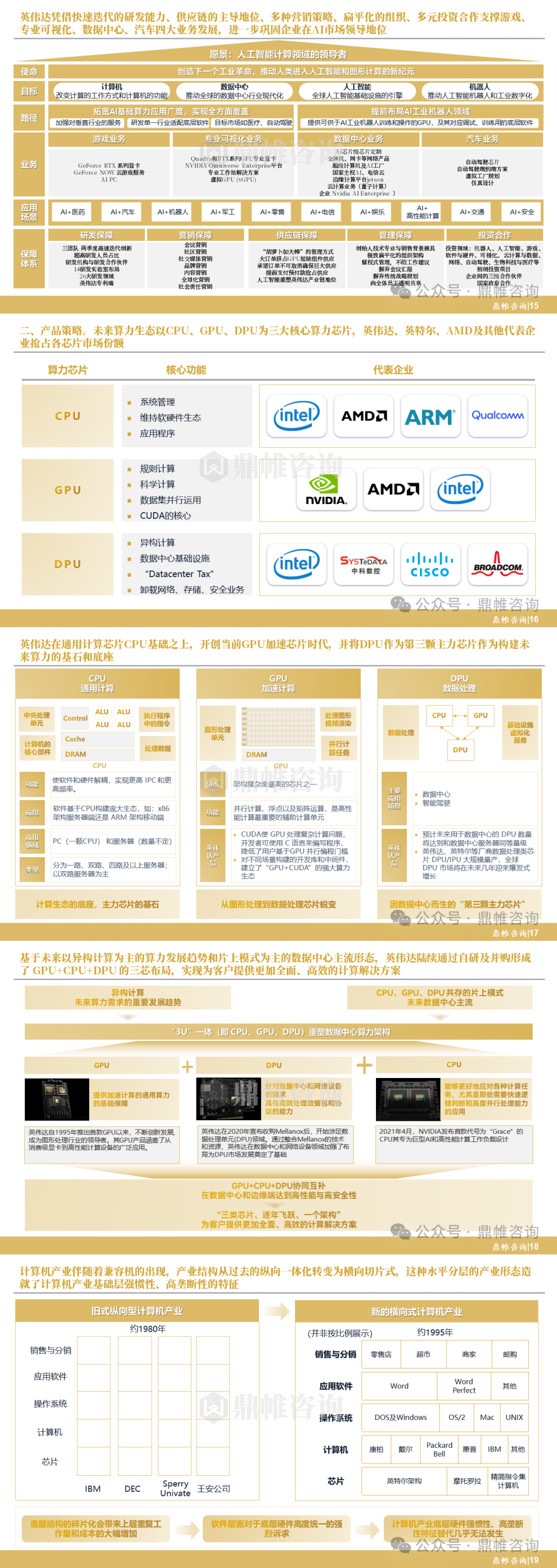
文章目录
- 1. 定义
- 2. 算法步骤
- 3. 演示
- 3.1 动态演示1
- 3.2 动态演示2
- 3.3 图片演示1
- 3.4 图片演示2
- 4. 性质
- 5. 算法分析
- 6. 代码实现
- C语言
- Python
- Java
- C++
- Go
- 结语
1. 定义
桶排序(英文:Bucket sort)是计数排序的升级版,适用于待排序数据值域较大但分布比较均匀的情况。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。
为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
2. 算法步骤
桶排序按下列步骤进行:
-
设置一个定量的数组当作空桶;
-
遍历输入数据,并且把数据一个一个放到对应的桶里去;
-
对每个不是空的桶进行排序;
-
从不是空的桶里把排好序的数据拼接起来。
3. 演示
3.1 动态演示1

3.2 动态演示2

3.3 图片演示1
元素分布在桶中:

然后,元素在每个桶中排序:

3.4 图片演示2

4. 性质
稳定性:
如果使用稳定的内层排序,并且将元素插入桶中时不改变元素间的相对顺序,那么桶排序就是一种稳定的排序算法。
由于每块元素不多,一般使用插入排序。此时桶排序是一种稳定的排序算法。
空间复杂度:
桶排序算法排序过程中新建了一个桶和一个输出数组,所以算法的空间复杂度是 O ( N + M ) O(N+M) O(N+M)。
时间复杂度:
桶排序的平均时间复杂度为 O ( n + n 2 k + k ) O(n+{n^2 \over k}+k) O(n+kn2+k)(将值域平均分成n块 + 排序 + 重新合并元素),当k≈n时为 O ( n ) O(n) O(n)。
桶排序的最坏时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
什么时候最快:
当输入的数据可以均匀的分配到每一个桶中。
什么时候最慢:
当输入的数据被分配到了同一个桶中。
5. 算法分析
桶排序最好情况下使用线性时间 O ( n ) O(n) O(n),桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为 O ( n ) O(n) O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。
6. 代码实现
C语言
void RadixSort(int* arr, int n)
{
//max为数组中最大最小值
int max = arr[0];
int min = arr[0];
int base = 1;
//找出数组中的最大值
for (int i = 0; i < n; i++)
{
if (arr[i] > max)
{
max = arr[i];
}
if (arr[i] < min)
{
min = arr[i];
}
}
//循环结束max就是数组最大最小值
//循环将数组的元素全部变为正数
//所有元素加上最小值的绝对值
for (int i = 0; i < n; i++)
{
arr[i] += abs(min);
}
//临时存放数组元素的空间
int* tmp = (int*)malloc(sizeof(int)*n);
//循环次数为最大数的位数
while (max / base > 0)
{
//定义十个桶,桶里面装的不是数据本身,而是每一轮排序对应(十、白、千...)位的个数
//统计每个桶里面装几个数
int bucket[10] = { 0 };
for (int i = 0; i < n; i++)
{
//arr[i] / base % 10可以取到个位、十位、百位对应的数字
bucket[arr[i] / base % 10]++;
}
//循环结束就已经统计好了本轮每个桶里面应该装几个数
//将桶里面的元素依次累加起来,就可以知道元素存放在临时数组中的位置
for (int i = 1; i < 10; i++)
{
bucket[i] += bucket[i - 1];
}
//循环结束现在桶中就存放的是每个元素应该存放到临时数组的位置
//开始放数到临时数组tmp
for (int i = n - 1; i >= 0; i--)
{
tmp[bucket[arr[i] / base % 10] - 1] = arr[i];
bucket[arr[i] / base % 10]--;
}
//不能从前往后放,因为这样会导致十位排好了个位又乱了,百位排好了十位又乱了
/*for (int i = 0; i < n; i++)
{
tmp[bucket[arr[i] / base % 10] - 1] = arr[i];
bucket[arr[i] / base % 10]--;
}*/
//把临时数组里面的数拷贝回去
for (int i = 0; i < n; i++)
{
arr[i] = tmp[i];
}
base *= 10;
}
free(tmp);
//还原原数组
for (int i = 0; i < n; i++)
{
arr[i] -= abs(min);
}
}
Python
N = 100010
w = n = 0
a = [0] * N
bucket = [[] for i in range(N)]
def insertion_sort(A):
for i in range(1, len(A)):
key = A[i]
j = i - 1
while j >= 0 and A[j] > key:
A[j + 1] = A[j]
j -= 1
A[j + 1] = key
def bucket_sort():
bucket_size = int(w / n + 1)
for i in range(0, n):
bucket[i].clear()
for i in range(1, n + 1):
bucket[int(a[i] / bucket_size)].append(a[i])
p = 0
for i in range(0, n):
insertion_sort(bucket[i])
for j in range(0, len(bucket[i])):
a[p] = bucket[i][j]
p += 1
Java
public class BucketSort extends BaseSort {
public static void main(String[] args) {
BucketSort sort = new BucketSort();
sort.printNums();
}
@Override
protected void sort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
bucketSort(nums);
}
public void bucketSort(int[] nums) {
if (nums == null || nums.length < 2) {
return;
}
//找出最大值,最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int num : nums) {
min = Math.min(min, num);
max = Math.max(max, num);
}
int length = nums.length;
//桶的数量
int bucketCount = (max - min) / length + 1;
int[][] bucketArrays = new int[bucketCount][];
//遍历数组,放入桶内
for (int i = 0; i < length; i++) {
//找到桶的下标
int index = (nums[i] - min) / length;
//添加到指定下标的桶里,并且使用插入排序排序
bucketArrays[index] = insertSortArrays(bucketArrays[index], nums[i]);
}
int k = 0;
//合并全部桶的
for (int[] bucketArray : bucketArrays) {
if (bucketArray == null || bucketArray.length == 0) {
continue;
}
for (int i : bucketArray) {
//把值放回到nums数组中
nums[k++] = i;
}
}
}
//每个桶使用插入排序进行排序
private int[] insertSortArrays(int[] arr, int num) {
