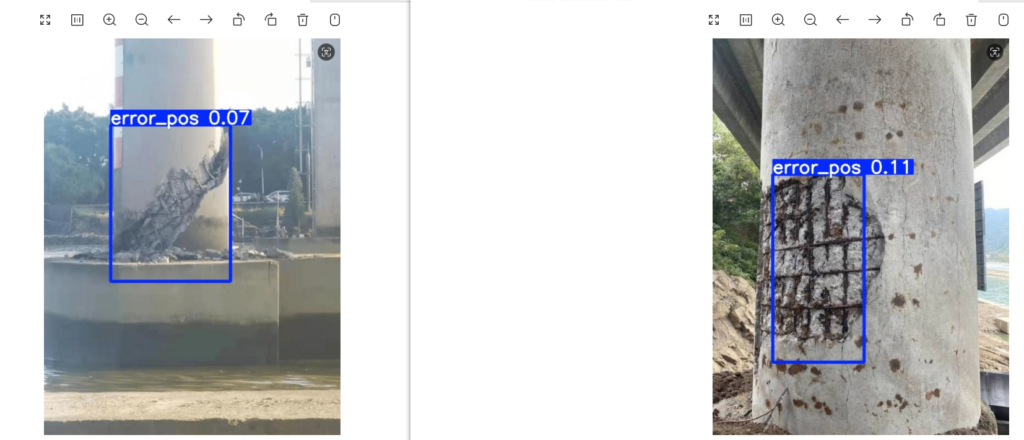
智慧矿井智能分析数据集

数据1:数据1包含煤矿采掘工作面工人安全帽检测,工人行为检测(行走,站立,坐,操作,弯腰,靠,摔,爬),液压支撑防护(液压支撑防护板所有角度如防护板0到30度,30度到60.....等多角度检测,支撑异常,剪煤机等)检测,采煤人检测,运煤线检测,煤块检测,数据集共22GB,13万张真实拍摄影像,yolo和coco两种标注格式。

数据2:数据2数据集总共包含70948张图片,囊括了三类不同亮度水平(包括低亮度、中亮度和高亮度)以及正面、左侧和右侧三类拍摄角度,并覆盖了目标遮挡、目标模糊等多种复杂场景,收录了煤矿井下钻场出现频率较高的5类重要目标,分别是夹持器、钻机卡盘、煤矿工人、矿井安全帽和钻杆,并提供了PASCAL VOC,yolo格式的标注文件。

智慧矿井智能分析数据集
数据集描述
该数据集是一个专门用于煤矿井下智能监控和安全分析的数据集,旨在帮助研究人员和开发者训练和评估基于深度学习的目标检测、行为识别和异常检测模型。数据集分为两个部分,涵盖了煤矿采掘工作面的多种场景和目标,包括工人安全帽检测、工人行为检测、液压支撑防护检测等。数据集提供了高分辨率的真实拍摄图像,并且标注质量很高,支持多种标注格式。
数据1:煤矿采掘工作面智能分析数据集
数据规模
- 总样本数量:130,000张真实拍摄影像
- 数据量:约22GB
- 标注格式:Yolo和COCO两种标注格式
- 目标类别:
- 工人安全帽检测
- 工人行为检测(行走、站立、坐、操作、弯腰、靠、摔、爬)
- 液压支撑防护检测(不同角度如0到30度、30度到60度等)
- 支撑异常检测
- 剪煤机检测
- 采煤人检测
- 运煤线检测
- 煤块检测
图像特性
- 高分辨率影像:图像为高分辨率,确保细节清晰。
- 多目标检测:涵盖多种目标和复杂的行为模式。
- 多样化场景:覆盖了煤矿采掘工作面的各种实际场景。
- 高质量标注:提供详细的边界框和类别标签,支持Yolo和COCO格式。
应用场景
- 工人安全监测:通过实时监控工人的安全帽佩戴情况和行为,提高作业安全性。
- 设备状态监控:检测液压支撑和其他机械设备的状态,预防潜在故障。
- 生产效率优化:通过对采煤人和运煤线的检测,优化生产流程和资源配置。
- 科研分析:用于研究目标检测和行为识别算法在煤矿环境中的应用。
数据2:煤矿井下钻场智能分析数据集
数据规模
- 总样本数量:70,948张图片
- 数据量:具体大小未提供
- 标注格式:PASCAL VOC和Yolo格式
- 目标类别:
- 夹持器
- 钻机卡盘
- 煤矿工人
- 矿井安全帽
- 钻杆
图像特性
- 多亮度水平:包括低亮度、中亮度和高亮度三种不同的光照条件。
- 多拍摄角度:正面、左侧和右侧三种不同的拍摄角度。
- 复杂场景:包含目标遮挡、目标模糊等多种复杂场景。
- 高质量标注:提供详细的边界框和类别标签,支持PASCAL VOC和Yolo格式。
应用场景
- 工人安全监测:通过实时监控矿井工人的安全帽佩戴情况,提高作业安全性。
- 设备状态监控:检测夹持器、钻机卡盘和钻杆的状态,预防潜在故障。
- 生产效率优化:通过对钻场内各种设备和工人的检测,优化钻探作业流程。
- 科研分析:用于研究目标检测算法在不同光照条件和复杂场景下的鲁棒性。
数据集结构
典型的数据集目录结构如下:
1smart_mine_analysis_dataset/
2├── data1/
3│ ├── images/
4│ │ ├── img_00001.jpg
5│ │ ├── img_00002.jpg
6│ │ └── ...
7│ ├── annotations_yolo/
8│ │ ├── img_00001.txt
9│ │ ├── img_00002.txt
10│ │ └── ...
11│ ├── annotations_coco/
12│ │ ├── coco_annotations.json
13│ └── README.md # 数据集说明文件
14└── data2/
15 ├── images/
16 │ ├── img_00001.jpg
17 │ ├── img_00002.jpg
18 │ └── ...
19 ├── annotations_voc/
20 │ ├── img_00001.xml
21 │ ├── img_00002.xml
22 │ └── ...
23 ├── annotations_yolo/
24 │ ├── img_00001.txt
25 │ ├── img_00002.txt
26 │ └── ...
27 └── README.md # 数据集说明文件示例代码
以下是一个使用Python和相关库(如OpenCV、PIL等)来加载和展示数据集的简单示例代码:
1import os
2import cv2
3import numpy as np
4from PIL import Image
5import json
6import xml.etree.ElementTree as ET
