全文链接:https://tecdat.cn/?p=37652
分析师:Chen Zhang
在教育政策研究领域,准确评估政策对不同区域和学生群体的影响至关重要。2021 年上海市出台的《上海市初中学业水平考试实施办法》对招生政策进行了调整,其中名额分配综合评价模块的变化尤为关键(点击文末“阅读原文”获取完整代码数据)。
相关视频
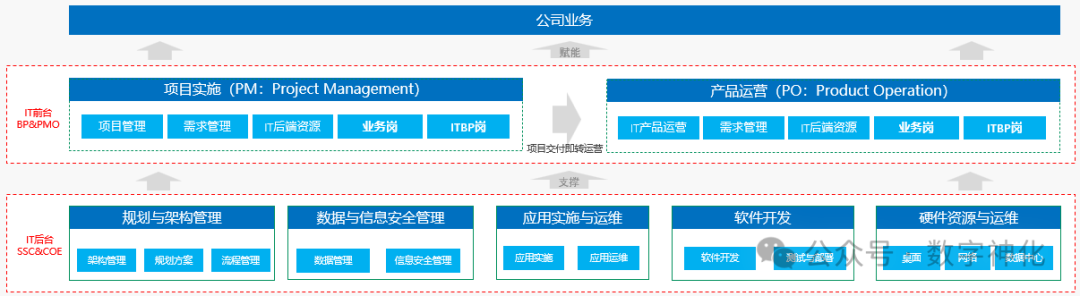
从机器学习和数据分析的角度来看,这为我们提供了一个极具价值的研究场景。在研究过程中,我们需要运用多种科学的分析方法来深入挖掘政策影响背后的规律。我们采用了分类与聚类方法,对上海市十六区和中考考生进行分类,例如在区域分类中,先引入席位问题中的不公平指标,再进行标准化处理和分层聚类操作;对学生分类则依据学业水平进行,通过数学运算得出不同类别学生占比。
另一方面,在数据科学领域中,聚类算法的高效实现一直是研究重点。K - means 算法作为经典的聚类算法,以及自组织映射(SOM)算法在数据可视化与聚类方面有着独特优势。然而,传统的算法实现方式在处理大规模数据和复杂计算场景时面临效率和可扩展性的挑战。
本文中我们基于 TensorFlow 这一深度学习框架对这些算法进行了创新性的改进。对于 K - means 算法,TensorFlow 实现了高效的距离计算、聚类中心更新以及迭代过程的优化;在自组织映射(SOM)算法中,对权重初始化、邻域函数定义、权重更新等关键环节进行了优化设计。这种基于 TensorFlow 的算法改进不仅提高了算法执行效率,还为复杂数据环境下的分析提供了新的思路。
分类、聚类、相关、归类与结构模型分析上海新招生名额分配评价办法对地区的影响研究
2021年上海市印发《上海市初中学业水平考试实施办法》(以下简称《实施办法》)通过研读《实施办法》,我们发现,自主招生录取所占比例较以往有所减少,而名额分配综合评价这一模块所占的比例有所增加。细读“名额分配综合评价录取”这一板块的政策调整后,我们认为该板块中综合素质评价加入和跨区择校比例的提高这两点对学生的升学起到了较大的影响。其中,综合素质评价将学生的学业成绩(总分750分)和对社会考察、探究学习、职业体验等方面能力(共占50分)的考察进行了结合;跨区择校比例提高将对不同地区不同层次的学生产生不同的影响。《实施办法》的出台旨在去重点化与破除“唯分数论”。因此,结合对《实施办法》的分析与对当代教育发展趋势的观察,我们期望通过数学分析与建模研究以下问题:名额分配综合评价对不同地区不同层次学生的影响。
模型假设
1、《实施办法》的出台将不会对各区的教育水平造成影响;
2、在改革前各区名额分配标准为平均分配;
前期准备
(一)、对上海市十六区进行分类
(二)、对不同层次学生进行分类
(三)、假设在综合素质评价中学业评价与德育占比相同
1、分区背景
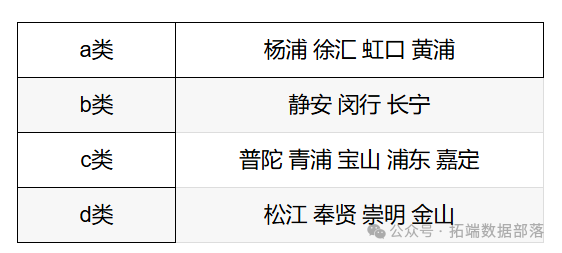
根据对社会现实的观察不难得出,上海的十六个区,其教育水平是有所差异的,为了使我们的研究更符合现实、更具有现实意义的同时简化我们的分析过程,我们根据各区教育水平将十六个区分为了四类。
分区依据
各区考入上海四校及其分校的学生数与考入八大的学生数.[1]。
分区方法
a.不公平指标[2]
