参考:
https://mp.weixin.qq.com/s?__biz=MjM5ODIwNjEzNQ==&mid=2649887403&idx=3&sn=f61fc0e238ffbc56a7f1249b93c20690&chksm=bfa0f632460e035f00be6cc6eb09637d91614e4c31da9ff47077ca468caad1ee27d08c04ca32&scene=27
https://cloud.tencent.com/developer/article/2351793
一:什么是生成式对抗网络(GAN)?
GANs是由Ian Goodfellow和其他蒙特利尔大学的研究人员,包括Yoshua Bengio,在2014年6月的论文《生成对抗网络》中介绍的一种新型神经网络架构。
GANs最显著的特点是它们能够创建超现实主义的图像、视频、音乐和文本。GANs有能力从训练图像中学习特征,并利用这些学到的模式想象出它们自己的新图像。例如,图1中展示的图像就是使用GANs模型生成的。
二:GANs架构
GANs基于对抗训练的思想。它们基本上由两个相互竞争的神经网络组成。这种竞争性帮助它们模仿任何数据分布。
我们可以将GAN架构想象成两个拳击手的战斗。在他们征服游戏的过程中,双方都在学习对方的移动和技巧。他们开始时对对手了解不多。随着游戏的进行,他们学习并变得越来越好
另一个帮助理解GANs想法的类比:将GANs想象成一个伪造者和一个警察在一场猫捉老鼠的游戏中的对立,其中伪造者正在学习通过假钞,而警察正在学习检测它们。双方都在动态变化。
这意味着,随着伪造者学习完善制造假钞,警察也在训练并变得更好,双方都在不断升级中学习对方的方法。
GAN架构由两个主要网络组成:
1.生成器:试图将随机噪声转换为看起来像是从原始数据集中采样的观测值。
2.鉴别器:试图预测一个观测值是来自原始数据集还是生成器的伪造品。

GAN架构
GAN所采取的步骤如下:
1.生成器接收随机数字并返回一个图像。
2.这个生成的图像与从实际的、真实的数据集中取出的图像一起输入到鉴别器中。
3.鉴别器接收真实和假图像,并返回概率,一个介于0和1之间的数字,1代表预测的真实性,0代表伪造。
如果仔细观察生成器和鉴别器网络,会发现生成器网络是一个倒置的ConvNet,从压平的向量开始,然后图像被放大,直到它们与训练数据集中的图像具有相似的大小。
三:深度卷积GANs(DCGANs)
在2014年的原始GAN论文中,使用多层感知器(MLP)网络构建了生成器和鉴别器网络。然而,从那时起,已经证明卷积层能够增强鉴别器的预测能力,这反过来又提高了生成器和整体模型的准确性。这种类型的GAN被称为DCGAN(深度卷积GAN)。
现在,所有GAN架构都包含卷积层,因此当我们谈论GAN时,“DC”已被暗含在内
四:鉴别器网络
鉴别器的目标是预测图像是真实的还是假的。这是一个典型的监督分类问题,所以我们可以使用传统的分类器网络。
网络由堆叠的卷积层组成,接着是一个带有sigmoid激活函数的密集输出层。我们使用sigmoid激活函数,因为这是一个二元分类问题,网络的目标是输出介于0和1之间的概率预测值。其中0意味着生成器生成的图像是假的,1意味着它是真的。
在图4中,我们可以看到GAN模型的鉴别作用,它接收两组图像。第一个是来自训练集的真实图像,第二个是假的,由生成器模型生成。

