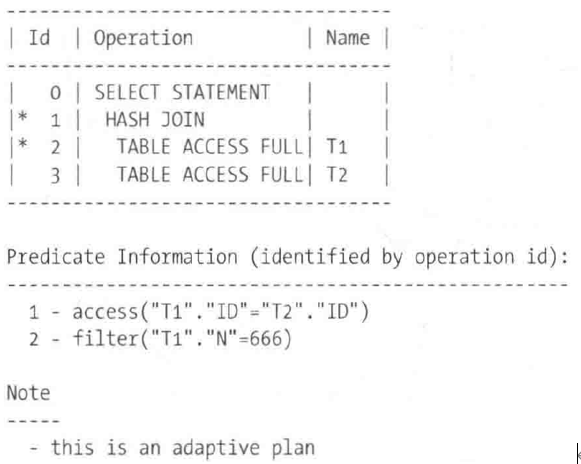
知识图谱是由实体(节点)和关系( 不同类型的边) 组成的多关系图。作为一种非常重要又特殊的图结构数据,知识图谱被广泛应用在人工智能和自然语言处理领域,从语义解析、命名实体消歧到问答系统、推荐系统中都可以看到来自知识图谱的技术推动。本质上,可以将知识图谱看作一种异构网络图,因此很多异构图神经网络可以直接应用在知识图谱上作为表示学习的方法。由于知识图谱的特殊性,它又有很多原创的嵌入方法,并且这些知识图谱的嵌入方法又反过来推动了新的图神经网络结构的研究。本章将探讨知识图谱上的经典嵌入方法及图神经网络在知识图谱上的应用和改进。
1 .知识图谱嵌入
一般来讲,知识图谱由一系列三元组的事实(h,r,t)构成,每个事实中包含两个实体 h,t和它们之间的关系r。这些三元组合在一起,就构成了一个图 KG=(h,r,t)。 在这个图中,实体表示节点,实体间的关系表示边。
知识图谱的表示学习,或者说知识图谱嵌入,是将实体和关系映射到一个低维连续空间上。也就是说,类似于普通的图嵌入,知识图谱嵌入旨在学习实体和关系的向量化表示。知识图谱嵌入的关键是合理定义知识图谱中关于事实(三元组(h,r,t))的打分函数fr(h,t) 。 通常,当事实(h,r,t) 成立时,我们期望最大化fr(h,t) 。 我们可通过最大化

