结论速递
VCED项目使用一个十分简单好用的 Web 应用程序框架Streamlit。
本次任务简单学习Streamlit的基本使用。并逐行阅读学习VCED项目的前端代码,学习数据的传递,中间存储方式,以及功能的实现。
前情回顾
- 环境配置
- Jina生态
- 跨模态模型
目录
- 结论速递
- 前情回顾
- 1 Streamlit
- 1.1 Streamlit简介
- 1.2 安装和使用
- 1.2.1 安装
- 1.2.2 使用
- 2 VCED项目的前端
- 2.1 使用流程
- 2.2 代码实现
1 Streamlit
1.1 Streamlit简介
Streamlit 是一个基于 Python 的 Web 应用程序框架,可以帮助数据科学家和学者在短时间内开发机器学习可视化仪表板。只需几行代码,就可以构建并部署强大的数据应用程序。其特点如下:
- 跨平台,支持 Windows、macOS、Linux
- 只需要掌握 Python,开发者就可以构建 Web App,不需要有任何的前端基础
- 开源,社区资源丰富(Community forum、Github)
由于 Streamlit 基于 Python,开发者无需学习其他就可以搭建一个较为完整的系统。因此此次教程,VCED项目就通过 Streamlit + Jina 构建了一套系统。
1.2 安装和使用
1.2.1 安装
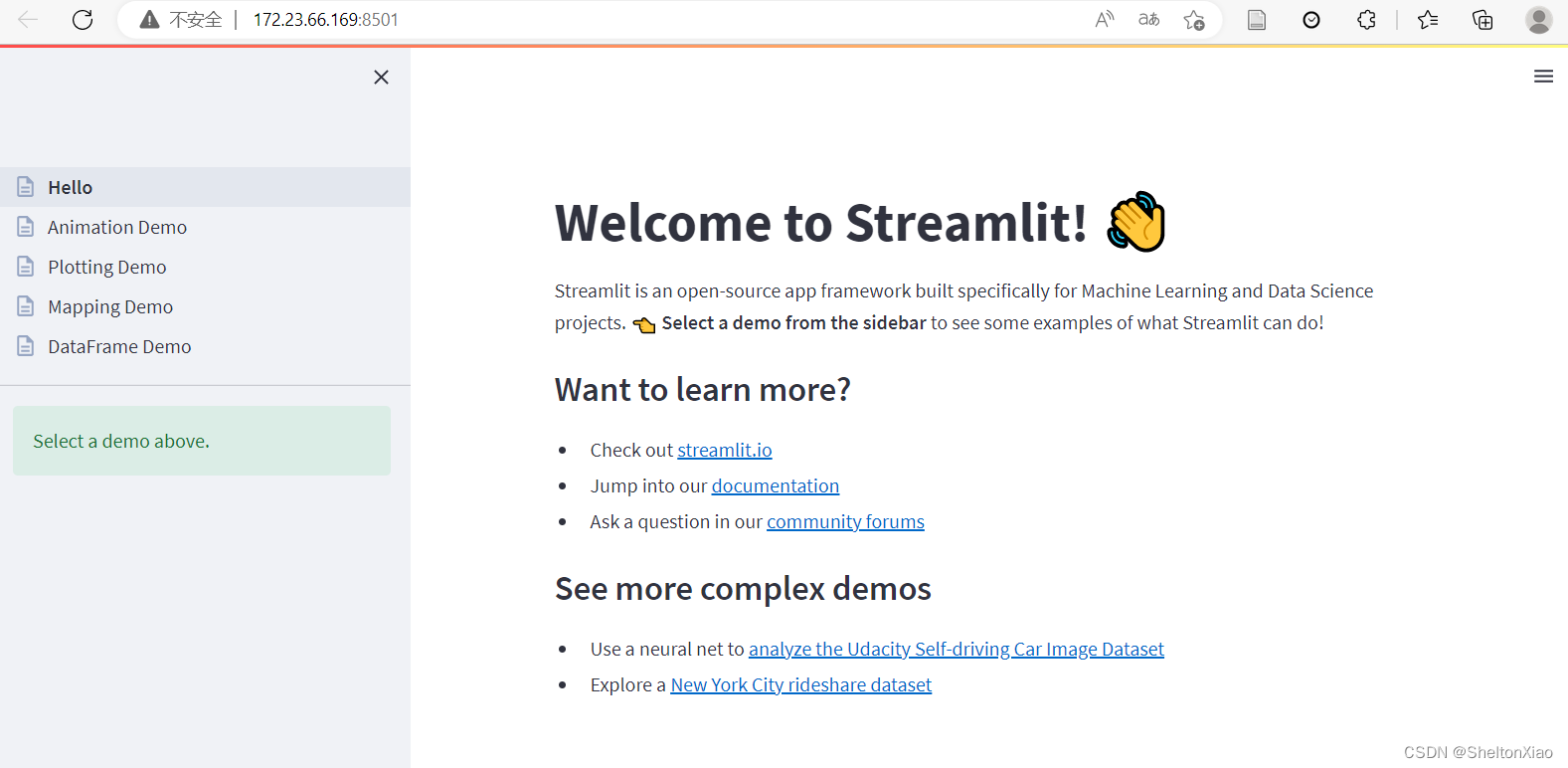
Streamlit目前支持Python 3.7以上的版本。用pip安装就可以。官方有一个预设网页:
streamlit hello
启动后长这样:
1.2.2 使用
Streamlit 框架提供了很多 API 供开发者使用。教程提供下面步骤将指引你一步一步构建自己的第一个 Web App:
- 打开 IDE(如 vscode),创建一个
hello-streamlit.py文件,输入:
import streamlit as st
- 每个Web页面都会有一个title:
st.set_page_config(page_title="Hello Streamlit")
- Streamlit API 中提供了很多页面中常见的 elements:
st.title('This is your first Streamlit page!') # 标题
st.markdown('Streamlit is **_really_ cool**.') # markdown
