第1章 认识GitLab CI/CD
1.3 GitLab CI/CD的几个基本概念
GitLab CI/CD由以下两部分构成。
(1)运行流水线的环境。它是由GitLab Runner提供的,这是一个由GitLab开发的开源软件包,要搭建GitLab CI/CD就必须安装它,因为它是流水线的运行环境。
(2)定义流水线内容的.gitlab-ci.yml文件。这是一个YAML文件,它以一种结构化的方式来声明一条流水线—— 官方提供了很多关键词来覆盖各种业务场景,使你在编写极少Shell脚本的情况下也能应对复杂的业务场景。
除此之外,在定义的流水线中,还需要掌握的概念有以下几个。
(1)流水线(pipeline)。在GitLab CI/CD中,流水线由.gitlab-ci.yml文件来定义。实际上,它是一系列的自动化作业。这些作业按照一定顺序运行,就形成了一条有序的流水线。触发流水线的时机可以是代码推送、创建tag、合并请求,以及定时触发等。通常,由创建tag触发的流水线叫作tag流水线,由合并请求触发的流水线叫作合并请求流水线。此外,还有定时触发的定时流水线、跨项目流水线以及父子流水线等。
(2)阶段(stages)。阶段在流水线之下,主要用于给作业分组,并规定每个阶段的运行顺序。它可以将几个作业归纳到一个群组里,比如构建阶段群组、测试阶段群组和部署阶段群组。
(3)作业(job)。作业在阶段之下,是最基础的执行单元。它是最小化的自动运行任务,比如安装Node.js依赖包、运行测试用例。
第2章 CI/CD环境GitLab Runner
2.2 安装GitLab Runner
没有GitLab Runner,GitLab CI/CD的流水线就无法运行,现在我们就在一台计算机上安装GitLab Runner。GitLab Runner的安装方式有很多,而在众多的安装方式中Docker安装最为简便。使用Docker来安装GitLab Runner不仅学习成本小、容易迁移,还可以使用Docker镜像。
2.2.1 使用Docker安装GitLab Runner
使用Docker安装GitLab Runner只需要运行一条命令
docker run -d --name gitlab-runner --restart always \
-v /srv/gitlab-runner/config:/etc/gitlab-runner \
-v /var/run/docker.sock:/var/run/docker.sock \
gitlab/gitlab-runner:v14.1.0
运行上述代码,会先在本地搜索Docker镜像gitlab/gitlab-runner:v14.1.0,如果本地没有的话,则会从Docker Hub拉取。下载完成后,自动安装运行,指定参数--restart always可以在计算机重启后,GitLab Runner容器也自动重启。还需要做的是挂载目录-v /srv/gitlab-runner/config:/etc/gitlab-runner,这样做是为了能够让GitLab Runner的配置持久化,即便重启或删除容器后也不会丢失已产生的配置数据。
2.2.2 在Linux系统上安装GitLab Runner
GitLab Runner的安装方式不止一种,除了使用Docker安装,还可以在Linux、macOS、Windows上安装,也可以在Kubernetes和OpenShift上安装。下面我们再来简单介绍一下如何在Linux系统上安装GitLab Runner,这也是一种常见的安装方式。使用RPM安装GitLab Runner的代码如清单2-2所示。
清单2-2 使用RPM安装GitLab Runner
curl -LJO "https://gitlab-runner-downloads.s3.amazonaws.com/v14.1.0/rpm/gitlab-runner_amd64.rpm"
rpm -i gitlab-runner_amd64.rpm
如果设备的系统架构不是amd64的,可以将命令中的amd64替换为arm或arm64。更完整的参数及安装包可以查看https://gitlab-runner-downloads.s3.amazonaws.com/latest/index.html 这个地址。
2.3 注册runner
要使用GitLab Runner运行某个项目的流水线,需要使用GitLab Runner为这个项目注册一个runner。注册runner的过程就是将一个runner与项目绑定起来。这个runner会与GitLab建立联系,并在适当的时候进行通信。可以在一台计算机上注册多个runner,为多个项目提供服务。
和Docker安装GitLab Runner一样,为项目注册runner也只需要运行一条命令
docker run --rm -v /srv/gitlab-runner/config:/etc/gitlab-runner gitlab/gitlab-runner:v14.1.0
register \
--non-interactive \
--executor "docker" \
--docker-image alpine:latest \
--url "{MY_GITLAB_HOST}" \
--registration-token "{PROJECT_REGISTRATION_TOKEN}" \
--description "docker-runner" \
--tag-list "docker,aws" \
--run-untagged="true" \
--locked="false" \
--access-level="not_protected"
执行上述代码,会进入名为gitlab-runner的容器,执行 register命令,并携带executor、docker-image、tag-list等诸多参数。
几个重要参数进行阐释。
● --executor "docker":这里是指定执行器为Docker,执行器是流水线真正的执行环境。在GitLab Runner中,有很多执行器可用,除了Docker,还有Shell、SSH、Kubernetes,每种执行器都有其独有的特征。其中,Docker执行器是最方便的,可以零配置进行迁移。
● --url "{MY_GITLAB_HOST}":这个参数用于指定GitLab的域名,表明注册的runner要与GitLab进行关联。每一个注册的runner 都可以服务一个独立安装的GitLab。将{MY_GITLAB_HOST} 替换为GitLab的域名。
● --registration-token "PROJECT_REGISTRATION_TOKEN":用于设置注册的Token,每个项目都有一个独有的Token—— 这个可以在项目的设置页面看到,进入某个项目Settings→CI/CD展开runners。url与token这两个参数都可以从此处取得。
● --tag-list "docker,aws":指定runner的标签,可以填写多个,用逗号分隔,尽量不要与其他runner的标签重复。标签会直接在编写流水线时使用,注册后也可以在GitLab中进行修改。
● --non-interactive:添加该参数表示每个注册的runner都是独立的,不会相互影响。在GitLab Runner的配置文件里,每个注册的runner都可以进行单独配置。
● --docker-image alpine:latest:如果选择Docker作为执行器,就需要指定一个基础镜像。
根据使用范围的不同,runner可以分为3种类型,分别是只用于某一特定项目的特有runner、可以用于一个群组中所有项目的群组runner,以及可用于每个项目的共享runner。
2.4 不同执行器的特点
在GitLab Runner中,执行器才是流水线真正的运行环境。GitLab官方提供了很多执行器,之所以设计如此多的执行器,是为了满足各种各样的CI/CD场景,比如有的项目需要在Windows下执行,需要用到Windows PowerShell。官方提供的执行器大致有以下几种。
- Docker。
- Shell。
- Kubernetes。
- SSH。
- VirtualBox。
- Parallels。
- Custom。
每一种执行器都有其独有的特点,在执行流水线时,也会有一些差异。各种执行器特点的对比如表所示。
各种执行器特点的对比(选自GitLab官方文档)
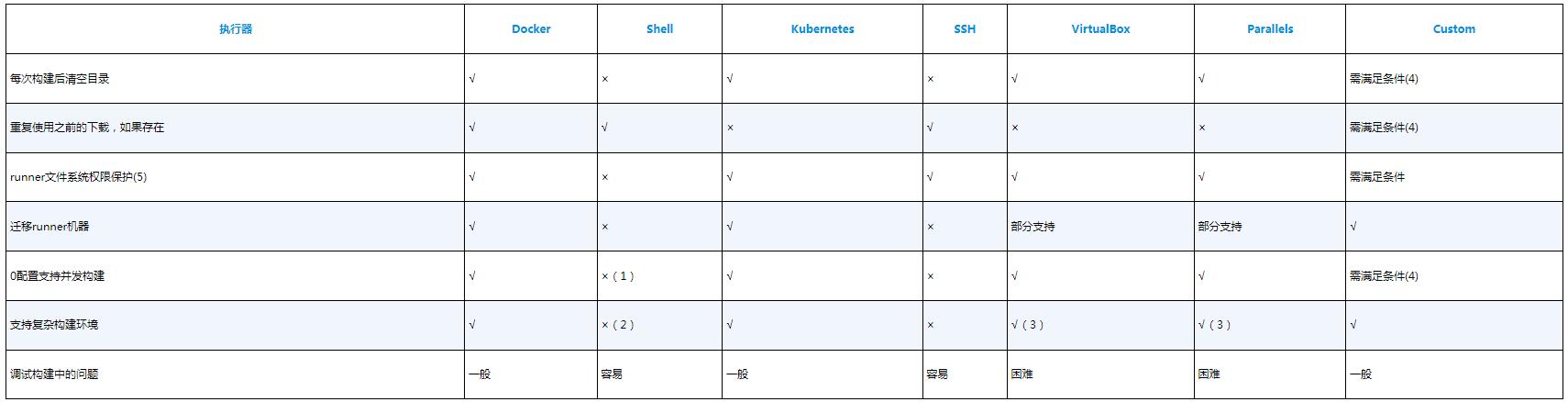
(1)在Shell执行器上并发构建是可以的,但如果使用了runner机器安装的其他服务,则大多数时候会出现问题。
(2)要求手动安装所有的依赖。
(3)例如使用Vagrant。
(4)取决于你正在配置的环境类型。它可以在每个构建之间完全隔离或共享。
(5)当一个runner的文件系统不被保护时,运行的作业将能访问到整个文件系统,包括runner的Token和其他作业的缓存与代码。标记为√的执行器,将不允许runner访问整个文件系统,但由于某些特殊的配置,运行的作业依然可以跳出容器,访问安装runner的宿主机文件系统。
各种执行器在执行流水线时的表现也有很多差异。各种执行器在执行流水线时的差异如表所示。