来学习所有实体及关系的向量化表示,其中O表示知识图谱中所有三元组的集合。
知识图谱并不能覆盖所有的知识,因此其核心任务之一就是利用已有的知识对未知的部分进行推理和补全KGC。这些都可以通过知识图谱嵌入的方法来解决。当我们得到了所有实体和关系的嵌入表示后,可以用定义的打分函数评价每个可能的三元组,以得到缺失的实体或者关系。假设在一个知识图谱上有一些缺失的关系,如在实体Forest Gump和 English之间存在某种联系,但在构建知识图谱时我们并没有把它囊括进来,这时可以通过知识图谱嵌入的方法对所有已知的实体和关系进行表示学习,然后用它们预测 Forest Gump 和 English之间未知的关系。除了补全关系,知识图谱补全也包含对缺失实体的预测,如上例中,如果我们已知Forest Gump和Language, 则可以推测出缺失的实体应该是 English。
传统的知识图谱推理一般只推测已经出现过的实体之间的关系,称之为转导推理或者直推式学习,而Teru等人提出了另一种推理任务,他们想将推理一般化到未见过的实体,这种新任务叫作归纳推理。
除了知识图谱的推理和补全,在知识图谱上我们还可以:
(1)对三元组分类,判断三元组事实(h,r,t) 是否为真。
(2)对实体分类,将实体归类为不同的语义类别。
(3)实体判别,判断两个实体是否为同一个目标。
知识图谱嵌入还可以辅助完成很多下游任务,包括关系抽取、问答 系统、推荐系统等。
随着对知识图谱相关研究的深入,出现了基于不同思路的知识图谱嵌入方法,这些方法定义了不同的嵌入空间或者不同的损失函数。将它们分为距离变换模型、语义匹配模型和知识图谱上的图神经网络模型。
2.距离变换模型
2.1 TransE模型
Mikolov 等人发现,利用该模型后,词向量空间存在平移不变现 象。受到该平移不变现象的启发,Border 等人提出了TransE模型,将知识库中的关系看作实体间的某种平移向量。对于每个事实三元组(h,r,t),假设它们分别有向量表示h,r,t 。TransE模型将实体和关系表示在同一空间中,把关系向量r 看作头实体向量h 和尾实体向量t 之间的平移,即h+r≈t。我们也可以将r 看作从h 到 t 的翻译,因此TransE模型也被称为翻译模型。它的打分函数可以定义为h+r与t距离的负, 即
fr(h,t)=-||h+r-t||L1/L2
![]()
2.2TransH模型
虽然TransE 模型简单高效,计算复杂度低,在大规模稀疏知识库上具有 较好的性能与可扩展性,但是它不能解决多对一和一对多关系的问题。以多对一关系为例,固定r 和t,TransE模型为了满足三角闭包关系,训练出来的头节点的向量会很相似,但实体在涉及不同关系时应该具有不同的表示形式。为了解决TransE模型在处理一对多、多对一、多对多复杂关系时的局限性 ,TransH模型提出让一个实体在不同的关系下拥有不同的表示。对于关系r, TransH模型同时使用平移向量r 和超平面的法向量 wr 来表示它。对于一个 三元组(h,r,t),TransH模型先将头实体向量h和尾实体向量t 投影到关系r对应的超平面上,分别得到h和 t
, 再对投影用的TransE模型进行训练和学习。

其中,h=h-
hwr。需要注意的是,关系r 可能存在无限个超平面(在二维空间中,超平面是一个直线;在三维空间中,超平面是一个平面;而在更高维度的空间中,超平面则是一个更高维度的“平面”,它将空间分割成两个部分),TransH 模型简单地令r与wr近似正交,来选取某一个超平面。
2.3TransR模型
TransR模型与TransH模型的思想类似,它引入的是关系特定的语义空间, 而不是超平面。虽然TransH 模型使每个实体在不同关系下拥有了不同的表示, 但是它仍然假设实体和关系处于相同的语义空间中,这在一定程度上限制了TransH模型的表示能力。TransR 模型则将一个实体看作多种属性的综合体,不同的关系拥有不同的语义空间并关注实体的不同属性。对于每一个关系r,TransR模型定义投影矩阵Mr, 将实体向量h和t从实体空间投影到关系r 对应的子空间:
h⊥=Mrh ,t⊥=Mrt,然后 ,TransR模型利用和TransH模型相同的翻译关系h1+r≈t1三元组的评分函数:
![]()
2.4TransD模型
虽然 TransR模型较TransE模型和TransH模型有显著的改进,但它仍然有如下缺点。
(1)在同一个关系下,头实体和尾实体共享相同的投影矩阵。然而,一个关系的头实体和尾实体的类型或属性可能差异巨大。例如,对于三元组(姜文, 出演,让子弹飞),“姜文”和“让子弹飞”的类型完全不同,一个是人物, 一个是电影。
(2)从实体空间到关系空间的投影是实体和关系之间的交互过程,因此TransR模型让投影矩阵仅与关系有关是不合理的。
( 3 ) 与TransE模型和TransH模型相比,TransR模型引入了空间投影,使得TransR模型的参数量急剧增加,计算复杂度大大提高。
为了解决这些问题,TransD模型设置了两个分别将头实体h和尾实体t投影到关系空间的投影矩阵Mr1 和 Mr2。
h⊥=Mr1h ,t⊥=Mr2t
其中,Mr₁由一个对应关系的向量wr 和一个对应头实体的向量wh组成, Mr₂ 则由wr 和一个对应尾实体的向量wt组成:Mr₁=wr+I,Mr2=
+I 这样投影矩阵就不仅和关系有关,还和被投影的实体有关系。另外, 通过两个向量外积的定义方式,TransD模型可以使投影矩阵的参数变少,从而降低模型的复杂度。
3 .语义匹配模型
语义匹配模型利用基于相似性的评分函数,通过匹配实体的潜在语义和向量空间表示中包含的关系来度量事实的可信性。
3.1RESCAL模型
RESCAL模型又称双线性模型,它将每个关系r都表示为一个矩阵Mr, 该矩阵对潜在因素之间的成对交互作用进行了建模。所谓双线性模型,指的是它的得分函数是一个双线性函数:

这个得分函数的值描述了h和t的所有分量之间的成对相互作用。
3.2 DistMult模型
DistMult模型是RESCAL模型的简化版本,它通过将Mr限制为对角矩阵来减少参数的数量。对于每一个关系r,它要求Mr=diag(r), 其中r是对应关系r的一个向量。它的评分函数与RESCAL相同,不同的是,由于Mr是一个对角阵,它只捕获h和t在相同维度上的分量之间的交互作用。也就是说,在RESCAL中的双线性函数式中,i≠j 的分量消失了,评分函数可以重写为 :
![]()
这样,DistMult模型可以将每一个关系的参数数量减少至O(d)。然而,DistMult 模型只能处理对称的关系,因为对于任意的h和t ,diag(r)t=
diag(r)h都是成立的。显然,在一般的知识图谱上,关系并不总是对称的,所以DistMult模型有很大的局限性。
3.3HolE模型
HolE模型将RESCAL模型的表达能力与DistMult模型的效率和简单性进行了结合。它把实体和关系都表示为同一个向量空间中的向量。给定一个事实 (h,r,t),先使用循环相关操作*将实体对(h,t)表示成:

然后将实体对的表示与关系的表示进行匹配,得到一个得分函数:
fr(h,t)=(h*t) ,循环相关运算压缩了h 和t 之间的相互作用,减少模型参数(每个关系只要 O(d) 个参数)。另外,循环相关运算符是不可交换的。因此,HolE 模型可以像RESCAL模型一样对非对称关系建模。
3.4 语义匹配能量模型
语义匹配能量模型也是对事实中的实体和关系进行语义匹配。不同的是,它使用一个更复杂的神经网络架构来实现。 首先,在输入层,将三元组(h,r,t)的每个元素映射为嵌入向量h,r,t;然后, 在隐含层,将关系向量r 和头实体向量h 组合,得到一个分数 gu(r,h)。同时,将关系向量r 和尾实体向量t组合,得到gv(r,t)。最终,将这两个分数组合, 得到最终的匹配分数,如

3.5神经张量网络模型
神经张量网络模型是另一种经典的神经网络语义匹配模型。在这个模型里,r不再仅用一个向量或矩阵来表示,而是引入了一个对应的张量Sr及对应的矩阵,
, 分别表示两种匹配关系:线性和双线性。它的得分函数是:

其中 ,b表示一个偏差的向量参数。神经张量网络模型是一个最具表达力的模 型,几乎涵盖了所有的匹配关系,但是它的参数过多,导致不能有效地处理大 型的知识图谱。
3.6 ConvE 模型
ConvE模型采用一个2D卷积得到实体和关系的匹配分数:

它先把头实体h和关系r 重塑成二维矩阵Mh和Mr, 然后利用卷积(*为卷积操作,为卷积核)和全连接层(参数为W)获取交互信息,最后与尾实体向量t相乘。它不像神经张量网络模型那样复杂,又可以叠加多层以增强表达力,在复杂度和表达力之间取得了很好的平衡。它很容易训练,可以被应用在大规模的知识图谱中。