code = '''def hello():
print("Hello, Streamlit!")'''
st.code(code, language='python') # code
df = pd.DataFrame(
np.random.randn(50, 20),
columns=('col %d' % i for i in range(20)))
st.dataframe(df) # dataframe
st.latex(r'''
a + ar + a r^2 + a r^3 + \cdots + a r^{n-1} =
\sum_{k=0}^{n-1} ar^k =
a \left(\frac{1-r^{n}}{1-r}\right)
''') # latex
st.title:标题st.markdown:markdownst.code:代码st.dataframe:数据帧st.latex:latex公式
上述生成的界面如下:

确实是really cool
这里只介绍了 Streamlit 的冰山一角,更多特性和细节感兴趣的同学可以去官网进一步学习。另外,官网也有很多 Streamlit 模板,可以帮助你更高效地搭建自己的应用。
2 VCED项目的前端
2.1 使用流程
VCED项目实现的流程有:
- 上传视频
- 输入描述
- 输入Top N值
- 点击搜索,等待返回结果
- 查看搜索结果
2.2 代码实现
定义存储路径,监听端口(这些都属于数据传输)
VIDEO_PATH = f"{os.getcwd()}/data"
# 视频存储的路径
if not os.path.exists(VIDEO_PATH):
os.mkdir(VIDEO_PATH)
# 视频剪辑后存储的路径
if not os.path.exists(VIDEO_PATH + "/videos/"):
os.mkdir(VIDEO_PATH + "/videos")
# GRPC 监听的端口
port = 45679
# 创建 Jina 客户端
c = Client(host=f"grpc://localhost:{port}")
接下去就是一个一个的定义功能。
首先定义页面
# 设置标签栏
st.set_page_config(page_title="VCED", page_icon="🔍")
# 设置标题
st.title('Welcome to VCED!')