在进行分区之前,我们引入了席位问题中常用的不公平指标,并借助程序进行运算,以此来描述名额分配的合理性,若数值越大,证明该区名额分配越不合理,为此我们认为该区教育水平落后;相反,我们也可以得出教育水平先进的区。具体运算结果如下:
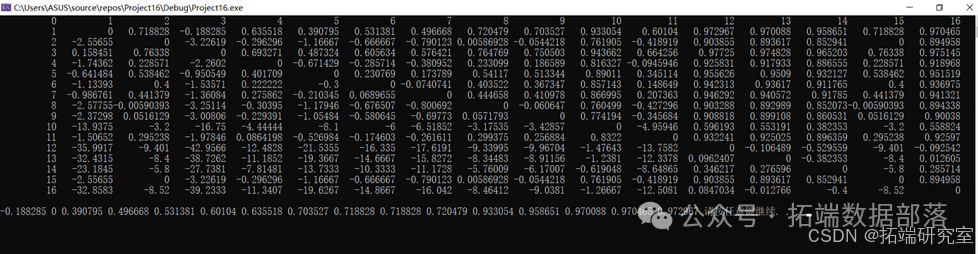
b.标准化处理
在我们的分区方法通过标准检验后,我们将数据进行标准化处理。首先构建原射矩阵,为便于计算、简化模型,我们将各区的数据映射到0-100的区间内,得到各区的教育水平指标。
c.加权平均[1]
将数据标准化后,我们进行分层聚类操作,由于数量较少,因此我们运用Excel进行计算,以平均数为聚类中心,大于和小于平均数的欧氏距离为界,将上海市十六区分为四个集群a、b、c、d。
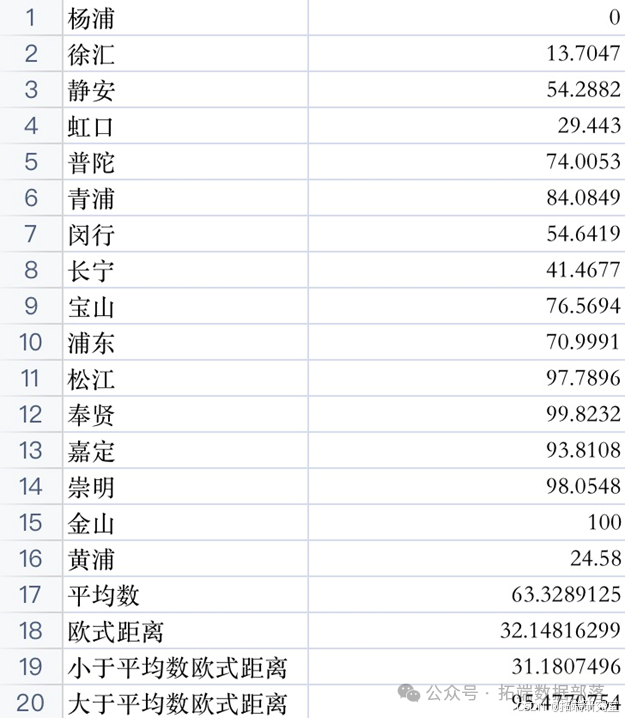
4、分区结果
、对上海市中考考生进行分类
分类背景
我们发现,《实施方法》对不同类型的学生的影响是不同的。为了使我们的研究更符合现实且能够将《实施方法》的影响具体到各类学生身上,我们根据学生的学业水平将学生分为了A、B、C、D、E五类。
分类依据
具体如下:
A类:通过获取推荐生的名额升学的考生;
B类:通过参与名额分配升学的考生;
C类:可争取通过名额分配升学,但大部分通过中考统一招生录取升学且成功升入普通高中的考生;
D类:无法通过名额分配进行升学,只能通过中考统一招生录取进行升学 ,并有可能无法升入普通高中;
E类:通过中考统一招生录取升学且进入中职的考生。[1]
分类方法
通过数学运算,将各级比例相乘,最后得出五类学生占总考生人数比。
4、分类结果

注:该结果来源于对网络数据的处理。
至此,所需要的各大区域和学生分类已经全部完成,下一步将以此数据作为依据,进行更深一步的探究。
综合素质名额分配录取对不同类型学生的影响
前期分析
通过分析,我们可以看出在改革前的中考招生政策中,无论是零志愿、名额分配还是平行志愿,都只是单一考察了考生们的学业水平。而在新的政策下,综合素质名额分配这一录取方法将考生的综合素质量化,并结合其学业水平对其进行排序,必然会与单纯考察其学业水平的排序有所不同。且在前期准备对学生的分类依据下得到的各类学生中,各个学生在综合素质方面的水平必然有所差异。下面,我们将运用数学模型模拟计算新政策中的综合素质名额分配录取将对各类学生产生怎样的影响。
具体方法

首先本次改革的亮点在于综合评价,因此我们需要得到对学生综合素质的描述性指标,但由于该项指标并不能直接得到,我们引入工具变量来替代相关指标。
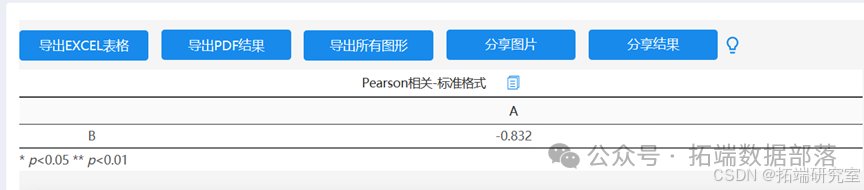
我们以上海市学生学习习惯调查作为依据进行相关性拟合,将会主动为自己留作业的学生归为尖子生,喜欢主动学习归为优秀生,有自主学习习惯归为优良生,知道需要学习归为中等生,其余归为差生,其相关系数接近于1,可以认为呈正相关,并符合工具变量定义,因此可以作为工具变量。
由此,我们认为学生学业水平与学生本身素质互为高度相关量,所以我们选用学生本身素质作为中间变量,以学生学习习惯为工具变量,由此预估学生在综合素质评价中学生大致得分。
以下为我们的对数据的操作处理。
我们理想化假设以学业为主(以道德为主类似),将不同学生的学业情况分为五类,得分分别为:学术22.95以上为A;学术20.95以上为B;学术16.9分之上为C;学术8分以上为D;8分以下E;分别占比8.2%;8%;16.2%;35.6%;32%(大致数据,以模型为主)
