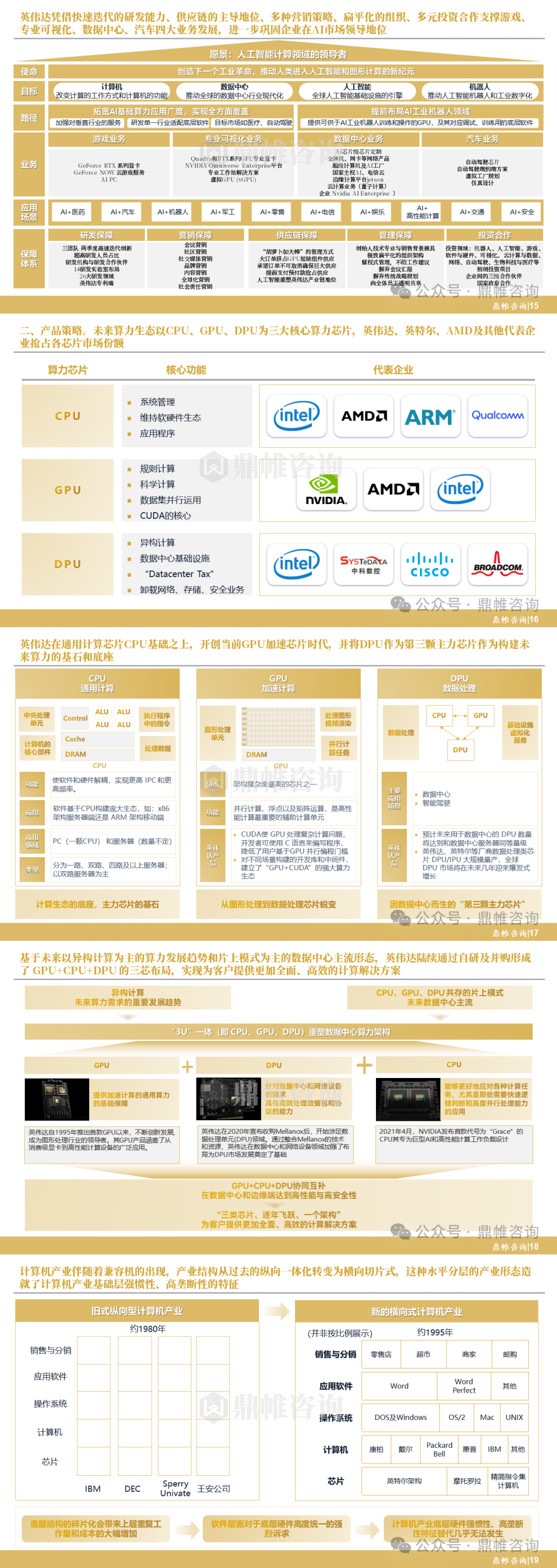
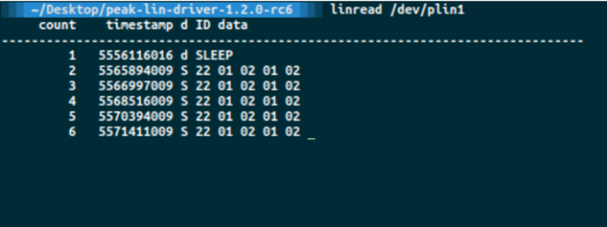
案例一:Python-WEB 爬虫库&数据解析库
这里开发的内容不做过多描述,贴上自己写的代码
爬取数据
要爬取p标签,利用Beautyfulsoup模块
import requests,time
from bs4 import BeautifulSoup
#url="https://src.sjtu.edu.cn/rank/firm/0/?page=2"
def get_content():
for i in range (30,40):
url="http://192.168.172.132/cms/show.php?id=%s"%i
print(url+'\n')
try:
response = requests.get(url)
markup = response.text
# print(markup)
soup=BeautifulSoup(markup, "lxml")
#divs = soup.find_all('div',attrs={'class','nav'})
ps = soup.find_all('p')
# print(ps)
for p in ps:
print(p.string+'\n')
with open("examples.txt",'a+',encoding='utf-8') as file:
file.write(p.string+'\n')
except Exception as e:
time.sleep(1)
pass
if __name__ == "__main__":
get_content()运行结果,把所有p标签的文字都输入到了文件中
案例二:Python-EDU_SRC-目标列表爬取
fofa挖掘数据,这里代码还可以优化,如果要挖掘更多数据可以带上cookie去访问
这里fofa搜索后面的参数就是的就是base64的编码值,所以可以直接搜好以后用url地址去跑
import requests
from bs4 import BeautifulSoup
#获取页码
def get_pages():
pages = soup.find('span',attrs={"class":"hsxa-highlight-color"})
#print(pages.get_text().strip())
page = int(int(pages.get_text().strip())/10)
page = page + 1
print("一共有%s页"%page)
#获取网页(title)名
def get_titles():
ps = soup.find_all('p',attrs={"class":"el-tooltip hsxa-one-line item"})
for p in ps:
print(p.string.strip())
#获取ip名
def get_ips():
ips = soup.find_all('span',attrs={"class":"hsxa-host"})
#print(ips)
for ip in ips:
print(ip.a.get_text().strip())
#获取指纹
def get_serves():
servers = soup.find_all('span',attrs={"class":"el-tooltip hsxa-list-span hsxa-list-span-sm"})
#print(servers)
for server in servers:
print(server.get_text().strip())
if __name__ == "__main__":
url = input("请输入fofa的url地址:")
response = requests.get(url)
markup = response.text
soup = BeautifulSoup(markup,"lxml")
while(True):
math = int(input("\n"+"获取页码输入1"+"\n"+"获取title输入2"+"\n"+"获取ip输入3"+"\n"+"获取指纹输入4"+"\n"+"退出请输入5"+"\n"))
if math == 1:
get_pages()
if math == 2:
get_titles()
if math == 3:
get_ips()
if math == 4:
get_serves()
if math == 5:
break运行结果





案例三: Python-FOFA_API-资产信息爬取
这里fafo自带有api接口可以利用去访问,不过呢这里需要fofa会员或者有F点才能够搜索,这里只能先贴上代码,没办法复现

import requests
import base64
#https://fofa.info/api/v1/search/all?email=your_email&key=your_key&qbase64=dGl0bGU9ImJpbmci
def get_fofa_data(email,apikey):
for eduname in open('eduname.txt',encoding='utf-8'):
e=eduname.strip()
search='"%s" && country="CN" && title=="Error 404--Not Found"'%e
b=base64.b64encode(search.encode('utf-8'))
b=b.decode('utf-8')
url='https://fofa.info/api/v1/search/all?email=%s&key=%s&qbase64=%s'%(email,apikey,b)
s=requests.get(url).json()
print('查询->'+eduname)
print(url)
if s['size'] != 0:
print(eduname+'有数据啦!')
for ip in s['results']:
print(ip[0])
else:
print('没有数据')
if __name__ == '__main__':
email='471656814@qq.com'
apikey='0fccc926c6d0c4922cbdc620659b9a42'
get_fofa_data(email,apikey)