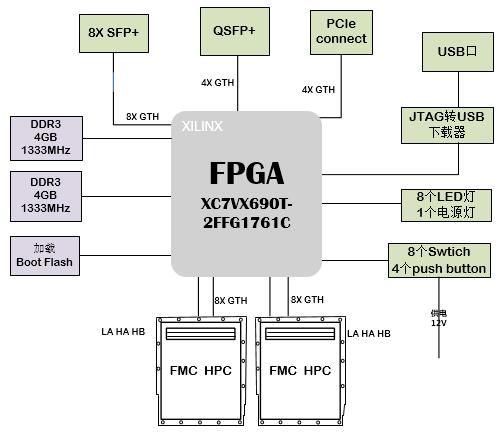
具体型号不说了,以免有打广告的嫌疑,给大家看下配置参数:
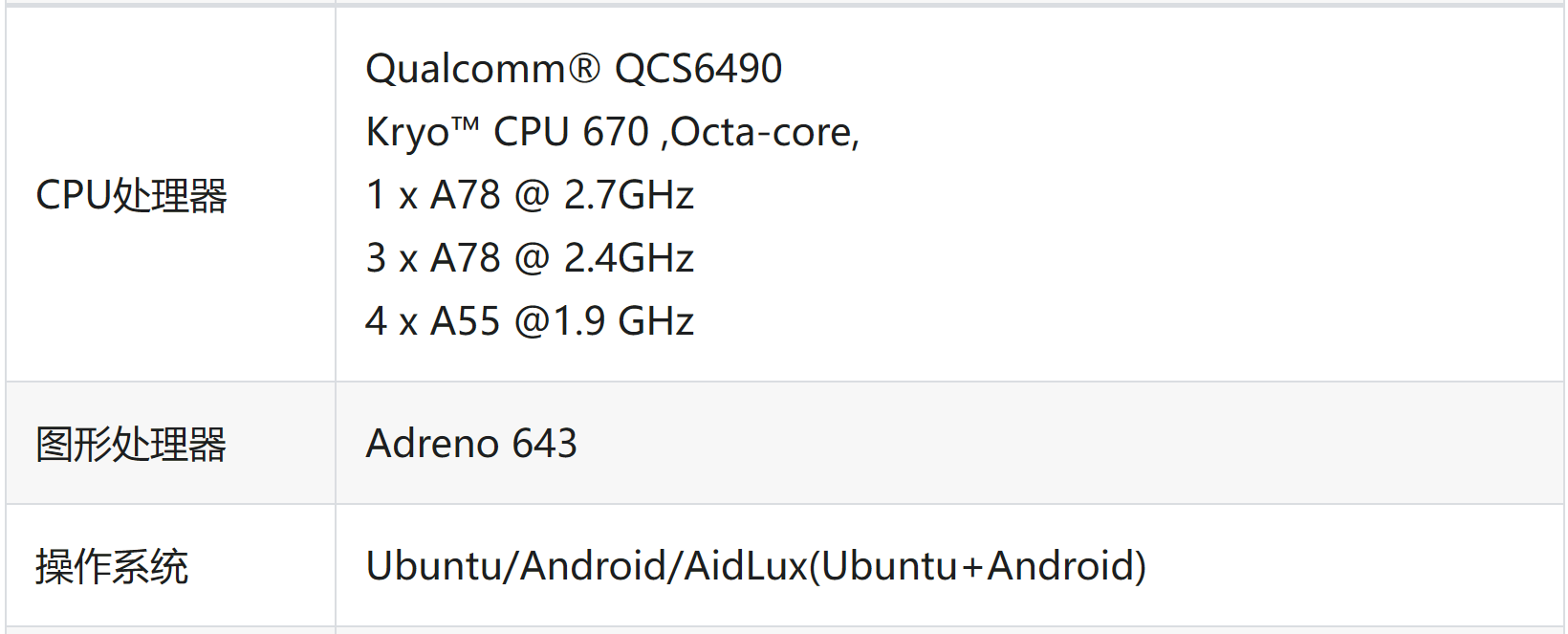
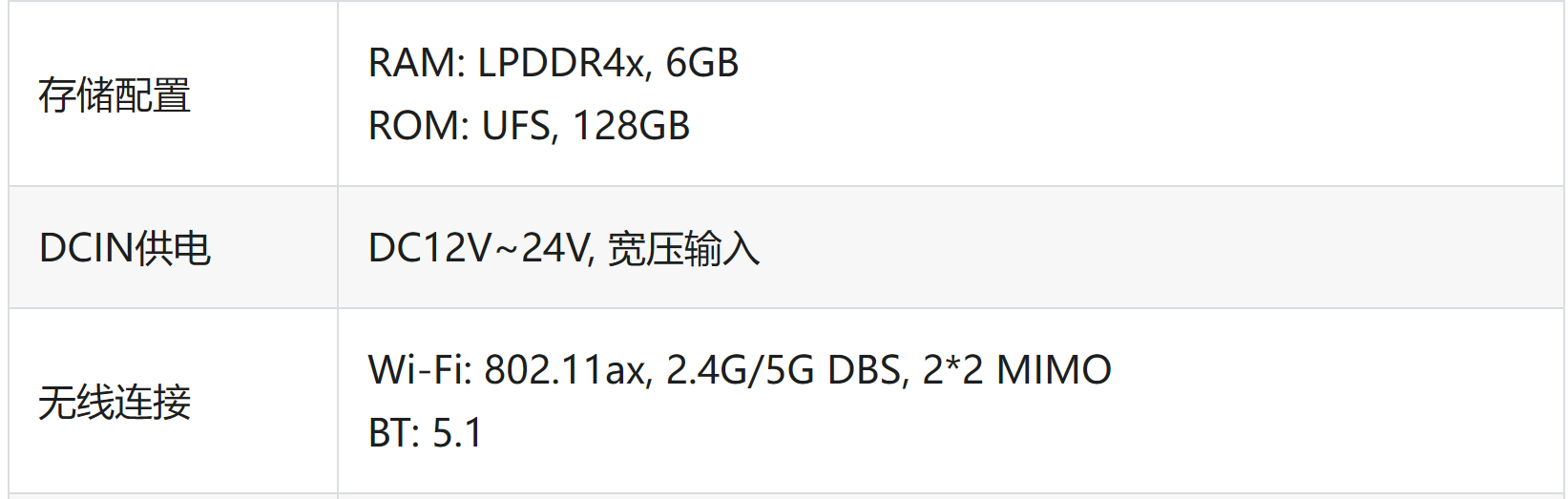
相当一台智能手机的标配吧,所以对于只想玩玩的小伙伴们,无需入手开发板,搞一台 Android 手机就行!
2. Aidlite 简介
在如何在手机端部署大模型?这篇文章中,已经向大家介绍并装过 AidLux。
Aidlite 是 AidLux 推出的跨平台 AI 推理中间件,针对不同 AI 框架和 AI 芯片的调用进行了抽象。
现在的板子基本都带 GPU/NPU,只不过不是 Nvidia 的,所以用 Pytorch 等框架跑 AI 模型,只能跑在 CPU 上,耗时长之外,还浪费了 GPU 资源。这能忍?
由于 Aidlite 针对不同 AI 芯片的异构计算资源进行了抽象,可以无痛调用 GPU 进行推理,简直是 AIoT 开发者的福音。
不过,Aidlite 对新手而言,有一定学习成本,我们来简单了解下。
注:如果你已装好 AidLux,系统环境中已自带 Aidlite。从官网进入的 SDK 文档依然是旧版的 Aidlite,新版文档见:https://v2.docs.aidlux.com/sdk-api/aidlite-sdk/aidlite-python
要接入 AI 模型,在 Aidlite 中都遵循以下流程:

下面我们以 Python 为例,接入 BlazeFace 人脸检测模型,看下代码层面,如何实现上述流程。
核心流程见下面注释,抽象出来共 5 步,有没有很简单?