以学生道德层面认知调查对学生进行分类,与上述内容相似,相关系数绝对值大于0.8,呈较强的负相关性,因此可以用作工具变量;
同理将道德素质分为五类:道德23.625分以上为A;道德20.55分以上为B;道德14.025以上为C;道德9.35分以上为D;其余为E,分别占比5.5%;12.3%;26.1%;18.7%;37.4%。
结合上方数据,我们将学业得分和道德得分进行加和,将综合素质评价分数划分为五类A(最低分为49.2702分)B(最低分为45.208分)C(最低分为40.6081分)D(最低分为32.7939分)E(低于D档最低分)。
依据2020年各类招生分数线,将原总分(630分)换算成新制度下的总分(750分),得到假设中各层次学生的最低分数线。我们将学生的成绩按照学业成绩(总分750分)和综合素质评价(总分50分)进行加权求和,通过对加和后的成绩进行比较排序,得到新的学生层次划分情况,可以看到,在旧的评价体系下属于B层次的学生有机会通过综合素质评价上升到A层次,同样A层次学生也可能由于综合素质评价成绩不理想降至B等级,其他等级变化情况同理。
随后我们引入归类模型,我们希望将学生分为两类,分别为“在政策出台后可以实现自身等级变更”和“在政策出台后仍不能实现自身等级变更”两类并进行归类;对每个学生而言,我们设置x为学生的学业成绩,y为学生的综合评价成绩,并根据下表得出随机样本,计算相应协方差和马氏距离(我们引入统计学中的马氏距离来代替数学中常用的欧氏距离,原因在于马氏距离可以更好的体现两个因素对学生的影响的相关性,而欧氏距离仅能表示单一距离)。
计算结果
前一个字母表示750分的总分体系下学生的成绩层次,后一个字母表示综合素质评价体系下学生的成绩层次(如AB则表示学生学业成绩等第为A,综合素质评价等地为B)。
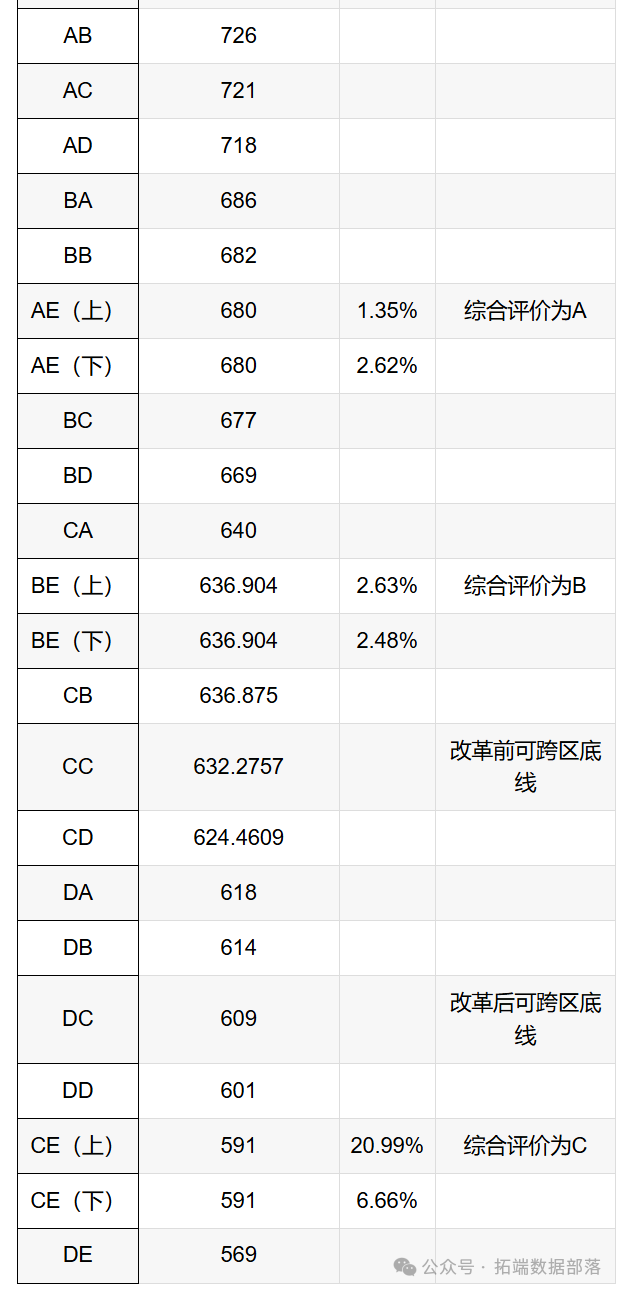
为此,我们得到在新政策出台后,可能实现学生类别跨越的学生原类别分别是:BA,BB,CA,DA,DB,DC六个类别,而其余类别一定不可能实现类别的跨越。
下图为随机选取的样本
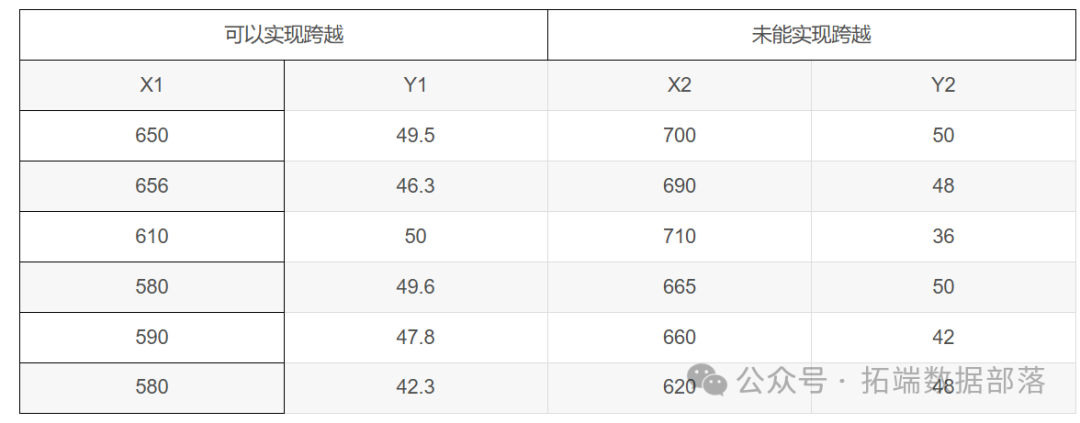
根据此样本,利用matlab软件计算协方差和样本到总体的马氏距离得到下图矩阵:
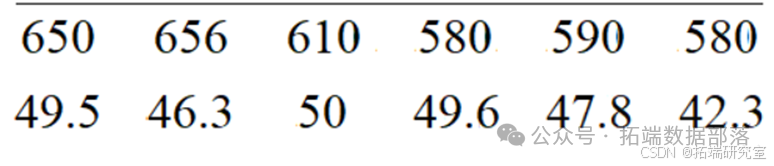
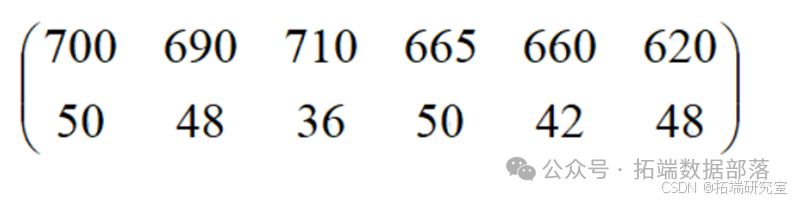
下图分别为两种样本的矩阵。
Cov1=
Cov2=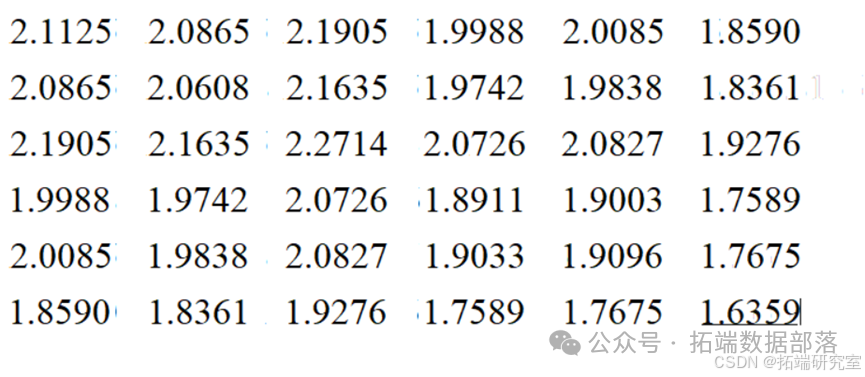
至此我们得到了两个类别每个对应元素的马氏距离矩阵。
再建立结构模型如下:
W(x)=1/2*((d^2(x,G1))-d^2(x,G2))
当x属于G1时,W>=0;当x属于G2时,W<0
由此可以判断任意指标属于哪一个类别。
结果分析
、通过增添综合素质评价这一评价指标,学生的排名得到更新,发展更为全面的学生将为自己赢取更多的机会;
、一定程度上破除“唯分数论”。
(二)、综合素质名额分配录取中跨区比例的调整对各区考生的影响
1、前期分析
通过研读《实施方法》,我们发现,委属市实验性示范性高中与区属实验性示范性高中是根据各区考生人数比来对各区进行名额分配的。故对不同区产生的影响有所不同。在以往的招生章程下,考生跨区择校的比例大约为15.8617442%;而在新的招生改革方案下,考生跨区择校比例则达到19.5%-23.525%,这势必将对各层次区的生源造成不同的影响。
