最近项目中需要评估业务部门搭建的RAG助手的效果好坏,看了一下目前业界一些评测的方法。目前分为两大类,基于传统的规则、机器学习的评测方法,基于大模型的评测方法。在这里做一些记录,上篇主要做评测方法的记录,下篇会详细分析下RAGas评测框架指标的一些实现
传统评测方法
基于字符规则
最常见的评测,是判断输出的字符是否包含、不包含或者正则满足一些规则。也可以给各个规则之间配置与或非的条件,这里的实现也比较简单,不过过多赘述
基于编程
相较于基于字符规则,允许适用方编写代码,给与了更大的灵活性,这里可以发挥的空间也更大。如果编程代码中也允许调用大模型接口,那可以实现很多种基于大语言模型的评测。
BLEU
https://blog.csdn.net/qq_36485259/article/details/136604753
BLEU(Bilingual Evaluation Understudy)是一种评估机器翻译质量的方法,特别是它如何接近人类翻译的程度。它通过计算机器翻译输出与一组参考翻译(通常是人类翻译)之间的重叠来工作。BLEU分数的范围通常是0到1,其中1表示完美的匹配,0表示没有重叠。
BLEU分数主要基于两个方面:n-gram精确度和短句惩罚。以下是BLEU度量的基本步骤:
- n-gram精确度:BLEU检查机器翻译输出中的n-gram(连续的n个词)与参考翻译中的n-gram有多少是匹配的。这里的n可以是1、2、3等,通常会计算多个n-gram长度的精确度,并对它们进行加权平均。
- 短句惩罚:为了避免机器翻译只输出很短的句子来提高n-gram精确度,BLEU引入了一个短句惩罚因子。如果机器翻译的句子比参考翻译短,那么它的BLEU分数会受到惩罚。
- 计算BLEU分数:对于每个n-gram长度,计算机器翻译输出与参考翻译之间的n-gram精确度,然后对这些精确度值应用短句惩罚,最后将它们结合起来得到一个综合的BLEU分数。
BERT
https://arxiv.org/abs/1904.09675
https://github.com/Tiiiger/bert_score
这篇论文介绍了BERTSCORE,这是一种新的文本生成自动评估指标,它利用了预训练的BERT模型的上下文嵌入。与传统依赖于表面形式相似性的度量方法(例如BLEU)不同,BERTSCORE使用上下文嵌入来计算令牌之间的相似性,这更好地捕捉了语义等价性。
BART
https://arxiv.org/abs/2106.11520
https://github.com/neulab/BARTScore
BARTSCORE是一种无监督的评估指标,它不需要人类提供标准答案或进行人工评判来训练。它的优势在于能够直接利用预训练的语言模型(如BART)来评估生成文本的质量,而不需要依赖于人类的标注数据。
具体来说,BARTSCORE通过以下方式工作:
- 模型训练:使用预训练的序列到序列(seq2seq)模型,如BART,该模型已经在大量文本数据上进行了训练,能够捕捉语言的复杂特征。
- 评估公式:BARTSCORE使用一个公式来计算生成文本的概率,该公式基于生成文本给定源文本或参考文本的条件下的对数概率之和。
- 无监督:由于BART模型已经在预训练阶段学习了丰富的语言表示,因此在评估新文本时不需要额外的人类标注数据。
- 多角度评估:通过改变输入和输出的方式,BARTSCORE能够从不同的角度(如信息量、流畅性、事实性等)对生成的文本进行评估。
基于大语言模型的评测
G-Eval
https://arxiv.org/abs/2303.16634?ref=blog.langchain.dev
https://github.com/nlpyang/geval