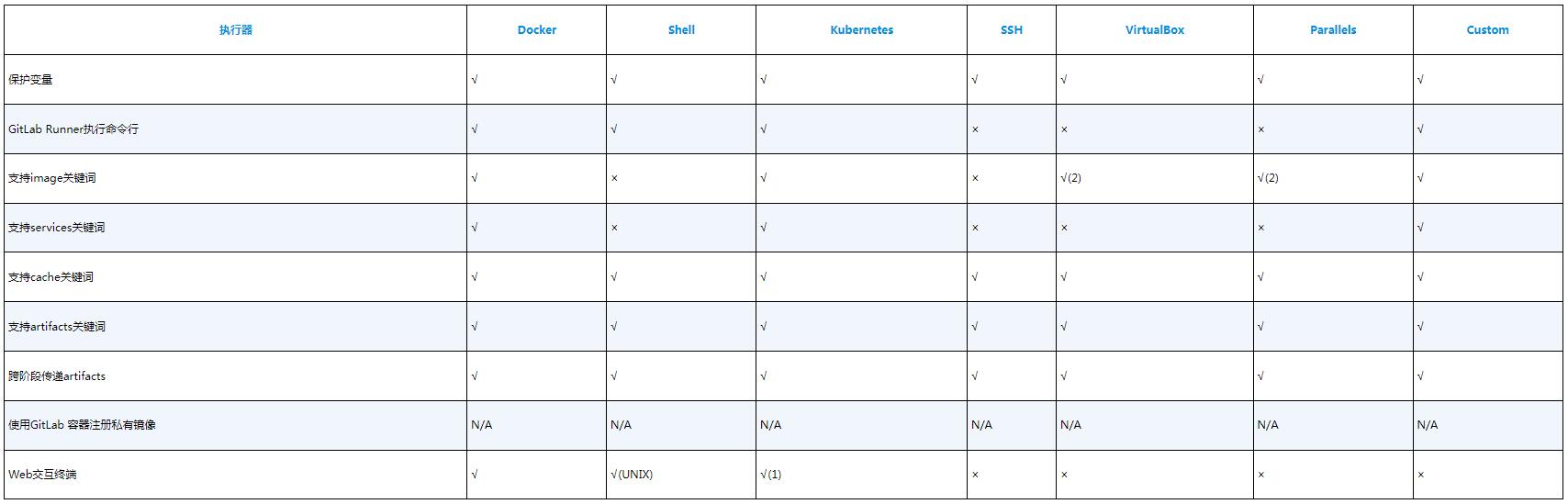
(1)交互式Web终端目前还不支持使用Helm chart安装的GitLab Runner。
(2)从GitLab Runner 14.2起支持。
2.5 配置runner
如果在使用runner的过程中需要对其进行一些特殊的配置,比如修改内存的限制、并发数或者挂载本地目录,这时就需要修改runner的配置文件。runner的所有配置保存在一个名为config.toml的文件中。如果你是按照清单来安装GitLab Runner的,那么可以在本地的/srv/gitlab-runner/config文件夹下找到config.toml文件。
config.toml文件的内容如清单所示。
concurrent = 1
check_interval = 0
[session_server]
session_timeout = 1800
[[runners]]
name = "115-for-hello-vue"
url = "http://10.2.13.9/"
token = "39NNqTxq8SfkmRyD9cVc"
executor = "docker"
[runners.custom_build_dir]
[runners.cache]
[runners.cache.s3]
[runners.cache.gcs]
[runners.cache.azure]
[runners.docker]
tls_verify = false
image = "alpine:latest"
privileged = false
disable_entrypoint_overwrite = false
oom_kill_disable = false
disable_cache = false
volumes = ["/cache", "/usr/bin/docker:/usr/bin/docker", "/var/run/docker.sock:/var/run/docker.sock"]
shm_size = 0
config.toml完整的文件中有很多配置参数,其中几个重要且常用的参数如下。
concurrent:限制runner能够同时执行多少个作业。log_level:定义日志的格式,可选项debug、info、warn、error、fatal和panic。check_interval:检查新任务的间隔,以秒为单位,默认为3。listen_address:定义Prometheus监控的HTTP地址。
在上述代码中,还有一部分是有关[session_server]的。这部分代码是用于配置调试流水线的,配置一个session地址,你可以在流水线的Web页面,进入一个交互式的控制台。这对于在线调试非常方便。
其中,有3个参数需要注意,如下所示。
listen_address:session服务的网络地址。advertise_address:gitlab-runner对外的服务端口,如果没有定义,直接使用listen_address。session_timeout:session的过期时间。
如果开发者注册了一个使用Docker作为执行器的runner,在config.toml文件中就会产生这样的一段配置,如清单所示。
[[runners]]
name = "115-for-hello-vue"
url = "http://120.77.178.9/"
token = "39NNqTxq8SfkmRyD9cVc"
executor = "docker"
[runners.custom_build_dir]
[runners.cache]
[runners.cache.s3]
[runners.cache.gcs]
[runners.cache.azure]
[runners.docker]
tls_verify = false
image = "alpine:latest"
privileged = false
disable_entrypoint_overwrite = false
oom_kill_disable = false
disable_cache = false
volumes = ["/cache"]
shm_size = 0
在config.toml文件中,每一块[[runners]]都是一个已经注册的runner的配置,其中会有一些默认值,也有一些是用户在注册runner时填写的,如token、url、name、executor,表明了当前的runner使用了哪种执行器。
volumes表明挂载主机哪些目录到容器中,通过该方法可以将流水线中的一些文件存放到主机上。此外,runner下还有一个参数limit,可以配置当前的runner能同时执行多少个作业。
每一种执行器都有其自己独特的配置项,并且所有的配置项都集中在config.toml中。如果你是在类 UNIX 系统上安装的GitLab Runner,使用root 用户安装,该配置文件存放在/etc/gitlab-runner/。非root用户,一般存放在~/.gitlab-runner/路径下,使用该方式安装后会创建一个 GitLab Runner的用户 gitlab-runner,流水线的运行也是使用该用户,如果需要在流水线中使用Docker的话,需要将用户gitlab-runner添加到docker用户组中。
2.6 runner的工作流程
runner的整个工作流程(摘自GitLab官方网站)
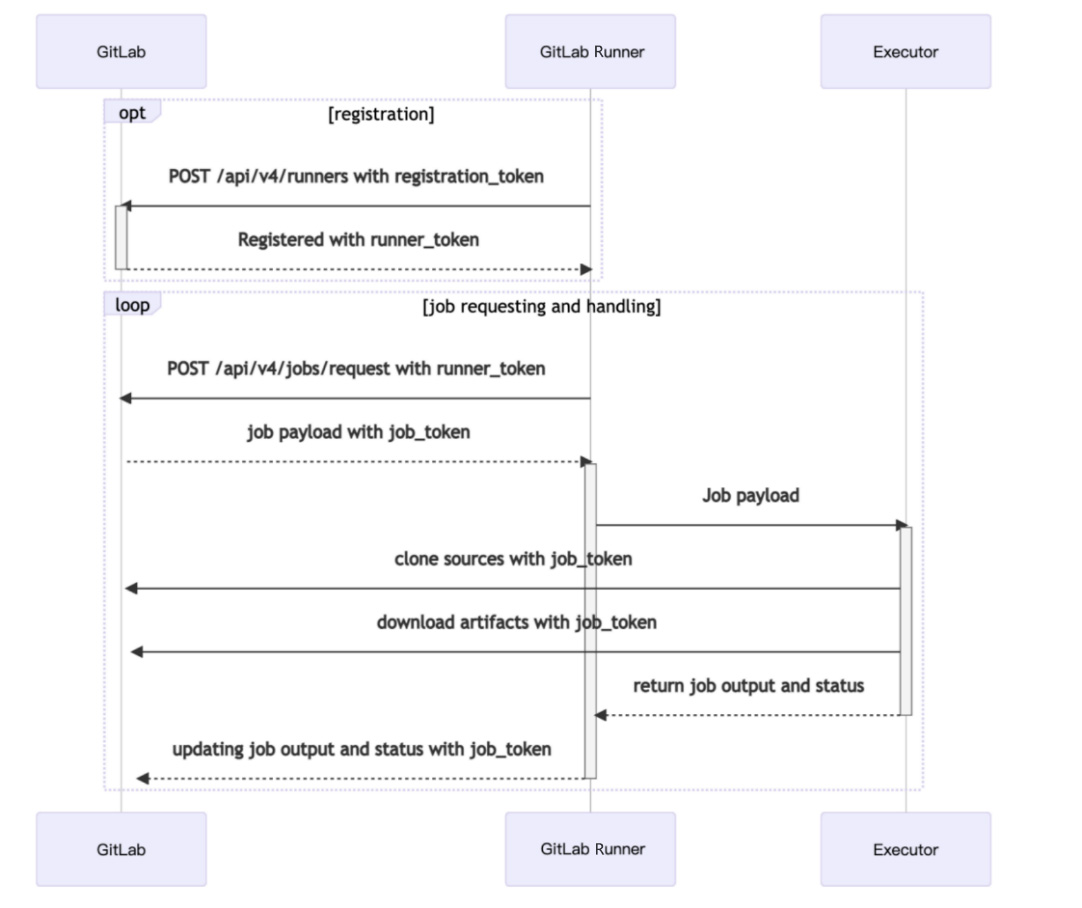
该流程描述得很清楚,当用户注册一个runner 时,是使用registration_token,向GitLab发送一个POST请求,然后GitLab会返回给GitLab Runner注册成功的信息,且 runner 需携带runner_token作为后续通信的凭证。
紧接着会进入一个循环,GitLab Runner会使用runner_token向GitLab 轮询发送请求,检查是否有流水线作业要执行,GitLab会返回任务的负载以及job_token,job_token会向下传递,传递到runner的执行器中,然后执行器去下载源码、下载artifacts、执行作业内容,最后再把作业的状态上报给GitLab Runner,GitLab Runner携带job_token通知GitLab更新作业的状态。
第3章 流水线内容.gitlab-ci.yml
3.1 存放位置
在一个项目里,流水线文件通常是默认放在项目根目录的.gitlab-ci.yml 文件,不过,开发者也可以在GitLab中修改这一配置。在项目中打开Settings→CI/CD,展开General pipelines菜单
要重新指定流水线文件的路径和文件名称,有一点需要保证,即该文件必须是以.yml为扩展名的文件,否则流水线将无法执行。除了指定项目中的某一个文件作为流水线文件,开发者还可以指定一个公开的文件作为该项目的流水线文件。如果指定了项目中的文件,因为该文件是存放在项目中的,所以也会被纳入版本的管理,每个版本的流水线内容可能不一样。
3.5 关键词
stages、 stage、script分别表示什么。其实,它们是GitLab CI/CD的关键词,是流水线语法的重要组成部分。GitLab官方提供了很多像stages、script这样的关键词。在14.1.0版本中,共有35个关键词(其中variables既是全局关键词,也是作业关键词),包括31个作业关键词(定义在作业上的,只对当前作业起作用,分别是after_script、allow_failure、artifacts、before_script、cache、coverage、dependencies、dast_configuration、environment、except、extends、image、inherit、interruptible、needs、only、pages、parallel、release、resource_group、retry、rules、script、secrets、services、stage、tags、timeout、trigger、variables和when,以及5个全局关键词(定义在流水线全局的,对整个流水线起作用,分别是stages、workflow、include、default和variables)。使用这些关键词,开发者可以很方便地编写流水线。例如,使用when关键词将一个作业从自动执行改为手动执行。
build_job:
script: echo 'hello cicd'
when: manual
又如,想让某个作业在master分支被执行,可以使用only关键词:
deploy_job:
script: echo 'start deploy'
only:
- master
这些关键词大大降低了编写流水线的复杂程度,让开发者只需关注流水线的核心逻辑,把条件判断、场景判断等操作都用这些关键词来实现。
第4章 初阶关键词
4.1 stages
stages是一个全局的关键词,它的值是一个数组,用于说明当前流水线包含哪些阶段,一般在.gitlab-ci.yml文件的顶部定义。如果没有定义该属性,则使用默认值。stages有5个默认值,如下所示。
prebuildtestdeploy- .