具体方法
通过查找数据获取往年各区考生跨区升学比例,再通过对今年的政策分析与计算,得到今年的各区考生跨区升学比例。对得到的数据进行研究,比较分析不同层次的地区受到的影响有何不同。
对此我们建立了一个分级模型。假设对每个等级的学生来说都存在着退出和调入的情况(事实如此)。我们假设推出为W,调入为R,那么每个等级在变换后的人数为:原人数+R-W。当推出人数与调入人数近似相等时,若存在a=a*p(a为人数,p调动比例)成立,则称该模型存在稳定域,即假设模型成立。经过变换,R=(a-aq)/aW,此时要求Ri>=0,并且对Ri求和等于1,则必满足a>=aq。
根据矩阵运算,得到下列不等式:
a1>=0.0373 · a2+0.1719 · a3+0.0403 · a4
a2>=0.0376 · a1+0.1655 · a3+0.0392 · a4
a3>=0.0947 · a1+0.0915 · a2+0.0987 · a4
a4>=0.0343 · a1+0.0313 · a2+0.1511 · a3
以此利用线性规划作出四维可行域,经计算,可行域存在,即存在相应的R和q使得模型成立,即存在稳定域,以此证明假设模型成立。
3、计算结果
结合我们前期准备得到的数据结果,我们得到不同层次的区参加中考的大致人数6:A层次:16000人;B层次:15550人;C层次:39200人;D层次:14200人。
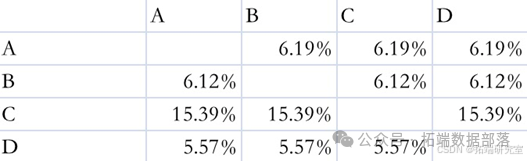
经过计算,我们以转移人数及比例为参考建立了转移矩阵,以下图表格形式体现。
其中表格的第一列为学生原所属地区,第一行为跨区择校之后学生去往就读的地区。(如:A行B列则为A地区学生跨区前往B地区就读的比例)
在进行高中招生改革前,各地区跨区择校比例大致如下图7所示:
进行改革以后,各地区给予外区的名额将按各地区中招人数比例进行分配,经过分析,我们不妨假设地区层次等级越高,教育资源和本区生源越好。显然,层次最高的A地区和较高的B地区将更大程度的保留本地优势,而教育资源和本地生源相对薄弱的C地区和D地区将尽可能的多地分配名额给外区以达到提升本地教育水平的目的,因此改革之后的考生跨区择校比例将如下图所示: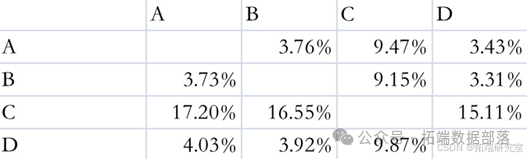
结果分析
、《实施办法》的出台,为各地区学生的择校提供了更多选择,其影响突出体现在跨区择校比例的提高。其具体表现在教育水平相对落后的学生拥有了更多去往教育水平更高地区就读的机会;
、跨区择校比例的提高有利于避免各地区教育水平走向两极化,一定程度上促进了社会的和谐公平。
深度学习框架改进K - means和自组织映射(SOM)算法|附代码数据
在当今的数据科学领域,聚类分析和数据可视化是至关重要的研究方向。K - means 算法作为一种经典的数据聚类算法,以及自组织映射(SOM)算法在数据可视化与聚类方面的独特优势,已被广泛应用于各个领域。然而,传统的算法实现方式在处理大规模数据和复杂计算场景时可能面临效率和可扩展性的挑战。
