前置环境资源下载
提示:要开外网才能下载的环境我都放在了网盘里,教程中用到的环境可从这里一并下载:
https://pan.quark.cn/s/f0c36aa1ef60
1. 下载YOLOv5源码
- 官方地址:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
2. 下载预训练检查点文件
- 官方地址:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
- 页面向下拉,会看到 "Pretrained Checkpoints" 表格,任选一个进行下载(我这里使用的是
yolov5x.pt)。 - 下载完成后,将
.pt文件放入 YOLOv5 源码的根目录。
3. 下载CUDA
- 要用显卡GPU训练模型,就必须下载CUDA。
- 官方链接:CUDA Toolkit Archive | NVIDIA Developer
- 我下载的是 12.2.0 版本,安装时选择默认路径即可。
4. 下载3个Python库:torch、torchvision、torchaudio
-
提示:
torch是算法核心,torchvision用于处理图像,torchaudio处理音频/视频。这一条很关键,仔细看,因为涉及到版本匹配 -
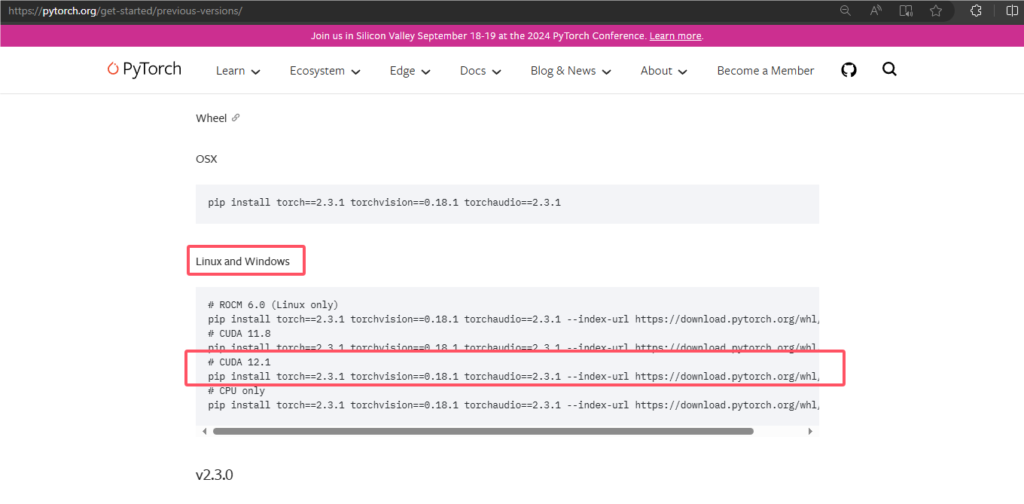
刚才我们下载的CUDA是12.2版本对吧,我们进入PyTorch官网往下拉可以看到一个注释为CUDA 12.1的,所以我就选择差别不大的12.1版本的命令下载,这官网里都给我们把版本匹配好了,就不要自己一个一个不指定版本去下载,ok获取到命令如下,如果下载失败,看下面第5条:
# CUDA 12.1
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121
5. 使用国内镜像下载库失败的解决方法
官方的命令下载这三个库很多人因为网络超时导致中途下载失败,当然也有下载顺利的人,而尝试使用国内镜像去下载这三个库时,好像是没有GPU版本的,下载下来的只有CPU版本的,因此提供如下安装这三个库的方式,包成功!!!:
下载地址:浏览器进入 PyTorch 官方站 https://download.pytorch.org/whl/torch_stable.html
使用快捷键ctrl+f搜索并下载:
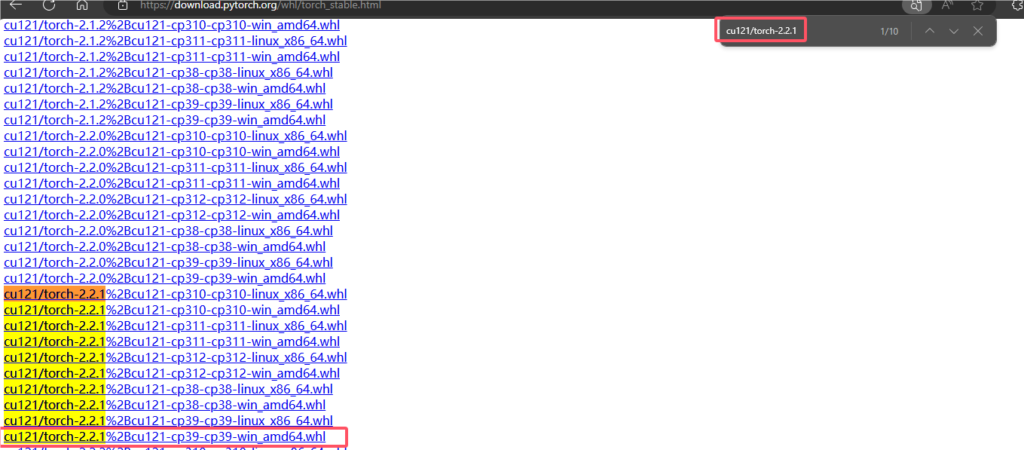
torch:搜索 cu121/torch-2.2.1,选择 cp39-win 的版本。
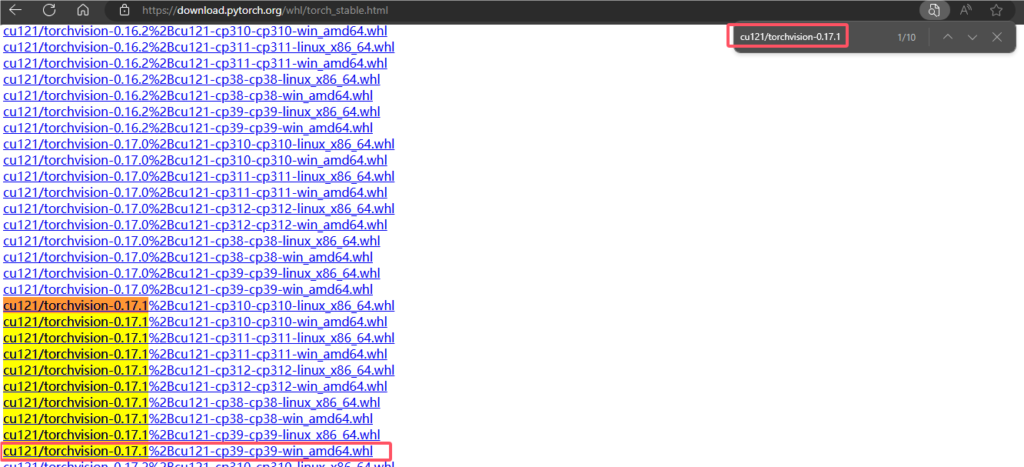
torchvision:搜索 cu121/torchvision-0.17.1,选择 cp39-win 的版本。
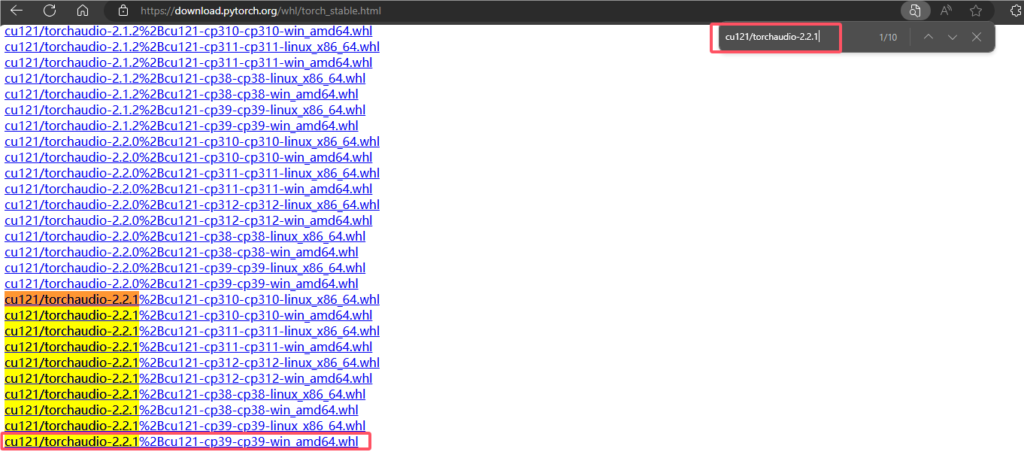
