高效的数据处理对于依赖大数据分析做出明智决策的企业和组织至关重要。显著影响数据处理性能的一个关键因素是数据的存储格式。本文探讨了不同存储格式(特别是 Parquet、Avro 和 ORC)对 Google Cloud Platform (GCP) 上大数据环境中查询性能和成本的影响。本文提供了基准测试,讨论了成本影响,并提供了根据特定使用案例选择合适的格式的建议。
大数据中的存储格式简介
数据存储格式是任何大数据处理环境的支柱。它们定义了数据的存储、读取和写入方式,直接影响存储效率、查询性能和数据检索速度。在大数据生态系统中,Parquet 和 ORC 等列式格式以及 Avro 等基于行的格式因其针对特定类型的查询和处理任务的优化性能而被广泛使用。
- 木条镶花之地板: Parquet 是一种列式存储格式,针对读取密集型操作和分析进行了优化。它在压缩和编码方面非常高效,非常适合优先考虑读取性能和存储效率的场景。
- 阿夫罗: Avro 是一种基于行的存储格式,专为数据序列化而设计。它以其架构演化功能而闻名,通常用于需要快速序列化和反序列化数据的写入密集型操作。
- ORC (Optimized Row Columnar): ORC 是一种类似于 Parquet 的列式存储格式,但针对读取和写入操作进行了优化,ORC 在压缩方面非常高效,从而降低了存储成本并加快了数据检索速度。
研究目标
本研究的主要目的是评估不同的存储格式(Parquet、Avro、ORC)如何影响大数据环境中的查询性能和成本。本文旨在提供基于各种查询类型和数据量的基准测试,以帮助数据工程师和架构师为其特定使用案例选择最合适的格式。
实验装置
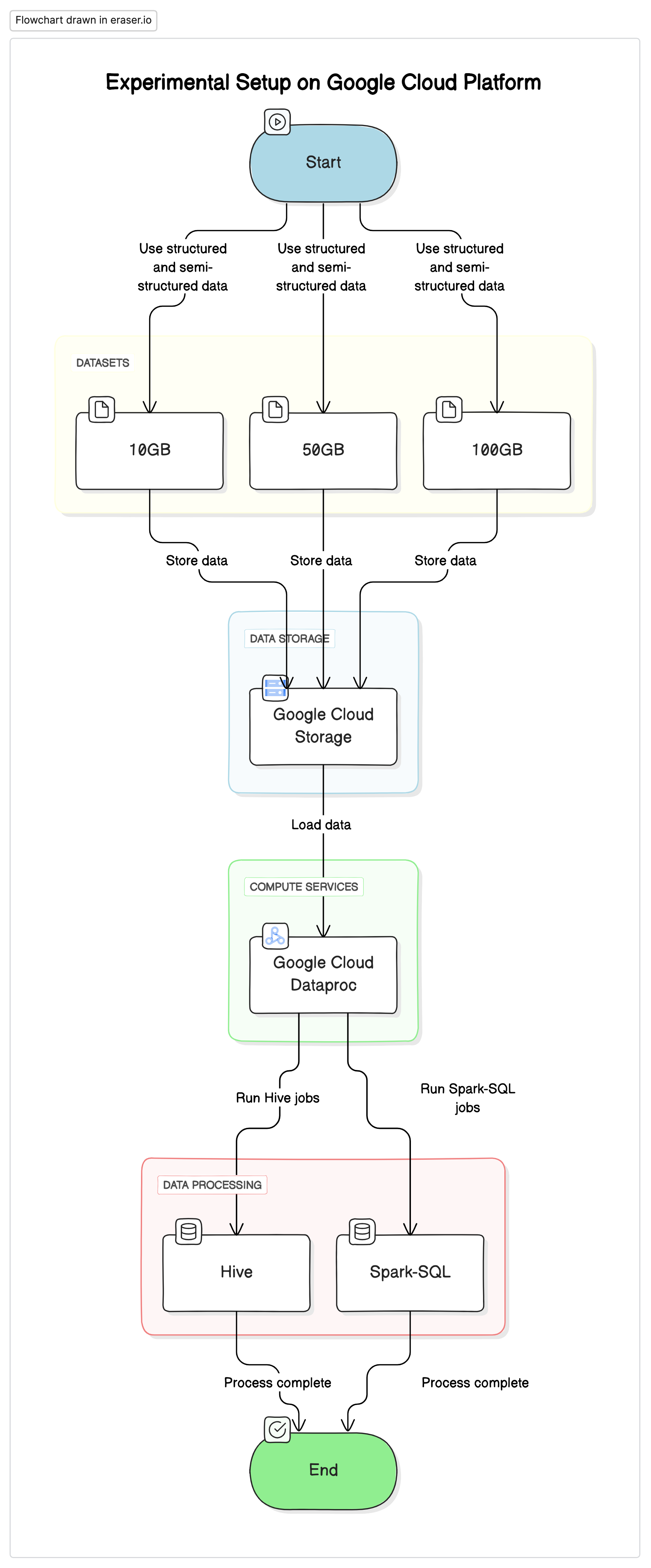
为了进行这项研究,我们在 Google Cloud Platform (GCP) 上使用了标准化设置,将 Google Cloud Storage 作为数据存储库,并使用 Google Cloud Dataproc 来运行 Hive 和 Spark-SQL 作业。实验中使用的数据是结构化和半结构化数据集的混合,用于模拟真实场景。
关键组件
- 谷歌云存储: 用于以不同格式(Parquet、Avro、ORC)存储数据集
- Google Cloud Dataproc: 用于运行 Hive 和 Spark-SQL 作业的托管 Apache Hadoop 和 Apache Spark 服务。
- 数据: 三个大小不同(10GB、50GB、100GB)的混合数据类型数据集。
