题目链接:160. 相交链表 - 力扣(LeetCode)
注:下述题目描述和示例均来自力扣

题目描述
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
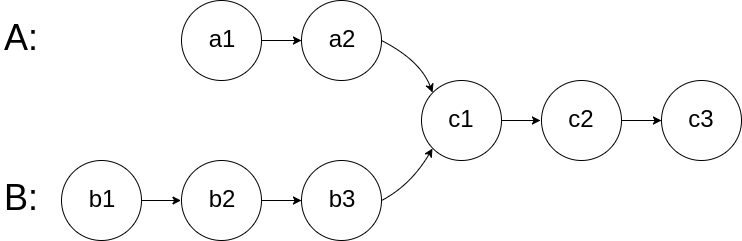
图示两个链表在节点 c1 开始相交:
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal- 相交的起始节点的值。如果不存在相交节点,这一值为0listA- 第一个链表listB- 第二个链表skipA- 在listA中(从头节点开始)跳到交叉节点的节点数skipB- 在listB中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例
示例 1:
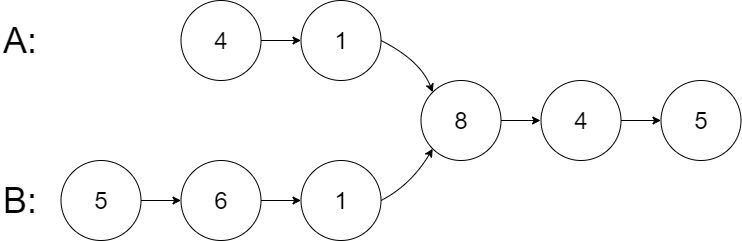
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:
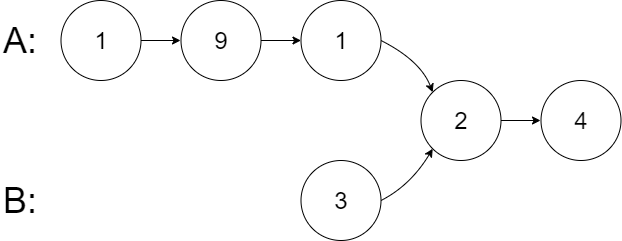
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
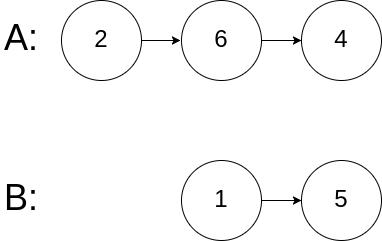
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA中节点数目为mlistB中节点数目为n1 <= m, n <= 3 * 10^41 <= Node.val <= 10^50 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA] == listB[skipB]
解法一:双重遍历寻找相同地址
实现思路
这段代码的思路是通过双重循环遍历两个链表,逐个比较每个节点的地址来寻找相交节点。
-
特殊情况处理:首先检查输入的两个链表是否为空。如果其中一个链表为空,显然它们不可能相交,直接返回
null。 -
初始化指针:将两个指针
a和b分别指向链表A和链表B的头节点,用于遍历链表。 -
遍历逻辑:
- 外层循环遍历链表A的每个节点。
- 内层循环遍历链表B的每个节点。
- 在内层循环中,如果节点
a和节点b的地址相同(即它们引用的是同一个节点),则表示找到了相交节点,记录这个节点并退出循环。
-
重新遍历链表B:当链表B被遍历完没有找到相交节点时,指针
a后移一个节点,指针b重新回到链表B的起点,继续外层循环。 -
终止条件:如果找到了相交节点,标志位
flag变为false,立即结束循环。如果遍历完所有节点也没有找到相交节点,则返回null。
通过暴力的双重循环遍历,逐一比较链表A的每个节点与链表B的每个节点,找到它们的第一个公共节点(相交节点)。
Java代码实现
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
// 如果链表本来就是空的那么肯定没有相交的节点
if (headA == null || headB == null){
return null;
}
ListNode a = headA;
ListNode b = headB;
ListNode resNode = null;
// 定义信号位用于判断是否出现了相交节点
boolean flag = true;
// 判断a是否遍历完了
while (flag && a != null){
// 判断b是否遍历完了
while (flag && b != null){
// 这里的a和b都是地址,如果地址是同一个那么意味着就是相交节点
if (a == b){
resNode = a;
flag = false;
}else {
// 不是那就让b下一位
b = b.next;
}
}
if (!flag){
break;
}
// 如果b被遍历完了都没有找到那么久a后移,然后b重新定位到开头
if (b == null){
a = a.next;
b = headB;
}
}
return resNode;
}
}
C++代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(nullptr) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
// 如果链表本来就是空的那么肯定没有相交的节点
if (headA == nullptr || headB == nullptr) {
return nullptr;
}
ListNode *a = headA;
ListNode *b = headB;
ListNode *resNode = nullptr;
// 定义信号位用于判断是否出现了相交节点
bool flag = true;
// 判断a是否遍历完了
while (flag && a != nullptr) {
// 判断b是否遍历完了
while (flag && b != nullptr) {
// 这里的a和b都是地址,如果地址是同一个那么意味着就是相交节点
if (a == b) {
resNode = a;
flag = false;
} else {
// 不是那就让b下一位
b = b->next;
}
}
if (!flag) {
break;
}
// 如果b被遍历完了都没有找到那么a后移,然后b重新定位到开头
if (b == nullptr) {
a = a->next;
b = headB;
}
}
return resNode;
}
};
使用时间