torchaudio:搜索 cu121/torchaudio-2.2.1,选择 cp39-win 的版本。
安装步骤:
下载完后随便放到一个目录(如:D:\C01MyENV),然后打开CMD命令行进入这个目录,执行以下三条命令安装:
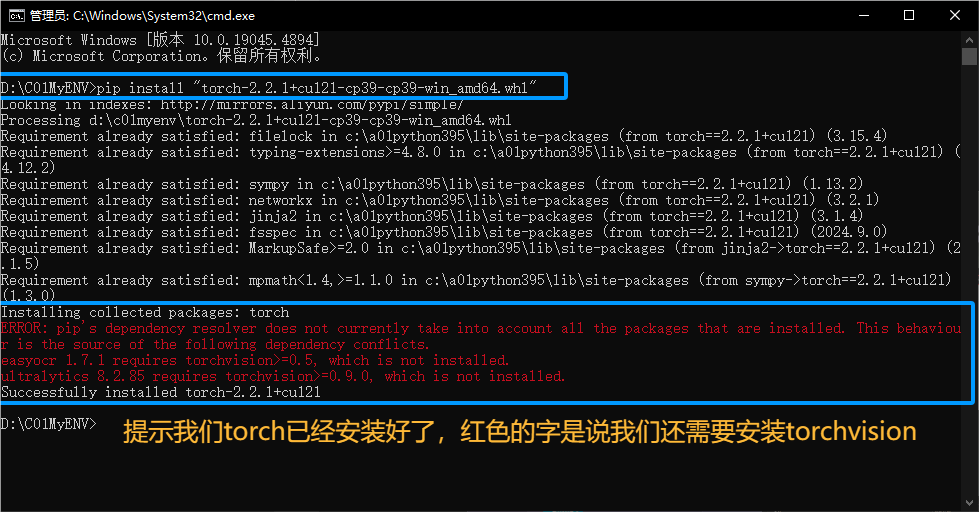
pip install "torch-2.2.1+cu121-cp39-cp39-win_amd64.whl"
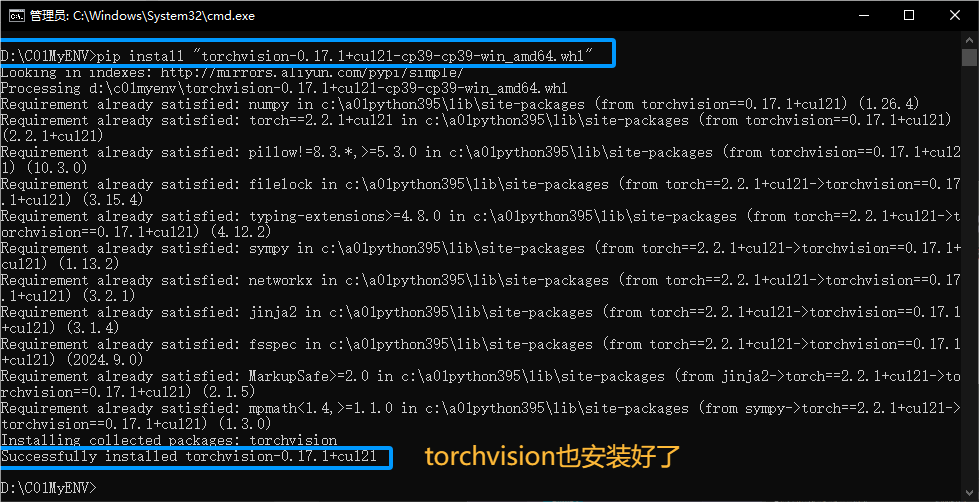
pip install "torchvision-0.17.1+cu121-cp39-cp39-win_amd64.whl"
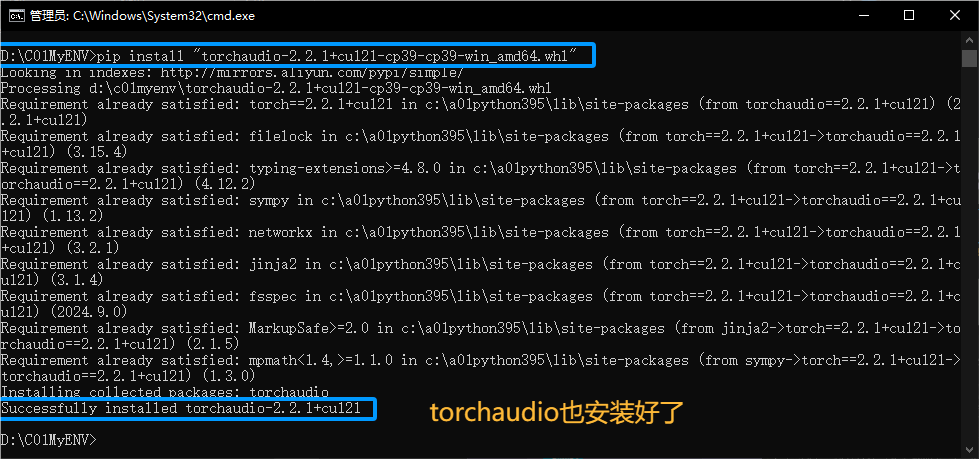
pip install "torchaudio-2.2.1+cu121-cp39-cp39-win_amd64.whl"安装过成如图
环境验证
验证CUDA是否可用
在Python中运行以下代码,查看你的CUDA是否可用:
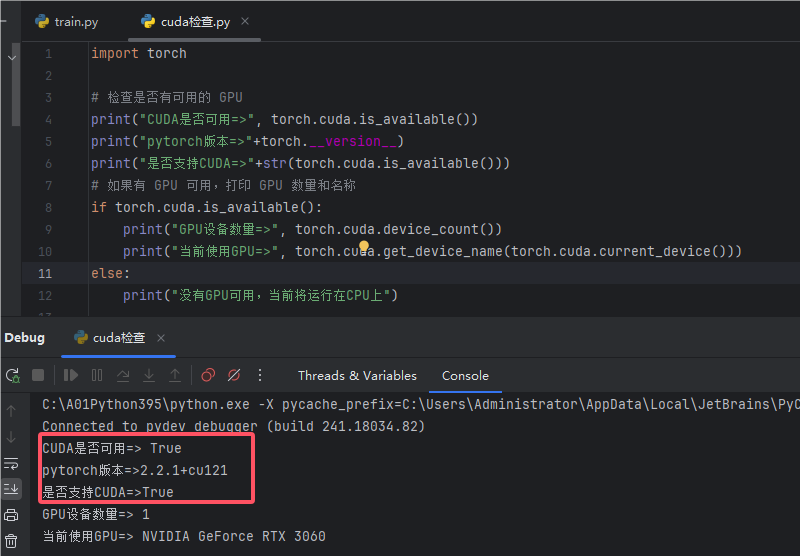
import torch
# 检查是否有可用的 GPU
print("CUDA是否可用=>", torch.cuda.is_available())
print("pytorch版本=>"+torch.__version__)
print("是否支持CUDA=>"+str(torch.cuda.is_available()))
# 如果有 GPU 可用,打印 GPU 数量和名称
if torch.cuda.is_available():
print("GPU设备数量=>", torch.cuda.device_count())
print("当前使用GPU=>", torch.cuda.get_device_name(torch.cuda.current_device()))
else:
print("没有GPU可用,当前将运行在CPU上")运行后你会看到如下界面,表示GPU版本的Yolov5环境成功了,如图:
Yolov5源码用到的库一键下载
CMD命令进入yolov5源码包,执行pip install -r requirements.txt,此命令会下载requirements.txt文件中指定版本的包。只要你配置了国内的镜像,这一步必然是顺利的。
下载标注工具
1. 下载labelImg工具
- 官方链接:https://github.com/tzutalin/labelImg
- 下载完成后,解压到本地。
2. 安装 pyQT5 依赖
-
由于
labelImg依赖于pyQT5,需要先安装它。安装命令:
pip install pyqt5
3. 安装 libs.resources 模块
-
打开 CMD,进入到
labelImg源码目录,执行以下命令安装libs.resources模块:安装命令:
