跨域训练评估BEVal:自动驾驶 BEV 的跨数据集评估框架
Abstract
当前在自动驾驶中的鸟瞰图语义分割研究主要集中在使用单个数据集(通常是nuScenes数据集)优化神经网络模型。这种做法导致了高度专业化的模型,可能在面对不同环境或传感器设置时表现不佳,这被称为域偏移问题。本文对最先进的鸟瞰图(BEV)分割模型进行了全面的跨数据集评估,以评估它们在不同训练和测试数据集、设置以及语义类别下的表现。我们探讨了不同传感器(如摄像头和LiDAR)对模型泛化能力的影响。此外,我们还进行了多数据集训练实验,结果表明相比单数据集训练,模型的BEV分割性能有所提高。我们的工作填补了在跨数据集验证下评估BEV分割模型的空白,研究结果强调了提升模型泛化性和适应性的重要性,以确保在自动驾驶应用中实现更加稳健和可靠的BEV分割方法。
代码获取:https://github.com/manueldiaz96/beval/
欢迎加入自动驾驶实战群
Introduction
近来,鸟瞰图(BEV)表示方法在自动驾驶社区中因其在场景理解中的重要作用而获得了广泛关注。与传统的图像或点云分割不同,BEV将多个传感器模态的信息整合为一个统一的空间,提供了如物体大小不变性和减少遮挡等优势。
生成语义BEV栅格表示面临一个独特的挑战:需要生成与车辆传感器提供的视角不同的俯视场景视图。一些前沿方法利用摄像头特征和几何信息来构建BEV表示,而另一些方法则利用3D点云数据提取相关的语义信息。最近,越来越多的传感器融合技术结合了不同类型传感器的特征,以提升BEV表示的质量。这种俯视视角在追踪和规划等下游任务中尤为有用。语义栅格使得系统能够区分不同的物体类型(如车辆、行人、静态障碍物)和场景区域(如道路、人行道、行人过道),从而促进更好的决策过程。
这些先进模型需要大量多样且精确标注的数据来学习语义BEV栅格中的复杂细节。目前对BEV分割的研究主要使用nuScenes数据集进行训练和评估。这引发了关于这些模型鲁棒性和泛化能力的关键问题,因为它们通常只在单一数据集上进行测试。虽然领域自适应技术强大且常用于提高模型的泛化能力,但它们通常会引入额外的复杂性和计算开销。相较之下,跨数据集评估提供了一种更直接和经验验证模型鲁棒性的方法,无需额外的训练或微调,即可验证模型在不同现实世界条件和场景中的表现。
此外,跨数据集评估有助于建立标准化基准,揭示模型的固有限制和优点,提供模型在不同现实环境下表现的清晰洞见。尽管跨数据集验证在确保模型不仅对其训练数据集有效而且避免过拟合方面具有重要意义,但在BEV语义栅格分割文献中,该领域仍未得到充分探索。