post
注意,.pre与.post 不能单独在作业中使用,必须要有其他阶段的作业才能使用。
如果官方提供的stages不满足业务需要,开发者可以自定义stages的值:
stages:
- pre-compliance
- build
- test
- pre-deploy-compliance
- deploy
- post-compliance
通常,作业的执行顺序是根据定义阶段顺序来确定的。
4.2 stage
stage关键词是定义在具体作业上的,定义了当前作业的阶段,其配置值必须取自全局关键词 stages。注意,全局关键词是stages,定义作业的阶段是stage。
4.4 cache
cache关键词可以管理流水线中的缓存、上传和下载。这个关键词可以定义在关键词default中(对整个流水线起作用),也可以单独配置在具体的作业中。这样配置,就可以将不同作业中共用的文件或者文件夹缓存起来—— 在后续执行阶段中都会被恢复到工作目录,从而避免在多个作业之间重复下载造成资源浪费。注意要缓存的文件,路径必须是当前工作目录的相对路径。
为什么会用到缓存呢?这是因为流水线中的每个作业都是独立运行的,如果没有缓存,运行上一个作业时安装的项目依赖包,运行下一个作业还需要安装一次。如果将上一个作业安装的依赖包缓存起来,在下一个作业运行时将其恢复到工作目录中,就可以大大减少资源的浪费。缓存用得最多的场景就是缓存项目的依赖包。每一种编程语言都有自己的包管理器,例如,Node.js应用使用NPM来管理依赖包,Java应用使用Maven来管理依赖包,Python应用使用pip来管理依赖包。这些依赖包安装完成后,可能不只为一个作业所使用,项目的构建作业需要使用它们,测试作业也需要使用它们。由于多个作业的执行环境可能不一致,而且在某些执行器中作业被执行完成后会自动清空所有依赖包,在这些情况下,就需要将这些依赖包缓存起来,以便在多个作业之间传递使用。
关键词cache的配置项有很多,最重要的是paths这个属性,用于指定要缓存的文件路径。
npm_init:
script: npm install
cache:
paths:
- node_modules
- binaries/*.apk
- .config
可以看到,npm_init作业执行npm install,安装了项目所需要的依赖包。在这个作业结束后,执行器会将工作目录中的node_modules、binaries目录下所有以.apk为扩展名的文件以及当前目录下的.config文件压缩成一个压缩包,缓存起来。
如果项目有多个分支,想要设置多个缓存,这时可以使用全局配置cache的key来设置。
default:
cache:
key: "$CI_COMMIT_REF_SLUG"
paths:
- binaries/
key的值可以使用字符串,也可以使用变量,其默认值是default。示例中,key的值就是CI中的变量:当前的分支或tag。在执行流水线的过程中,对于使用相同key缓存的作业,执行器会先尝试恢复之前的缓存。
在一个作业中最多可以定义4个key。清单4-8所示的示例,配置了2个key。
清单4-8 cache配置多个key
test-job:
stage: build
cache:
- key:
files: #文件列表
- Gemfile.lock
paths:
- vendor/ruby
- key:
files:
- yarn.lock
paths:
- .yarn-cache/
script:
- bundle install --path=vendor
- yarn install --cache-folder .yarn-cache
- echo 'install done'
开发者还可以将cache的key指向一个文件列表,这样做之后,只要这些文件内容没有变动,key就不会变,在执行时就会使用之前的缓存。
如果runner的执行器是Shell,缓存的文件默认是存放在本地,即/home/gitlab-runner/cache/<user>/<project>/<cache-key>/cache.zip;如果执行器是Docker,本地缓存会被存放在/var/lib/docker/volumes/<volume-id>/_data/<user>/<project>/<cache-key>/cache.zip目录中。使用Docker或使用rpm的方式安装的GitLab Runner默认使用本地缓存。开发者还可以将缓存放在一些分布式的存储平台,如AWS S3、MinIO。作业能否使用以前的缓存完全取决于两次缓存的key是否一致,如果在一个项目中两条流水线命中了同一个key的缓存,那么不管这个缓存是否是在当前流水线中创建的,都可以被使用。缓存通常不能跨项目,但可以跨流水线。缓存默认的key是default,要获得更好的体验,我们强烈建议开发者在使用缓存时定义key,当然也可以对不同的分支使用不同的key。
4.7 variables
在开发流水线的过程中,开发者可以使用variables关键词来定义一些变量。这些变量默认会被当作环境变量。
4.7.1 在.gitlab-ci.yml文件中定义变量
variables:
- USER_NAME: "fizz"
print_var:
script: echo $USER_NAME
变量名的推荐写法是使用大写字母,使用下画线_来分隔多个单词。在使用时,可以直接使用变量名,也可以使用$变量名,或使用${变量名}。为了与正常字符串区分开来,我们推荐使用后一种方式。如果将变量定义在全局范围,则该变量对于任何一个作业都可用;如果将变量定义在某个作业,那么该变量只能在当前作业可用;如果局部变量与全局变量同名,则局部变量会覆盖全局变量。
variables:
USER_NAME: 'fizz'
test:
variables:
USER_NAME: 'ZK'
script: echo 'hello' $USER_NAME
注意:如果在某一个作业的
script中修改了一个全局变量的值,那么新值只在当前的脚本中有效。对于其他作业,全局变量依然是当初定义的值。
4.7.2 在CI/CD设置中定义变量
除了在.gitlab-ci.yml中显式地定义变量,开发者还可以在项目的CI/CD中设置一些自定义变量。
在这里,开发者可以定义一些比较私密的变量,例如登录DockerHub的账号、密码,或者登录服务器的账号、密码或私钥。
将隐秘的信息变量定义在这里,然后勾选Mask variable复选框,这样在流水线的日志中,该变量将不会被显式地输出(但对变量值有一定格式要求)。这可以使流水线更安全,不会直接在代码中暴露隐秘信息。开发者还可以将一些变量设置为只能在保护分支使用。
如果有些变量需要在一个群组的项目中使用,可以设置群组CI/CD变量。
除了预设一些自定义变量,开发者还可以在手动执行流水线时,定义流水线需要的变量,这样做有可能会覆盖定义的其他变量。
如果想查看当前流水线所有的变量,可以在script中执行export 指令。
4.7.3 预设变量
除了用户自定义变量,在GitLab CI/CD中也有很多预设变量,用于描述当前操作人、当前分支、项目名称、当前触发流水线的方式等。使用这些预设变量可以大幅度降低开发流水线的难度,将业务场景分割得更加精确。
4.8 when
when关键词提供了一种监听作业状态的功能,只能定义在具体作业上。如果作业失败或者成功,则可以去执行一些额外的逻辑。例如当流水线失败时,发送邮件通知运维人员。
when的选项如下所示。
on_success:此为默认值,如果一个作业使用when: on_success,那么在此之前的阶段的其他作业都成功执行后,才会触发当前的作业。on_failure:如果一个作业使用when:on_failure,当在此之前的阶段中有作业失败或者流水线被标记为失败后,才会触发该作业。always:不管之前的作业的状态如何,都会执行该作业。manual:当用when:manual修饰一个作业时,该作业只能被手动执行。delayed:当某个作业设置了when:delayed时,当前作业将被延迟执行,而延迟多久可以用start_in来定义,如定义为5 seconds、30 minutes、1 day、1 week等。never:流水线不被执行或者使用rule关键词限定的不被执行的作业。
示例:
manual_job:
script: echo 'I think therefore I am'
when: manual
fail_job:
script: echo 'Everything is going to be alright,Maybe not today but eventually'
when: on_failure
注意:该作业必须放到最后一个阶段来执行,只有这样,才能监听到之前所有阶段的作业失败状态。如果之前的作业没有失败,该作业将不会被执行;如果之前的作业有一个失败,该作业就会被执行。
4.9 artifacts
在执行流水线的过程,开发者可能需要将一些构建出的文件保存起来,比如一些JAR包、测试报告,这时就可以使用artifacts关键词来实现。开发者可以使用artifacts关键词配置多个目录或文件列表,作业一旦完成,这些文件或文件夹会被上传到GitLab—— 这些文件会在下一个阶段的作业中被自动恢复到工作目录,以便复用。通过这种方式,开发者可以很好地持久化测试报告和其他文件,也可以在GitLab上自由查看和下载这些文件。
通过artifacts的配置项,开发者可以很容易地设置其大小和有效期,也可以使用通配符来选择特定格式的文件。
将文件目录保存到artifacts下:
artifacts_test_job:
script: npm run build
artifacts:
paths:
- /dist
上面的作业,会在执行完npm run build后,将/dist 目录作为artifacts上传到GitLab 上。在14.x的版本中,开发者可以直接在GitLab在线查看artifacts的内容而不用下载。
artifacts的复杂配置示例:
upload:
script: npm run build
artifacts:
paths:
- /dist
- *.jar
exclude:
- binaries/**/*.o # binaries目录下的所有以.o为扩展名的文件排除掉
expire_in: 1 week #文件的有效期是1周
name: "$CI_JOB_NAME" # artifacts名称使用当前的作业名称来命名
在本节中,我们只展示artifacts几个常用配置项的用法,如下所示。
exclude:用于排除一些文件或文件夹。expire_in:artifacts的有效期。expose_as:使用一个字符串来定义artifacts在GitLab UI上显示的名称。name:定义artifacts的名称。paths:定义artifacts存储的文件或文件夹,以便将其传入一个文件列表或文件夹列表。public:表明artifacts是否是公开的。
有些开发者不知道何时该用cache、何时该用artifacts。需要明确的是,cache大多数用于项目的依赖包;artifacts常用于作业输出的一些文件、文件夹,比如构建出的dist目录、JAR包、测试报告。此外,cache 可以被手动被清空,而artifacts是会过期的。
4.12 only与except
only与except这两个关键词用于控制当前作业是否被执行,或当前作业的执行时机。only是只有当条件满足时才会执行该作业;except是排除定义的条件,在其他情况下该作业都会被执行。如果一个作业没有被only、except或者rules修饰,那么该作业的将默认被only修饰,值为tags或branchs。最常用的语法就是,控制某个作业只有在修改某个分支时才被执行。
only_example:
script: deploy test
only:
- test #只有修改了test分支的代码,该作业才会被执行。
only与except下可以配置4种值,如下所示。
refs。variables。changes。Kubernetes。
4.12.1 only:refs/except:refs
如果only/except关键词下配置的是refs,表明作业只有在某个分支或某个流水线类型下才会被添加到流水线中或被排除。
test:
script: deploy test
only:
- test #只有修改了test分支的代码后,作业才会被执行
build:
script: deploy test
only:
refs:
- test #只有修改了test分支的代码后,作业才会被执行
deploy:
script: deploy test
only:
refs:
- tags
- schedules #只有项目创建了tags 或者 当前是定时部署 该作业才会被执行
api:使用pipeline API触发的流水线。branches:当分支的代码被改变时触发的流水线。chat:使用GitLab ChatOps命令触发的流水线merge_requests:流水线由创建或更新merge_request触发。web:使用GitLab Web上的Run pipeline触发的流水线。
此外,refs的值也可以配置成正则表达式,如/^issue-.*$/。
4.12.2 only:variables/except:variables
only:variables与except:variables可以根据CI/CD中的变量来动态地将作业添加到流水线中。
在only中使用变量
test:
script: deploy test
only:
variables:
- $USER_NAME === "fizz" #只有定义的变量USER_NAME等于fizz时,该作业才会被执行
开发者可以配置多个only:variables的条件判断,只要有一个条件符合,作业就会被执行。
4.12.3 only:changes/except:changes
使用changes来修饰关键词only适用于某些文件改变后触发作业的情景。例如,只有项目中Dockerfile文件改变后,才执行构建Docker镜像的作业;又如,一个项目中有多个应用,针对某个文件夹的变动,执行某一个应用的作业。这些针对文件改变执行或不执行的作业都可以使用only:changes或except:changes来定义。
test:
script: deploy test
only:
changes:
- Dockerfile #该作业只有在修改了Dockerfile或者fe目录下的文件才会被执行
- fe/**/*
在tag流水线或定时流水线中,该作业也会被执行。
4.12.4 only:kubernetes/except:kubernetes
only:kubernetes与except:kubernetes用于判断项目是否接入了Kubernetes服务,进而来控制作业是否被执行。
deploy:
script: deploy test
only:
kubernetes: active #只有项目中存在可用的Kubernetes服务时,作业才会被执行。
第5章 中阶关键词
5.1 coverage
在GitLab CI/CD中,开发者可以使用关键词coverage配置一个正则表达式来提取作业日志中输出的代码覆盖率,提取后可以将之展示到代码分支上。
test:
script: npm test
coverage: '/Code coverage: \d+\.\d+/'
注意,coverage的值必须以/开头和结尾。如果该作业输出了Code coverage: 67.89这种格式的日志,会被GitLab CI/CD记录起来。如果有多个日志符合规则,取最后一个记录。