图4 运行中的 GAN 模型判别器

图5 鉴别器模型的架构
训练鉴别器相当直接,因为它类似于传统的监督分类问题,我们用标记的图像来喂养鉴别器:假的(或生成的)和真实的图像。真实图像来自训练数据集,假图像是生成器模型的输出。
让我们在Keras中实现鉴别器网络,以了解其工作原理。鉴别器模型中没有什么新东西。它遵循传统的CNN网络的常规模式。
我们将堆叠卷积、批量归一化、激活和dropout层来创建我们的模型。所有这些层都有我们在训练网络时调整的超参数。对于您自己的实现,您可以调整这些超参数,并根据需要添加或删除层。
def discriminator_model():
# 实例化一个顺序模型并将其命名为鉴别器
discriminator = Sequential()
# 向鉴别器模型添加一个卷积层
discriminator.add(Conv2D(32, kernel_size=3, strides=2, input_shape=(28,28,1),
padding="same"))
# 添加一个leakyRelu激活函数
discriminator.add(LeakyReLU(alpha=0.2))
# 添加一个dropout层,dropout概率为25%
discriminator.add(Dropout(0.25))
# 添加第二个卷积层,带有零填充
discriminator.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
discriminator.add(ZeroPadding2D(padding=((0,1),(0,1))))
# 添加一个批量归一化层,以加快学习和提高准确性
discriminator.add(BatchNormalization(momentum=0.8))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Dropout(0.25))
# 添加第三个卷积层,带有批量归一化、leakyRelu和dropout
discriminator.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
discriminator.add(BatchNormalization(momentum=0.8))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Dropout(0.25))
# 添加第四个卷积层,带有批量归一化、leakyRelu和dropout
discriminator.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
discriminator.add(BatchNormalization(momentum=0.8))
discriminator.add(LeakyReLU(alpha=0.2))
discriminator.add(Dropout(0.25))
# 展平网络并添加输出Dense层,带有sigmoid激活函数
discriminator.add(Flatten())
discriminator.add(Dense(1, activation='sigmoid'))
# 打印模型摘要
discriminator.summary()
# 设置输入图像形状
img = Input(shape=img_shape)
# 运行鉴别器模型以获得输出概率
probability = discriminator(img)
# 返回一个模型,它将图像作为输入并产生概率输出
return Model(img, probability)
五:生成器网络
生成器网络接收一些随机数据,并尝试模仿训练数据集以生成假图像。它的目标是通过尝试生成与训练数据集完美复制品的图像来欺骗鉴别器。
随着它的训练,它在每次迭代后都会变得越来越好。另一方面,鉴别器同时被训练,所以生成器必须不断改进,因为鉴别器学会了它的技巧。
生成器模型的架构看起来像是一个倒置的传统ConvNet。生成器接收一个带有随机噪声数据的向量输入,并将其重塑为一个具有宽度、高度和深度的立方体体积。这个体积被视为将被馈送到几个卷积层的特征图,这些卷积层将创建最终的图像。
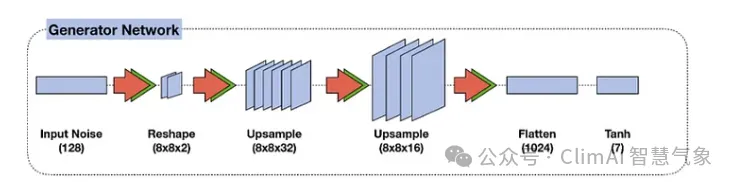
图7 GAN模型的生成器网络。
就像传统的卷积神经网络使用池化层来下采样输入图像一样。为了缩放特征图,我们使用上采样层,通过重复其输入像素的每行和每列来放大图像尺寸。
现在,让我们使用Keras构建生成器网络。在生成器代码中,我们将使用与鉴别器网络中使用的类似组件。唯一的新组件是上采样层,通过重复像素来将其输入尺寸加倍。
与鉴别器类似,我们将堆叠卷积层,并添加其他优化层,如BatchNormalization。生成器模型的关键区别在于它从压平的向量开始,然后图像被上采样,直到它们具有与训练数据集相似的尺寸。
def generator_model():
# 实例化一个顺序模型并将其命名为生成器
generator = Sequential()
# 添加一个Dense层,其神经元数量= 128x7x7
generator.add(Dense(128 * 7 * 7, activation="relu", input_dim=100))
# 将图像尺寸重塑为7 x 7 x 128
generator.add(Reshape((7, 7, 128)))
# 上采样层,将图像尺寸加倍到14 x 14
generator.add(UpSampling2D(size=(2,2)))
# 添加一个卷积层来运行卷积过程+批量归一化
generator.add(Conv2D(128, kernel_size=3, padding="same", activation="relu"))
generator.add(BatchNormalization(momentum=0.8))
# 将图像尺寸上采样到28 x 28
generator.add(UpSampling2D(size=(2,2)))
# 卷积+批量归一化层
# 注意我们这里没有添加上采样,因为我们已经有了28 x 28的图像尺寸
# 这与MNIST数据集中的图像尺寸相等。您可以根据自己的问题进行调整。
generator.add(Conv2D(64, kernel_size=3, padding="same", activation="relu"))
generator.add(BatchNormalization(momentum=0.8))
# 过滤器=1的卷积层
generator.add(Conv2D(1, kernel_size=3, padding="same", activation="relu"))
# 打印模型摘要
generator.summary()
# 生成长度=100的输入噪声向量
# 我们在这里选择100来创建一个简单的网络
noise = Input(shape=(100,))
# 运行生成器模型以创建假图像
fake_image = generator(noise)
# 返回一个模型,它将噪声向量作为输入并输出假图像
return Model(noise, fake_image)