7
8# 数据集路径
9dataset_path = 'path/to/smart_mine_analysis_dataset/'
10
11# 加载图像和标注 (YOLO格式)
12def load_image_and_labels_yolo(image_path, annotation_path):
13 # 读取图像
14 image = Image.open(image_path).convert('RGB')
15
16 # 解析YOLO标注文件
17 with open(annotation_path, 'r') as infile:
18 lines = infile.readlines()
19 objects = []
20 for line in lines:
21 class_id, x_center, y_center, width, height = map(float, line.strip().split())
22 objects.append([class_id, x_center, y_center, width, height])
23 return image, objects
24
25# 加载图像和标注 (VOC格式)
26def load_image_and_labels_voc(image_path, annotation_path):
27 # 读取图像
28 image = Image.open(image_path).convert('RGB')
29
30 # 解析VOC标注文件
31 tree = ET.parse(annotation_path)
32 root = tree.getroot()
33 objects = []
34 for obj in root.findall('object'):
35 class_name = obj.find('name').text
36 bbox = obj.find('bndbox')
37 xmin = int(bbox.find('xmin').text)
38 ymin = int(bbox.find('ymin').text)
39 xmax = int(bbox.find('xmax').text)
40 ymax = int(bbox.find('ymax').text)
41 objects.append([class_name, xmin, ymin, xmax, ymax])
42 return image, objects
43
44# 展示图像和标注
45def show_image_with_boxes(image, boxes, is_yolo=False, image_size=(512, 512)):
46 img = np.array(image)
47 h, w, _ = img.shape
48
49 for box in boxes:
50 if is_yolo:
51 class_id, x_center, y_center, width, height = box
52 xmin = int((x_center - width / 2) * w)
53 ymin = int((y_center - height / 2) * h)
54 xmax = int((x_center + width / 2) * w)
55 ymax = int((y_center + height / 2) * h)
56 else:
57 _, xmin, ymin, xmax, ymax = box
58
59 cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
60
61 cv2.imshow('Image with Boxes', img)
62 cv2.waitKey(0)
63 cv2.destroyAllWindows()
64
65# 主函数
66if __name__ == "__main__":
67 subset = 'data1' # 可以选择 'data2'
68 images_dir = os.path.join(dataset_path, subset, 'images')
69 annotations_dir = os.path.join(dataset_path, subset, 'annotations_yolo')
70
71 # 获取图像列表
72 image_files = [f for f in os.listdir(images_dir) if f.endswith('.jpg')]
73
74 # 随机选择一张图像
75 selected_image = np.random.choice(image_files)
76 image_path = os.path.join(images_dir, selected_image)