G-EVAL是一个用于评估自然语言生成(NLG)系统输出质量的框架,它利用大型语言模型(LLMs)和思维链(Chain-of-Thoughts,CoT)以及一种填表范式来评估。G-EVAL的核心思想是通过让大型语言模型根据给定的任务介绍和评估标准来自动生成详细的评估步骤(CoT),然后使用这些步骤来评估NLG输出。
效果
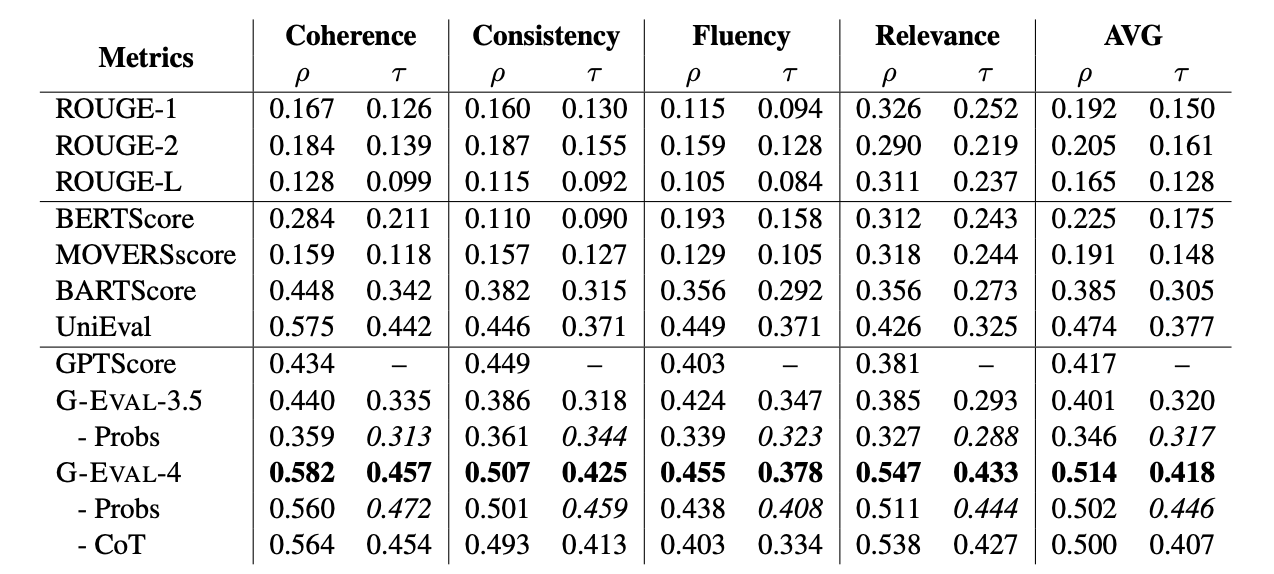
- SummaryEval
SummEval是一个用于评估文本摘要质量的基准测试。它提供了人类对每个摘要在四个方面上的评分:流畅性(fluency)、连贯性(coherence)、一致性(consistency)和相关性(relevance)。SummEval建立在CNN/DailyMail数据集上,后者是一个广泛用于文本摘要任务的数据集,包含了大量的新闻文章和相应的摘要。
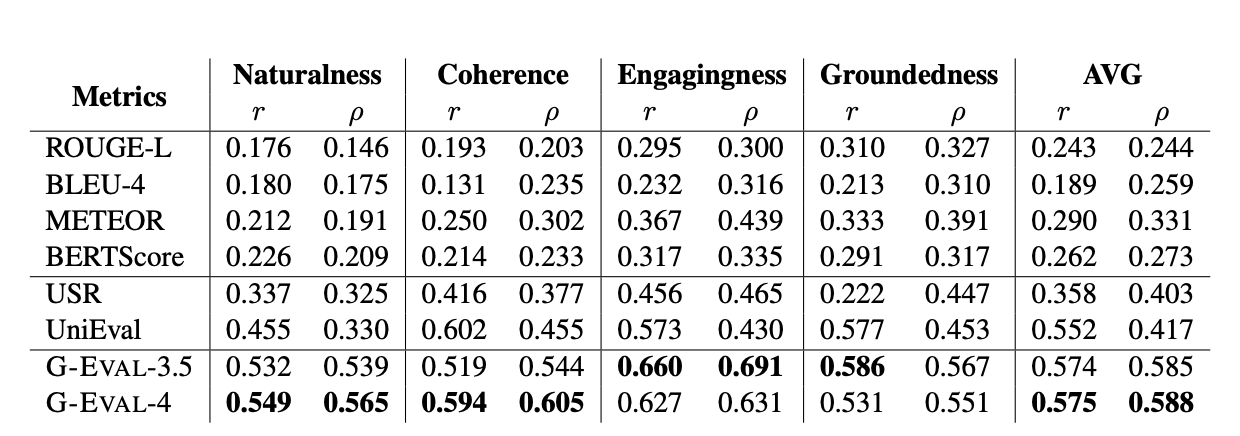
- Topical-Chat
Topical-Chat是一个用于元评估对话响应生成系统的测试平台,特别是那些使用知识的系统。它提供了人类对对话中每个回复在四个方面上的评分:自然性(naturalness)、连贯性(coherence)、引人入胜性(engagingness)和基于事实性(groundedness)。这个数据集用于评估对话系统生成的回复是否自然、相关,并且能否吸引用户继续对话。
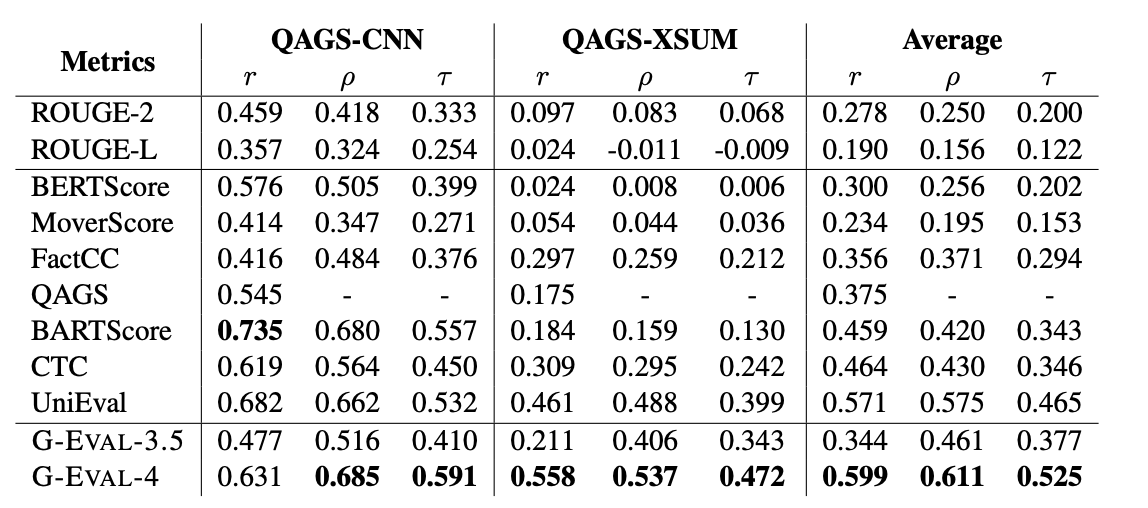
- QAGS
QAGS是一个用于评估摘要任务中事实一致性的基准测试。它旨在测量摘要在两个不同的摘要数据集上的事实一致性维度
实现
Evaluate Coherence in the Summarization Task
评估文本摘要任务中连贯性(Coherence)
You will be given one summary written for a news article.
Your task is to rate the summary on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
Evaluation Criteria:
Coherence (1-5) - the collective quality of all sentences. We align this dimension with the DUC quality question of structure and coherence whereby ”the summary should be well-structured and well-organized. The summary should not just be a heap of related information, but should build from sentence to sentence to a coherent body of information about a topic.”
Evaluation Steps:
1. Read the news article carefully and identify the main topic and key points.
2. Read the summary and compare it to the news article. Check if the summary covers the main topic and key points of the news article, and if it presents them in a clear and logical order.
3. Assign a score for coherence on a scale of 1 to 5, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria.