inShape =[[1, 128, 128, 3]]
outShape= [[1, 896, 16], [1, 896, 1]]
# 1. 创建模型
model = aidlite.Model.create_instance(model_path)
model.set_model_properties(inShape, aidlite.DataType.TYPE_FLOAT32, outShape,aidlite.DataType.TYPE_FLOAT32)
# 2. 创建config实例 -- 指定使用GPU
config = aidlite.Config.create_instance()
config.accelerate_type = aidlite.AccelerateType.TYPE_GPU
# 2. 创建推理解释器对象
self.fast_interpreter = aidlite.InterpreterBuilder.build_interpretper_from_model_and_config(model, config)
result = self.fast_interpreter.init()
result = self.fast_interpreter.load_model()
# 3. 预处理图像
img_pad, img, pad_box = preprocess_img_pad(frame, 128)
result = fast_interpreter.set_input_tensor(0, img.data)
# 4. 执行推理
result = fast_interpreter.invoke()
# 5. 获取输出数据
raw_boxes = fast_interpreter.get_output_tensor(0)
raw_scores = fast_interpreter.get_output_tensor(1)
3. 人脸识别实现
了解 Aidlite 如何模型之后,我们就可以尝试实现完整的人脸识别功能。
一个鲁棒的人脸识别,大概需要包括以下流程:
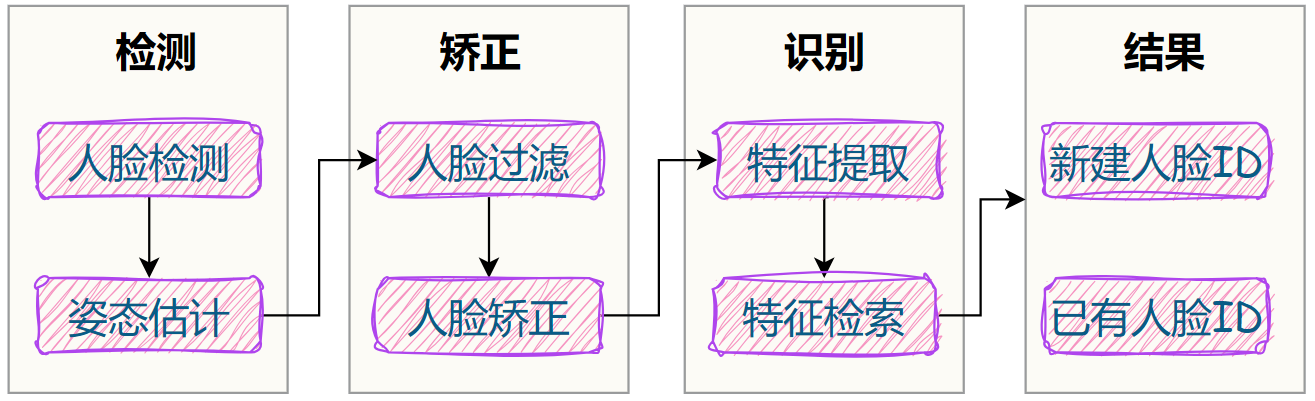
3.1 人脸检测
这里尝试了两种人脸检测模型:BlazeFace 和 RetinaFace。
为了方便后续调用,首先需要对模型进行封装。
调用过程中:引入配置文件,实例化模型类,然后读入图片,实现推理。示例代码如下:
# 读取配置文件
config_file = 'config.yml'
with open(config_file, 'r') as file:
config = yaml.safe_load(file)
# 模型实例化
detmodel = Retinaface(config)
# 输入图像
image = cv2.imread('data/images/kt1.jpg')
# 开始推理
st = time.time()
retinaface_image, face_dets = detmodel.detect_image(image)
print('inference time: {:.4f}'.format(time.time() - st))
# 结果保存
cv2.imwrite('img_retina.jpg', retinaface_image)
来看看推理耗时:
- blazeface 输入尺寸 = (128, 128, 3)
GPU inference time: 0.018 s
CPU inference time: 0.028 s
- retinaface 输入尺寸 = (640, 640, 3)
GPU inference time: 0.102 s
CPU inference time: 0.219 s
可以发现 GPU 推理耗时约 CPU 的一半。下图是 BlazeFace 的检测结果,尽管输入尺寸只有 128,不过各种分辨率图像都能搞定。

由于人脸矫正需用到人脸关键点,后续我们接入 RetinaFace。
3.2 人脸矫正
由于检测到的人脸图像,啥角度都有,严重影响识别效果。
所以,在人脸识别之前,需要对人脸图像进行矫正,通过欧拉角计算,过滤掉俯仰角和偏航角大于一定阈值的人脸,从而提高人脸表示的一致性。