在本研究中,我们旨在弥补这一空白,通过跨多个数据集评估BEV分割模型,以验证其在多样化现实场景中的可靠性和适用性。我们提出了一个新的跨数据集框架,用于在nuScenes和Woven Planet数据集上训练和评估三种BEV分割模型。我们在三类语义分割类别上使用交并比(IoU)得分评估三种最先进的BEV分割模型的性能。如图1所示,当模型在未见过的数据集上进行测试时,性能明显下降。我们提出的跨数据集验证框架旨在识别在单一数据集中不易发现的特定弱点或故障模式,帮助开发更为鲁棒和可靠的自动驾驶模型。据我们所知,这是首次在该主题上进行研究。
3.Method
在本节中,我们概述了研究所采用的方法。首先,我们讨论了使用的数据集,突出它们的特征和差异。接下来,我们详细说明了两者之间传感器数据的处理以及生成的地面真实数据。最后,我们描述了模型以及训练和评估策略。
A. 数据集
为了在本文中进行跨数据集评估研究,我们使用了nuScenes数据集和Woven Planet Perception Dataset,这些数据集在BEV(鸟瞰图)分割文献中具有重要性,且传感器设置相似。nuScenes数据集专注于驾驶场景,数据采集于美国波士顿和新加坡。它提供了来自六个摄像头、五个雷达和一个32层LiDAR的传感器信息,覆盖1000个驾驶场景,每个场景持续20秒。由于每个传感器的采样频率不同,数据集提供了一组跨所有传感器的同步关键帧,频率为2Hz。数据集还提供了不同场景中多种代理的3D边界框注释以及高分辨率地图。
Woven Planet Perception Dataset(前身为Lyft Level 5 Perception Dataset)是一个用于自动驾驶车辆研究的大规模数据集。数据采集于美国帕洛阿尔托市,提供了来自六个摄像头和三个64层LiDAR的传感器数据,以及场景中的行人和车辆的3D边界框注释,并提供了分辨率为10cm/px的语义地图栅格。
两个数据集都提供了全面的360°视野,包括六个周围摄像头和车顶安装的LiDAR。为了保持两者之间的传感器配置一致性,我们省略了nuScenes数据集中的雷达传感器和Woven Planet数据集中的前置LiDAR点云。
B. 点云处理
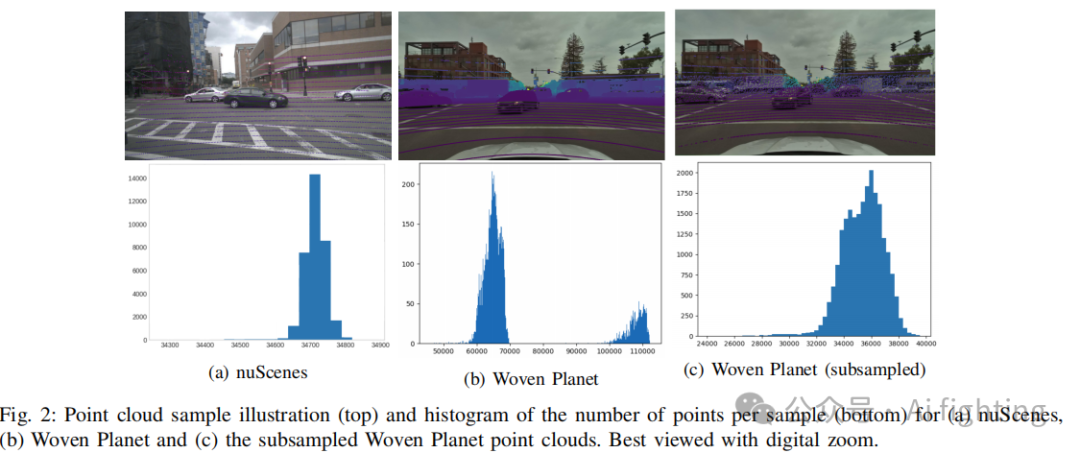
鉴于nuScenes(32层)和Woven Planet(64层)之间LiDAR规格的差异,我们进行了初步研究,比较了两个数据集的点云分布。我们生成了直方图来显示每个样本的点数,如图2a显示的是nuScenes,图2b是Woven Planet。可以观察到两个数据集的点云密度有显著差异,这是由于其不同的LiDAR系统所致。显著的是,nuScenes的点云在样本之间更加均匀,点数的中位数和平均数为34,720,而Woven Planet的平均点数为72,431,中位数为65,568。
