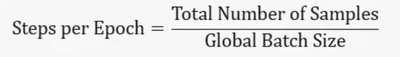为了让广大的开发者
更深入地了解
百度地图开放平台的
技术能力
轻松掌握满满的
技术干货
更加简单地接入
位置服务
我们特别推出了
“位置服务(LBS)开发微课堂”
系列技术案例
第二期的主题是
《轨迹重合率分析API升级》
百度地图的鹰眼轨迹服务是一款行业领先的商用级轨迹管理服务,它结合百度地图专业精准的地理位置数据优势,助力开发者更高效地进行轨迹的分析和处理,让轨迹数据创造更大的价值。
在轨迹数据的分析处理中,重合率是非常重要的指标,不仅可用于聚类分析,还能帮助识别出异常数据。结合用户反馈,鹰眼轨迹服务对轨迹重合率分析API进行了全面的升级。
此次升级在轨迹上限、分析精度以及可用范围上均实现了显著提升,不仅突破了以往轨迹点数、轨迹距离的限制,同时也降低了使用门槛,使用该服务更加便捷高效。
01 问题引入
轨迹重合率分析在众多行业中都展现出了广泛的应用价值。
例如,在危化品运输过程中,要求运输车辆必须严格按照规划路线行驶。这就需要从车辆采集的数千公里长距离轨迹中,准确识别出偏航情况并标识出偏航路段。

同样,在网约车行业中,顺风车拼单是一个典型的业务场景。这需要从愿意拼车的候选轨迹集合中,找出收益最高的轨迹组合,并评估拼单对原订单的影响。
轨迹 1
轨迹 2
在这些实际应用场景中,对轨迹的重合率分析服务都提出了较高的要求。
02 轨迹重合率分析升级
2.1 效果提升
为了更好地满足实际应用场景中的各类复杂需求,鹰眼轨迹服务的重合率分析API进行了以下升级:
1. 支持的点数提升到单条轨迹5万点,且对轨迹长度不作限制。这一升级可以满足货运客户纵贯南北、横贯东西的超长距离轨迹分析需求。
2. 消除了对路网数据的强依赖,可以对全球用户提供效果一致的重合率分析能力。
3. 提供了可配置的匹配半径功能,让用户能够自由定义“重合”的标准。这一功能既可以满足网约车米级精度的偏航识别需求,也可以用于海运海里级的偏航分析。
4. 消除了对轨迹时间戳和点间距的依赖。路线规划出的路线简单拼接后就可以直接进行分析,极大地降低了使用难度。
新旧版本特性对照:
| 优化点 | 优化前 | 优化后 |
| 轨迹点数 | 500 ~ 2000点 | 50000点 |
| 距离提升 | 500km | 不限距离 |
| 轨迹真实时间戳 | 必须 | 可选 |
| 可用区域 | 路网覆盖(国内) | 不限 |
| 重合判定阈值 | 固定 | 可调 |
2.2 匹配算法优化
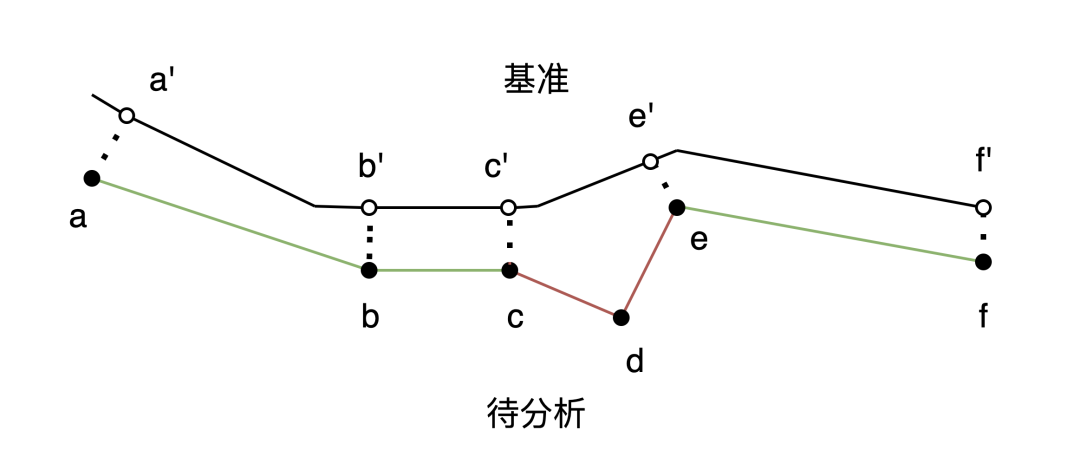
旧版API:采用"线-线"匹配的方式判断重合
(1)图中待分析轨迹的c'、d'两段,与基准轨迹中的c段属性要素(方向/经纬度)差异大于阈值,则视为不重合,其他段则视为重合。
(2)引入基础路网绑路,使用修正后的轨迹进行判断,可以有效减少匹配错误,但也限制了使用区域,增加了资源成本。