pyrcc5 -o libs/resources.py resources.qrc
4. 删除预制标签
- 为了避免初学者在标记时混淆,请删除
labelImg-master\data\predefined_classes.txt文件中的所有内容,注意是删除内容,不是让你删除文件。
5. 启动 labelImg
-
CMD命令进入
labelImg源码目录,运行以下命令启动标注工具:启动命令:
python labelImg.py -
之后,每次启动
labelImg都可以直接运行此命令。
准备图片
为快速操作,我这里使用如下爬虫,快速爬取图片,然后筛选24张进行标注训练,当然实际过程中为了保证模型的准确,会需要更多的图片,不复杂的场景100张即可,复杂的场景要上千张
'''
key_word:图片名称关键词
img_num:爬取图片轮数,1轮30张
'''
import json
import math
import os.path
import sys
import time
import requests
def catch_img(key_word,rounds): #关键字、爬取轮次,一轮30张
if not os.path.exists(key_word):
os.mkdir(key_word)
for count in range(rounds):
print(str(count)+"轮")
pn=count*30
url = "https://images.baidu.com/search/acjson?tn=resultjson_com&logid=11514788725054802565&ipn=rj&ct=201326592&is=&fp=result&fr=&word="+str(key_word)+"&queryWord="+str(key_word)+"&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=&expermode=&nojc=&isAsync=&pn="+str(pn)+"&rn=30&gsm=1e&1717479169689="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
res = requests.get(url, headers=headers)
if len(res.json()["data"])==1:
print("无图片可获取了")
sys.exit()
json_data=res.json()["data"] #获取json数据
json_str= json.dumps(json_data, indent=2) #json转json字符串
list_data=json.loads(json_str) #json字符串转list/dict
for obj in list_data:
try:
pic_url=obj["thumbURL"] #图像链接
except:
continue
r = requests.get(pic_url,headers=headers)
with open(str(key_word)+"\\"+str(time.time())+".jpg", mode="wb") as f:
f.write(r.content)
if __name__ == '__main__':
catch_img("桥梁地基冲刷照片",20)1. 标注数据集
1.1 创建文件目录
- 在
yolov5目录下创建yoloData目录,随后在yoloData目录下建立以下两个子目录:txtData:用于存放标注的标签文件(.txt 格式)picData:用于存放需要标注的图片文件
1.2 准备图片文件
- 将需要标注的图片放入
yoloData/picData目录中。
1.3 启动 labelImg 并设置参数
- 启动
labelImg。 - 点击打开目录,选择
yoloData/picData目录。 - 将左边的存储格式由默认的 PascalVOC 改为 YOLO。
- 点击文件 -> 改变存放目录,将标签的存放目录设置为
yoloData/txtData。 - 如图一定要按步骤来,不然可能会闪退
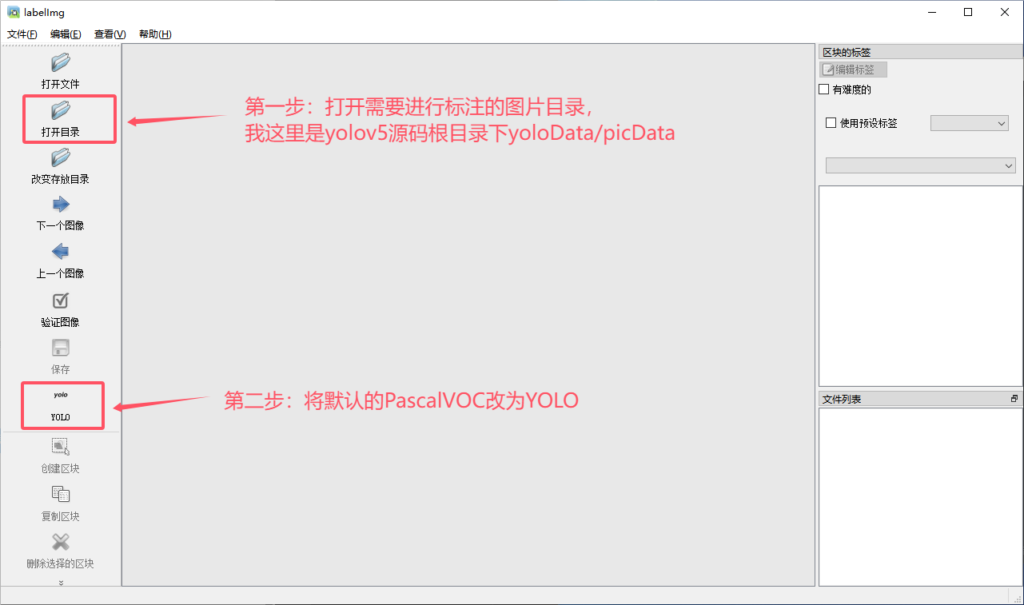
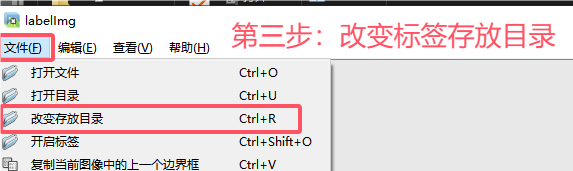
1.4 开始标注
- 例如,如果你要标注图片中的桥墩损坏部位,按下
W键调出标注十字架,框选出损坏部位并保存,随后输入自定义的缺陷英文名称(如error_pos),然后继续标注下一张图片。 - 可以在同一张图片中标记多个部位。
- 标记第一张图片时会提示你先命名标记的类别,类别可以自定义(我这里设置为
error_pos)。
1.5 常用快捷键
- W:调出标注十字架
- A:切换到上一张图片
- D:切换到下一张图片
- Del:删除标注框
- Ctrl+U:选择标注的图片文件夹
- Ctrl+R:选择标注好的标签文件夹
1.6 检查标注结果
- 标记完后,检查
txtData目录中的标签文件(.txt)与picData目录中的图片文件名称是否对应,数量是否一致。
2. 划分数据集
在我们创建的yoloData目录下建立SplitData.py文件,加入如下代码然后执行会将txt标签和图篇按照8:1:1的比例划分为训练集、测试集、验证集到新的目录
import os
import shutil
import random
# 设置随机种子
random.seed(0)
def split_data(file_path, xml_path, new_file_path, train_rate, val_rate, test_rate):
'''====1.将数据集打乱===='''
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