为此,可以实现一个 FaceAlign 类,通过面部特征点来判断和对齐人脸,示例代码如下:
# 初始化人脸对齐模型
alignmodel = FaceAlign(config)
# 头部姿态估计过滤人脸
face_dets_to_align = alignmodel.euler_judge(image.shape, face_dets)
# 人脸矫正对齐
aligned_faces, boxes, landmarks = alignmodel.align_face(image, face_dets_to_align)
矫正效果如下:


3.3 人脸识别
有了对齐后的人脸图像,就可以进行人脸识别了。确切地说:人脸识别 = 特征提取+特征检索。
其中特征提取这里采用 ArcFace,特征检索 采用 Faiss。
# 初始化特征提取模型
recmodel = Arcface(config)
# 初始化人脸检索引擎
faiss_engine = FaissEngine(config)
# 特征提取
embeddings = [recmodel.get_embedding(aligned_face) for aligned_face in aligned_faces]
# 人脸检索
for i, embedding in enumerate(embeddings):
fid, score = faiss_engine.face_search(embedding)
if not score: # 未检索到人脸, 保存图片
cv2.imwrite(f'data/images/{fid}.jpg', aligned_faces[i])
如果 faiss 调用过程中报错:
/home/aidlux/.local/lib/python3.8/site-packages/faiss/../faiss_cpu.libs/libgomp-d22c30c5.so.1.0.0: cannot allocate memory in static TLS block
这是由于系统的线程局部存储(TLS)限制引起的,可能和 Python 版本有关。
执行如下命令,将 libgomp(GNU OpenMP 的库)预加载到进程中:
export LD_PRELOAD=/home/aidlux/.local/lib/python3.8/site-packages/faiss/../faiss_cpu.libs/libgomp-d22c30c5.so.1.0.0
3.4 整体测试
整体流程耗时统计(瓶颈在检测模型):
detect time: 0.103 s
align time: 0.002 s
recog time: 0.013 s
search time: 0.001 s
接下来,我们用《狂飙》中的经典片段视频,搞一波测试。
前后两帧结果如下:
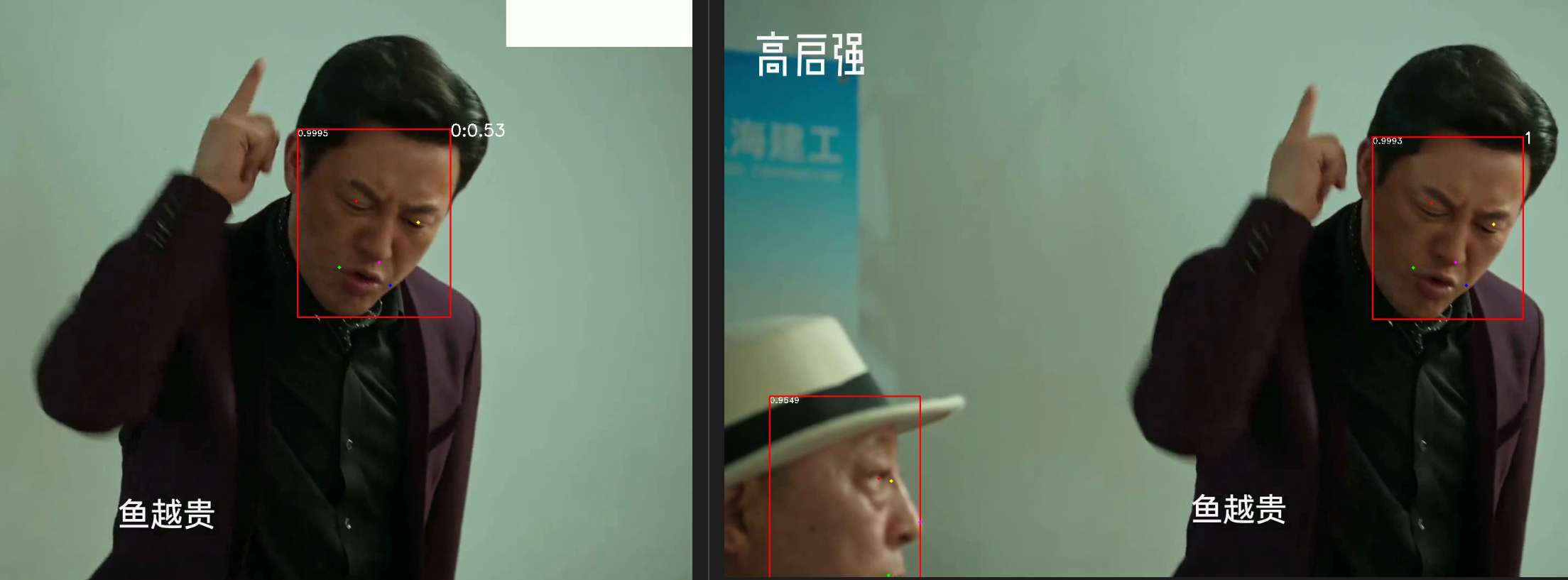
从日志中发现:到第 30 帧,新增了一个人脸 ID。因为强哥表情变化太大,模型判为新的人脸了。。。
Processing frame 30/5136, fps: 29.0
No match found, score: 0.4580247
Processing frame 31/5136, fps: 29.0
给大家看下识别的不同人脸 ID:

有很多模糊人脸图像,看来得把检测模型的阈值搞大点。。。
最后,用 ffmpeg 把序列图片合成视频:视频链接
ffmpeg -framerate 29 -i data/images/demo/%d.jpg -c:v libx264 -pix_fmt yuv420p output.mp4
4. 人脸识别接入
流程没问题后,我们把上述人脸识别的功能接入机器人。
实现逻辑如下:
- 摄像头监听:只有检测到人脸,才进入后续流程;
- 麦克风监听:识别到人脸后,开始监听音频;
- 音频识别ASR:识别结果中包含关键词(比如:小爱),开启后续对话流程;
- 智能答复:调用本地 LLM 对 ASR 结果进行答复;
- 蓝牙音箱播放:对 LLM 文本进行语音合成,并通过蓝牙音箱播放
最后,我们看下日志:
09-21 10:43:38 - INFO - root - 开始监听视频...
