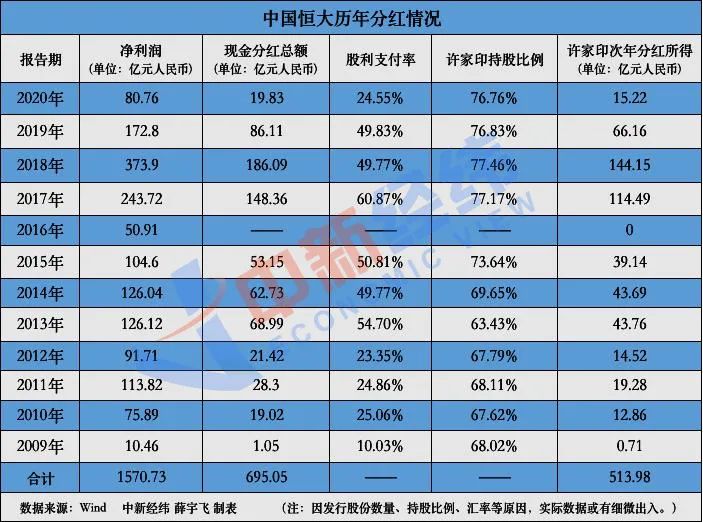
这篇文章中,我探讨了最近的一项实验,旨在创建一个针对保险行业量身定制的 RAG 管道,专门用于处理汽车保险索赔,目的是尽可能减少处理时间。
我还展示了 Autogen AI Agents 的实施,通过代理交互和对样本汽车保险索赔文件、问答用例的函数调用来增强搜索检索,以及此工作流程如何大幅减少索赔处理所需的时间。
我认为 RAG 工作流代表了一种新颖的数据堆栈,不同于传统的 ETL 流程。虽然它们包含与数据工程中的传统 ETL 类似的数据提取和处理,但它们引入了额外的管道阶段,例如分块、嵌入和将数据加载到矢量数据库中,这与标准的 Lakehouse 或数据仓库管道不同。
RAG 申请流程的每个阶段都对下游 LLM 申请的准确性和针对性至关重要。其中一个阶段是分块方法,对于这个概念验证,我选择测试一种基于页面的分块技术,该技术利用文档的布局而不依赖第三方软件包。
主要服务和特点:
通过利用 Azure AI 服务的企业级功能,我可以通过私有端点安全地集成 Azure AI 文档智能、Azure AI 搜索和 Azure OpenAI。这种集成可确保解决方案符合最佳实践的网络安全标准。此外,它还提供安全的网络隔离以及与虚拟网络和相关 Azure 服务的私有连接。
其中一些服务是:
- Azure AI 文档智能和预建布局模型。
- 配置了HNSW 搜索算法的Azure AI 搜索索引和向量数据库。
- Azure OpenAI GPT-4-o 模型。
- 基于页面的分块技术。
- Autogen AI 代理。