Example:
Source Text:
{{Document}}
Summary:
{{Summary}}
Evaluation Form (scores ONLY):
- Coherence:Evaluate Engagingness in the Dialogue Generation Task
Evaluate Engagingness in the Dialogue Generation Task
评估对话生成任务中回复的参与度(Engagingness)
You will be given a conversation between two individuals. You will then be given one potential response for the next turn in the conversation. The response concerns an interesting fact, which will be provided as well.
Your task is to rate the responses on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
Evaluation Criteria:
Engagingness (1-3) Is the response dull/interesting?
- A score of 1 (dull) means that the response is generic and dull.
- A score of 2 (somewhat interesting) means the response is somewhat interesting and could engage you in the conversation (e.g., an opinion, thought)
- A score of 3 (interesting) means the response is very interesting or presents an interesting fact
Evaluation Steps:
1. Read the conversation, the corresponding fact and the response carefully.
2. Rate the response on a scale of 1-3 for engagingness, according to the criteria above.
3. Provide a brief explanation for your rating, referring to specific aspects of the response and the conversation.
Example:
Conversation History:
{{Document}}
Corresponding Fact:
{{Fact}}
Response:
{{Response}}
Evaluation Form (scores ONLY):
- Engagingness:Evaluate Hallucinations
Human Evaluation of Text Summarization Systems:
Factual Consistency: Does the summary untruthful or misleading facts that are not supported by the source text?
Source Text:
{{Document}}
Summary:
{{Summary}}
Does the summary contain factual inconsistency?