定义视频上传组件,使用st.file_uploader实现上传,然后根据上传结果创建st.video对象,并存储到先前定义的路径下,方便后端读取。
# 视频上传组件
uploaded_file = st.file_uploader("Choose a video")
video_name = None # name of the video
# 判断视频是否上传成功
if uploaded_file is not None:
# preview, delete and download the video
video_bytes = uploaded_file.read()
st.video(video_bytes)
# save file to disk for later process
video_name = uploaded_file.name
with open(f"{VIDEO_PATH}/{video_name}", mode='wb') as f:
f.write(video_bytes) # save video to disk
video_file_path = f"{VIDEO_PATH}/{video_name}"
uid = uuid.uuid1()
同时生成一个uid。
定义文本输入框和top k 输入框。
# 文本输入框
text_prompt = st.text_input(
"Description", placeholder="please input the description", help='The description of clips from the video')
# top k 输入框
topn_value = st.text_input(
"Top N", placeholder="please input an integer", help='The number of results. By default, n equals 1')
然后定义三个功能函数:
- 时间还原:将秒数转化为str时间戳,截取视频用
- 截取视频:根据时间戳截取视频
- 后端交互:生成jina对象,通过Client post数据,得到返回结果resp,存入json。
# 根据秒数还原 例如 10829s 转换为 03:04:05
def getTime(t: int):
m,s = divmod(t, 60)
h, m = divmod(m, 60)
t_str = "%02d:%02d:%02d" % (h, m, s)
print (t_str)
return t_str
# 根据传入的时间戳位置对视频进行截取
def cutVideo(start_t: str, length: int, input: str, output: str):
"""
start_t: 起始位置
length: 持续时长
input: 视频输入位置
output: 视频输出位置
"""
os.system(f'ffmpeg -ss {start_t} -i {input} -t {length} -c:v copy -c:a copy -y {output}')
# 与后端交互部分
def search_clip(uid, uri, text_prompt, topn_value):
video = DocumentArray([Document(uri=uri, id=str(uid) + uploaded_file.name)])
t1 = time.time()
c.post('/index', inputs=video) # 首先将上传的视频进行处理
text = DocumentArray([Document(text=text_prompt)])
print(topn_value)
resp = c.post('/search', inputs=text, parameters={"uid": str(uid), "maxCount":int(topn_value)}) # 其次根据传入的文本对视频片段进行搜索
data = [{"text": doc.text,"matches": doc.matches.to_dict()} for doc in resp] # 得到每个文本对应的相似视频片段起始位置列表
return json.dumps(data)
定义Serach按钮,同时实现功能。
单击后,生成对象给后端查找,返回时间戳,剪视频,输出。
# search
search_button = st.button("Search")
if search_button: # 判断是否点击搜索按钮
if uploaded_file is not None: # 判断是否上传视频文件
if text_prompt == None or text_prompt == "": # 判断是否输入查询文本
st.warning('Please input the description first!')
else:
if topn_value == None or topn_value == "": # 如果没有输入 top k 则默认设置为1
topn_value = 1
with st.spinner("Processing..."):
result = search_clip(uid, video_file_path, text_prompt, topn_value)
result = json.loads(result) # 解析得到的结果
for i in range(len(result)):
matchLen = len(result[i]['matches'])
for j in range(matchLen):
print(j)
left = result[i]['matches'][j]['tags']['leftIndex'] # 视频片段的开始位置
right = result[i]['matches'][j]['tags']['rightIndex'] # 视频片段的结束位置
print(left)
print(right)
start_t = getTime(left) # 将其转换为标准时间
output = VIDEO_PATH + "/videos/clip" + str(j) +".mp4"
cutVideo(start_t,right-left, video_file_path, output) # 对视频进行切分
st.video(output) #将视频显示到前端界面
st.success("Done!")
else:
st.warning('Please upload video first!')
此处有一个疑问
?:为什么要通过json传递数据,直接字典不可以吗
![[python]basemap后安装后hello world代码](https://img-blog.csdnimg.cn/c5f2b969eb034153b300e1044a2ca431.png)


![[Apollo Cyber RT] Timer实现](https://img-blog.csdnimg.cn/e38e5bbff45d4bc3b313c029f0569d5b.png)