- Azure Open AI 嵌入模型:text-ada-003。
- Azure 密钥保管库。
- 所有服务的私有端点集成。
- Azure Blob 存储。
- Azure Function App。(此无服务器计算平台可以用Microsoft Fabric或Azure Databricks替换)
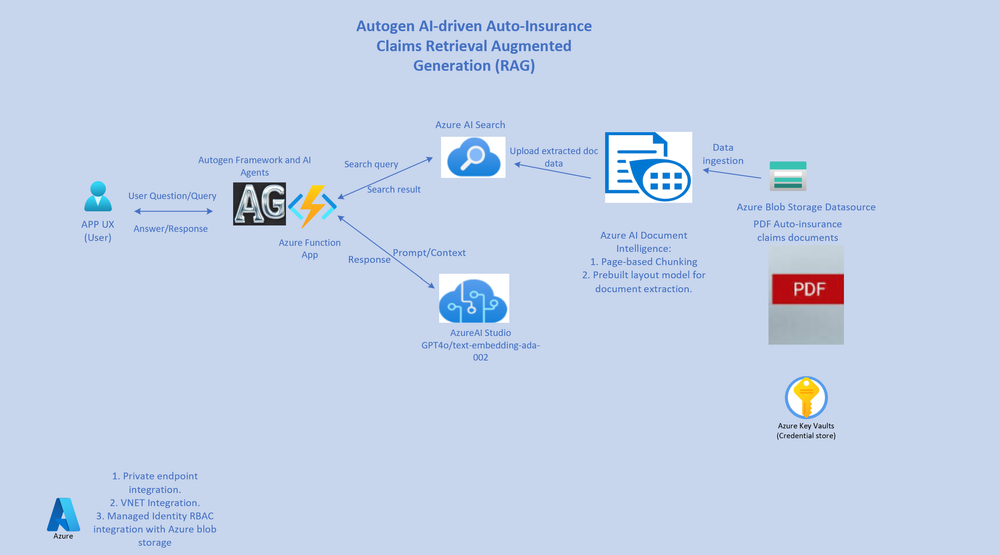
文档提取和分块:
这些模板包括表格,其中包含详细说明事故地点、描述、相关方的车辆信息以及任何受伤情况的数据。感谢LlamaIndex的工作人员提供索赔文件样本。以下是表格模板的示例。

索赔样本表
索赔文件是存储在 Azure Blob 存储中的 PDF 文件。数据提取从 Blob 存储的容器 URL 开始,使用 Azure AI 文档智能 Python SDK。
这种基于页面的分块方法的实现利用了 Azure AI 文档智能 SDK 的 markdown 输出。该 SDK 设置了预构建的布局提取模型,可将页面内容(包括表单和文本)提取为 markdown 格式,同时保留文档的特定结构(例如段落和章节)及其上下文。
SDK 通过文档的 pages 集合,方便逐页提取文档,从而可以按顺序组织 markdown 输出数据。每页都作为页面列表中的元素保存,从而简化了高效提取每个段页码的过程。有关文档智能服务和布局模型的更多详细信息,请参阅此链接。
下面的代码片段说明了基于页面的提取、页面元素的预处理以及将它们分配给 Python 列表的过程:
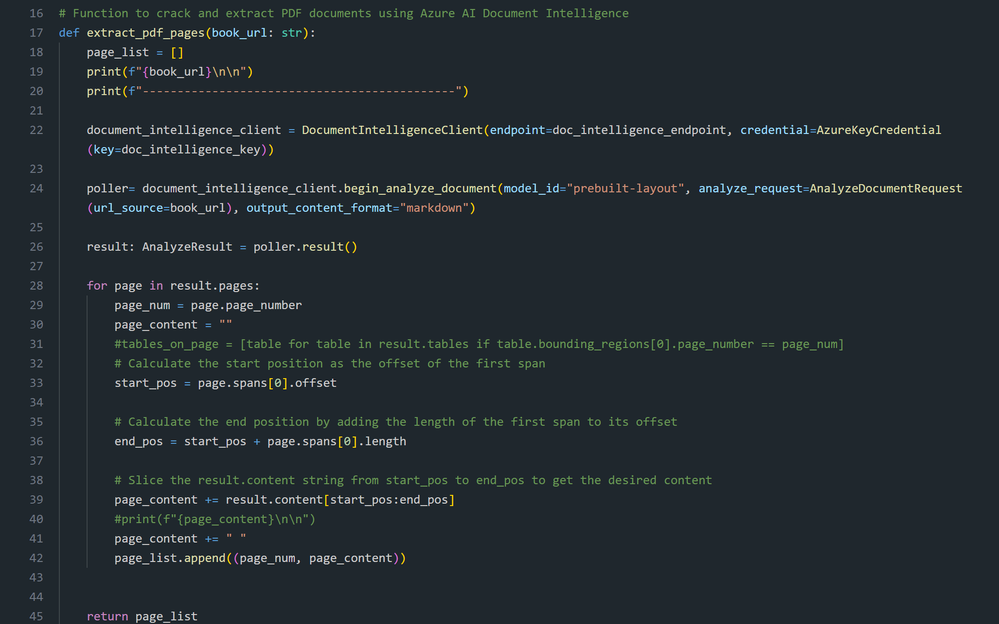
页面提取