5.2 dependencies
dependencies关键词可以定义当前作业下载哪些前置作业的artifacts,或者不下载之前的artifacts。dependencies的值只能取自上一阶段的作业名称,可以是一个数组,如果是空数组,则表明不下载任何artifacts。在GitLab CI/CD中,所有artifacts在下一阶段都是被默认下载的,如果artifacts非常大或者一条流水线有很多artifacts,则默认下载全部artifacts就会很低效。正确的做法是使用dependencies来控制,仅下载必要的artifacts。
stages:
- build
- deploy
build_windows:
stage: build
script:
- echo "start build on windows"
artifacts: #产生 artifact
paths:
- binaries/
build_mac:
stage: build
script:
- echo "start build on mac"
artifacts:
paths:
- binaries/
deploy_mac:
stage: deploy
script: echo 'deploy mac'
dependencies: # deploy_mac作业只会下载build_mac作业的artifacts
- build_mac
deploy_windows:
stage: deploy
script: echo 'deploy windows'
dependencies: # deploy_windows作业只会下载build_windows作业的artifacts
- build_windows
release_job:
stage: deploy
script: echo 'release version'
dependencies:[] # release_job作业不会下载任何artifacts
5.4 extends
extends关键词可用于继承一些配置模板。利用这个关键词,开发者可以重复使用一些作业配置。extends关键词的值可以是流水线中的一个作业名称,也可以是一组作业名称。
.test:
script: npm lint
stage: test
only:
refs:
- branches
test_job:
extends: .test #
script: npm test
only:
variables:
- $USER_NAME
在上述的示例中,有两个作业,一个是.test,另一个是test_job。可以看到,在test_job中配置了extends: .test。
在GitLab CI/CD中,如果一个作业的名称以“.”开头,则说明该作业是一个隐藏作业,任何时候都不会执行。这也是注释作业的一种方法,上文说的配置模板就是指这类被注释的作业。test_job继承了作业.test的配置项,两个作业的配置项会进行一次合并。test_job中没有而.test作业中有的,会被追加到test_job中。test_job中已经有的不会被覆盖。
test_job:
stage: test
script: npm test
only:
refs:
- branches
variables:
- $USER_NAME
开发者可以将流水线中一组作业的公共部分提取出来,写到一个配置模板中,然后使用extends来继承。这样做可以大大降低代码的冗余,提升可读性,并方便后续统一修改。
5.5 default
default是一个全局关键词,定义在.gitlab-ci.yml文件中,但不能定义在具体的作业中。default下面设置的所有值都将自动合并到流水线所有的作业中,这意味着使用default可以设置全局的属性。能够使用default 设置的属性有after_script、artifacts、before_script、cache、image、interruptible、retry、services、tags和timeout。
default:
image: nginx
before_script:
- echo 'job start'
after_script:
- echo 'job end'
retry: 1
build:
script: npm run
test:
image: node
before_script:
- echo 'let us run job'
script: npm lint
default下定义的属性只有在作业没有定义时才会生效。
合并后的代码
default:
image: nginx
before_script:
- echo 'job start'
after_script:
- echo 'job end'
retry: 1
build:
image: nginx
before_script:
- echo 'job start'
after_script:
- echo 'job end'
retry: 1
script: npm run
test:
after_script:
- echo 'job end'
retry: 1
image: node
before_script:
- echo 'let us run job'
script: npm lint
如果开发者想要实现在某些作业上不使用default定义的属性,但又不想设置一个新的值来覆盖,这时可以使用关键词inherit来实现。
5.6 inherit
inherit关键词可以限制作业是否使用default或者variables定义的配置。inherit下有两个配置,即default与variables。
default:
retry: 2
image: nginx
before_script:
- echo 'start run'
after_script:
- echo 'end run'
test:
script: echo 'hello'
inherit:
default: false # 该作业不会合并default的属性
deploy:
script: echo 'I want you to be happy,but I want to be the reason'
inherit:
default: # 作业deploy将会合并default的retry和image属性
- retry
- image
inherit:variables下可以设置true或者false,也可以设置一个数组,数组的值取自全局定义的variables。
variables:
NAME: "This is variable 1"
AGE: "This is variable 2"
SEX: "This is variable 3"
test:
script: echo "该作业不会继承全局变量"
inherit:
variables: false # 全局变量不会被引入 test作业中
deploy:
script: echo "该作业将继承全局变量 NAME和AGE"
inherit:
variables: # 全局变量NAME和AGE将被引入deploy作业中
- NAME
- AGE
5.7 interruptible
interruptible关键词用于配置旧的流水线能否被新的流水线取消,主要应用于“同一分支有新的流水线已经开始运行时,旧的流水线将被取消”的场景。该关键词既可以定义在具体作业中,也可以定义在全局关键词default中。interruptible关键词的默认值为false,即旧的流水线不会被取消。
要取消旧的流水线,还需要在GitLab上进行项目配置,即单击项目设置下的CI/CD子菜单,勾选Auto-cancel redundant pipelines选项。
interruptible的用法:
stages:
- install
- build
- deploy
install_job:
stage: install
script:
- echo "Can be canceled."
interruptible: true
build_job:
stage: build
script:
- echo "Can not be canceled."
deploy_job:
stage: deploy
script:
- echo "Because build_job can not be canceled, this step can never be canceled, even
though it's set as interruptible."
interruptible: true
当作业install_job正在运行或者准备阶段,如果此时在同一分支有新的流水线被触发,那么旧的流水线会被取消。但如果旧的流水线已经运行到了build_job,此时再有新的流水线被触发,则旧的流水线不会被取消。只要运行了一个不能被取消的作业,则该流水线就不会被取消,这就是取消的规则。所以,如果开发者想要达到无论旧的流水线运行到了哪个作业,只要有新流水线被触发,旧的流水线就要被取消这一目的,可以在default关键词下设置interruptible为true。
5.8 needs
needs关键词用于设置作业之间的依赖关系。跳出依据阶段的运行顺序,为作业之间设置依赖关系,可以提高作业的运行效率。通常,流水线中的作业都是按照阶段的顺序来运行的,前一个阶段的所有作业顺利运行完毕,下一阶段的作业才会运行。但如果一个作业使用needs设置依赖作业后,只要所依赖的作业运行完成,它就会运行。这样就会大大提高运行效率,减少总的运行时间。
stages:
- install
- build
- deploy
install_java:
stage: install
script: echo 'start install'
install_vue:
stage: install
script: echo 'start install'
build_java:
stage: build
needs: ["install_java"] # 只要install_java作业运行完毕,build_java就会开始运行
script: echo 'start build java'
build_vue:
stage: build
needs: ["install_vue"]
script: echo 'start build vue'
build_html:
stage: build
needs: [] # 该作业将会放到第一队列运行 当流水线触发时它就会运行
script: echo 'start build html'
job_deploy: #待作业build_vue与build_java运行完毕后,deploy阶段的job_deploy作业才会运行
stage: deploy
script: echo 'start deploy'
needs还可以设置跨流水线的依赖关系。
父流水线和子流水线的示例。
父流水线:
create-artifact:
stage: build
script: echo "sample artifact" > artifact.txt
artifacts:
paths: [artifact.txt]
child-pipeline:
stage: test
trigger:
include: child.yml
strategy: depend
variables:
PARENT_PIPELINE_ID: $CI_PIPELINE_ID
子流水线:
use-artifact:
script: cat artifact.txt
needs:
- pipeline: $PARENT_PIPELINE_ID # 依赖流水线。
job: create-artifact
5.10 parallel
parallel关键词用于设置一个作业同时运行多少次,取值范围为2~50,这对于非常耗时且消耗资源的作业来说是非常合适的。要在同一时间多次运行同一个任务,开发者需要有多个可用的runner,或者单个runner允许同时运行多个作业。
test:
script: echo 'hello WangYi'
parallel: 5
在上述例子中,我们定义了一个test作业,并设置该作业的parallel为5,这样该作业将会并行运行5次。作业名称以test 1/5、test 2/5、test 3/5这样命名,以此类推。
parallel关键词除了可以配置数字,还可以配置matrix。使用matrix可以为同时运行的作业注入不同的变量值:
deploystacks:
stage: deploy
script:
- bin/deploy
parallel:
matrix:
- PROVIDER: aws # 变量
STACK:
- monitoring
- app1
- app2
- PROVIDER: ovh # 变量
STACK: [monitoring, backup, app] # 变量
- PROVIDER: [gcp, vultr] # 变量
STACK: [data, processing] # 变量
这10个作业的变量值分别如下。
- deploystacks: [aws, monitoring]。
- deploystacks: [aws, app1]。
- deploystacks: [aws, app2]。 笛卡尔积
- deploystacks: [ovh, monitoring]。
- deploystacks: [ovh, backup]。
- deploystacks: [ovh, app]。 笛卡尔积
- deploystacks: [gcp, data]。
- deploystacks: [gcp, processing]。
- deploystacks: [vultr, data]。
- deploystacks: [vultr, processing]。 笛卡尔积
5.13 release
release关键词用于创建发布。如果流水线使用的是Shell执行器,要创建发布,必须安装官方提供的release-cli,这是一个创建发布的命令行工具。如果是Docker执行器的话,可以直接使用官方提供的镜像registry.gitlab.com/gitlab-org/release-cli:latest。
release关键词下有很多配置项,有些是必填的,有些是选填的,如下所示。
- tag_name:必填,项目中的Git 标签。
- name:选填,release的名称,如果不填,则使用tag_name的值。
- description:必填,release的描述,可以指向项目中的一个文件。
- ref:选填,release的分支或者tag。如果不填,则使用tag_name。
- milestones:选填,与release关联的里程碑。
- released_at:选填,release创建的日期和时间,如’2021-03-15T08:00:00Z’。
- assets:links:选填,资产关联,可以配置多个资源链接。
release_job:
stage: release
image: registry.gitlab.com/gitlab-org/release-cli:latest
rules:
- if: $CI_COMMIT_TAG
script:
- echo "Running the release job."
release:
name: 'Release $CI_COMMIT_TAG'
description: 'Release created using the release-cli.'