<span style="color:#aa5500"># Initialize PySpark and set up Google Cloud Storage as file system</span>from pyspark.sql import SparkSession pyspark.sql import SparkSessionspark = SparkSession.builder \ = SparkSession.builder \ .appName("BigDataQueryPerformance") \appName("BigDataQueryPerformance") \ .config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \ .getOrCreate()getOrCreate()<span style="color:#aa5500"># Configure the access to Google Cloud Storage</span>spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem").conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")spark.conf.set("fs.gs.auth.service.account.enable", "true").conf.set("fs.gs.auth.service.account.enable", "true")spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json").conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")测试查询
- 简单的 SELECT 查询: 从表中基本检索所有列
- 筛选查询: 带有 WHERE 子句的 SELECT 查询以筛选特定行
- 聚合查询: 涉及 GROUP BY 和聚合函数(如 SUM、AVG 等)的查询。
- 联接查询: 在公共键上联接两个或多个表的查询
结果和分析
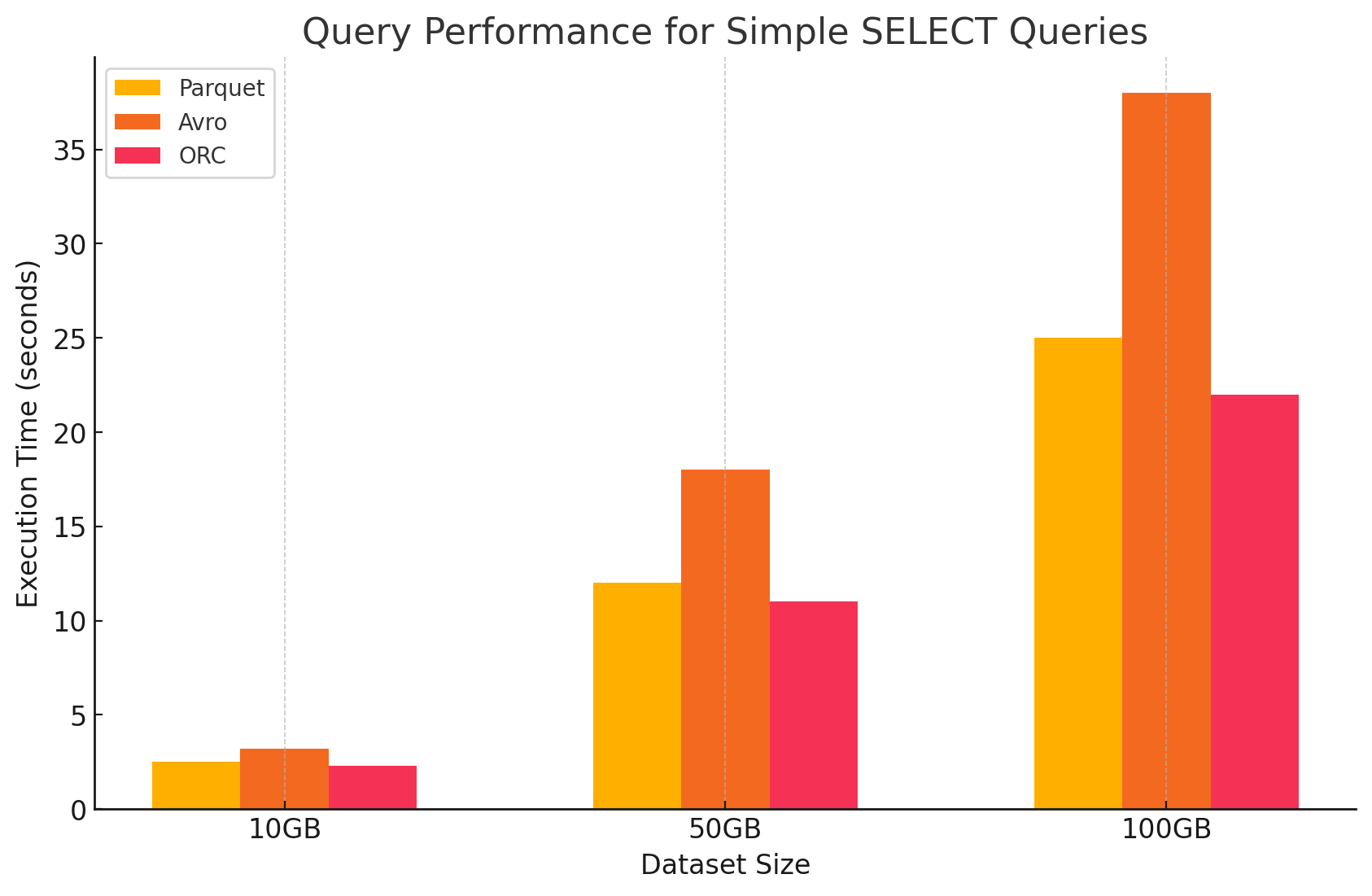
1. 简单的 SELECT 查询
- 木条镶花之地板:由于其柱状存储格式,它的性能非常出色,可以快速扫描特定色谱柱。Parquet 文件经过高度压缩,减少了从磁盘读取的数据量,从而缩短了查询执行时间。