解法二:哈希表
实现思路
-
特殊情况处理:首先判断两个链表是否为空。如果任意一个链表为空,那么它们不可能相交,直接返回
null。 -
遍历链表A并存储节点:将链表A的所有节点存入一个哈希表中。因为哈希表的查找时间复杂度是 O(1),这一步的目的是为了快速判断链表B的节点是否存在于链表A中。
-
遍历链表B:遍历链表B的每个节点,检查该节点是否存在于哈希表中。如果存在,说明找到了两个链表的相交节点,直接返回该节点。
-
返回结果:如果遍历完链表B后,仍未找到任何相交节点,则返回
null。
通过这种方式,算法有效地利用了哈希表的快速查找能力来减少时间复杂度。整个过程的时间复杂度是 O(N + M),其中 N 是链表A的长度,M 是链表B的长度。
Java代码实现
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
// 如果链表本来就是空的那么肯定没有相交的节点
if (headA == null || headB == null){
return null;
}
ListNode a = headA;
ListNode b = headB;
// 利用哈希表存储a中的值
Set<ListNode> setA = new HashSet<>();
// 将链表a的值全部存入哈希表
while (a != null){
setA.add(a);
a = a.next;
}
// 遍历B看a中是否有和b相同的点位(地址)
while (b != null){
if (setA.contains(b)) {
return b;
}else {
b = b.next;
}
}
// 没找到返回null
return null;
}
}C++代码实现
#include <unordered_set>
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(nullptr) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
// 如果链表本来就是空的那么肯定没有相交的节点
if (headA == nullptr || headB == nullptr) {
return nullptr;
}
ListNode *a = headA;
ListNode *b = headB;
// 利用哈希表存储a中的节点地址
std::unordered_set<ListNode*> setA;
// 将链表A中的节点全部存入哈希表
while (a != nullptr) {
setA.insert(a);
a = a->next;
}
// 遍历链表B,查找是否有相同节点
while (b != nullptr) {
if (setA.find(b) != setA.end()) {
return b; // 找到相交节点
} else {
b = b->next;
}
}
// 没找到返回nullptr
return nullptr;
}
};
使用时间

解法三:双指针
实现思路
一句话,你没发现这个两个链表是互补的吗??
给A链表增加B链表的长度,给B链表增加A链表的长度
这样他俩就一样了,那么我们让他们走一样了路程了,那一刻,那个位置
不就刚好是相交的位置吗,完美至极!!!

具体大家可以看看官方题解的说明,说的比我详细,但是我属于是一语道破天机嘿嘿
-
特殊情况处理:首先检查两个链表是否为空。如果任意一个链表为空,直接返回
null,因为链表为空不可能有相交节点。 -
双指针初始化:定义两个指针
A和B,分别指向链表A和链表B的头节点。 -
双指针遍历链表:两个指针同时向前遍历。如果
A指针到达链表A的末尾,则将其重新指向链表B的头节点;同样,如果B指针到达链表B的末尾,则将其重新指向链表A的头节点。 -
相交节点判断:通过这种指针交换的方式,最终
A和B将在相交点相遇。如果两个链表存在相交节点,指针A和B最终会指向相同的节点;如果没有相交节点,它们最终都会变为null,结束循环。 -
返回结果:当
A和B相等时,说明找到了相交节点,直接返回。如果遍历结束仍未相等,则说明没有相交节点,返回null。
这种方法的时间复杂度是 O(N + M),其中 N 和 M 分别是两个链表的长度。通过让两个指针走过相同的总长度,实现了同时到达相交节点或结束。
Java代码实现
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode A = headA, B = headB;
while (A != B) {
A = A == null ? headB : A.next;
B = B == null ? headA : B.next;
}
return A;
}
}C++代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(nullptr) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if (headA == nullptr || headB == nullptr) {
return nullptr;
}
ListNode *A = headA;
ListNode *B = headB;
// 当A和B不相等时,遍历两个链表
while (A != B) {
// 如果A遍历到链表尾端,重定向到链表B的头部
A = A == nullptr ? headB : A->next;
// 如果B遍历到链表尾端,重定向到链表A的头部
B = B == nullptr ? headA : B->next;
}
// 当A == B时,返回相交节点或nullptr(如果无相交)
return A;
}
};
使用时间

总结
从直接暴力的思路到采用哈希表优化到发现两个链表的互补关系,我们拿下了全世界99.91%的人,我们太强了!!!!!!!!!!!!!