if (arr == null || arr.length == 0) {
return new int[]{num};
}
//创建一个temp数组,长度是arr数组的长度+1
int[] temp = new int[arr.length + 1];
//把传进来的arr数组,复制到temp数组
for (int i = 0; i < arr.length; i++) {
temp[i] = arr[i];
}
//找到一个位置,插入,形成新的有序的数组
int i;
for (i = temp.length - 2; i >= 0 && temp[i] > num; i--) {
temp[i + 1] = temp[i];
}
//插入需要添加的值
temp[i + 1] = num;
//返回
return temp;
}
}
C++
#include<iterator>
#include<iostream>
#include<vector>
using namespace std;
const int BUCKET_NUM = 10;
struct ListNode{
explicit ListNode(int i=0):mData(i),mNext(NULL){}
ListNode* mNext;
int mData;
};
ListNode* insert(ListNode* head,int val){
ListNode dummyNode;
ListNode *newNode = new ListNode(val);
ListNode *pre,*curr;
dummyNode.mNext = head;
pre = &dummyNode;
curr = head;
while(NULL!=curr && curr->mData<=val){
pre = curr;
curr = curr->mNext;
}
newNode->mNext = curr;
pre->mNext = newNode;
return dummyNode.mNext;
}
ListNode* Merge(ListNode *head1,ListNode *head2){
ListNode dummyNode;
ListNode *dummy = &dummyNode;
while(NULL!=head1 && NULL!=head2){
if(head1->mData <= head2->mData){
dummy->mNext = head1;
head1 = head1->mNext;
}else{
dummy->mNext = head2;
head2 = head2->mNext;
}
dummy = dummy->mNext;
}
if(NULL!=head1) dummy->mNext = head1;
if(NULL!=head2) dummy->mNext = head2;
return dummyNode.mNext;
}
void BucketSort(int n,int arr[]){
vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));
for(int i=0;i<n;++i){
int index = arr[i]/BUCKET_NUM;
ListNode *head = buckets.at(index);
buckets.at(index) = insert(head,arr[i]);
}
ListNode *head = buckets.at(0);
for(int i=1;i<BUCKET_NUM;++i){
head = Merge(head,buckets.at(i));
}
for(int i=0;i<n;++i){
arr[i] = head->mData;
head = head->mNext;
}
}
Go
package main
import (
"fmt"
"container/list"
)
func bucketSort(theArray []int,num int){
var theSort [99]int
for i:=0;i< len(theArray);i++{
theSort[10]=1
if theSort[theArray[i]] !=0{
theSort[theArray[i]] = theSort[theArray[i]]+1
}else{
theSort[theArray[i]] = 1
}
}
l:=list.New()
for j:=0;j<len(theSort);j++{
if theSort[j]==0{
//panic("error test.....")
}else{
for k:=0;k<theSort[j];k++{
l.PushBack(j)
}
}
}
for e := l.Front(); e != nil; e = e.Next() {
fmt.Print(e.Value, " ")
}
}
func main() {
var theArray = []int{10, 1, 18, 30, 23, 12, 7, 5, 18, 17}
fmt.Print("排序前")
fmt.Println(theArray)
fmt.Print("排序后")
bucketSort(theArray,11)
}
结语
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下。
也可以点点关注,避免以后找不到我哦!
Crossoads主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是作者前进的动力!
带你初步了解排序算法:https://blog.csdn.net/2301_80191662/article/details/142211265
直接插入排序:https://blog.csdn.net/2301_80191662/article/details/142300973
希尔排序:https://blog.csdn.net/2301_80191662/article/details/142302553
直接选择排序:https://blog.csdn.net/2301_80191662/article/details/142312028
堆排序:https://blog.csdn.net/2301_80191662/article/details/142312338
冒泡排序:https://blog.csdn.net/2301_80191662/article/details/142324131
快速排序:https://blog.csdn.net/2301_80191662/article/details/142324307
归并排序:https://blog.csdn.net/2301_80191662/article/details/142350640
计数排序:https://blog.csdn.net/2301_80191662/article/details/142350741
桶排序:https://blog.csdn.net/2301_80191662/article/details/142375338
基数排序:https://blog.csdn.net/2301_80191662/article/details/142375592
十大经典排序算法总结与分析:https://blog.csdn.net/2301_80191662/article/details/142211564