第6章 高阶关键词
6.1 rules
由于项目的流水线内容都是定义在.gitlab-ci.yml文件中的,为了应对各种业务场景、各种分支的特殊作业,开发者需要编写复杂的条件来实现在特定场景下运行特定的作业,这个时候可以使用关键词rules。
关键词rules是一个定义在作业上的关键词。它不仅可以使用自定义变量、预设变量来限定作业是否运行,还可以通过判断项目中某些文件是否改变以及是否存在某些文件来决定作业是否运行。开发者可以设置多条判断语句,如果有多条规则命中,会按照第一匹配原则来决定作业是否会运行。关键词rules是关键词only/except的“加强版”,在相同的场景下官方推荐使用rules,官方对关键词only/except将不再开发新的特性。rules下有6个配置项,分别是if、changes、exists、allow_failure和variables。
6.1.1 rules:if
rules:if用于条件判断,可以配置多个表达式,当表达式的结果为true时,该作业将被运行。
test_job:
script: echo "Hello, ZY!"
rules:
- if: '$CI_MERGE_REQUEST_SOURCE_BRANCH_NAME =~ /^feature/ && $CI_MERGE_REQUEST_
TARGET_BRANCH_NAME != $CI_DEFAULT_BRANCH'
# 当前的代码改动中,如果在当前的合并请求中源分支是以feature开头的,且目标分支不是项目的默认分支,
when: never # 则当前作业不会被添加到流水线中
- if: '$CI_MERGE_REQUEST_SOURCE_BRANCH_NAME =~ /^feature/'
when: manual
allow_failure: true
- if: '$CI_MERGE_REQUEST_SOURCE_BRANCH_NAME'
如果用when:never修饰一个rules:if,表明若命中该表达式不会运行。此外,在rules:if中使用的变量格式必须是$VARIABLE。
6.1.2 rules:changes
为了满足指定文件改变而运行特定作业的场景需求,GitLab CI/CD提供了rules:changes。
docker_build:
script: docker build -t my-image:$CI_COMMIT_REF_SLUG .
rules:
- changes:
- Dockerfile #只要Dockerfile更改了,docker_build作业就会运行
注意:首先,配置的文件路径必须是项目根目录的相对路径;其次,当流水线类型是定时流水线或者tag流水线时,该作业也会运行。所以开发者应尽量在分支流水线或者合并流水线中使用它。
6.1.3 rules:exists
rules:exists可以用于实现根据某些文件是否存在而运行作业:如果配置的文件存在于项目中,则运行作业;如果不存在,则不运行作业。
docker_build:
script: docker build -t fizz-app:$CI_COMMIT_REF_SLUG .
rules:
- exists:
- Dockerfile #如果项目中存在Dockerfile,则该作业会运行,否则不运行。
6.1.4 rules:allow_failure
rules:allow_failure可以配置当前作业运行失败后,使流水线不停止,而继续往下运行。其默认值为false,表示作业运行失败则流水线停止运行。
test_job:
script: echo "Hello, Rules!"
rules:
- if: '$CI_MERGE_REQUEST_TARGET_BRANCH_NAME == $CI_DEFAULT_BRANCH'
when: manual
allow_failure: true #如果作业运行失败,流水线不会停止运行。
6.1.5 rules:variables
rules:variables用于对变量进行操作,可以在满足条件时修改或创建变量。
rules_var:
variables:
DEPLOY_VARIABLE: "default-deploy"
rules:
- if: $CI_COMMIT_REF_NAME == $CI_DEFAULT_BRANCH
variables:
DEPLOY_VARIABLE: "deploy-production" # 将变量DEPLOY_VARIABLE修改为deploy-production
- if: $CI_COMMIT_REF_NAME = 'feature'
variables:
IS_A_FEATURE: "true" #新建一个变量为IS_A_FEATURE,令其值为true。
script:
- echo "Run script with $DEPLOY_VARIABLE as an argument"
- echo "Run another script if $IS_A_FEATURE exists"
6.3 trigger
trigger关键词用于创建下游流水线,即在流水线中再触发新的流水线,尤其适用于构建部署复杂的项目或者多个微服务的项目结构。使用该关键词,开发者可以创建父子流水线(在一个项目中运行两条流水线),也可以创建跨项目流水线。
如果一个作业配置了trigger,那么该作业有些属性将不能被定义,如script、after_script和before_script。能够配置的属性只有以下几个:stage、allow_failure、rules、only、except、when、extends和needs。
trigger-other-project:
stage: deploy
trigger:
project: my/deployment
branch: stable-2022 #触发my/deployment项目的stable-2022分支的流水线
trigger-child-pipeline:
stage: deploy
trigger:
include: path/to/microservice_a.yml #触发一个下游流水线,该流水线的内容定义在该项目的path/to/microservice_a.yml文件中
默认情况下,一旦下游流水线得以创建,触发流水线的作业就会变为成功状态,并且上游的流水线会继续运行,并不会等待下游流水线运行完成。如果开发者需要上游流水线在下游流水线运行完成后再继续运行,可以在作业上配置strategy: depend。
trigger-microservice_a:
stage: deploy
variables: #该变量会直接注入下游流水线中
ENVIRONMENT: staging
trigger:
include: path/to/microservice_a.yml
strategy: depend # 同步等待完成。
6.4 include
include 关键词用于引入模板,即允许开发者在.gitlab-ci.yml文件中引入外部的YAML文件。引入的文件可以是本项目中的,也可以是一个可靠的公网YAML文件,还可以是官方的模板文件。我们可以将常用的一些配置模板定义在仓库外的一个公网YAML文件中,然后使用include引入,这样做之后,修改引入的文件将不会触发流水线,在下次运行流水线时生效。为了安全起见,开发者应该引入那些可靠的YAML文件。
前文提到,开发者可以在.gitlab-ci.yml中定义一个配置模板作业,然后用extends关键词来继承它,以降低配置、提取公共代码。但对于跨项目或者多项目,共享配置是无法单独使用extends来实现的。对此GitLab CI/CD团队提供了关键词include,用于引入外部的YAML文件。 include是一个全局关键词,一般定义在.gitlab-ci.yml的头部,可以一次引入多个文件,但文件的扩展名必须是.yml或.yaml。
include关键词下有4个配置项,分别是local、file、remote和template。每个配置项都可以引入不同类型的YAML文件,且都允许引入多个文件。local的值必须指向本项目的文件,file的值可以指向其他项目的文件,remote用于引入公网文件资源,template配置项只能用于引入GitLab 官方编写的模板文件。这4个配置项可以单独使用,也可以组合使用。
6.4.1 include:local
include:local用于引入本地文件,且只能引入当前项目的文件,需要以/开头,表示项目根目录。引入的文件必须与当前的.gitlab-ci.yml文件位于同一分支,无法使用Git submodules的路径。
include:
- local: '/templates/.fe-ci-template.yml'
合并时,对于相同的key,使用.gitlab-ci.yml的配置。注意,.fe-ci-template.yml文件要与.gitlab-ci.yml位于同一分支。因为只引入了一个文件,所以上述例子也可以简写成include: '/templates/.fe-ci-template.yml'。
对于大型项目的流水线,引入的模板资源不止一个,如果一个一个引入,无疑会很麻烦。这时可以将模板文件存放在一个文件夹下,在.gitlab-ci.yml中用通配符来匹配该目录下的所有模板文件,进行批量引入。批量引入模板文件可以写成include: '/fe/*.yml',这样将会引入fe目录下的所有以.yml结尾的文件,但不会引入fe的子目录下的YAML文件。如果要引入一个目录下所有的YAML文件,并引入该目录所有子级目录下的YAML文件,可以配置为include: '/fe/**.yml'。
6.4.2 include:file
include:file用于引入其他项目文件,可以在.gitlab-ci.yml文件中引入另一个项目的文件。开发者需要指定项目的完整路径,如果有群组,那么需要加上群组路径。
include:
- project: 'fe-group/my-project'
ref: main #分支
file: '/templates/.gitlab-ci-template.yml'
- project: 'test-group/my-project'
ref: v1.0.0 # tag
file: '/templates/.gitlab-ci-template.yml'
- project: 'be-group/my-project'
ref: 787123b47f14b552955ca2786bc9542ae66fee5b # Git SHA
file:
- '/templates/.gitlab-ci-template.yml'
- '/templates/.tests.yml'
6.4.3 include:remote
include:remote用于引入公网文件,即可以引入公网的资源。开发者需要指定文件资源的完整路径,由于文件资源必须是公开、不需要授权的,因此可以使用HTTP或HTTPS的GET请求获得。
include:
- remote: 'https://../.../../.gitlab-ci.yml'
使用该方法可以在不增加版本记录的情况下,对流水线进行修改。开发者可以将流水线所有内容定义在一个外网的文件上,使用include引入。注意,这可能会存在安全隐患。使用include引入文件后,在流水线运行时,会将所有的引入文件做一次快照合并到.gitlab-ci.yml文件中。在流水线运行后再修改引用的文件,并不会触发流水线,也不会更改已经运行的流水线结果,所修改的内容会在流水线下一次运行时应用。如果重新运行旧的流水线,运行的依然是修改前的内容。
6.4.4 include:template
include:template用于引入官方模板文件,也就是说,可以将官方的一些模板引入流水线中,
include:
- template: Android-Fastlane.gitlab-ci.yml
- template: Auto-DevOps.gitlab-ci.yml
引入这些模板时,不用填写完整路径,只需要保证文件名称正确。
6.5 resource_group
在一个频繁构建、频繁部署的应用中,可能同时存在多条运行的流水线,这种并发运行的情况会导致很多问题。比如,一个旧的流水线部署的环境要比新的流水线较晚完成,导致部署环境不是用最新的代码部署的。为了解决这一问题,GitLab CI/CD引入了“资源组”的概念。将resource_group关键词配置到一个作业上,在同一时间只会有一个作业正在运行,可确保运行顺序,使其他的作业在当前作业完成后再运行
deploy-production-job:
script: sleep 600
resource_group: prod #
如果现在有两条流水线同时运行,无论这两条流水线是否属于同一分支,作业都只能按照先后顺序运行,一个作业运行完成后再运行下一个作业。
等待的作业的状态为:waiting。
resource_group的值是开发者自己定义的,可以包含字母、数字、_ 、-、 /、 $、 {、 }、.和空格等,但不能以 /开头或结尾。开发者可以在一条流水线中定义多个resource_group。
resource_group关键词也可以用于设置在一个跨项目流水线或父子流水线的作业,这样可以保证在触发下游的流水线时不会有敏感作业在运行。
父级流水线:
build:
stage: build
script: echo "Building..."
test:
stage: test
script: echo "Testing..."
deploy:
stage: deploy
trigger:
include: deploy.gitlab-ci.yml
strategy: depend #在触发子级流水线的作业上必须配置strategy:depend
resource_group: AWS-production #只要子流水线还没有完成,父流水线就不会再次触发流水线,必须等到子级流水线完成后才继续运行
子级流水线
stages:
- provision
- deploy
provision:
stage: provision
script: echo "Provisioning..."
deployment:
stage: deploy
script: echo "Deploying..."