# 将两个文件通过zip()函数绑定。
data = list(zip(each_class_image, each_class_label))
# 计算总长度
total = len(each_class_image)
# random.shuffle()函数打乱顺序
random.shuffle(data)
# 再将两个列表解绑
each_class_image, each_class_label = zip(*data)
'''====2.分别获取train、val、test这三个文件夹对应的图片和标签===='''
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
'''====3.设置相应的路径保存格式,将图片和标签对应保存下来===='''
# train
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
# val
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
# test
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
if __name__ == '__main__':
file_path = r"D:\A03PyThonProjects395\yolov5-master\yoloData\picData" #原图片路径
txt_path = r"D:\A03PyThonProjects395\yolov5-master\yoloData\txtData" #.txt标签路径
new_file_path = r"D:\A03PyThonProjects395\yolov5-master\yoloData\splitData" #划分后的目录
# 设置划分比例
split_data(file_path, txt_path, new_file_path, train_rate=0.8, val_rate=0.1, test_rate=0.1)3. 训练模型
1修改VOC.yaml:
将data目录下的VOC.yaml文件修改内容为如下: download及其以下的配置不用改动,download以上的全部改掉为如下
train: D:\A03PyThonProjects395\yolov5-master\yoloData\splitData\train #训练集绝对路径
val: D:\A03PyThonProjects395\yolov5-master\yoloData\splitData\val #验证集绝对路径
# Classes
names: ['error_pos'] #这个error_pos是我们标记数据时设置的勾画物体名称,若忘记了可以在txtData目录下的classes.txt看到