本研究聚焦于利用 TensorFlow 这一强大的深度学习框架来创新性地实现 K - means 算法和自组织映射(SOM)算法。与传统方法不同,我们将深度学习框架的高效计算能力和灵活的编程模型引入到这两个算法中。对于 K - means 算法,通过 TensorFlow 实现了高效的距离计算、聚类中心更新以及迭代过程的优化,能够快速处理鸢尾花数据集等复杂数据。在自组织映射(SOM)算法中,利用 TensorFlow 对权重初始化、邻域函数定义、权重更新等关键环节进行了优化设计,使得算法在数据可视化和聚类分析方面具有更高的精度和效率。这种基于 TensorFlow 的实现方式不仅提高了算法的执行效率,还为算法在更复杂的数据环境和大规模数据集中的应用提供了新的可能性,是对传统算法实现方式的一种创新性突破。我们将通过对鸢尾花数据集的详细处理与分析,展示这些创新实现方式的具体操作步骤、代码实现以及结果输出。
K - means 算法创新点:
计算框架层面:
借助 TensorFlow 构建 K - means 算法的整体计算流程。TensorFlow 强大的计算能力可以更好地处理数据,尤其是在处理大规模数据集时,能够充分利用硬件资源,实现高效的并行计算。这种基于深度学习框架的实现方式打破了传统计算方式在效率和可扩展性方面的限制,使算法在复杂数据环境下的运行效率得到显著提升。
迭代机制方面:
设计了高效的迭代更新机制。在每次迭代过程中,能够精确地判断当前训练与上一次迭代相比是否有实质性的进展。这种机制避免了在算法已经收敛或者接近最优解时的不必要计算,大大节省了计算资源。同时,在聚类中心的更新方面,采用了更加灵活和高效的策略,使聚类中心能够根据数据点的分布特征快速调整,从而提高了聚类的准确性与稳定性。
SOM 算法创新点:
权重管理方面:
在自组织映射(SOM)算法中,利用 TensorFlow 对权重进行管理。在权重初始化阶段,通过 TensorFlow 的特定机制,可以在合理的范围内进行随机初始化,确保权重的初始值具有一定的多样性和合理性。在权重调整过程中,结合 TensorFlow 的计算图,根据多种因素动态调整权重,使权重的调整更加灵活。而且,通过利用 TensorFlow 的自动求导和优化功能,可以更高效地进行权重的训练,提高算法的训练效率和精度。
节点处理方面:
在距离计算和节点处理上构建了高效的计算逻辑。在计算映射节点到输入向量的距离时,采用了高效的计算方式,能够快速准确地衡量节点与输入向量之间的相似性。在处理最佳匹配单元(BMU)时,通过高效的算法流程,可以快速准确地找到与输入向量最匹配的节点,从而提高了整个算法在数据处理和映射方面的效率。
TensorFlow 实现 K - means 算法
本文主要介绍了基于 TensorFlow 框架实现 K - means 聚类算法的过程。通过对鸢尾花数据集进行处理与分析,展示了算法的具体操作步骤、代码实现以及结果输出。
K - means 算法是一种广泛应用于数据聚类的算法。在本文中,我们利用 TensorFlow 库来实现该算法,并对鸢尾花数据集进行聚类分析。
算法实现过程
以下是基于 TensorFlow 实现 K - means 算法的代码:
# 计算数据在每个维度上的最大值和最小值,用于初始化聚类中心bounds = np.vstack((np.max(iris\_input, axis=0),np.min(iris\_input, axis=0))).T# 随机初始化聚类中心centers = tf.Variable(np.array(\[np.array(\[np.random.uniform(b\[1\], b\[0\]) for b in bounds\]) for i in range(NUM\_CLUSTERS)\]), name='centers')prev = tf.Variable(tf.zeros(centers.get\_shape(), dtype=tf.float64), name='prev')# 判断训练过程与上一次迭代相比是否有进展cont = tf.reduce\_any(tf.not\_equal(tf.constant(0, dtype=tf.float64), tf.squared\_difference(centers, prev)), name='continue')# 保存当前的聚类中心作为上一次的聚类中心store = tf.assign(prev, centers, name='store')# 根据数据点所属的聚类更新聚类中心update = tf.assign(centers, tf.concat(0, \[tf.reduce\_mean(tf.gather(iris_input,在上述代码中,首先读取鸢尾花数据集。然后,随机初始化聚类中心,并通过计算数据点与聚类中心的距离来分配数据点到不同的聚类。在每次迭代中,更新聚类中心,直到满足最大迭代次数或者聚类中心不再变化的条件。
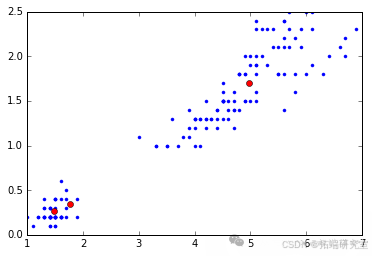
结果
代码运行后,输出了聚类中心、数据点所属的聚类以及原始数据集的类别信息。同时,通过绘制散点图(![image 开头的图片原始链接未给出,无法准确说明图片情况,可补充说明后再完善此部分])展示了数据点和聚类中心的分布情况,其中数据点用点表示,聚类中心用红色的圆圈表示。这有助于直观地观察聚类效果。
plt.plot(iris\_input\[:,2\], iris\_input\[:,3\], ".")plt.plot(c\[:,2\], c\[:,3\], "o", color='red')
``````
结论
本文通过 TensorFlow 实现的 K - means 算法对鸢尾花数据集进行了聚类分析,展示了算法的有效性和代码实现的可行性。该方法可以为进一步的数据挖掘和分析提供基础。
点击标题查阅往期内容

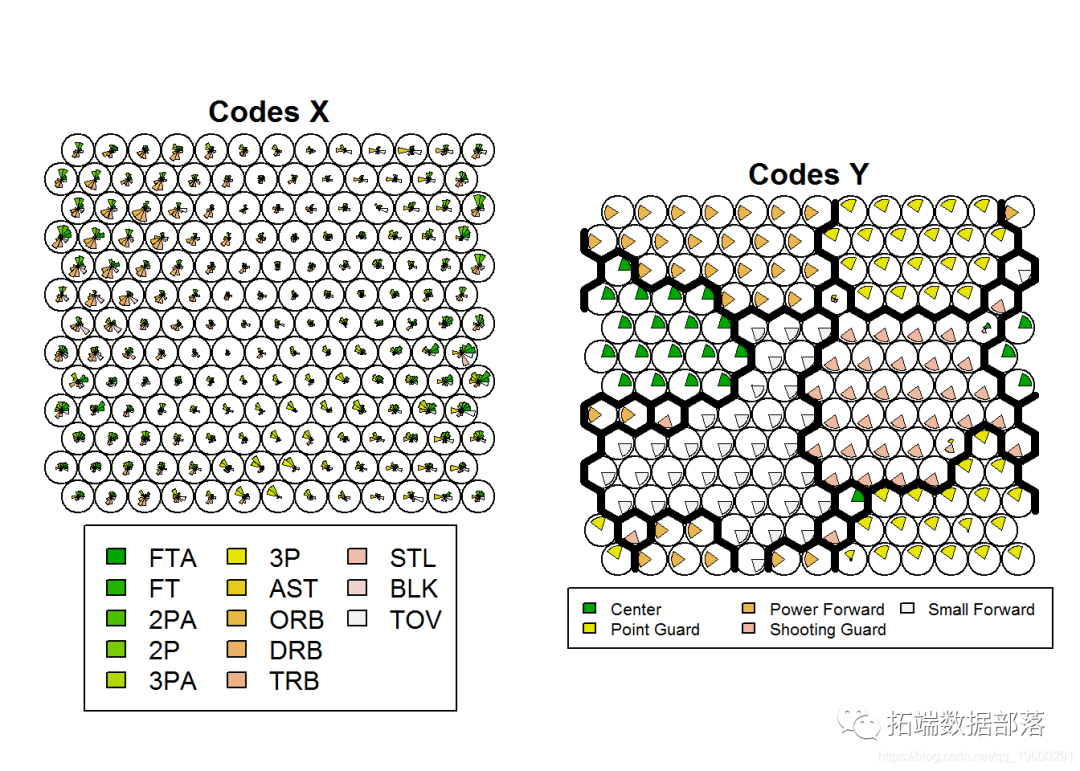
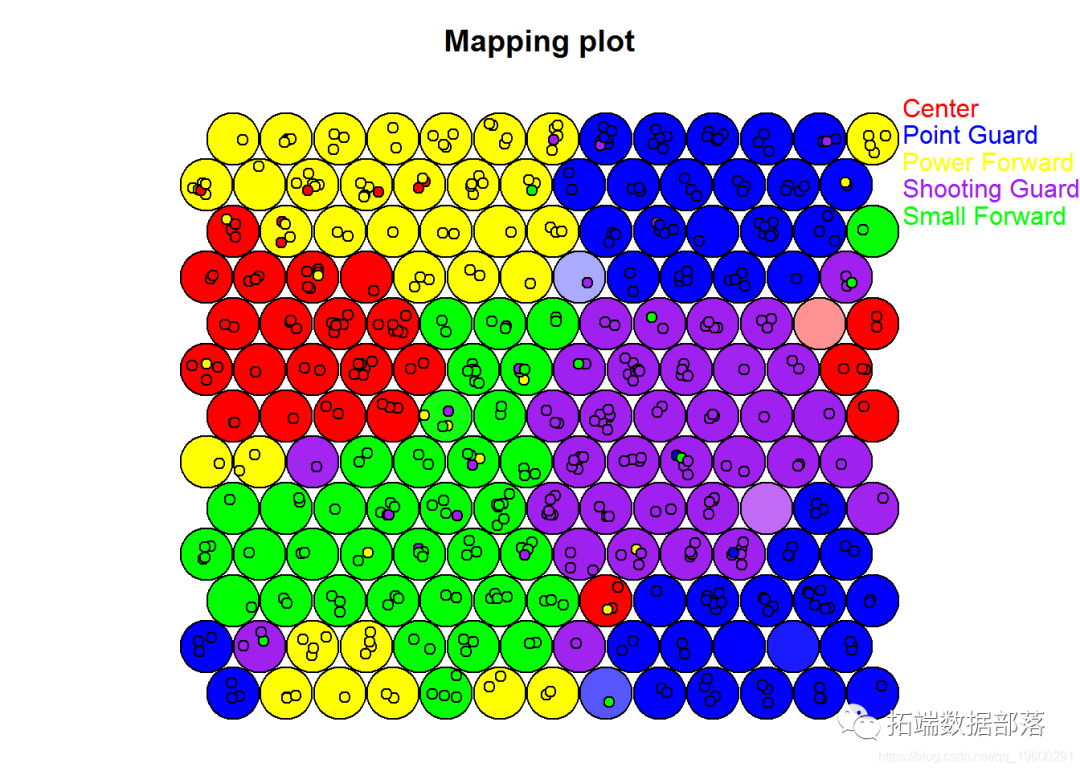
R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析

左右滑动查看更多
01
02
03

04
TensorFlow 的自组织映射(SOM)算法实现
本文详细阐述了利用 TensorFlow 实现自组织映射(SOM)算法的过程,通过对鸢尾花数据集进行处理与分析,展示了算法实现的具体步骤、代码实现以及结果输出。
自组织映射(SOM)算法在数据可视化、聚类等领域具有重要应用。本文利用 TensorFlow 库来实现该算法,并将其应用于鸢尾花数据集的分析。
算法实现过程
以下是基于 TensorFlow 实现 SOM 算法的代码:
# 加载鸢尾花数据集作为训练数据,包括输入特征和输出类别iris\_input = np.genfromtxt('iris.data.txt', delimiter='\\t', skip\_header=1, dtype=np.float64, usecols=(0, 1, 2, 3))# 计算映射节点到 BMU 的距离distance\_to\_bmu = tf.sqrt(tf.reduce\_sum(tf.cast(tf.squared\_difference(bmuc, nodes), dtype=tf.float64), reduction\_indices=\[1\]))distance\_to\_bmu2d = tf.reshape(distance\_to\_bmu, \[SOM\_HEIGHT, SOM\_WIDTH\])# 定义邻域函数,用于确定权重调整对映射节点的影响nf = tf.maximum(-(distance\_to\_bmu - radius) / radius, 0)nf2d = tf.reshape(nf, \[SOM\_HEIGHT, SOM\_WIDTH\])# 根据邻域函数和学习率更新权重adjusted = weights + tf.expand\_dims(nf, 1) * tf.expand\_dims(alpha, 1) * (data\_vector - weights)adj2d = tf.reshape(adjusted, \[SOM\_HEIGHT, SOM\_WIDTH, NUM\_INPUTS\])adjust = tf.assign(weights, adjusted)de2d = tf.transpose(tf.pack(to2d(de)))# 计算平均量化误差aqe = tf.reduce\_mean(tf.sqrt(tf.reduce\_sum(tf.squared\_difference(iris_input, tf.gather(weights, de)), 1)))在上述代码中,首先读取鸢尾花数据集。然后初始化权重,并通过随机选择数据向量,计算与映射节点的距离来找到最佳匹配单元(BMU)。根据邻域函数和学习率,不断更新权重,直到达到最大迭代次数。
实验结果
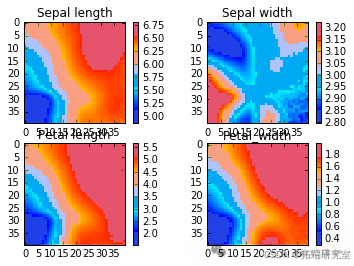
代码运行后,输出了平均量化误差。通过绘制图像展示了不同特征下权重的分布情况、umatrix 的数值分布以及不同类别鸢尾花在 SOM 映射中的位置分布。
plt.imshow(umatrix, interpolation='none')plt.colorbar()
``````
<matplotlib.colorbar.Colorbar at 0x7fa0f0b7e5f8>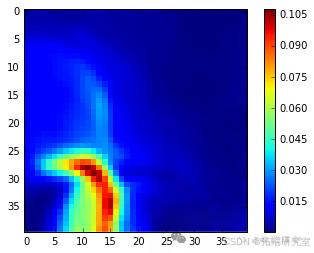
plt.plot(dd\[0:50,1\], SOM\_HEIGHT-dd\[0:50,0\], 'ro', label='I\_setosa')plt.plot(dd\[50:100,1\], SOM\_HEIGHT-dd\[50:100,0\], 'bo', label='I\_versicolor')plt.plot(dd\[100:150,1\], SOM\_HEIGHT-dd\[100:150,0\], 'go', label='I\_virginica')
``````
\[<matplotlib.lines.Line2D at 0x7fa0f0944e80>\]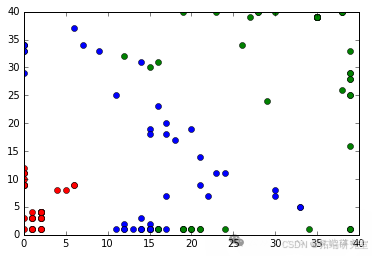