<span style="color:#aa5500"># Simple SELECT query on Parquet file</span>parquet_df.select("column1", "column2").show().select("column1", "column2").show()- 阿夫罗:Avro 表现一般。作为基于行的格式,Avro 需要读取整行,即使只需要特定列也是如此。这会增加 I/O 操作,导致与 Parquet 和 ORC 相比,查询性能较慢。
<span style="color:#aa5500">-- Simple SELECT query on Avro file in Hive</span>CREATE EXTERNAL TABLE avro_table EXTERNAL TABLE avro_tableSTORED AS AVROAS AVROLOCATION 'gs://your-bucket/dataset.avro';'gs://your-bucket/dataset.avro';SELECT column1, column2 FROM avro_table; column1, column2 FROM avro_table;- ORC: ORC 表现出与 Parquet 相似的性能,压缩率略好,并且优化了存储技术,从而提高了读取速度。ORC 文件也是列式的,因此适用于仅检索特定列的 SELECT 查询。
<span style="color:#aa5500"># Simple SELECT query on ORC file</span>orc_df.select("column1", "column2").show().select("column1", "column2").show()
2. 筛选查询
- 木条镶花之地板: Parquet 由于其列式性质和快速跳过不相关列的能力而保持了其性能优势。但是,由于需要扫描更多行以应用筛选条件,性能受到了轻微影响。
<span style="color:#aa5500"># Filter query on Parquet file</span>filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value') = parquet_df.filter(parquet_df.column1 == 'some_value')filtered_parquet_df.show().show()- 阿夫罗: 由于需要读取整行并在所有列中应用筛选器,因此性能进一步下降,从而增加了处理时间。