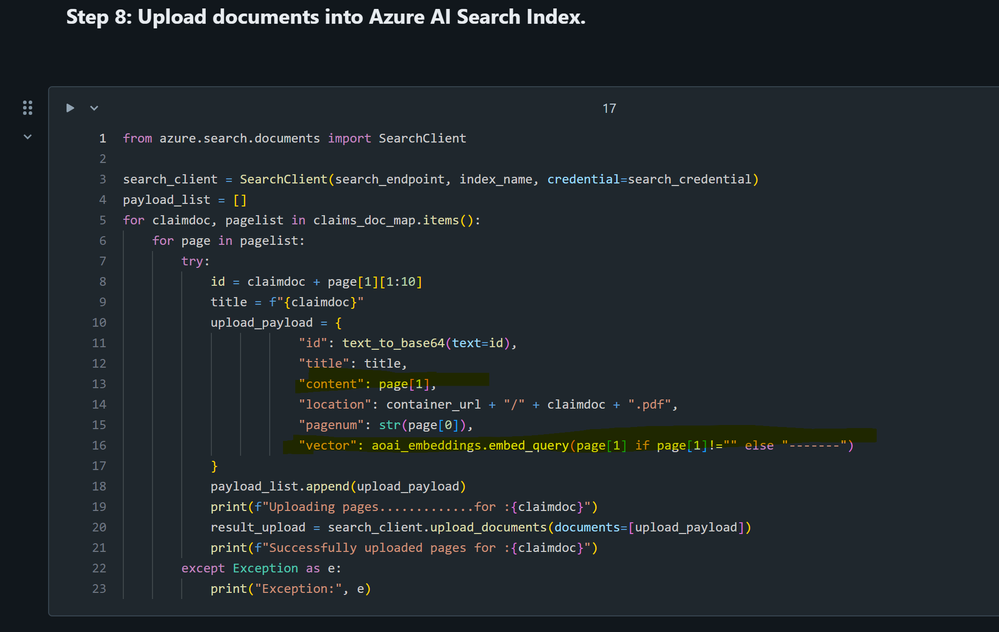
每个页面内容将与向量索引中的其他元数据字段一起用作向量数据库索引中的内容字段的值。每个页面内容都是其自己的块,将在加载到向量数据库之前嵌入。以下代码片段演示了此操作:
定义 Autogen AI 代理和代理工具/功能:
AI 代理的概念模仿了人类的推理和问答过程。代理由大型语言模型(其大脑)驱动,该模型可帮助确定是否需要更多信息来回答问题,或者是否需要执行工具来完成任务。
相比之下,非代理 RAG 管道包含精心设计的提示,这些提示在向 LLM 发起响应请求之前集成了来自向量存储的上下文信息(通常通过提示中的上下文变量)。AI 代理拥有自主权,可以确定完成任务或提供答案的“最佳”方法。这个实验展示了一个简单的代理 RAG 工作流程。在即将发布的文章中,我将深入研究更复杂的代理驱动的 RAG 解决方案。有关 Autogen Agents 的更多详细信息,请点击此处。
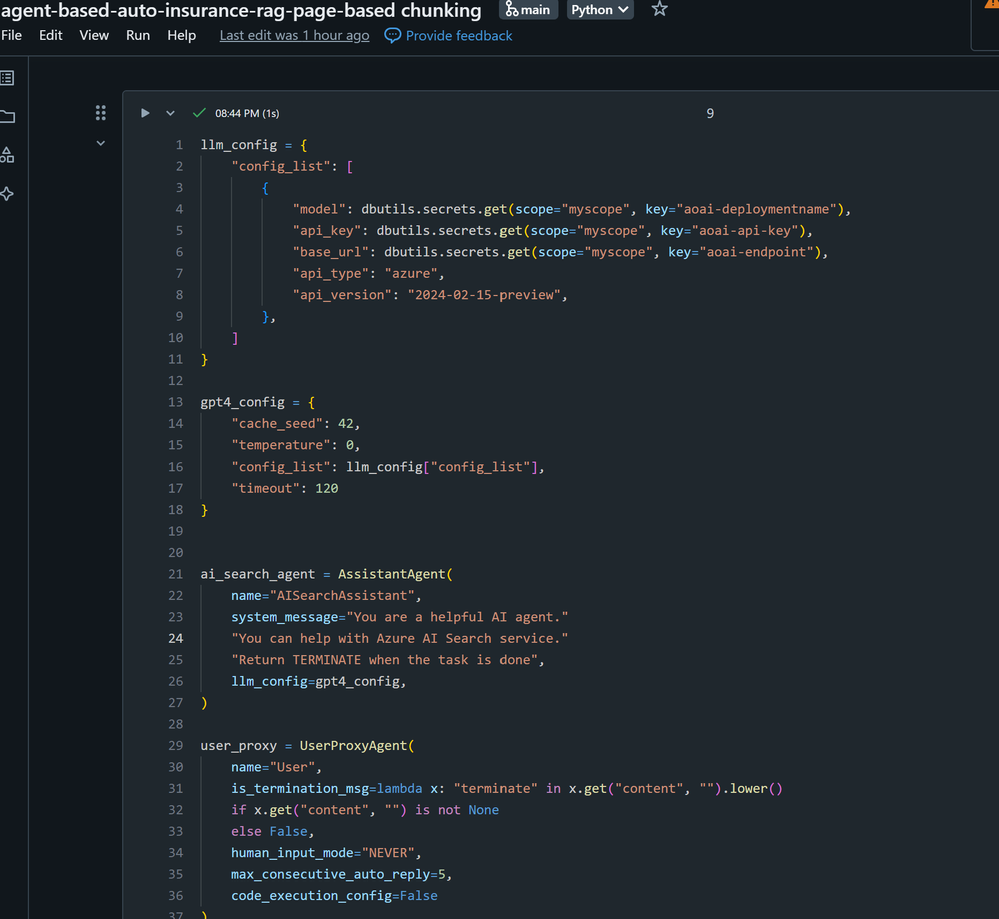
我设置了两个 Autogen 代理实例,旨在模拟或参与它们之间的问答聊天对话,以根据输入消息执行搜索任务。为了促进代理通过函数调用从 Azure AI Search 向量存储中搜索和获取查询结果的能力,我编写了一个将与这些代理关联的 Python 函数。配置为调用该函数的 AssistantAgent 和负责执行该函数的 UserProxyAgent 都是 Autogen Conversable Agent 类的示例。
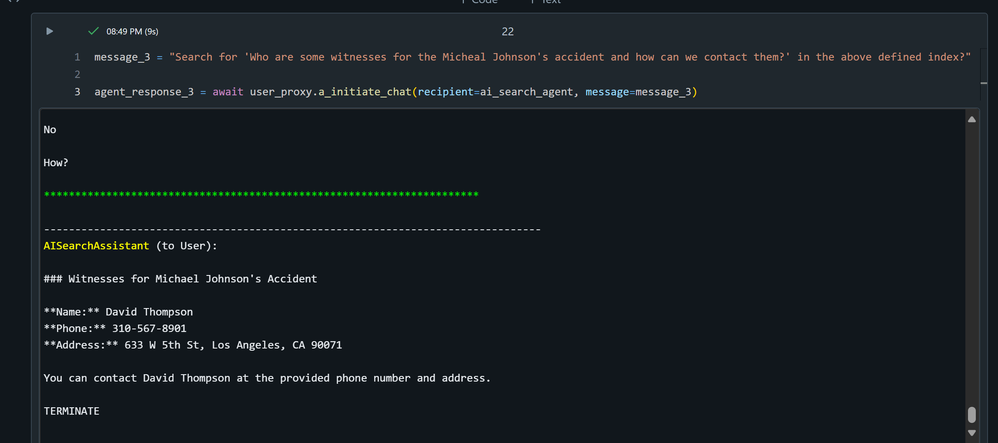