6.6 environment
关键词environment可用于定义部署作业的环境名称。这里的“部署作业”是“泛指”,任何一个作业都可以被看作部署作业。
deploy_test_job:
script: sleep 2
environment: test #定义了一个部署到test环境的作业,并指定了environment为test
当上述作业运行后,项目的Deployments菜单下的Environments列表中会出现一条记录。
在该页面是部署环境概览页,开发者可以自由查看部署到各个环境的作业,包括最新的更新时间、操作人和作业详情等,可非常方便地查看各个部署环境的最新动态。
environment:name用于配置部署环境的名称,可以是文本,也可以是CI/CD中的变量。常见的名称有qa、staging和production。自定义的环境名称只能包含字母、数字、空格以及-、 _、 /、 $、 {、 }等字符。
environment:url用于配置部署环境的访问地址。当一个部署环境配置了访问地址后,在项目Environments列表里,就可以直接单击访问按钮访问到该环境
在开发软件的过程中,有时需要很多个部署环境。有些环境需要长期存在,有些环境只是用于验证某个功能,不需要长期存在。这时,开发者就可以移除某个部署环境,然后在移除环境时触发一个清空部署环境的作业,进而自动释放部署环境的资源。environment:on_stop与environment:action就是做这样的事的
environment:action的值有3个,分别是start(默认值)、prepare和stop。如果没有配置environment:action,就会取默认值start。这样设置后,表明当前作业会部署一次新环境,如果没有则应予以创建。environment:action的值为prepare,表明当前作业正在准备部署环境,还未开始部署环境;environment:action的值为stop,表明当前作业会停止一个部署环境。
environment:auto_stop_in关键词可以用于设置部署环境存留的时间,使用它可以实现在部署环境运行一段时间后,自动移除部署环境。注意,所有移除部署环境的操作都是需要开发者编写具体的作业来完成的,GitLab CI/CD只是提供一个界面上的部署环境管理,并不会真正帮你释放资源、清空配置。environment:auto_stop_in可以配置一段时间,如1 day、1 hour and 30 minutes、1 week。
deploy_test_env:
script:
- echo "Deploy test env"
environment:
name: test
url: https://........ #访问地址
on_stop: clean_test_env #on_stop的值必须是当前流水线中的一个作业名,配置完成后,在单击移除test部署环境后,clean_test_env作业将会执行
auto_stop_in: 1 day
clean_test_env:
script: echo 'stop deploy and clean test env'
when: manual # 设置为手动触发可以避免自动运行造成的不可预期的环境清空
environment:
name: test
action: stop
6.7 services
services关键词可以用于在作业上添加除image之外的Docker镜像,其配置值为镜像名称,这些镜像可以与image指定的镜像通信。关键词services与image都用于配置作业的镜像,但也有区别。首先二者都可以使用default定义一个流水线的全局值,此外两个都可以指定Docker镜像,也可以指定私有仓库的镜像。不同的是,services可以指定多个镜像,而image只能指定一个。此外services主要使用于需要网络访问的场景,如在作业中使用了数据库。image关键词用于普遍的基础镜像(如Python、Node),而services常用于MySQL、Redis。在作业中使用services有两种方式:一种是在GitLab Runner的配置文件config.toml 文件中配置;另一种是在.gitlab-ci.yml文件中配置。
end-test-end:
image: node
services:
- mysql
- postgres:11.7
script:
- echo 'start test'
在上述例子中,我们指定了image:node,表明当前作业在Node.js环境下进行,还引入了两个服务(MySQL与PostgreSQL)。通常情况下,不需要使用两个数据库,这里之所以这样做,只是为了展示services可以配置多个服务。end-test-end作业运行时,会先启动node的容器,然后启动mysql容器与postgres:11.7容器。在启动mysql容器后,如果要给mysql创建数据库和root账号的密码,可以定义两个变量MYSQL_DATABASE和MYSQL_ROOT_PASSWORD,
variables:
MYSQL_DATABASE: fizz
MYSQL_ROOT_PASSWORD: FIZZ_ROOT_PASSWORD
end-test-end:
image: node
services:
- mysql
script: echo 'start test'
在上述例子中,我们创建了一个MySQL服务,并指定了密码和数据库。在应用中使用数据时:
Host: mysql
User: root
Password: FIZZ_ROOT_PASSWORD #
Database: fizz
MySQL服务的Host默认是mysql,其余信息开发者可以自由配置。每个services的host都是由镜像名转换而来的。镜像名转换服务Host的规则为:删除镜像名中冒号及之后的信息,通过将/替换为两个下画线来创建主Host,通过将/替换为-来创建副Host。以GitLab镜像为例,若镜像名称为gitlab/gitlab-ce:latest,生成的Host有两个:一个是gitlab__gitlab-ce;另一个是gitlab-gitlab-ce。
在指定services时,共有5个属性可以配置,分别是name(必填)、entrypoint、command、alias和variables。name用于指定完整镜像名称。entrypoint可以定义一些脚本或命令作为容器的入口。alias是容器的别名。variables可以定义一些服务使用的环境变量(注:14.5版本加入的)。
end-to-end-tests:
image: node:latest
services:
- name: selenium/standalone-firefox:${FIREFOX_VERSION}
alias: firefox
- name: registry.gitlab.com/organization/private-api:latest
alias: backend-api
- postgres:9.6.19
variables:
FF_NETWORK_PER_BUILD: 1
POSTGRES_PASSWORD: supersecretpassword
BACKEND_POSTGRES_HOST: postgres
script:
- npm install
- npm test
6.8 secrets
secrets关键词可以用于配置密钥,这些密钥在作业中可以像CI/CD变量一样使用。这种方式使用了专业的密钥管理平台,因此更加安全、可靠。但使用secrets的前提是GitLab必须是专业版或旗舰版。也就是说,这是一个付费版才有的功能。
密钥与变量不同,它不是直接配置在GitLab中的,secrets使用的密钥功能目前必须由专业的密钥托管商HashiCorp Vault提供。secrets支持两个配置,即secrets:vault与secrets:file。secrets:vault可以配置密钥的路径以及算法,而secrets:file可以控制密钥转化的变量类型为文本格式还是文件格式。
test_secrets:
secrets:
DATABASE_PASSWORD:
vault: production/db/password #变量的值会从HashiCorp Vault的密钥production/db中的password字段取得
file: false # 转化为文本格式的变量
script: echo ${DATABASE_PASSWORD}
在上述例子中,我们使用secrets声明了一个变量DATABASE_PASSWORD,该。这样配置后,密钥转化的变量将会变成文件格式的CI/CD变量。如果要转化为文本格式的变量,则需使用增加file:false,如清单6-26所示。
secrets:file默认设置为true,即默认转化为文件格式的变量。
6.9 dast_configuration
dast_configuration关键词也是一个付费版GitLab提供的功能,该关键词可以根据DAST配置去扫描部署后的网站,检查一些错误的配置以及从源码看不出来的安全隐患。DAST使用的是一个开源工具OWASP Zed Attack Proxy。
stages:
- build
- dast
include:
- template: DAST.gitlab-ci.yml
dast:
dast_configuration:
site_profile: "Example Co"
scanner_profile: "Quick Passive Test"
使用dast_configuration时,开发者直接引入官方流水线模板DAST.gitlab-ci.yml即可。除此之外,应确保作业名称为dast,这样该作业才会合并DAST.gitlab-ci.yml模板中的配置参数。注意,该关键词必须在Docker执行器下使用。
DAST需要在项目Security & Compliance的Configuration中配置。
第7章 GitLab CI/CD部署前端项目
略
第8章 Java复杂微服务应用的CI/CD方案
8.2 CI/CD方案
使用GitLab CI/CD来构建部署复杂应用,首先需要搞清楚应用或者服务之间的依赖关系,并拆分出该应用系统需要多少种部署方案、需要应对哪些部署环境,这些都是需要考虑清楚的。下面我们总结一下复杂应用的构建部署问题及解决途径。
1.一个Git仓库项目包含前端、后端两个应用,如何独立构建、部署?
在这种情况下可以使用rule:change来处理。前端应用的代码变更后触发前端流水线的作业,后端应用的代码变更后触发后端流水线的作业。
2.一个Git仓库项目包含前端、后端两个应用,如何构建出单一镜像?
构建单一镜像能够使软件部署更加快速,这是增效降本的有效手段。为了实现这一目的,需要先将前端构建,然后将用于部署前端的artifacts(一般是静态资源,如HTML、JavaScript、CSS文件)复制到后端应用对应的静态文件目录,最后再统一构建出单一的镜像或其他安装包。
3.如何解决多服务、多项目的大型应用构建部署问题?
如果一个大型应用拆分为5个应用A、B、C、D、E,每个应用对应一个微服务,同时这5个应用对应5个GitLab项目。其中应用A是公共基础模块,所有应用都依赖它,并且应用B依赖其他4个应用。在这种情况下就必须要使用跨项目流水线,使用关键词trigger来触发其他项目流水线。流水线开端要从最基础的应用A开始,将应用A构建后,会产生一个artifacts,以供其他服务使用。GitLab CI/CD支持跨项目的artifacts获取,但这个功能付费版才提供。如果开发者使用的是免费版,可以将artifacts存储到本地或者上传到云端,等到要使用时再从合适的地方获取。这可能需要针对不同的场景编写不同的Dockerfile或者构建命令。
8.4 前、后端单独构建的流水线
有时由于项目开发的需要,在开发和测试期间,需要在开发环境和测试环境前、后端单独部署。这意味着对前端应用构建出一个镜像进行单独部署,对后端应用也需要构建出一个镜像进行单独部署。两个构建是相互独立的。此外,为了保证效率,只有修改了fizz-service目录的文件才会去构建部署fizz-service应用,只有修改了fizz-ui目录的文件才会去构建部署fizz-ui应用。由于这种情况没有应用依赖关系,因此比较好写。
stages:
- install
- test
- build
- package
- deploy
variables:
MAVEN_OPTS: "-Dmaven.repo.local=.m2"
default:
tags:
- docker-runner
fizz-service的流水线:
.service-job-config:
image: maven:3-jdk-8-alpine
before_script:
- cd fizz-service
cache:
key:
files:
- fizz-service/pom.xml
prefix: service
paths:
- fizz-service/.m2
rules:
- if: '$CI_COMMIT_BRANCH == "test" || $CI_COMMIT_BRANCH == "dev"'
changes:
- fizz-service/**/* # 文件改变了则触发。
service-install:
stage: install
extends: [.service-job-config]
script:
- mvn install
service-test:
stage: test
extends: [.service-job-config]
script:
- mvn test
cache:
policy: pull
service-package:
stage: package
extends: [.service-job-config]
script:
- mvn clean package -Dmaven.test.skip=true
artifacts:
paths:
- fizz-service/target/*.jar
cache:
policy: pull
service-docker-deploy:
stage: deploy
extends: [.service-job-config]
cache: []
variables:
IMAGE_NAME: "fizz-service"
APP_CONTAINER_NAME: "fizz-service-app"
image: docker
script:
- docker build --build-arg JAR_FILE=target/fizz-service.jar -t $IMAGE_NAME .
- if [ $(docker ps -aq --filter name=$APP_CONTAINER_NAME) ]; then docker rm -f $APP_
CONTAINER_NAME;fi
- docker run -d -p 8080:8080 --name $APP_CONTAINER_NAME $IMAGE_NAME
environment: test
resource_group: test
fizz-ui的流水线:
.ui-job-config:
image: node:14.17.0-alpine
before_script:
- cd fizz-ui
cache:
key:
files:
- fizz-ui/yarn.lock
prefix: ui
paths:
- fizz-ui/node_modules
rules:
- if: '$CI_COMMIT_BRANCH == "test" || $CI_COMMIT_BRANCH == "dev"'
changes:
- fizz-ui/**/* #文件修改则触发
ui-install:
stage: install
extends: [.ui-job-config]
script:
- yarn
ui-test:
stage: test
extends: [.ui-job-config]
script:
- yarn test
cache:
policy: pull
ui-build:
stage: build
extends: [.ui-job-config]
script:
- yarn build
artifacts:
paths:
- fizz-ui/build
cache:
policy: pull
ui-docker-deploy:
stage: deploy
extends: [.service-job-config]
cache: []
variables:
IMAGE_NAME: "fizz-ui"
APP_CONTAINER_NAME: "fizz-ui-app"
image: docker
script:
- docker build -t $IMAGE_NAME .