nc: 1 #这里填写1的原因:在我们标记数据集之前,我们清空了labelImg-master\data\predefined_classes.txt,然后标记数据时,添加了类别名为error_pos,yolov5在索引我们的类别时是从0开始的,我们的类别只有一个error_pos,所以这里填1,如果不太明白可以简单理解为多少个类别就填几
# Download script/URL (optional) ---------------------------------------------------------------------------------------
download: |..........download这块及其一下都不用改动......2.修改模型配置文件:
因为我们这里使用的预训练权重是yolov5x.pt,因此将models目录下的yolov5x.yaml文件改动如下:
nc: 1 # number of classes ,只需要把这个改为1就行了3.正式训练模型前的配置
训练模型是用train.py ,在训练之前,先定位到train.py的parse_opt方法,可以看到有很多训练参数,这里解释下可能需要修改的参数:
--weights:加载的权重文件路径,默认是根目录下的yolov5s.pt,我用的是yolov5x.pt,因此要改为yolov5x.pt
--cfg:这个要指定我们的models/yolov5x.yaml文件
--data:是指定数据集配置文件,我们这里填data/VOC.yaml
--epochs:表示训练的轮次,要训练300轮就改成300
--batch-size:表示每一批训练的批次大小,这个大小根据GPU或CPU指定,一般为16,32,64,128,256等
--workers:表示使用的核心数量,默认为8
--device:选项有0、1、2、3、cpu,0、1、2、3表示选择第几个GPU,我这里就一个显卡,填0就行了
以上是可能需要修改的参数,下面列出所有参数解释:
opt参数解析:
• cfg: 模型配置文件,网络结构
• data: 数据集配置文件,数据集路径,类名等
• hyp: 超参数文件
• epochs: 训练总轮次
• batch-size: 批次大小
• img-size: 输入图片分辨率大小
• rect: 是否采用矩形训练,默认False
• resume: 接着打断训练上次的结果接着训练
• nosave: 不保存模型,默认False
• notest: 不进行test,默认False
• noautoanchor: 不自动调整anchor,默认False
• evolve: 是否进行超参数进化,默认False
• bucket: 谷歌云盘bucket,一般不会用到
• cache-images: 是否提前缓存图片到内存,以加快训练速度,默认False
• weights: 加载的权重文件