为了在两个数据集之间实现每个样本点数的一致性,我们对Woven Planet数据集的点云进行了下采样,使其尽可能接近nuScenes数据集的点云密度。首先,我们将Woven Planet中的每个点云从原始笛卡尔坐标(x, y, z)转换为球坐标(ρ, θ, ϕ)。然后,我们将θ值范围划分为32个扇区,对应nuScenes中的32层LiDAR。对于ϕ值,我们将其划分为1500个扇区,因为这产生的分布最接近nuScenes。我们从每个扇区中采样一个点,并保存生成的点云以供后续使用。原始点云和下采样点云之间的差异分别显示在图2b和图2c顶部。图2c底部的直方图显示下采样后Woven Planet的点云分布更接近nuScenes,点数中位数为35,498,平均数为35,360。
C. 图像处理
nuScenes和Woven Planet数据集提供的摄像头图像大小不同。nuScenes提供六个(1600×900)像素的摄像头图像,而Woven Planet则包含两种不同大小的图像:某些场景为(1920×1080)像素,16:9宽高比(与nuScenes相同),而其他场景为(1124×1024)像素,1:1.1宽高比。
为了确保两个数据集的一致性,我们遵循了前人的方法,将每张图像的尺寸调整为(128×352)像素,并进行了中心裁剪。我们还相应调整了摄像机的内参矩阵。此外,我们在将图像传递给模型进行评估之前,应用了标准的ImageNet归一化。
D. 地面真实数据生成
我们在围绕自车的100m×100m区域内评估BEV分割。我们以每像素0.5m的分辨率对该空间进行了离散化,生成了一个200×200像素的栅格。在实验中,我们使用了三个语义类别:人类、车辆和可驾驶区域,因为这三个类别在两个数据集中都是通用的。
为了获得所需的“人类”和“车辆”类别的地面真实数据,我们对提供的3D边界框坐标和尺寸进行了离散化,并将它们投影到BEV中生成相应的语义地面真实数据。我们没有根据可见性水平过滤这些注释,因为这些可见性水平仅在nuScenes数据集中可用。
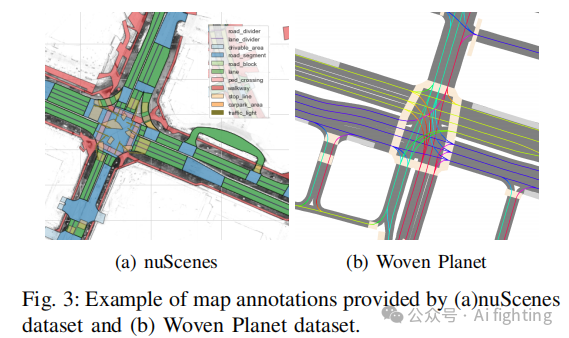
关于“可驾驶区域”类别的地面真实数据生成,我们首先展示了每个数据集中提供的原始地图注释的示例,如图3所示。对于nuScenes数据集来说,通过其提供的地图API生成这些数据非常简单。通过提供自车位置、感兴趣区域、分辨率和所需类别,我们可以为任何样本生成地面真实地图表示。
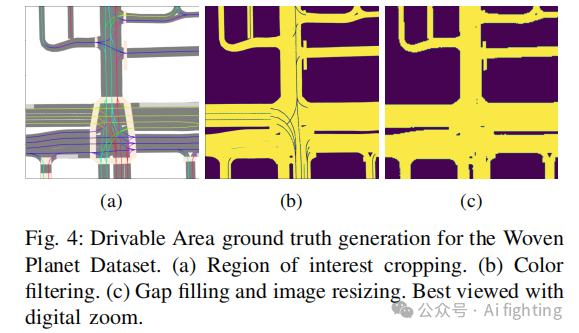
