文章目录
- 前言
- 原理
- 使用方法(初级)
- 代码实例
- Prophet 高级应用
- add_seasonality 添加自定义周期性
- add_regressor 添加外生变量
- 交叉检验
前言
Prophet 是 Facebook 团队开发的一个时间序列分析工具,相比传统的 ARMA 时间序列分析,能够综合考虑节假日、季节等因素的影响,非常适合现实生活中具有相应特点的数据。适用背景:和现实生活联系紧密,时间跨度比较长,具有一定周期性和偶然性的时间序列。往往涉及到经济、商业等方面的问题。
这一篇 CSDN 博客已经对 Prophet 作出了较为完整的一个阐述,包括原理和应用等方面,本文会深入 Python 代码介绍 Prophet 库的另一些重要参数,相当于是 Prophet 的拓展应用,对原理则简单介绍。
附上 Prophet 论文的网址:Forecasting at scale (peerj.com)。数学建模的时候若使用 Prophet,可以在原论文中摘取一些原理的介绍。
原理
给定一系列 (日期,值) 或者说
(
t
i
,
y
i
)
(t_i,y_i)
(ti,yi) 的序列,直接调用 Prophet 模型即可直接拟合出未来日期的结果。Prophet 适用于具有明显的内在规律的商业行为数据。prophet 模型将
y
(
t
)
y(t)
y(t) 拆解为:
y
(
t
)
=
g
(
t
)
+
s
(
t
)
+
h
(
t
)
+
ε
(
t
)
y(t)=g(t)+s(t)+h(t)+\varepsilon (t)
y(t)=g(t)+s(t)+h(t)+ε(t)
其中:
- g ( t ) g(t) g(t) 表示趋势项,它表示时间序列在非周期上面的变化趋势。
- s ( t ) s(t) s(t) 表示周期项,或者称为季节项,一般来说是以周或者年为单位。
- h ( t ) h(t) h(t) 表示节假日项,表示时间序列中那些潜在的具有非固定周期的节假日对预测值造成的影响。
- ε ( t ) \varepsilon (t) ε(t) 即误差项或者称为剩余项,表示模型未预测到的波动,服从高斯分布。
使用方法(初级)
注意:数据中的异常点直接赋值为None即可,因为Prophet的设计中可以通过插值处理缺失值。但是 Prophet 对异常值比较敏感。
Prophet 方法的常见参数有:
growth:模型的增长趋势,默认值growth = 'linear',但是如果认为是 Logistic 增长,可以使用growth = 'logistic'。使用 Logistic 模型需要设置容量值 capacity 参数,具体怎么设置可以查看相关文章。changepoints:如果知道某些日期肯定是转折点,那么可以人为地添加。yearly_seasonality:是否分析年季节性,即是否画相应的图。同理还有参数weekly_seasonality和daily_seasonality。holidays:有的时候,add_country_holidays导入的未必是完整的节日,一些洋节也会在中国产生影响,此时需要手动添加。可以有这样的holidays:
# 下面的 playoffs 添加的节假日包括:
# 2024-01-13 2024-01-14 2024-01-15
# 2024-05-13 2024-05-14 2024-05-15
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2024-01-14', '2024-05-14']),
'lower_window': -1,
'upper_window': 1,
})
mcmc_samples:一个非常神奇的参数。默认的mcmc_samples=0,当传入这个参数为非零值时,分解图开始出现置信区间。changepoint_prior_scale:控制 Prophet 模型对转折点的敏感程度,默认值 0.05 0.05 0.05。其值越大时,模型更容易检测到时间序列中的转折点,但是缺点是容易过拟合;其值越小时,不太容易过拟合,但是对一些转折点的识别能力较差。具体可看下面两张图对比:


参考文献:Facebook Prophet使用与调参实践 – 标点符
代码实例
import pandas as pd
import numpy as np
from prophet import Prophet
import datetime as dt
import matplotlib.pyplot as plt
# 准备数据
np.random.seed(114)
data = pd.DataFrame({
'ds': [dt.date(2024,1,1) + dt.timedelta(i) for i in range(100)],
'y': 10 + (np.sin(range(100)) * 0.3 + np.arange(100) * 0.2) * np.random.rand(100)
})
# 创建模型
model = Prophet(growth='linear',
yearly_seasonality=True,
weekly_seasonality=True,
# changepoints = ['2024-01-03']
# 可以添加转折点但是必须是 ds 里面有的日期
interval_width=0.95)
# 添加传统节日效应
model.add_country_holidays(country_name='CN')
# 拟合模型
model.fit(data)
# 预测未来值
future = model.make_future_dataframe(periods=50) # period = 50 代表预测未来 50 天的数据
forecast = model.predict(future)
# 可视化预测结果
model.plot(forecast)
plt.savefig("预测.pdf")
model.plot_components(forecast)
plt.savefig("分解.pdf")