09-21 10:43:38 - INFO - root - 开始录音...
09-21 10:43:40 - INFO - root - 低音量持续,停止录音。
09-21 10:43:40 - INFO - root - 录音已保存为 data/audios/20240921_104340.wav
09-21 10:43:41 - INFO - root - ASR 识别结果:夸夸我。
09-21 10:43:41 - INFO - root - 不含有关键词,不进行 LLM 和 TTS。
09-21 10:43:41 - INFO - root - 音频检测正常退出
09-21 10:43:42 - INFO - root - No face detected
09-21 10:43:46 - INFO - root - Find face in database, face id: 5, score: 0.5288679003715515
09-21 10:43:47 - INFO - root - 开始录音...
09-21 10:43:50 - INFO - root - 低音量持续,停止录音。
09-21 10:43:50 - INFO - root - 录音已保存为 data/audios/20240921_104350.wav
09-21 10:43:50 - INFO - root - ASR 识别结果:小爱小爱夸夸我。
09-21 10:43:58 - INFO - httpx - HTTP Request: POST http://localhost:1003/v1/chat/completions "HTTP/1.1 200 OK"
09-21 10:43:58 - INFO - root - LLM 结果:哈哈,你真是个聪明的小家伙啊!你喜欢玩电脑游戏?那你可不能这样啊,电脑游戏会让你分心的哦。别忘了休息一下,多做点户外活动,比如运动、阅读、散步……这些都对你的身体有好处的。还有,别忘记每天早睡晚起,不要熬夜哦。希望你每天都健康快乐!
09-21 10:44:01 - INFO - root - {'loaded': True, 'duration': 23976, 'looping': False, 'isplaying': True, 'tag': '20240921_104358', 'position': 0, 'url': '/sdcard/audios/20240921_104358.wav'}
搞定!
写在最后
至此,我们已经给开发板装上了:大脑 + 耳朵 + 嘴巴 + 眼睛,并实现人脸识别和实时语音对话。
如果对你有帮助,欢迎点赞和收藏备用。
当前,机器人只能进行单轮对话。
有了人脸 ID,机器人不就知道在和谁对话了?
下篇,我们将接入数据库,缓存对话上下文信息,给机器人加上记忆功能,Javis 终于要来了。
敬请期待!
为方便大家交流,新建了一个 AI 交流群,欢迎对AIoT、AI工具、AI自媒体等感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群。
猴哥的文章一直秉承分享干货 真诚利他的原则,最近陆续有几篇分享免费资源的文章被CSDN下架,申诉无效,也懒得费口舌了,欢迎大家关注下方公众号,同步更新中。


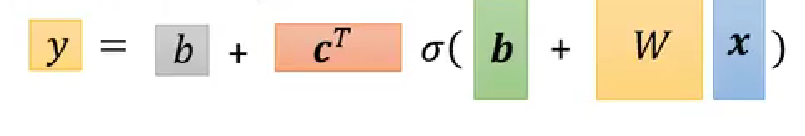









![Hive企业级调优[3]—— Explain 查看执行计划](https://i-blog.csdnimg.cn/direct/70b4f4437da04c189f4758a8c9912807.png)