对于Woven Planet数据集,它提供了一个RGB图像格式的地图,地面真实数据的生成过程有所不同。首先,我们从原始地图图像中裁剪出感兴趣区域。接下来,我们应用颜色过滤器来隔离表示可驾驶区域和交叉路口的像素,随后使用(5×5)内核进行形态学闭合操作,以填充由中心线留下的空隙。最后,我们调整图像大小以匹配所需的BEV分辨率。这个过程如图4所示。
E. 模型
我们使用最先进的BEV语义分割模型和多种输入传感器模态进行了跨数据集验证实验:
仅摄像头:Lift-Splat-Shoot (LSS)是一种仅使用摄像头图像输入的著名语义BEV分割模型。它预测隐式深度分布,将图像特征投影到3D空间,并通过求和池化将这些特征分配给BEV单元。该模型作为基准,用于评估仅使用图像输入时跨数据集的性能变化。
早期摄像头-LiDAR传感器融合:LAPT采用了早期融合方法,将摄像头和LiDAR数据在初始阶段结合起来。该模型利用LiDAR深度信息将图像特征与BEV连接起来,从多个图像尺度投影特征以增强BEV覆盖范围。它展示了有限传感器融合的影响,主要集中在点云的深度值上,而不是它们的完整3D结构。
晚期摄像头-LiDAR传感器融合:LAPT-PP是LAPT的一个变体,采用了晚期融合技术。该模型利用专门的LiDAR编码器,从点云数据生成BEV特征图。然后,将这些特征图与摄像头生成的BEV特征图融合在一起,预测最终的语义分割结果。该模型评估了依赖点云3D结构的网络在晚期传感器融合中的性能变化。
4.Experiment
A. 跨数据集评估
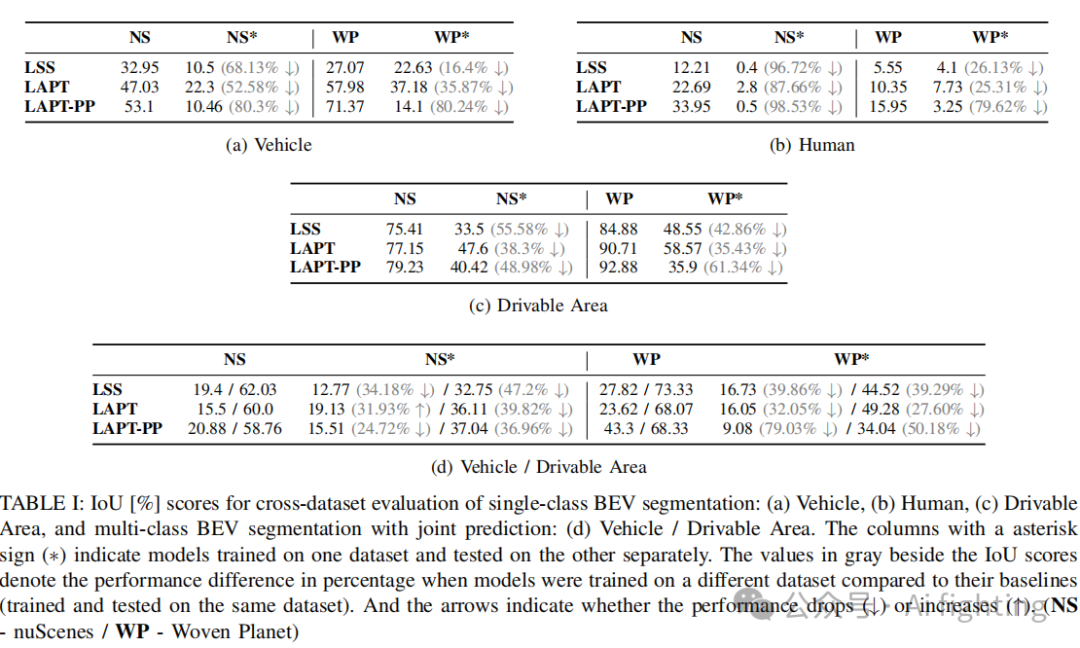
在表I中,我们呈现了不同数据集间的模型评估结果。结果显示,尽管在Woven Planet上训练,但模型在nuScenes数据集上的泛化能力普遍不强,这主要表现在IoU分数的显著下降。在所有模型中,LAPT-PP在跨数据集评估中的表现明显落后,特别是在不同语义类别和训练-测试配置中,性能下降最为显著。这种显著的性能退化可能源于LAPT-PP-FPN对LiDAR点云特征的过度依赖,而基于LiDAR的模型在跨数据集泛化时通常表现不佳,这主要是由于Woven Planet和nuScenes数据集在LiDAR配置上的差异。与此相反,基于图像的模型,如LSS和LAPT,由于视觉数据的一致性、标准化的预处理和注释方式,展现出了更优的跨数据集性能。
此外,表I(d)展示了多类别分割结果,这些模型在BEV栅格中同时预测车辆和可驾驶区域。我们发现,与单类别预测相比,多类别预测在跨数据集和模型的性能下降较小。这表明,通过联合预测多个类别,可以减轻数据集差异对模型性能的负面影响。这种多类别学习策略使模型能够捕捉到更加鲁棒和冗余的特征,从而稳定预测结果,减少数据集特定偏差的影响。