上图是“预测.pdf”。值得一提的是,因为我们设置了年周期性和周周期性分析选项,预测图中在一个月后出现了较大抖动,分解图中也有yearly分量。在取消yearly_seasonality=True,以及weekly_seasonality=True的设置之后,预测图变成下图,分解图中yearly也将消失。

下面这张图是“分解.pdf”:

Prophet 高级应用
&emsp上面通过Prophet方法得到了模型model,实际上这个model对象还有一些方法可以满足我们一些额外的需求。
add_seasonality 添加自定义周期性
添加自定义周期性之后,模型的原理是不变的,即
y
(
t
)
=
g
(
t
)
+
s
(
t
)
+
h
(
t
)
+
ε
(
t
)
y(t)=g(t)+s(t)+h(t)+\varepsilon (t)
y(t)=g(t)+s(t)+h(t)+ε(t)。只不过此时的
s
(
t
)
s(t)
s(t) 就会单独考虑添加一个新的周期性分量了。比如我已知存在有一个
T
=
14
d
T=14\mathrm d
T=14d (
d
\mathrm d
d 表示天)的影响因子,那么在得到model对象后可以加入下面的代码:
model.add_seasonality('genshin', period=14, fourier_order=2)
这将带来以下区别:
- Prophet 模型会考虑你所谓的
T
=
14
d
T=14\mathrm d
T=14d 的周期性分量,提取出这样的成分,画在分解图中。这个周期性分量的表达式为:
p ( t ) = ∑ n = 1 N [ a n cos ( 2 π n t / T ) + b n sin ( 2 π n t / T ) ] p(t)=\sum_{n=1}^{N}{[}{{a}_{n}}\cos{(}2\pi nt/T)+{{b}_{n}}\sin{(}2\pi nt/T)] p(t)=n=1∑N[ancos(2πnt/T)+bnsin(2πnt/T)]
这里的
N
N
N 就是上面的fourier_order,
T
T
T 就是上面的T。
- 人为加入这一行代码,与不加入相比,预测结果会产生一点偏差。如果你找的规律好,预测当然会更准确。
add_regressor 添加外生变量
外生变量指的就是和预测变量存在关联关系的变量。比如预测的y的含义是销量,那么就可以将价格作为外生变量传入 Prophet 模型中。
训练时使用外生变量,只需在传入Prophet方法的 DataFrame 里面加入新的列。例如,如下所示加入价格列price(其长度与其他列相同):
data = pd.DataFrame({
'ds': [dt.date(2024,1,1) + dt.timedelta(i) for i in range(100)],
'y': 10 + (np.sin(range(100)) * 0.3 + np.arange(100) * 0.2) * np.random.rand(100),
'price': [……] # 自己填充数据
})
其他地方原封不动即可。Prophet模型在训练时会考虑到这些,从而变成多变量时间序列预测模型。
在预测时,我们需要给出外生变量的值,从而让模型能够预测。在上面的代码中我们得到了一个叫做future的 DataFrame:
future = model.make_future_dataframe(periods=50) # period = 50 代表预测未来 50 天的数据
实际上,我们只需要设置future['price'] = [……](给一个长为 periods = 50 的列表),就可以调用forecast = model.predict(future)进行预测。加入了外生变量的总代码如下:
import pandas as pd
import numpy as np
from prophet import Prophet
import datetime as dt
import matplotlib.pyplot as plt
# 准备数据
np.random.seed(114)
data = pd.DataFrame({
'ds': [dt.date(2024,1,1) + dt.timedelta(i) for i in range(100)],
'y': 10 + (np.sin(range(100)) * 0.3 + np.arange(100) * 0.2) * np.random.rand(100),
# 注意这里需要填入外生变量
'price': [……]
})
# 创建模型
model = Prophet(growth='linear',
yearly_seasonality=True,
weekly_seasonality=True,
# changepoints = ['2024-01-03']
# 可以添加转折点但是必须是 ds 里面有的日期
interval_width=0.95)
# 添加传统节日效应
model.add_country_holidays(country_name='CN')
# 拟合模型
model.fit(data)
# 预测未来值
future = model.make_future_dataframe(periods=50) # period = 50 代表预测未来 50 天的数据
# 注意这里需要给出预测的 periods = 50 天时间内外生变量 price 的实际值
future['price'] = [……]
forecast = model.predict(future)