<span style="color:#aa5500">-- Filter query on Avro file in Hive</span>SELECT * FROM avro_table WHERE column1 = 'some_value'; * FROM avro_table WHERE column1 = 'some_value';- ORC: 这在筛选查询中略优于 Parquet,因为它的谓词下推功能允许在将数据加载到内存之前直接在存储级别进行筛选。
<span style="color:#aa5500"># Filter query on ORC file</span>filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value') = orc_df.filter(orc_df.column1 == 'some_value')filtered_orc_df.show().show()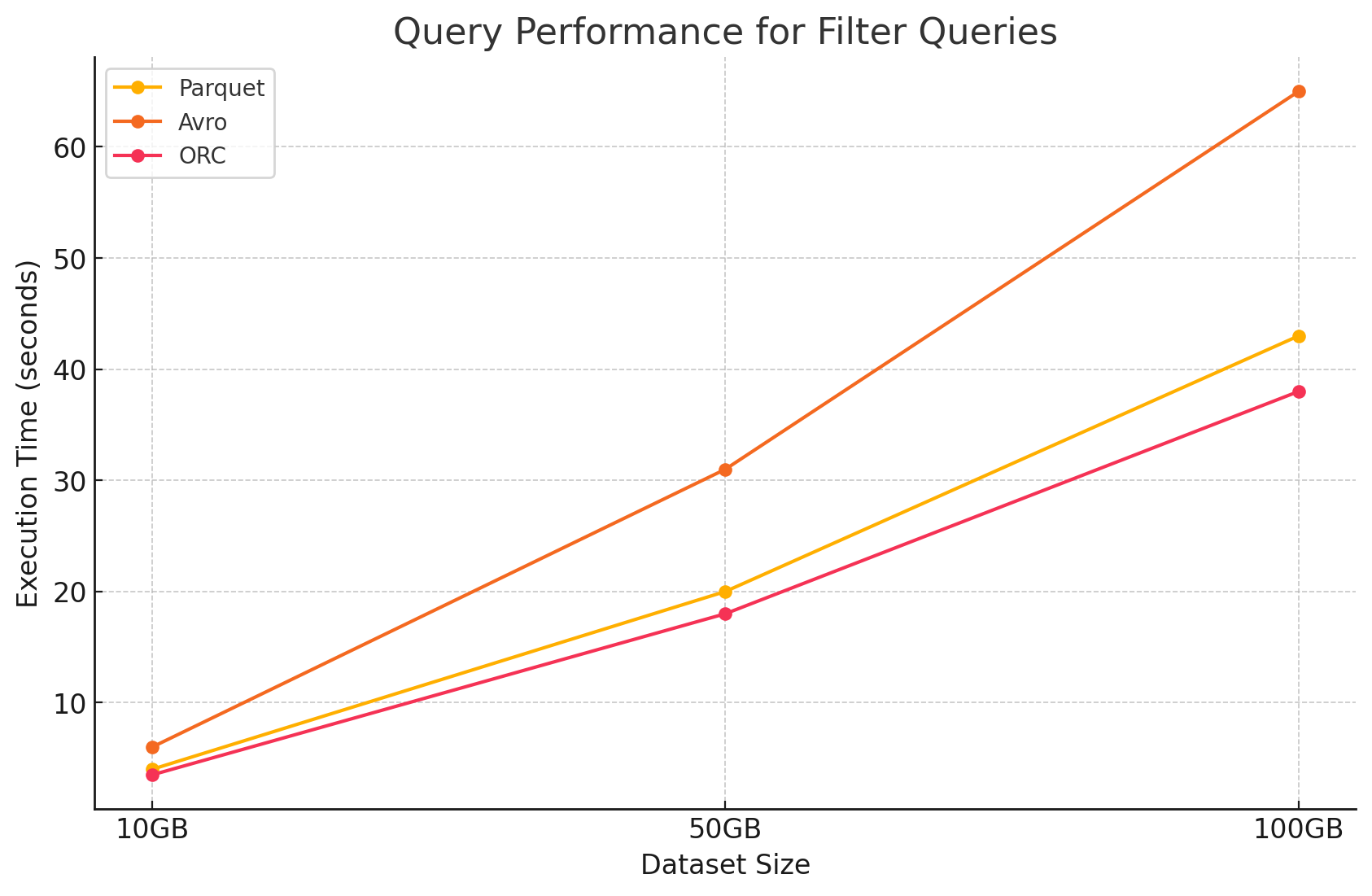
3. 聚合查询
- 木条镶花之地板: Parquet 表现良好,但效率略低于 ORC。列式格式通过快速访问所需的列来有利于聚合操作,但 Parquet 缺少 ORC 提供的一些内置优化。
<span style="color:#aa5500"># Aggregation query on Parquet file</span>agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"}) = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})agg_parquet_df.show().show()- 阿夫罗: Avro 由于其基于行的存储而落后,这需要扫描和处理每行的所有列,从而增加了计算开销。
<span style="color:#aa5500">-- Aggregation query on Avro file in Hive</span>SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1; column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;- ORC: ORC 在聚合查询方面的表现优于 Parquet 和 Avro。ORC 的高级索引和内置压缩算法可实现更快的数据访问并减少 I/O 操作,使其非常适合聚合任务。