• name: 数据集名字,如果设置:results.txt to results_name.txt,默认无
• device: 训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
• multi-scale: 是否进行多尺度训练,默认False
• single-cls: 数据集是否只有一个类别,默认False
• adam: 是否使用adam优化器
• sync-bn: 是否使用跨卡同步BN,在DDP模式使用
• local_rank: gpu编号
• logdir: 存放日志的目录
• workers: dataloader的最大worker数量最后我修改过的parse_opt结果如下:
parser.add_argument("--weights", type=str, default=ROOT / "yolov5x.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="models/yolov5x.yaml", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "data/VOC.yaml", help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
parser.add_argument("--epochs", type=int, default=100, help="total training epochs")
parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")
parser.add_argument("--device", default="0", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")4.开始训练:
参数配置完后执行train.py开始训练
如图表示在训练了,不愧是GPU,3秒一轮,CPU训练非常慢

5.查询训练结果
训练完后结果会保存在runs的tarin文件里,训练出的最优模型它命名为best.pt,如图
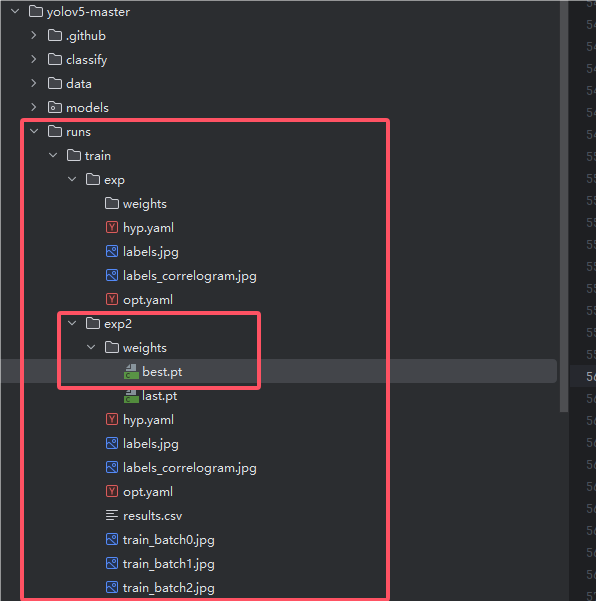
4.验证模型
验证模型靠的是根目录下的val.py文件,进入val.py文件,定位到parse_opt方法,这里要改动几个参数为我们自己的:
--data:指定验证集的配置文件,即我们data下的VOC.yaml
--weights:指定模型权重文件,选择我们训练模型后runs下最好的权重文件best.pt,我这里最好的是exp2目录下的best.pt最后我改动的参数为如下(就改了两个位置):
parser.add_argument("--data", type=str, default=ROOT / "data/VOC.yaml", help="dataset.yaml path")