77 annotation_path = os.path.join(annotations_dir, selected_image.replace('.jpg', '.txt'))
78
79 # 加载图像和标注
80 if subset == 'data1':
81 image, boxes = load_image_and_labels_yolo(image_path, annotation_path)
82 is_yolo = True
83 elif subset == 'data2':
84 annotations_dir = os.path.join(dataset_path, subset, 'annotations_voc')
85 annotation_path = os.path.join(annotations_dir, selected_image.replace('.jpg', '.xml'))
86 image, boxes = load_image_and_labels_voc(image_path, annotation_path)
87 is_yolo = False
88 else:
89 raise ValueError("Invalid subset. Choose 'data1' or 'data2'.")
90
91 # 展示带有标注框的图像
92 show_image_with_boxes(image, boxes, is_yolo=is_yolo)这段代码展示了如何加载图像和其对应的YOLO或VOC格式的标注文件,并在图像上绘制边界框。您可以根据实际需求进一步扩展和修改这段代码,以适应您的具体应用场景。
示例代码:使用预训练模型进行推理
以下是使用预训练模型进行推理的示例代码。这里我们假设您使用的是基于YOLOv5的模型,但您可以根据需要选择其他支持目标检测的模型。
1import torch
2import cv2
3import numpy as np
4from PIL import Image
5import yolov5 # 请确保已安装yolov5库
6
7# 数据集路径
8dataset_path = 'path/to/smart_mine_analysis_dataset/'
9
10# 加载预训练模型
11model = yolov5.load('path/to/pretrained/yolov5_weights.pt') # 替换成实际的预训练模型路径
12model.eval()
13
14# 主函数
15if __name__ == "__main__":
16 subset = 'data1' # 可以选择 'data2'
17 images_dir = os.path.join(dataset_path, subset, 'images')
18
19 # 获取图像列表
20 image_files = [f for f in os.listdir(images_dir) if f.endswith('.jpg')]
21
22 # 随机选择一张图像
23 selected_image = np.random.choice(image_files)
24 image_path = os.path.join(images_dir, selected_image)
25
26 # 读取并预处理图像
27 image = Image.open(image_path).convert('RGB')
28
29 # 使用预训练模型进行推理
30 results = model(image)
31
32 # 处理预测结果
33 boxes = results.xyxy[0].cpu().numpy()
34
35 # 在图像上绘制边界框
36 img = np.array(image)
37 for box in boxes:
38 xmin, ymin, xmax, ymax, conf, class_id = box
39 class_name = results.names[int(class_id)]
40 label = f'{class_name} {conf:.2f}'
41 cv2.rectangle(img, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 255, 0), 2)
42 cv2.putText(img, label, (int(xmin), int(ymin) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
43
44 # 显示结果
45 cv2.imshow('Image with Boxes', img)
46 cv2.waitKey(0)
47 cv2.destroyAllWindows()这段代码展示了如何使用预训练的YOLOv5模型进行推理,并显示和保存推理结果。您可以根据实际需求进一步扩展和修改这段代码,以适应您的具体应用场景。如果您需要使用其他模型进行更高级的功能,如模型微调或增量训练,可以参考相应模型的官方文档来进行相应的配置和操作。