在数据库操作中,并发控制 是确保数据一致性和事务隔离性的关键。然而,多个事务的并发操作可能导致数据不一致,破坏数据库的ACID特性。本文将深入探讨并发操作可能带来的问题,并介绍常见的并发控制技术。
1. 并发操作带来的挑战
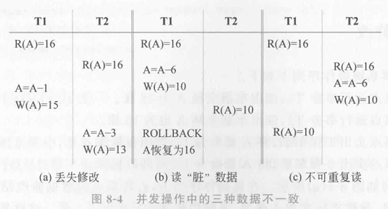
当多个事务同时对同一数据库进行操作时,可能会发生以下三种典型的问题:
- 丢失修改(Lost Update)
- 读“脏”数据(Dirty Read)
- 不可重复读(Non-repeatable Read)
1.1 丢失修改
丢失修改 是指两个事务读取同一数据并分别进行修改,其中一个事务的结果被另一个事务的结果覆盖,导致前者的修改丢失。
示例:火车票售票系统中的丢失修改
假设有两个售票点,甲和乙,它们分别运行事务T1和T2。
- 甲售票点 运行事务T1,读取车票余额A为16张。
- 乙售票点 运行事务T2,读取车票余额A也为16张。
- 甲售票点 卖出1张票,将A修改为15,并写回数据库。
- 乙售票点 卖出3张票,将A修改为13,并写回数据库。
结果: 乙售票点的修改结果覆盖了甲售票点的修改结果,导致系统中显示只卖出了3张票,而实际上卖出了4张。这就是丢失修改问题。
1.2 读“脏”数据
读“脏”数据 是指一个事务读取了另一个事务尚未提交的修改数据,结果该事务因为某种原因被撤销,导致读取的数据与最终数据库中的数据不一致。
示例:火车票售票系统中的读“脏”数据
假设甲售票点运行事务T1,乙售票点运行事务T2。
- 甲售票点 运行事务T1,读取车票余额A为16张。
- 甲售票点 卖出6张票,将A修改为10,并写入数据库。
- 乙售票点 运行事务T2,读取车票余额A为10张。
- 甲售票点 撤销了之前的操作,车票余额A恢复到16张。
结果: 乙售票点读取了一个过渡性的无效数据,即10张票的余额,而实际上数据库中的余额已经恢复到16张。这就是读“脏”数据问题。
1.3 不可重复读
不可重复读 是指一个事务在两次读取同一数据时,结果不同。通常是因为在两次读取期间,另一个事务对数据进行了修改。
示例:火车票售票系统中的不可重复读
甲售票点运行事务T1,乙售票点运行事务T2。
- 甲售票点 运行事务T1,读取车票余额A为16张。
- 乙售票点 运行事务T2,读取车票余额A也为16张。
- 乙售票点 卖出6张票,将A修改为10,并写回数据库。
- 甲售票点 再次运行事务T1,读取车票余额A,此时余额为10张。
提示: 不可重复读可能会导致数据的不一致性,尤其是在需要多次读取同一数据的事务中。
2. 并发控制的必要性
并发控制的主要目标是防止数据不一致性,确保事务之间的隔离性。如果不对并发操作进行控制,数据库系统将无法保证数据的正确性。
2.1 为什么需要并发控制?
- 保证数据一致性: 并发控制确保即使多个事务同时运行,数据的一致性也不会被破坏。
- 提高系统效率: 通过正确的并发控制,系统可以高效地处理多个事务,最大化资源利用率。
3. 常见的并发控制技术
为了处理并发操作带来的问题,数据库管理系统(DBMS)通常采用以下几种并发控制技术:
3.1 封锁(Locking)
封锁 是最常见的并发控制技术。封锁机制通过锁定数据来防止其他事务对其进行修改,从而确保数据的一致性。
- 共享锁(S锁): 允许多个事务同时读取数据,但不允许修改。
- 排他锁(X锁): 允许一个事务独占访问数据,其他事务既不能读也不能改。
示例: 当甲售票点读取车票余额时,系统为该数据加上共享锁,乙售票点不能修改数据,直到甲售票点释放锁。
3.2 时间戳(Timestamp)
时间戳 技术为每个事务分配一个唯一的时间戳,并根据时间戳的顺序来处理事务,确保事务之间的顺序性。
- 时间戳排序: 事务按照时间戳的顺序执行,确保早先的事务不会被后来的事务影响。
示例: 在时间戳控制下,早于乙售票点的甲售票点事务将优先执行,确保数据的一致性。
3.3 乐观控制法(Optimistic Control)
乐观控制法 假设事务的并发冲突很少发生,因此在事务开始时不加锁,在提交时检测是否有冲突,若有冲突则回滚事务。
- 冲突检测: 在事务提交时检查是否有其他事务修改了相同的数据,如果有,则回滚当前事务。
示例: 甲售票点和乙售票点都可以在不加锁的情况下读取和修改数据,只有在提交时才检查是否有冲突。
4. 如何避免并发操作中的数据不一致性?
为了避免并发操作带来的数据不一致性问题,开发者应根据具体应用场景选择适当的并发控制技术。
4.1 使用合适的隔离级别
数据库系统通常提供四种隔离级别:
- 读未提交(Read Uncommitted): 允许读取未提交的数据,但易引发“脏读”问题。
- 读已提交(Read Committed): 仅允许读取已提交的数据,避免脏读,但可能导致不可重复读。
- 可重复读(Repeatable Read): 保证在同一个事务中多次读取结果一致,避免不可重复读。
- 可序列化(Serializable): 提供最高级别的隔离,完全避免并发问题,但影响性能。
建议: 在不影响性能的前提下,尽量选择较高的隔离级别,如可重复读或可序列化,以确保数据一致性。
4.2 避免不必要的并发
在设计数据库操作时,尽量减少不必要的并发操作。例如,尽量减少对同一数据的频繁修改或避免在同一事务中多次读取和修改同一数据。
4.3 充分利用数据库的并发控制机制
现代DBMS提供了丰富的并发控制工具和配置选项,如锁机制、隔离级别设置等。充分利用这些机制,可以有效避免并发操作带来的数据不一致性问题。
总结
通过本文的讲解,你应该对并发控制的重要性和常见问题有了清晰的认识。丢失修改、读“脏”数据 和 不可重复读 是并发操作中常见的三大问题,而封锁、时间戳 和 乐观控制法 是应对这些问题的常见技术。



