<span style="color:#aa5500"># Aggregation query on ORC file</span>agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"}) = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})agg_orc_df.show().show()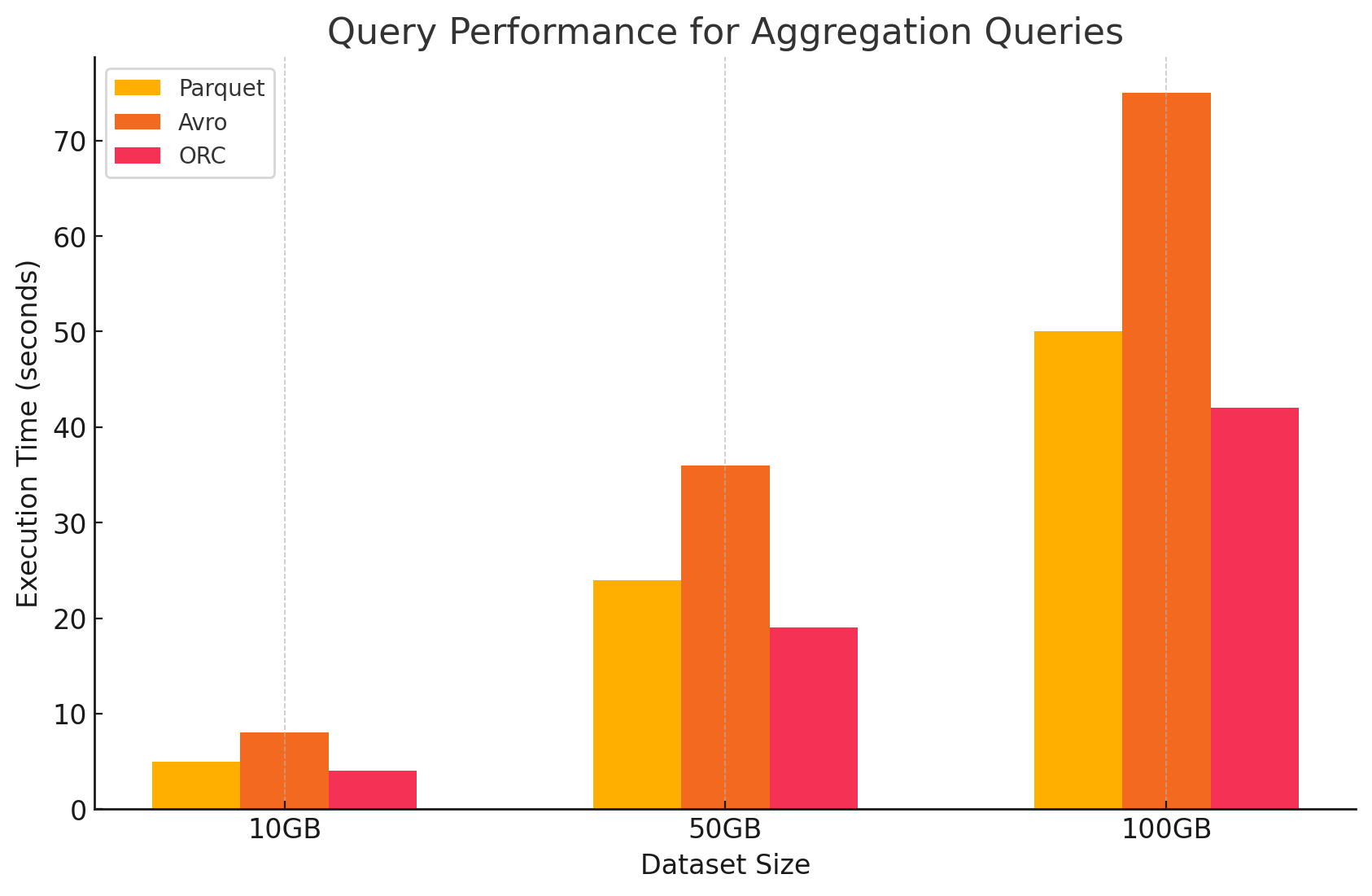
4. 联接查询
- 木条镶花之地板: Parquet 性能良好,但在联接操作中效率不如 ORC,因为它对联接条件的数据读取不太优化。
<span style="color:#aa5500"># Join query between Parquet and ORC files</span>joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key) = parquet_df.join(orc_df, parquet_df.key == orc_df.key)joined_df.show().show()- ORC: ORC 在联接查询方面表现出色,受益于高级索引和谓词下推功能,这些功能最大限度地减少了联接操作期间扫描和处理的数据。
<span style="color:#aa5500"># Join query between two ORC files</span>joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key) = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)joined_orc_df.show().show()- 阿夫罗:Avro 在连接操作方面遇到了很大困难,主要是因为读取整行的开销很高,并且缺乏对连接键的列式优化。
<span style="color:#aa5500">-- Join query between Parquet and Avro files in Hive</span>SELECT a.column1, b.column2 a.column1, b.column2 FROM parquet_table a parquet_table a JOIN avro_table b avro_table b ON a.key = b.key; a.key = b.key;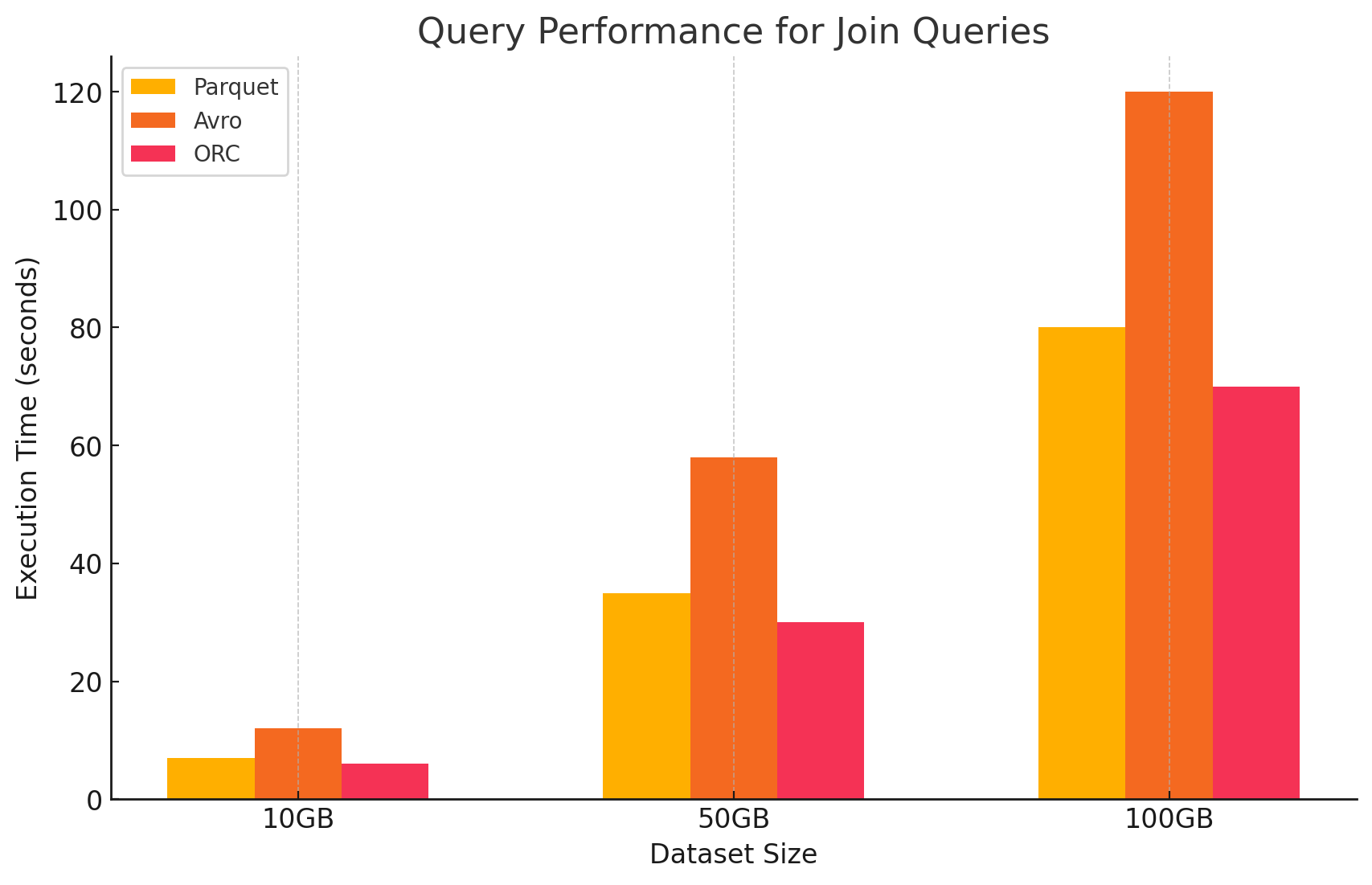