用户代理通过询问搜索文档的问题来与助理代理开始对话,助理代理根据系统消息提示指令和从向量库中获取的上下文数据,收集并合成响应。
以下代码片段提供了 Autogen 代理的定义以及代理之间的聊天对话。完整的笔记本实现可在链接的 GitHub存储库中找到。
最后的想法:
助理代理正确回答了所有六个问题,这与我对文件信息和基本事实的评估一致。此概念验证展示了将相关服务集成到 RAG 工作流程中以开发 LLM 应用程序,旨在大幅缩短汽车保险行业场景中处理索赔的时间。
如前所述,RAG 工作流程的每个阶段都对响应质量至关重要。助理代理的系统消息提示需要精确制作,因为它可以根据设定的指令改变响应结果。同样,自定义检索功能的逻辑在代理定位和合成消息响应的能力中起着重要作用。
答案的准确性已通过人工评估。理想情况下,该流程应实现自动化。
在即将发布的文章中,我打算探讨 RAG 工作流程的自动评估。可以使用哪些方法来准确评估并随后改进 RAG 流程?
RAG 过程的检索和生成阶段都需要彻底的评估。
我们可以使用哪些工具来准确评估 RAG 工作流的端到端阶段,包括提取、处理和分块策略?我们如何比较各种分块方法,例如本文中描述的基于页面的分块与递归字符文本拆分分块选项?
我们如何比较 HNSW 向量搜索算法和 KNN 穷举算法的检索结果?
有哪些可用的评估工具以及可以为基于代理的系统捕获哪些指标?
是否有一个万能的工具可以管理这些问题?我们将找到这些问题的答案。
此外,我还想研究和评估如何审查这个和其他 RAG 和生成性人工智能工作流程,以确保符合公平性、可靠性和安全性、隐私性和安全性、包容性、透明度和问责制的标准,如构建和开发这些系统的负责任的人工智能道德框架中所定义。