# 可视化预测结果
model.plot(forecast)
plt.savefig("预测.pdf")
model.plot_components(forecast)
plt.savefig("分解.pdf")
参考文献:【时序分析】Prophet模型中使用外生变量、自定义周期性_prophet如何自定义周期-CSDN博客
交叉检验
参考文献:
- 掌握时间波动:借助时间序列交叉验证技术提升预测精准度-CSDN博客
- prophet Diagnostics诊断-腾讯云开发者社区-腾讯云
Prophet 预测的效果好不好,需要进行交叉检验。Prophet 用下面的方式交叉检验:
# 接着上面的代码
from prophet.diagnostics import cross_validation
df_cv = cross_validation(model, initial='50 days', period='10 days', horizon = '5 days')
# 一般设置参数 initial = 3 * horizon,period = 0.5 * horizon,当然可以调整一下达到最好效果
交叉检验基于已给的前initial天(可能有一些偏差)的数据,预测紧接着horizon天的数据。然后将initial自增period,重复操作……直到已有数据用完。上面代码生成的数据如下,这个y是实际值,yhat是根据已有数据的估计值。
ds yhat yhat_lower yhat_upper y cutoff
0 2024-02-25 16.388943 14.007529 18.943522 13.804077 2024-02-24
1 2024-02-26 17.330200 14.915873 19.953441 20.031500 2024-02-24
2 2024-02-27 19.368427 16.741796 21.909734 20.663439 2024-02-24
3 2024-02-28 19.180708 16.633248 21.765376 16.081144 2024-02-24
4 2024-02-29 20.501733 17.950074 23.024951 18.069711 2024-02-24
5 2024-03-06 12.081063 9.124616 15.339416 11.955349 2024-03-05
6 2024-03-07 10.326309 7.134838 12.963412 12.771650 2024-03-05
7 2024-03-08 6.582040 3.493560 9.725560 10.321305 2024-03-05
8 2024-03-09 2.564637 -0.545879 5.474141 17.704553 2024-03-05
9 2024-03-10 -2.144653 -5.084986 0.953620 16.517561 2024-03-05
10 2024-03-16 19.026456 15.343248 22.797478 16.060686 2024-03-15
…… …… …… …… …… …… ……
仍然不够直观,调库计算上面的误差:
from prophet.diagnostics import performance_metrics
df_p = performance_metrics(df_cv)
"""
结果:
horizon mse rmse ... mdape smape coverage
0 1 days 69.840361 8.357055 ... 0.187254 0.354367 0.4
1 2 days 47.651266 6.902990 ... 0.191466 0.385643 0.4
2 3 days 72.913272 8.538927 ... 0.362286 0.529062 0.4
3 4 days 224.096939 14.969868 ... 0.609604 0.999131 0.0
4 5 days 285.191131 16.887603 ... 1.129841 1.205107 0.2
"""
这里的 mse,…,smape 是不同角度的误差衡量方式,显然其值越小越好。均方误差 mse 对异常值非常敏感,故大多都是选择 mape 误差。认为 mape 误差在 20 % 20\% 20% 以内,prophet 的拟合效果就还可以,也即问题适合使用 prophet 模型。
这个 coverage 目前还找到一篇博客说清楚他到底是啥,但知道它越大越好,在 70 % 70\% 70% 以上则说明 prophet 模型较为合适。
将上面的误差可视化,这里选择 mape 误差:
from prophet.diagnostics import plot_cross_validation_metric
fig = plot_cross_validation_metric(df_cv, metric='mape')
作出来结果如下。百分比绝对误差达到了 1,说明参数调得非常烂。这是因为我乱生成的数据,实际数据肯定是有点周和年的规律的。在取消yearly_seasonality=True,weekly_seasonality=True的设置之后就好多了。


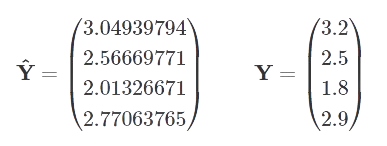








![[C++] 剖析多态的原理及实现](https://img-blog.csdnimg.cn/img_convert/87b4893ba2799adebf972685351c6b2d.png)