存储格式对成本的影响
1. 存储效率和成本
- Parquet 和 ORC(列式格式)
- 压缩和存储成本: Parquet 和 ORC 都是列式存储格式,可提供高压缩率,尤其是对于列中具有许多重复值或类似值的数据集。这种高压缩率减小了整体数据大小,进而降低了存储成本,尤其是在存储按 GB 计费的云环境中。
- 最适合分析工作负载: 由于其列式性质,这些格式非常适合经常查询特定列的分析工作负载。这意味着从存储中读取的数据更少,从而减少了 I/O 操作和相关成本。
- Avro (基于行的格式)
- 压缩和存储成本: Avro 通常提供比 Parquet 和 ORC 等列式格式更低的压缩率,因为它逐行存储数据。这可能会导致更高的存储成本,尤其是对于具有许多列的大型数据集,因为必须读取一行中的所有数据,即使只需要几列也是如此。
- 更适合写入密集型工作负载: 虽然 Avro 可能会因压缩率较低而导致存储成本较高,但它更适合持续写入或附加数据的写入密集型工作负载。与存储相关的成本可能会被数据序列化和反序列化的效率提高所抵消。
2. 数据处理性能和成本
- Parquet 和 ORC(列式格式)
- 降低加工成本: 这些格式针对读取密集型操作进行了优化,这使得它们在查询大型数据集时非常高效。由于它们仅允许读取查询所需的相关列,因此它们会减少处理的数据量。这样可以降低 CPU 使用率并加快查询执行时间,从而在计算资源根据使用情况计费的云环境中显著降低计算成本。
- 用于成本优化的高级功能: 特别是 ORC,它包括谓词下推和内置统计信息等功能,这些功能使查询引擎能够跳过读取不必要的数据。这进一步减少了 I/O 操作并加快了查询性能,从而优化了成本。
- Avro (基于行的格式)
- 更高的加工成本: 由于 Avro 是一种基于行的格式,因此即使只需要几列,它通常需要更多的 I/O 操作来读取整行。由于 CPU 使用率较高和查询执行时间延长,这可能会导致计算成本增加,尤其是在读取密集型环境中。
- 高效的流式处理和序列化: 尽管查询的处理成本较高,但 Avro 非常适合快速写入速度和架构演变更为关键的流式处理和序列化任务。
3. 成本分析及定价详情
