前沿科技速递🚀
在人工智能飞速发展的今天,通用对话与代码生成的融合已经成为开发者高效工作的关键工具。近日,DeepSeek 团队正式发布了全新的 DeepSeek-V2.5 模型,一个强大的开源模型,它将通用语言处理与代码生成能力结合,成为开发者与研究者们强大的智能助手。
来源:传神社区
01 DeepSeek-V2.5 模型简介
DeepSeek-V2.5 是对 DeepSeek-V2-Chat 和 DeepSeek-Coder-V2-Instruct 的全面升级,将两者的优势深度融合,使其具备了更强的通用对话与编程能力。无论是日常对话、复杂的指令跟随,还是代码生成和补全任务,DeepSeek-V2.5 都能轻松胜任。
核心亮点
-
通用与代码能力合一:既能胜任对话任务,又能高效处理代码任务,是真正的 “All-in-One” 模型。
-
人类偏好对齐优化:通过更好地对齐人类偏好,DeepSeek-V2.5 在多项任务中表现得更加自然、智能。
-
开源透明:模型完全开源,开发者们可以根据自己的需求进行调整和优化。
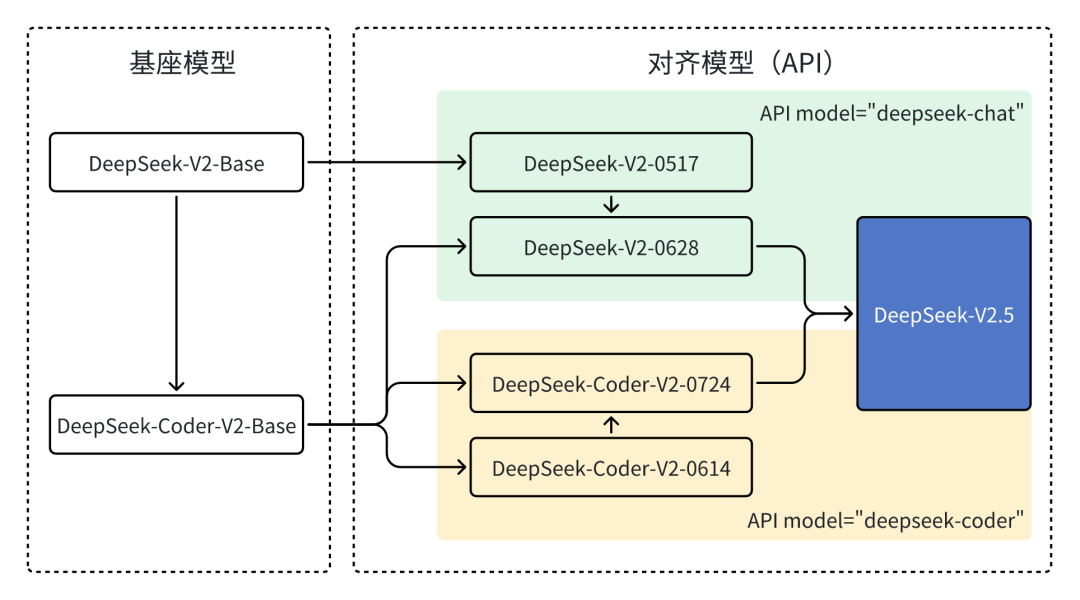
02 模型表现如何?数据告诉你!