- if [ $(docker ps -aq --filter name=$APP_CONTAINER_NAME) ]; then docker rm -f $APP_
CONTAINER_NAME;fi
- docker run -d -p 3000:80 --name $APP_CONTAINER_NAME $IMAGE_NAME
environment: test
resource_group: test
前端和后端的流水线都使用了配置模板,尽可能多地将公共配置信息提取到配置模板中,然后在具体的作业中使用extends 关键词来继承这些配置。例如,后端的每个作业都需要进入fizz-service目录,所以在后端配置模板.service-job-config中才会配置 before_script 为cd fizz-service,以进入后端应用的根目录。后端使用的镜像为maven:3-jdk-8-alpine,前端使用的镜像为node:14.17.0-alpine。流水线的运行都使用rules来限定,如果fizz-service目录下的文件有变动,并且当分支是test或者dev时,就会触发后端的构建作业进而部署。前端作业同理。在流水线中,我们都用了一个文件来当作缓存key,以此来保证缓存的及时更新和唯一性。流水线运行完成后,前端应用将被部署在3000端口,后端应用将被部署在8080端口。
8.5 构建单镜像
对前、后端单独构建出镜像是比较简单的事情,因为它们是相互独立的,不存在先后和依赖关系。但有时为了提高项目的交付能力,开发者需要对外提供产品的单镜像,只要有单镜像就能够提供软件所有的服务,这种方式能够使软件使用更加简单、方便,对于新手也非常友好。这个时候就需要构建单镜像的方案。构建单镜像主要是在后端应用构建前,需要将前端的artifacts 放到后端的静态目录中,这样构建出的镜像就会包含前、后端所有的代码。fizz-service应用的静态目录是/src/main/resources/static,在该目录下的所有文件都能够被用户直接访问。所以在流水线中,我们只需要将fizz-ui构建出的build目录中的所有文件复制到fizz-service/src/main/resources/static目录中,再进行fizz-service应用的构建即可。此处我们假设构建单镜像的时机是开发者创建了一个git tag,那么构建单镜像的流水线全局配置如清单8-8所示。
清单8-8 构建单镜像的流水线全局配置
stages:
- install
- test
- build
- package
- deploy
variables:
MAVEN_OPTS: "-Dmaven.repo.local=.m2"
default:
tags:
- docker-runner
workflow:
rules:
- if: $CI_COMMIT_TAG
include:
- local: fizz-service/.gitlab-ci-service.yml
- local: fizz-ui/.gitlab-ci-ui.yml
上述代码是fizz-mall根目录下.gitlab-ci.yml文件的全部内容。流水线共包括5个阶段,分别是install、test、build、package和deploy。此外,定义一个环境变量maven设置存放依赖包的目录为.m2。该流水线只使用tags为docker-runner的runner来执行。另外,我们将fizz-service的流水线与fizz-ui的流水线分别定义在各自的文件目录下,拆分后使用关键词include来引入。这样拆分后,好处是fizz-ui的流水线可以由fizz-ui的开发人员来管理、修改。使用workflow:rules来保证流水线只有在创建git tag时才会被触发。
8.5.1 前端UI流水线
在fizz-ui目录下创建.gitlab-ci-ui.yml文件,用来定义fizz-ui的相关作业。.gitlab-ci-ui.yml文件的内容如清单8-9所示。
清单8-9 .gitlab-ci-ui.yml文件的内容
.ui-job-config:
image: node:14.17.0-alpine
before_script:
- cd fizz-ui
cache:
key:
files:
- fizz-ui/yarn.lock
prefix: ui
paths:
- fizz-ui/node_modules
ui-install:
stage: install
extends: [.ui-job-config]
script:
- yarn
ui-test:
stage: test
extends: [.ui-job-config]
script:
- yarn test
cache:
policy: pull
ui-build:
stage: build
extends: [.ui-job-config]
script:
- yarn build
artifacts:
paths:
- fizz-ui/build
cache:
policy: pull
在.gitlab-ci-ui.yml文件中,我们定义了前端流水线的公共配置、要使用的镜像、前端缓存,以及任务执行前运行的脚本。有些读者会有疑问,.gitlab-ci-ui.yml本身已经位于fizz-ui目录了,为什么在运行时还要进入fizz-ui目录?这是因为通过include引入的其他YAML文件最后都会合并到项目根目录下的.gitlab-ci.yml文件中,所以流水线运行的默认工作目录就是项目的根目录,不管.gitlab-ci.yml文件位于项目的哪个目录下。在前端的流水线中,我们会去安装前端依赖包、运行测试用例,最后编译,并将编译后的文件做成artifacts存放到GitLab上。这里有一个小的优化是缓存的设置,通过设置cache的poilicy属性,缓存只在ui-install作业里进行上传、下载,其他的作业上只下载不上传。这样在缓存大或网络不好的情况下可以加快流水线运行速度。
8.5.2 后端服务流水线
在fizz-service目录下创建.gitlab-ci-service.yml文件,该文件的内容如清单8-10所示。
清单8-10 .gitlab-ci-service.yml文件的内容
.service-job-config:
image: maven:3-jdk-8-alpine
before_script:
- cd fizz-service
cache:
key:
files:
- fizz-service/pom.xml
prefix: service
paths:
- fizz-service/.m2
service-install:
stage: install
extends: [.service-job-config]
script:
- mvn install
service-test:
stage: test
extends: [.service-job-config]
script:
- mvn test
cache:
policy: pull
service-package:
stage: package
extends: [.service-job-config]
script:
- cp -rf ${CI_PROJECT_DIR}/fizz-ui/build/* ${CI_PROJECT_DIR}/fizz-service/src/main/
resources/static
- mvn clean package -Dmaven.test.skip=true
artifacts:
paths:
- fizz-service/target/*.jar
cache:
policy: pull
docker-build:
stage: deploy
extends: [.service-job-config]
cache: []
dependencies:
- service-package
variables:
IMAGE_NAME: "fizz-mall"
APP_CONTAINER_NAME: "fizz-mall-app"
image: docker
script:
- docker build --build-arg JAR_FILE=target/fizz-service.jar -t $IMAGE_NAME .
- if [ $(docker ps -aq --filter name=$APP_CONTAINER_NAME) ]; then docker rm -f $APP_
CONTAINER_NAME;fi
- docker run -d -p 8090:8080 --name $APP_CONTAINER_NAME $IMAGE_NAME
environment: prod
resource_group: prod
与前端流水线一致,后端流水线也提取了公共的配置模板.service-job-config,使用统一的镜像、缓存和作业预运行脚本。作业service-install用于安装项目所需依赖包,安装完成后将之放置在缓存中以备后用。作业service-test会加载缓存,并执行项目中编写的测试用例,执行通过后继续往下执行。在作业service-package中,首先将前端目录fizz-ui/build的所有文件都复制到/fizz-service/src/main/resources/static目录下。这一步一定要在前端构建后再执行,否则是没有build 目录的,这也是package 阶段在build 阶段之后的原因。将文件复制后,执行后端的打包命令 mvn clean package -Dmaven.test.skip=true。为了不重复执行测试用例,添加参数-Dmaven.test.skip=true可以跳过。执行打包命令后,会在fizz-service/target目录下生成一个JAR包。有了这个JAR包,我们就能在下一阶段构建出一个包含前、后端的镜像。在service-package阶段需要提取fizz-service/target下的JAR包,做成artifacts以备下一阶段使用。
在docker-build作业中,我们使用了上一阶段service-package作业编译出的JAR包,将其构建到镜像中,最后再运行构建出的镜像以实现重新部署,也可以将构建出的镜像推送到DockerHub或者私有Harbor。
8.6 使用分布式缓存MinIO
在使用本地缓存时,如果一条流水线中存储两个key的缓存,有时会导致缓存恢复失败。具体细节可以看官方仓库下的Issues:Using multiple caches in gitlab ci broken when not using distributed caching。此外,使用本地缓存,无法解决不同计算机、不同runner缓存一致的问题。要解决上述问题,一种可行的方案是使用分布式缓存。
8.6.1 使用Docker安装MinIO
略
8.6.2 配置GitLab Runner使用MinIO存储缓存
要配置某一个 runner 使用分布式缓存,需要修改 GitLab Runner的配置文件,在/srv/gitlab-runner/config/config.toml文件中找到对应的runner,修改[runners.cache]与[runners.cache.s3]部分的配置:
[runners.cache]
Type = "s3"
Path = "prefix"
Shared = false
[runners.cache.s3]