- 为了量化每种存储格式的成本影响,我们使用 GCP 进行了一项实验。我们根据 GCP 的定价模型计算了每种格式的存储和数据处理相关成本。
- Google Cloud 存储费用
- 存储成本: 这是根据以每种格式存储的数据量计算的。GCP 对存储在 Google Cloud Storage 中的数据每月每 GB 收费。每种格式实现的压缩率直接影响这些成本。Parquet 和 ORC 等列式格式通常比 Avro 等基于行的格式具有更好的压缩率,从而降低存储成本。
- 以下是仓储成本的计算方法示例:
- 木条镶花之地板: 高压缩率可减小数据大小,从而降低存储成本
- ORC: 与 Parquet 类似,ORC 的高级压缩也有效地降低了存储成本
- 阿夫罗: 与 Parquet 和 ORC 相比,较低的压缩效率导致更高的存储成本
<span style="color:#aa5500"># Example of how to save data back to Google Cloud Storage in different formats</span><span style="color:#aa5500"># Save DataFrame as Parque</span>parquet_df.write.parquet("gs://your-bucket/output_parquet").write.parquet("gs://your-bucket/output_parquet")<span style="color:#aa5500"># Save DataFrame as Avro</span>avro_df.write.format("avro").save("gs://your-bucket/output_avro").write.format("avro").save("gs://your-bucket/output_avro")<span style="color:#aa5500"># Save DataFrame as ORC</span>orc_df.write.orc("gs://your-bucket/output_orc").write.orc("gs://your-bucket/output_orc")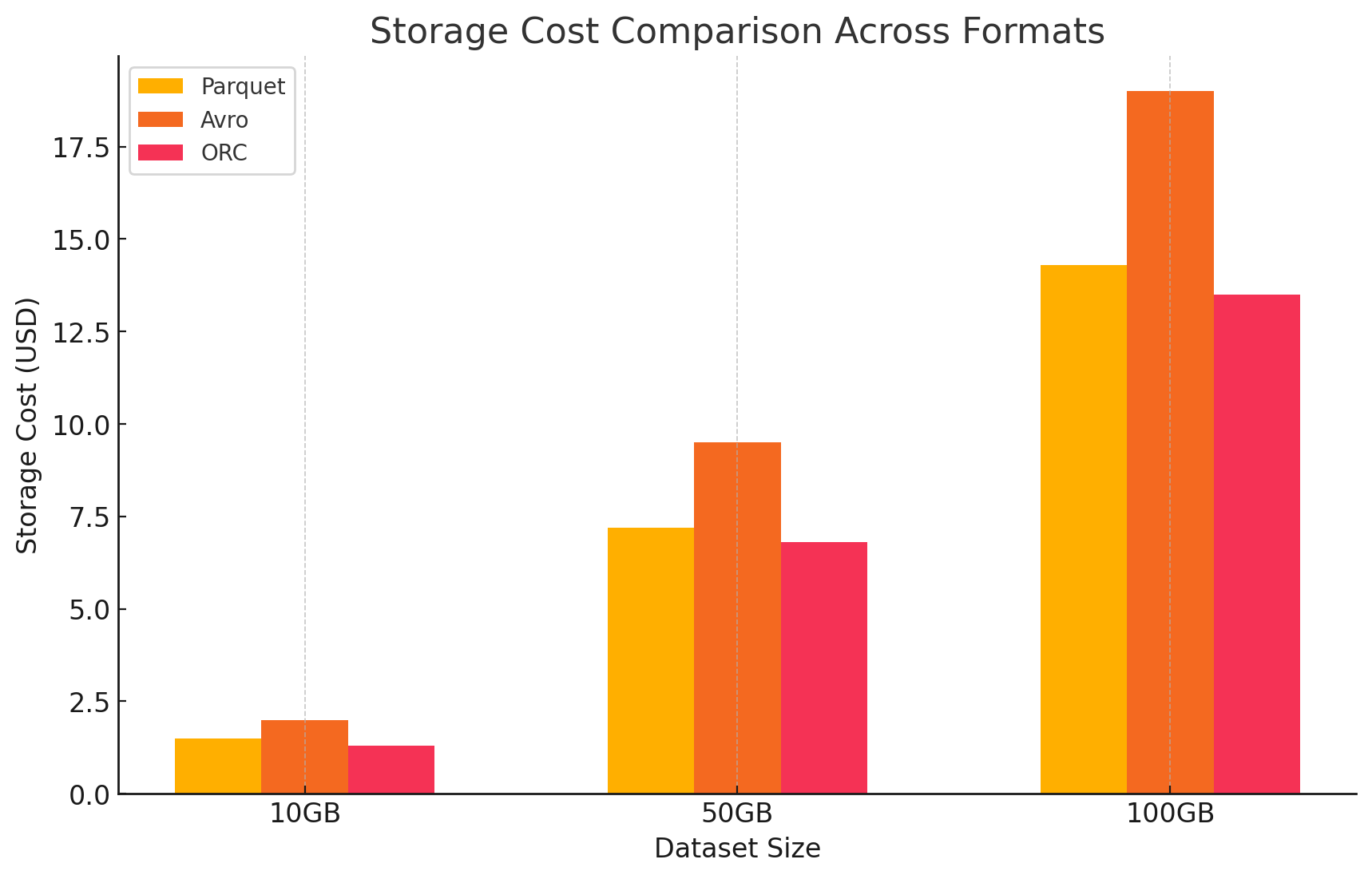
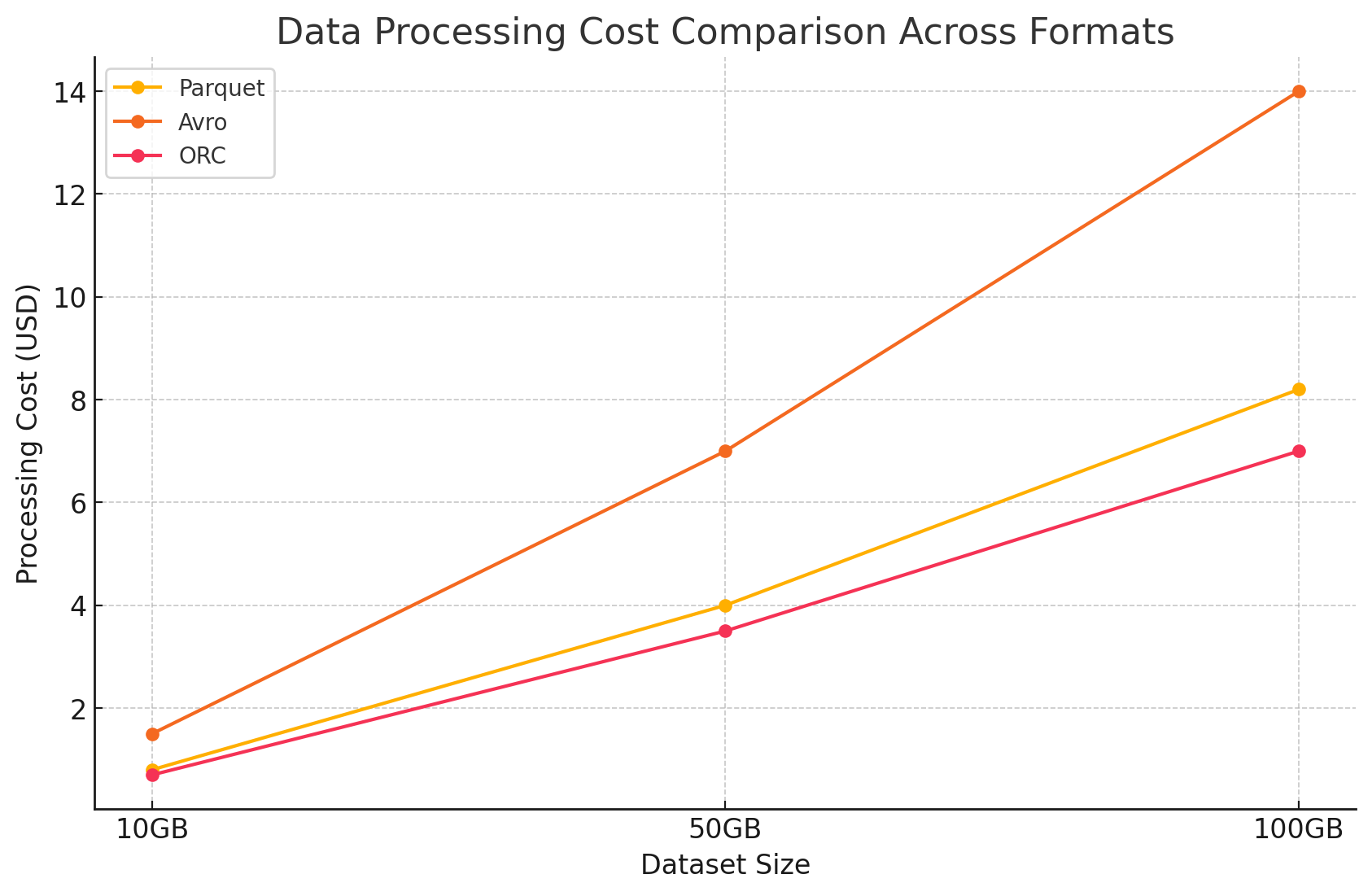
- 数据处理成本
- 数据处理费用是根据在 GCP 上使用 Dataproc 执行各种查询所需的计算资源计算得出的。GCP 根据集群的大小和资源的使用时长收取 Dataproc 使用费。