在多项评测中,DeepSeek-V2.5 的表现都非常突出,尤其在代码生成和复杂任务处理方面
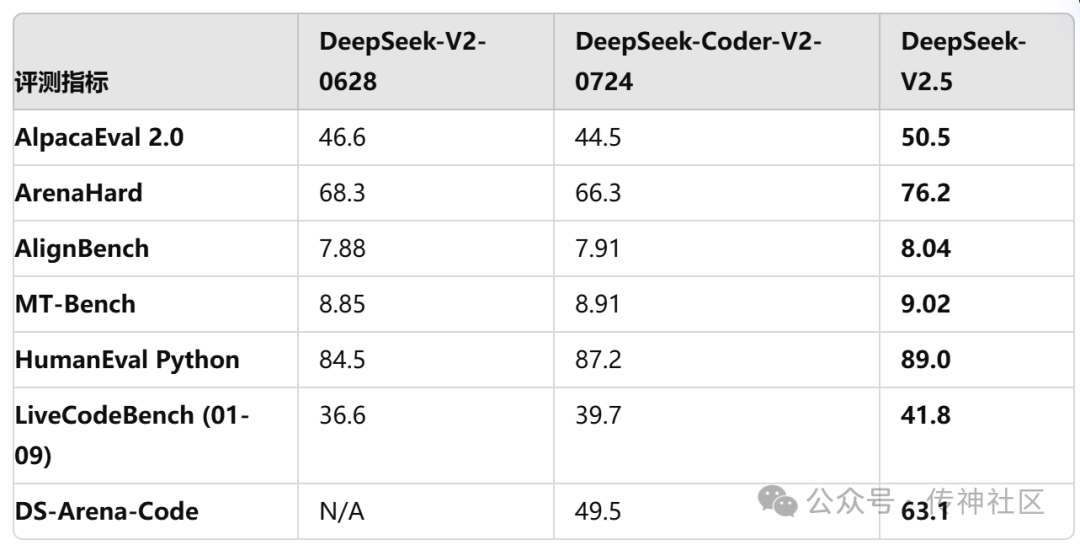
从数据看表现:
-
通用能力提升:在 AlpacaEval 2.0 和 ArenaHard 等通用任务中,DeepSeek-V2.5 展示了极大的提升,特别是在复杂任务中的表现更为突出。
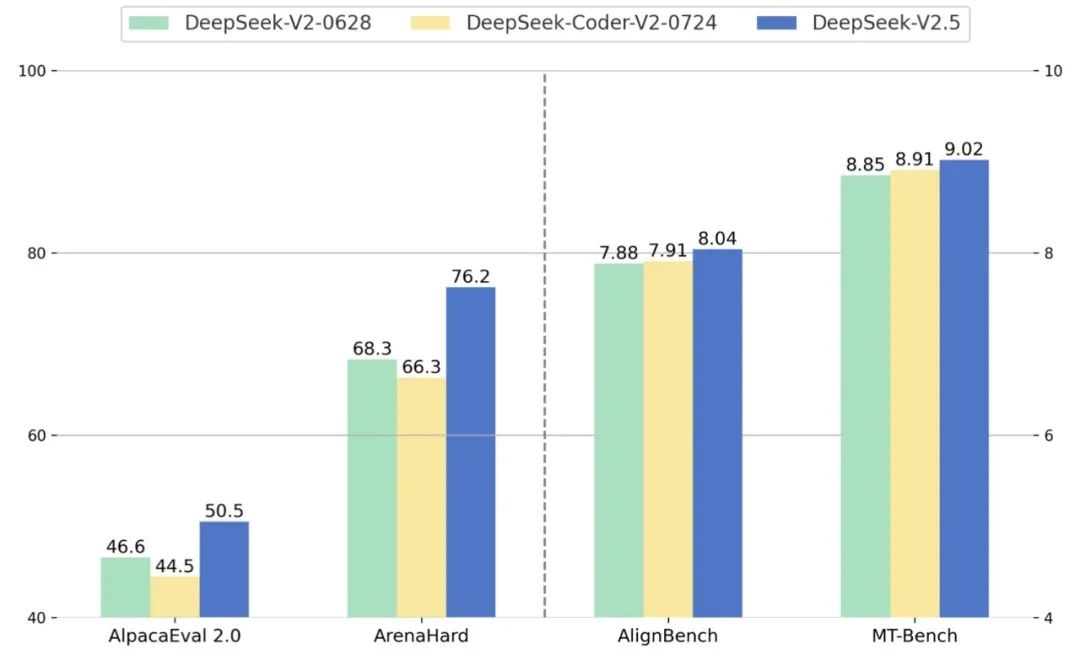
在DeepSeek内部的中文评测中,和 GPT-4o mini、ChatGPT-4o-latest 的对战胜率(裁判为 GPT-4o)相较于 DeepSeek-V2-0628 均有明显提升。此测评中涵盖创作、问答等通用能力,用户使用体验将得到提升:
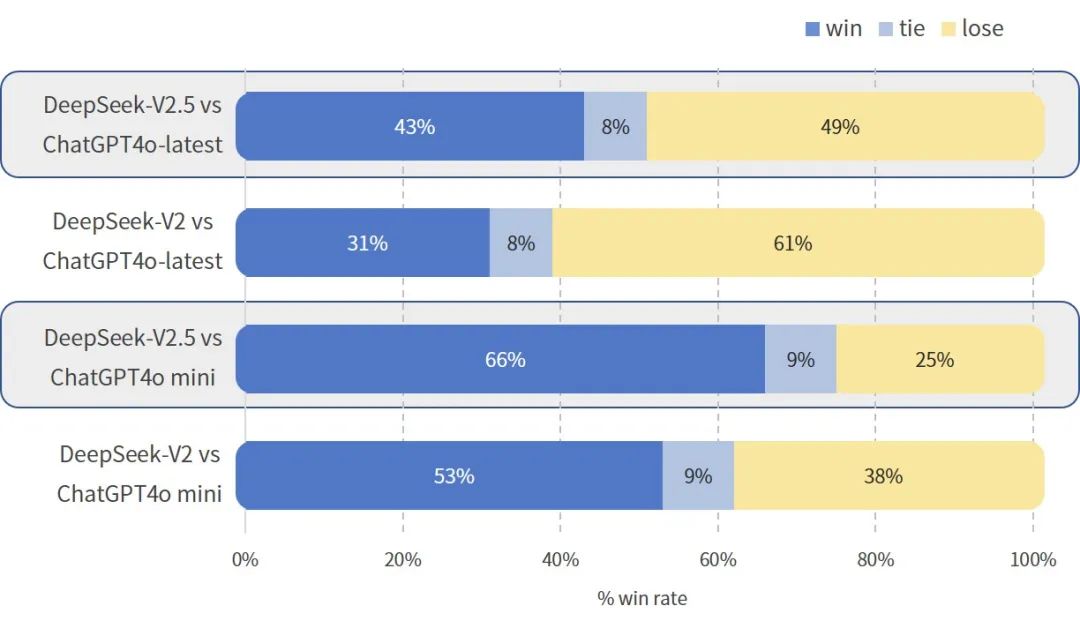
-
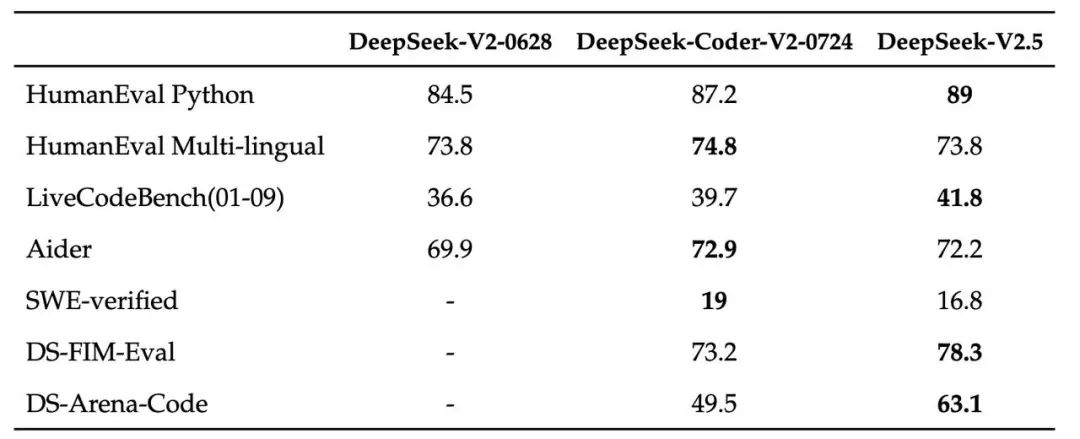
编程能力更强:在代码方面,DeepSeek-V2.5 保留了 DeepSeek-Coder-V2-0724 强大的代码能力。在 HumanEval Python 和LiveCodeBench(2024 年 1 月 - 2024 年 9 月)测试中,DeepSeek-V2.5 显示了较为显著的改进。在 HumanEval Multilingual 和 Aider 测试中,DeepSeek-Coder-V2-0724 略胜一筹。在 SWE-verified 测试中,两个版本的表现都较低,表明在此方面仍需进一步优化。
另外,在FIM补全任务上,内部评测集DS-FIM-Eval的评分提升了 5.1%,可以带来更好的插件补全体验。HumanEval Python 和 LiveCodeBench 的测试中,DeepSeek-V2.5 分别取得了 89.0 和 41.8 的高分,远超同类模型,为开发者们提供了更加智能的代码生成与补全体验。
03 使用实例
以下是小编对通用对话能力和代码助手的测试
04 模型下载
传神社区:
https://opencsg.com/models/deepseek-ai/DeepSeek-V2.5
huggingface:
https://huggingface.co/deepseek-ai/DeepSeek-V2.5
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区