最后,我们注意到行人分割在所有数据集和模型中的IoU分数最低。这一方面是因为行人样本数量有限,使得BEV分割更具挑战性;另一方面,所采用的BEV栅格分辨率为0.5m/px,导致每个行人注释仅由一到两个像素表示,这种高精细度可能在特定数据集上训练出过于专业化的模型。
B. 多数据集训练
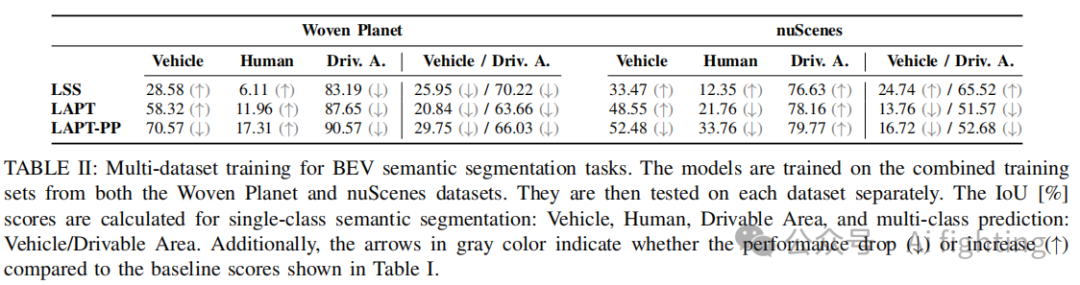
接下来,我们使用Woven Planet和nuScenes数据集的组合训练集进行了实验。然后,我们分别在每个数据集上测试每个模型,并在表II中展示了IoU分数。显示了单类别和多类别分割的性能。在同时训练两个数据集后,模型在两个数据集上表现出一致的准确性。具体而言,每个数据集的IoU分数与表I中显示的基线相似。此外,两个数据集的IoU分数表现出均衡的性能,而不会偏向某一个数据集。值得注意的是,由于在训练过程中包含了nuScenes数据,所有模型在人类分割任务上在Woven Planet数据集上提升了10%到15%。
C. 定性结果
在图5和图6中,我们展示了LAPT-PP模型在nuScenes和Woven Planet数据集上分别产生的定性结果。我们将场景中的车辆和可驾驶区域联合预测到同一个BEV栅格中。根据上述讨论,模型在训练数据集上表现最佳。图5(b)和6©显示了模型在同一数据集上训练和测试时的两个示例,生成的BEV栅格与地面真实数据高度匹配。然而,在不同数据集上进行评估时(如图5©和5(b)所示),模型的预测无法准确反映场景语义。

结论
文章的贡献如下:
1.首次引入了BEV语义分割任务的跨数据集验证框架。该框架具有灵活性,可扩展到更多模型、数据集和语义类别。
使用两个真实世界的大规模数据集进行了对比研究,评估了三种BEV分割模型在各种输入传感器模态下的性能,涵盖了三类语义分割类别。
2.通过同时在两个数据集上训练模型,研究了它们的泛化能力。
文章引用:
BEVal: A Cross-dataset Evaluation Study of BEV Segmentation Models for Autononomous Driving
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
扫码加入自动驾驶实战知识星球,即可快速掌握自动驾驶感知的最新技术:环境配置,算法原理,算法训练,代码理解等。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。