- 计算成本:
- 镶木地板和 ORC: 由于它们高效的列式存储,这些格式减少了读取和处理的数据量,从而降低了计算成本。更快的查询执行时间也有助于节省成本,尤其是对于涉及大型数据集的复杂查询。
- 阿夫罗: 由于 Avro 采用基于行的格式,因此需要更多的计算资源,这增加了读取和处理的数据量。这导致了更高的成本,尤其是对于读取密集型操作。
结论
在大数据环境中选择存储格式会显著影响查询性能和成本。以上研究和实验证明了以下关键点:
- 镶木地板和 ORC:这些列式格式可提供出色的压缩效果,从而降低存储成本。它们能够有效地仅读取必要的列,从而大大提高了查询性能并降低了数据处理成本。由于 ORC 具有高级索引和优化功能,因此在某些查询类型中略优于 Parquet,使其成为需要高读取和写入性能的混合工作负载的绝佳选择。
- 阿夫罗: 虽然 Avro 在压缩和查询性能方面的效率不如 Parquet 和 ORC,但它在需要快速写入操作和架构演变的使用案例中表现出色。这种格式非常适合涉及数据序列化和流式处理的场景,在这些场景中,写入性能和灵活性优先于读取效率。
- 成本效益: 在像 GCP 这样的云环境中,成本与存储和计算使用密切相关,选择正确的格式可以节省大量成本。对于主要读取密集型的分析工作负载,Parquet 和 ORC 是最具成本效益的选项。对于需要快速数据摄取和灵活 Schema 管理的应用程序,尽管 Avro 的存储和计算成本较高,但它是一个合适的选择。
建议
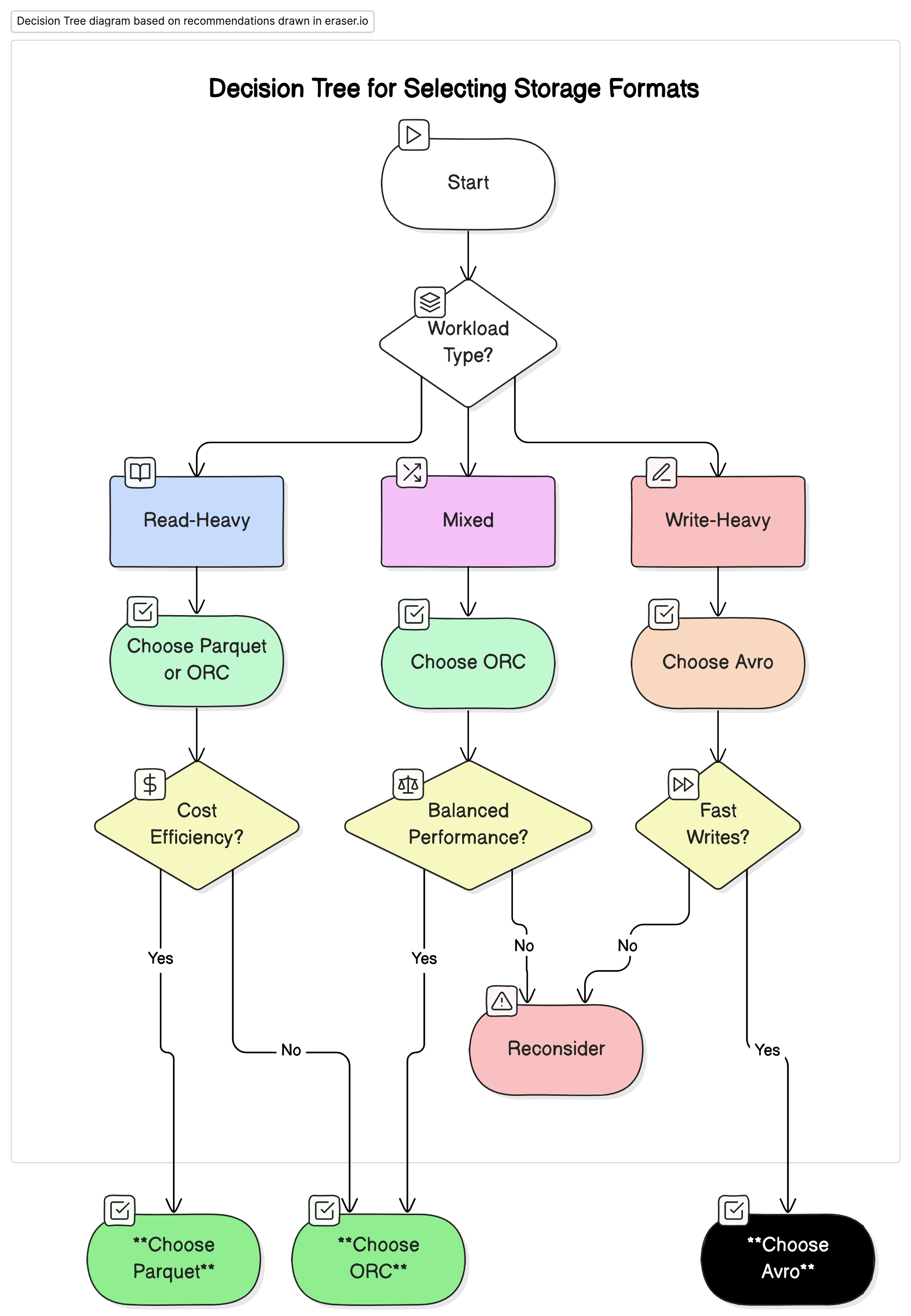
根据我们的分析,我们建议如下:
- 对于读取密集型分析工作负载: 使用 Parquet 或 ORC。这些格式由于其高压缩率和优化的查询性能而提供卓越的性能和成本效益。
- 对于写入密集型工作负载和序列化: 使用 Avro。 它更适合于快速写入和架构演变至关重要的场景,例如数据流和消息传递系统。
- 对于混合工作负载:ORC 为读取和写入操作提供平衡的性能,使其成为数据工作负载变化的环境的理想选择。
为大数据环境选择正确的存储格式对于优化性能和成本至关重要。了解每种格式的优缺点使数据工程师能够根据特定用例定制其数据架构,从而最大限度地提高效率并最大限度地降低费用。随着数据量的持续增长,对于维护可扩展且经济高效的数据解决方案,就存储格式做出明智的决策将变得越来越重要。
通过仔细评估本文中介绍的性能基准和成本影响,组织可以选择最符合其运营需求和财务目标的存储格式。