ServerAddress = "172.17.0.4:9000"
AccessKey = "12345678"
SecretKey = "87654321"
BucketName = "fizz-minio"
Insecure = true
在[runners.cache]配置块下,Type设置为s3,Path用于定义存储文件的前缀路径,Shared 则表明是否可以共享。开启共享后,存储缓存的路径中将不带有项目路径。可以实现跨项目使用缓存,前提是缓存的key一致。
在[runners.cache.s3]配置下,需要填写MinIO的服务地址,格式为Host+端口号。AccessKey 与 SecretKey 需要使用上一步下载的。BucketName就是上一步创建的Bucket,名为fizz-minio。Insecure表明是否使用HTTPS来请求接口,如果没有开启TSL服务,需要设置为true才能正确调用接口。
配置GitLab Runner后,再次运行流水线,就会发现缓存已经上传到MinIO了,
8.7 多项目微服务依赖构建单应用
随着业务的发展,菲兹商城不断增加新的功能,整个系统也变得太过臃肿。架构组准备将系统拆分为多个微服务,在开发测试环境使用微服务部署。新版本不仅提供微服务部署方式,还提供单镜像部署方式。在改造软件架构的同时,项目CI/CD流水线也需要进行改造与优化。
8.7.1 项目背景及软件架构
拆分后的菲兹商城包含以下几个微服务。
● 应用入口,基础应用,对应fizz-mall-common项目。
● 用户服务,提供用户授权、用户基本信息管理功能,对应fizz-mall-user项目。
● 商品服务,提供商品管理功能,对应fizz-mall-product项目。
● 订单服务,提供订单管理功能,对应fizz-mall-order项目。
● 前端项目,提供UI交互功能,对应fizz-mall-ui项目。
5个项目都位于GitLab的fizz-mall项目组中,这样做便于管理。权限的设置、CI/CD变量的定义,都会比较省事。5 个项目的依赖关系如下:fizz-mall-common 依赖fizz-mall-ui与fizz-mall-user,fizz-mall-user依赖fizz-mall-product与fizz-mall-order。
8.7.2 多项目同时构建
由于是菲兹商城的代码分布在5个GitLab项目里,因此在构建单镜像时,要使用跨项目流水线。这时可以使用关键词trigger,也可以使用curl 命令加trigger token的方式。为了方便,我们使用关键词trigger。由于fizz-mall-common是最基础的包,因此我们将它作为流水线的开端,由它触发其他项目流水线。
stages:
- prestart
- install_trigger
- build
- package
- deploy
variables:
MAVEN_OPTS: "-Dmaven.repo.local=.m2"
default:
image: maven:3-jdk-8-alpine
tags:
- docker-runner
cache:
key:
files:
- pom.xml
paths:
- .m2
prepare_job:
stage: prestart
script:
- echo 'create or clean directory'
- echo 'prepare environment'
install_job:
stage: install_trigger
script:
- echo 'install depe'
trigger_user_job:
stage: install_trigger
trigger:
project: fizz-mall/fizz-mall-user
branch: main
strategy: depend
trigger_ui_job:
stage: install_trigger
trigger:
project: fizz-mall/fizz-mall-ui
branch: main
strategy: depend
trigger_order_job:
stage: install_trigger
trigger:
project: fizz-mall/fizz-mall-order
branch: main
strategy: depend
trigger_product_job:
stage: install_trigger
trigger:
project: fizz-mall/fizz-mall-product
branch: main
strategy: depend
build_common_job:
stage: build
needs: [install_job]
script: echo 'start build'
package_job:
stage: package
script: echo 'start package'
deploy_job:
stage: deploy
script: echo 'start deploy'
在fizz-mall-common的流水线中,安装项目依赖与触发下游流水线可以同时进行(这里假设fizz-mall-user只影响fizz-mall-common的编译,而不影响安装依赖和测试)。
8.7.3 依赖构建
项目依赖有两种:一种是运行顺序的依赖,例如,fizz-mall-order的构建作业必须要在fizz-mall-user构建作业之前,否则会找不到对应的依赖;另一种是artifacts的依赖,例如,fizz-mall-user在构建的时候,必须拿到fizz-mall-user和fizz-mall-product。顺序的依赖关系可以通过关键词的配置来实现,例如使用关键词need来配置两个作业的依赖关系。如果是跨项目流水线,开发需要保证下游流水线运行完成后,再继续运行主流水线,可以将trigger:strategy设置为depend。跨项目流水线也遵循stages的顺序。GitLab CI/CD支持跨项目流水线的artifacts依赖,可使用needs:project。使用它可以指定获取GitLab中具体项目生成的artifacts,可以指定Git分支、作业名称。但这是一个付费版才有的功能,免费用户是无法使用的。如果有类似跨项目的流水线artifacts依赖,可以使用下面两种方法。
● 在流水线的runner中挂载一个同步读写的主机目录或者一个数据卷,流水线构建出artifacts后,假设为一个JAR包或者一个文件夹,可以将这些artifacts复制到挂载的目录中,这样就简单地实现了artifacts持久化。
● 直接将artifacts上传到对应的存储平台,如构建的Docker镜像可以推送到自建的Harbor中,JAR包制品可以上传到maven中央仓库Nexus,构建的文件可以上传到MinIO等分布式存储系统,等到使用的时候再下载。
8.7.4 自由选择分支tag构建
通常情况下,每一个项目发布版本都会创建一个tag,并根据该tag发布对应的版本。但有时候开发者并不遵循这一规定,比如为了修复一个线上bug,开发者为了减少工作量,会只替换某个应用的版本,这个时候我们的流水线就需要能够自由选定每个项目的分支或tag。自由定义构建项目的分支一般使用Web的方式填写变量,然后使用该变量来触发项目对应的分支或tag流水线。
ready_job:
stage: prebuild
script:
- if [ $USER_REF == '']; then echo "USER_REF=${ALL_REF}" >> build.env; fi;
- if [ $PRODUCT_REF == '']; then echo "PRODUCT_REF=${ALL_REF}" >> build.env; fi;
- if [ $ORDER_REF == '']; then echo "ORDER_REF=${ALL_REF}" >> build.env; fi;
- if [ $UI_REF == '']; then echo "UI_REF=${ALL_REF}" >> build.env; fi;
artifacts:
reports:
dotenv: build.env
由于运行流水线时需要自由填写每个项目要构建的分支或tag,此时就需要进行变量的处理,定义一个变量ALL_REF为统一构建的分支。如果没有为某个项目定义分支变量,则使用ALL_REF来确定该项目要构建的分支。在上述的作业中,变量USER_REF用于定义fizz-mall-user的构建分支,如果没有定义该变量,则使用变量ALL_REF的值。其他变量PRODUCT_REF、ORDER_REF、UI_REF同理。除此之外,我们为这些变量重新赋值后,需要将其追加到build.env文件中,并保存为artifacts。使用artifacts:reports:dotenv这种方式生成的artifacts,文件中的内容会在后续的作业中转化为变量,这是artifacts关键词的一个特殊用法。很多人不理解为什么要这样做,为什么变量重新赋值后还要保存到文件中,并且做成artifacts?这是因为在流水线中,编写Shell脚本并不像在主机上那样方便。因为流水线的脚本是运行在runner的执行器中的,执行器是多种多样的,执行环境也多种多样,并且一条流水线有可能不止一个runner,所以当开发者在一个作业的script中改变了一个全局变量的值后,只能在当前的作业中生效,在下一个作业中该全局变量还是初始值。
处理完变量后,触发下游流水线时就可以使用变量来定义需要构建的分支:
trigger_user_pipeline:
stage: trigger
trigger:
project: fizz-mall/fizz-mall-user
branch: $USER_REF
strategy: depend
only:
- Web
trigger_product_pipeline:
stage: trigger
trigger:
project: fizz-mall/fizz-mall-product
branch: $PRODUCT_REF
strategy: depend
only:
- Web
在fizz-mall-common的流水线中,使用关键词trigger来触发下流跨项目的流水线。配置项目地址与分支,并配置strategy:depend,以保证下游流水线完成后再继续执行主流水线。only:Web 可以限定当前作业只有在通过Web触发流水线时才会被执行。对于一些通用的配置,我们都可以将其提取到一个配置模板中,再使用extends来继承。
8.7.5 运行流水线
如果流水线是由git tag来触发的,那么流水线可以设置为自动,然后将部署作业设置为手动,但由于需要自由选择每个项目的构建分支,因此运行流水线时还需要支持Web触发并设置变量,在GitLab中手动触发流水线并配置变量
第9章 部署Python应用到Kubernetes中
略
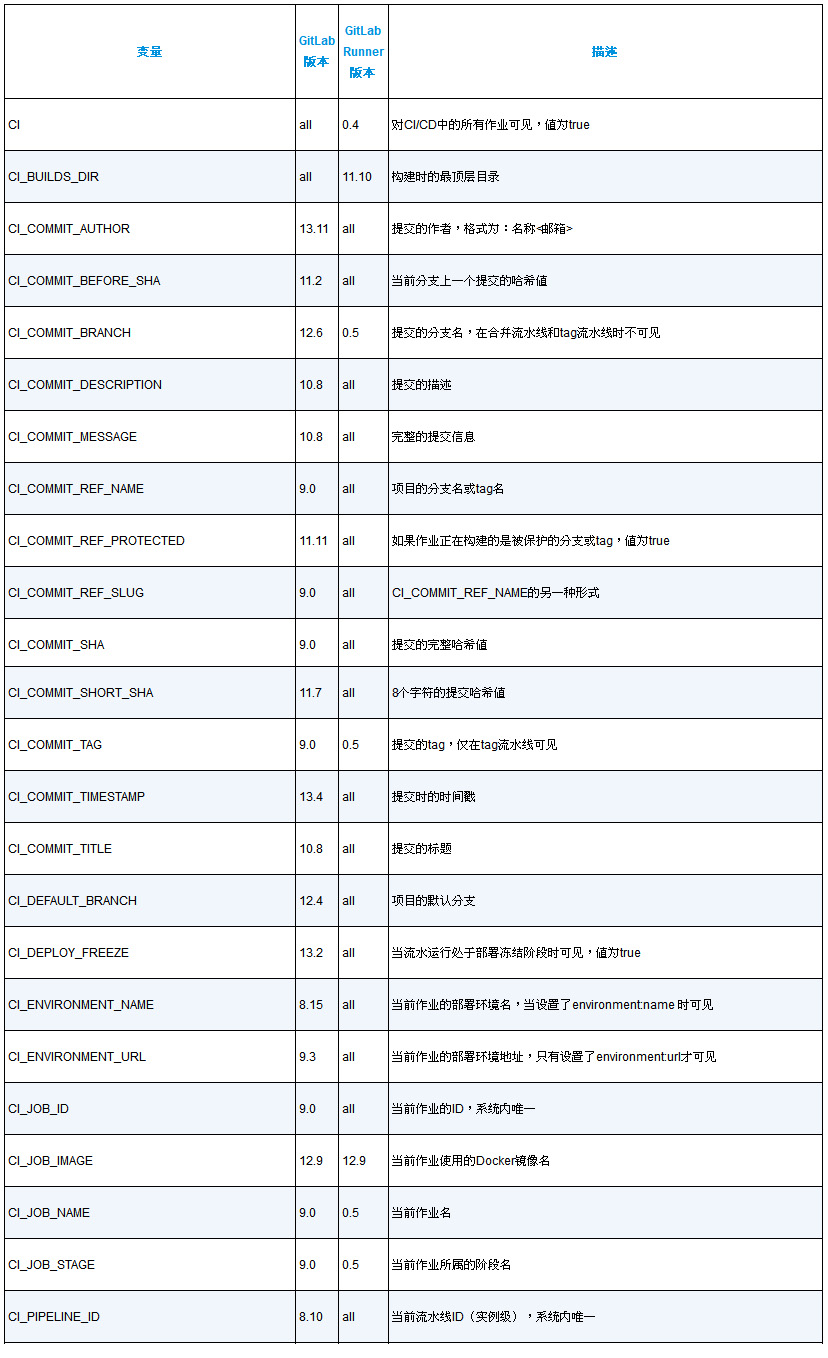
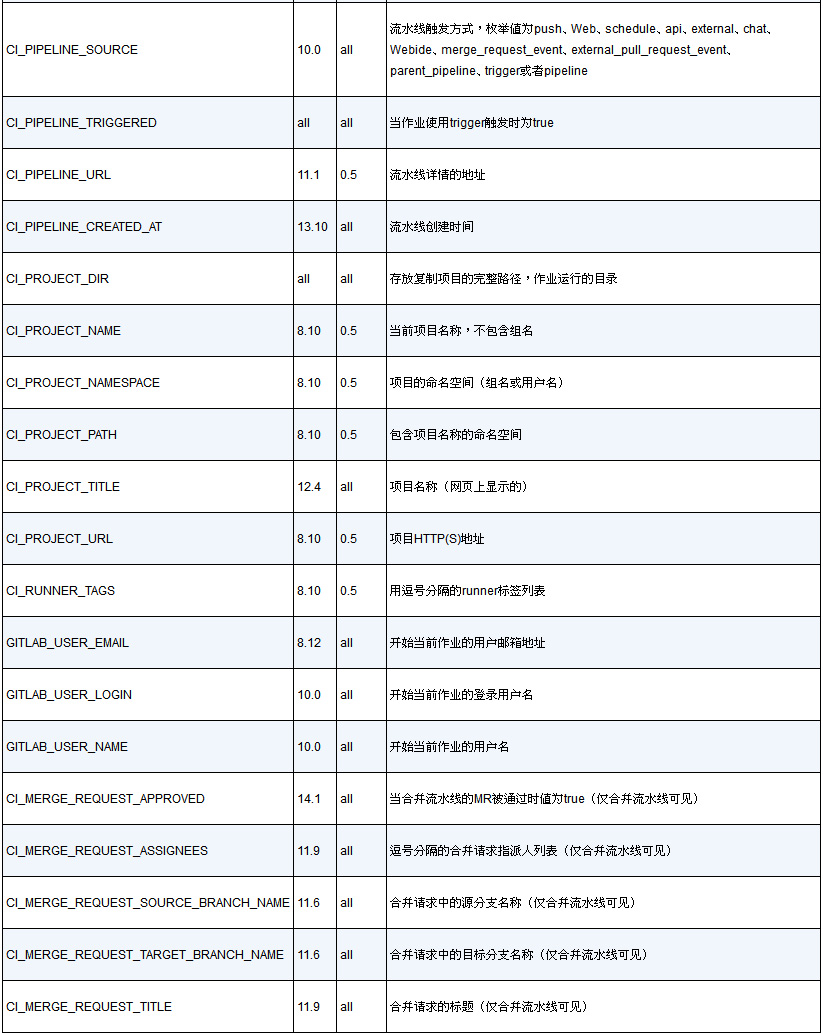
附录1 GitLab CI/CD中的预设变量











![[C++] 剖析多态的原理及实现](https://img-blog.csdnimg.cn/img_convert/87b4893ba2799adebf972685351c6b2d.png)