Answer:RAGAs
https://arxiv.org/pdf/2309.15217
https://github.com/explodinggradients/ragas
https://docs.ragas.io/en/latest/index.html
使用 RAGAs(Retrieval Augmented Generation Assessment)进行评测的步骤可以概括为以下几个主要环节:
- 定义质量维度:
-
- 忠实度(Faithfulness):确保生成的答案能够从给定的上下文中推断出来,避免幻觉。
- 答案相关性(Answer Relevance):生成的答案应直接且适当地回答所提出的问题。
- 上下文相关性(Context Relevance):检索的上下文应集中且只包含回答所需的信息。
- 使用语言模型(LLM)进行评估:
-
- 利用一个大型语言模型(如 GPT-3.5 或更新版本)来自动化评估过程。
- 依据数据分别评估每个维度的分数
- 计算分数并迭代优化
效果
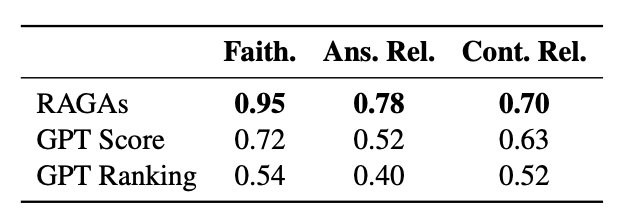
不同自动评测方法相较于人类评测的准确度
- 在忠实度(Faithfulness)上的预测与人类评估员的判断高度一致,准确率约为0.95。
- 在答案相关性(Answer Relevance)方面,RAGAs的一致性稍低,准确率约为0.78
- 在上下文相关性(Context Relevance)方面,RAGAs的准确率约为0.70,
实现
忠实度(Faithfulness)
- 忠实度评估的是生成答案是否能够从给定的上下文中推断出来。首先,使用 LLM 从生成的答案中提取一系列陈述。提取声明的 prompt 示例:
Given a question and answer, create one or more statements from each sentence in the given answer.
question: [question]
answer: [answer]- 然后,对于每个声明,使用 LLM 的验证函数来确定它是否可以从上下文中推断出来。验证声明的 prompt 示例:
Consider the given context and following statements, then determine whether they are supported by the information present in the context. Provide a brief explanation for each statement before arriving at the verdict (Yes/No). Provide a final verdict for each statement in order at the end in the given format. Do not deviate from the specified format.
statement: [statement 1]
...
statement: [statement n]- 最终的忠实度得分(F)是支持的声明数量与总声明数量的比例,使用以下公式计算:
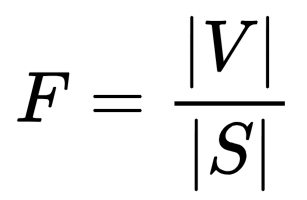
-
- F 代表忠实度得分。
- ∣V∣ 是模型验证后确认可以由上下文支持的声明的数量。
- ∣S∣ 是从答案中提取出的总声明数量。
答案相关性(Answer Relevance)
- 答案相关性评估的是生成答案是否直接且适当地回答了提出的问题。基于生成的答案,LLM 生成 n 个潜在的问题。生成潜在问题的 prompt 示例:
Generate a question for the given answer.
answer: [answer]- 使用文本嵌入模型计算原始问题与每个潜在问题之间的相似度。
- 答案相关性评分计算公式:
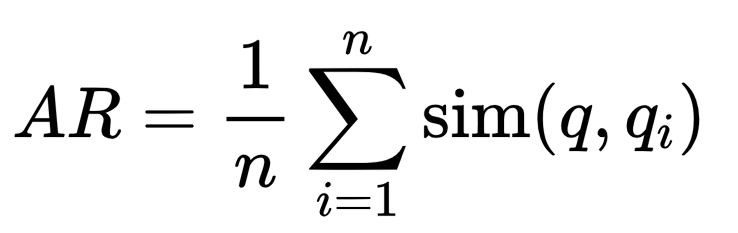
-
- AR 是答案相关性评分
-
是原始问题 q 与潜在问题 qi 之间的相似度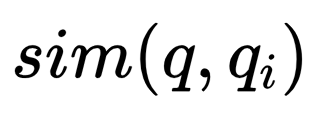
上下文相关性(Context Relevance)
- 上下文相关性评估的是检索的上下文是否只包含回答所需的信息,避免包含冗余信息。LLM 从给定的上下文中提取对回答问题至关重要的句子子集。提取相关句子的 prompt 示例:
Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you’re not allowed to make any changes to sentences from given context.- 上下文相关性评分计算公式:
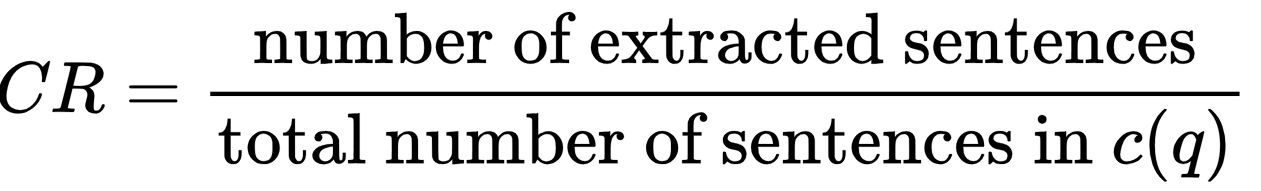
-
- 其中 CR 是上下文相关性评分
GPT Score
https://arxiv.org/pdf/2302.04166