关于分析师

在此对 Chen Zhang 对本文所作的贡献表示诚挚感谢,他在上海财经大学完成经济统计学专业学位,专注于相关领域的研究。擅长 Python、SPSS、SQL server。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《TensorFlow深度学习框架改进K-means聚类、SOM自组织映射算法及上海招生政策影响分析研究》。
点击标题查阅往期内容
Python用 tslearn 进行时间序列聚类可视化
Python用KShape对时间序列进行聚类和肘方法确定最优聚类数k可视化
R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析
Python用RNN神经网络:LSTM、GRU、回归和ARIMA对COVID19新冠疫情人数时间序列预测
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
用PyTorch机器学习神经网络分类预测银行客户流失模型
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
Python主题建模LDA模型、t-SNE 降维聚类、词云可视化文本挖掘新闻组数据集
R语言用关联规则和聚类模型挖掘处方数据探索药物配伍中的规律
K-means和层次聚类分析癌细胞系微阵列数据和树状图可视化比较
KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
PYTHON实现谱聚类算法和改变聚类簇数结果可视化比较
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
R语言多维数据层次聚类散点图矩阵、配对图、平行坐标图、树状图可视化城市宏观经济指标数据
r语言有限正态混合模型EM算法的分层聚类、分类和密度估计及可视化
Python Monte Carlo K-Means聚类实战研究
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言谱聚类、K-MEANS聚类分析非线性环状数据比较
R语言实现k-means聚类优化的分层抽样(Stratified Sampling)分析各市镇的人口
R语言聚类有效性:确定最优聚类数分析IRIS鸢尾花数据和可视化
Python、R对小说进行文本挖掘和层次聚类可视化分析案例
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间
R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析
R语言复杂网络分析:聚类(社区检测)和可视化
R语言中的划分聚类模型
基于模型的聚类和R语言中的高斯混合模型
r语言聚类分析:k-means和层次聚类
SAS用K-Means 聚类最优k值的选取和分析
用R语言进行网站评论文本挖掘聚类
基于LDA主题模型聚类的商品评论文本挖掘
R语言鸢尾花iris数据集的层次聚类分析
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言聚类算法的应用实例



![]()