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "runs/train/exp2/weights/best.pt", help="model path(s)")然后运行val.py进行验证,运行后,会在runs目录下生成val的目录,里面就是验证的结果,可能你现在还看不懂,总之可以简单理解为这些图表表示了模型的准确率,当然我这里为了快速教学,用了24张图片肯定是不够的,如图
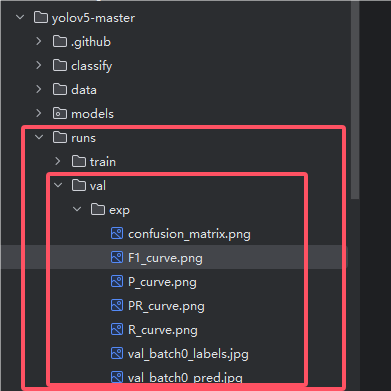
5. 用模型检测其他图片
当我们用val.py验证后通过图标查看识别率还不错的话,就可以开始用detect.py进行检测看看效果了
先在根目录创建一个otherPics目录,然后随便网上找几张和你模型需要识别相关的图片,比如我是用来识别桥梁地基冲刷缺陷的,我就找这类图,然后放入otherPics目录
来到detect.py文件下,同样是定位到parse_opt方法,要改动几个参数,这里同验证模型改参数一样:
--weights:指定为自己的最好的训练模型,即runs/train下最好的best.pt
--source:指定要测试的图片的目录,我这里是otherPics
--data:指定数据集配置文件,即我们的data/VOC.yaml
--conf-thres:指定置信度,越小则越信任识别的内容,当然也就越不准确,默认0.25,我这里因为用的图片少,所以调的很低最终我配置为如下
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "runs/train/exp2/weights/best.pt", help="model path or triton URL")
parser.add_argument("--source", type=str, default=ROOT / "otherPics", help="file/dir/URL/glob/screen/0(webcam)")
parser.add_argument("--data", type=str, default=ROOT / "data/VOC.yaml", help="(optional) dataset.yaml path")
parser.add_argument("--conf-thres", type=float, default=0.07, help="confidence threshold")然后运行detect.py,执行完成后会在runs下生成detect目录,目录内便是识别后的图片,如图
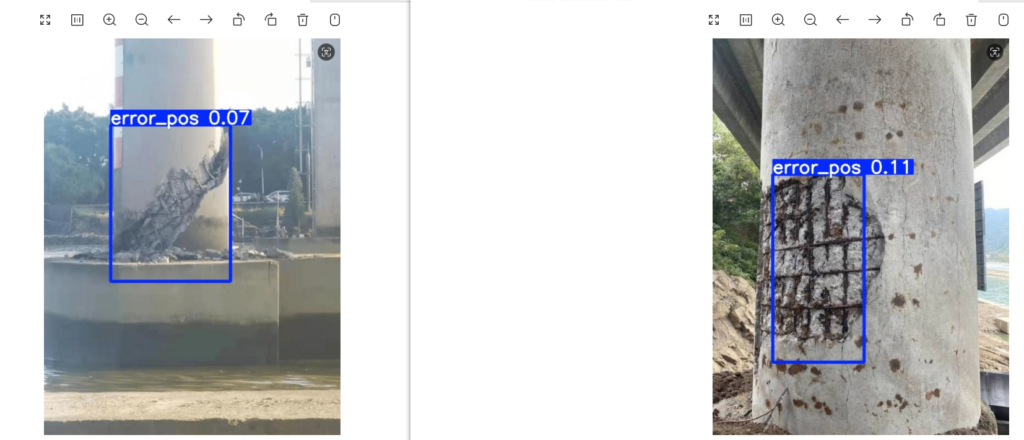
至此,幽络源的图像识别教程结束
补充:如有需要,可以自行将detect改为传入照片然后就返回识别后的信息。
大牛交流QQ群:307531422