新版API:采用"点-线"匹配的方式判断重合
(1)将待分析轨迹中的形点,根据匹配半径召回基准轨迹中的线段,并根据属性要素(距离/方向/点序)计算形点落在线段上的放射概率,取放射概率最大的线段计算投影点。若相邻原始点组成的直线(如ab)与投影点在基准轨迹截取的折线(如a'b')小于阈值,则视为重合。
(2)若形点(如d)未召回任何线段,则该形点与前后点组成的线段(cd和de)视为与基准轨迹不重合。
2.3 细分场景表现
2.3.1 无路网场景
海面无路网的情况,仍可以提供重合率分析能力。
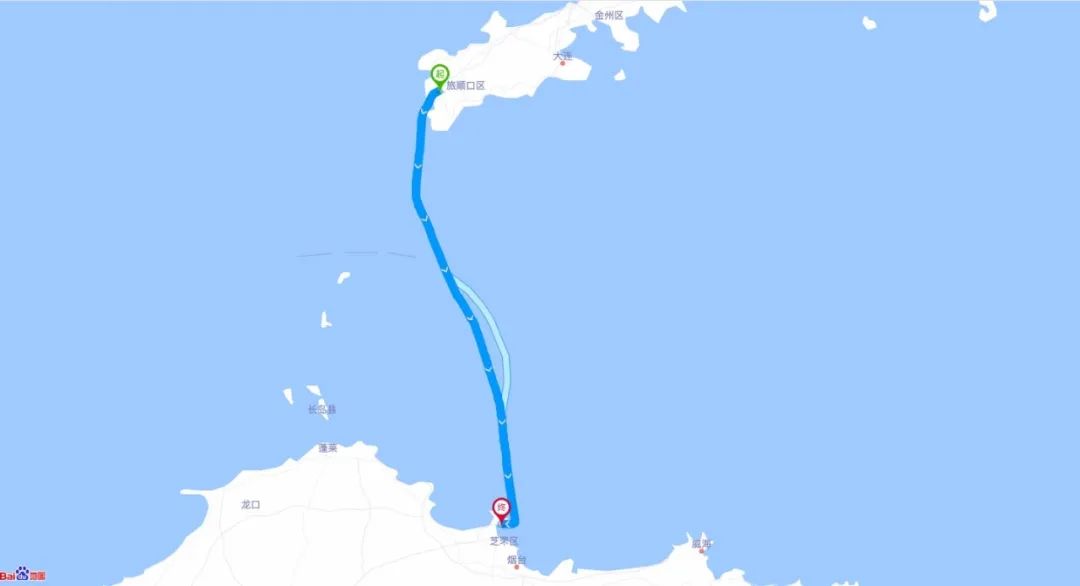
重合率结果(部分):
{
"status": 0,
"message": "OK",
"data": {
"similarity": 67.65,
"standard_track_distance": 151002.05,
"track_distance": 154475.49,
"unmatched_distance": 51060.44,
"matched_distance": 103415.05,
"standard_match_ratio": 68.37,
"standard_matched_distance": 103246.76
}
}2.3.2 相同位置多次轨迹重叠
轨迹AB进行分析,两条轨迹可识别出有1圈重合。
轨迹AC进行分析,两条轨迹可识别出有2圈重合。

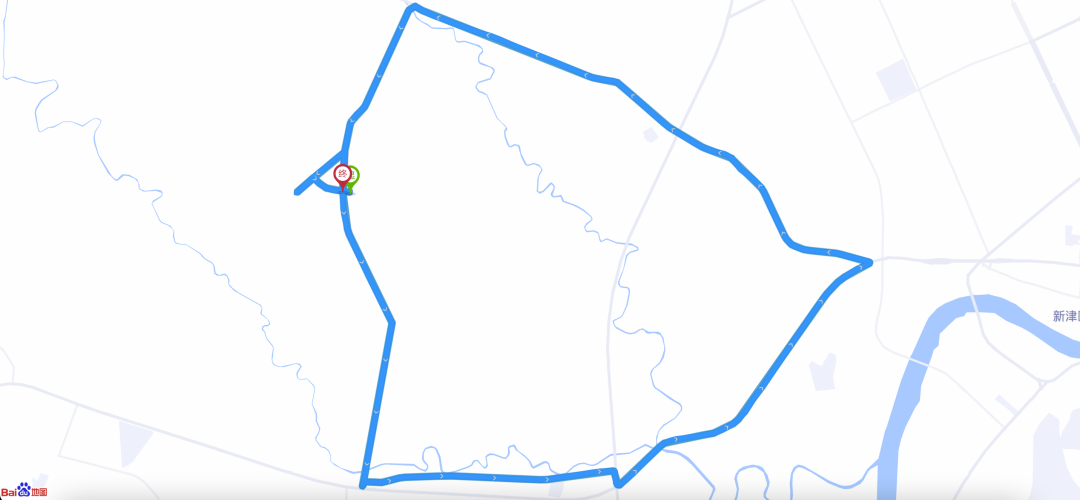
2.3.3 位置相同,方向相反
在相同路线上,以相反方向行驶产生的两条真实轨迹,整体仅有14%的重合率(起点区域是重合的)。
逆时针
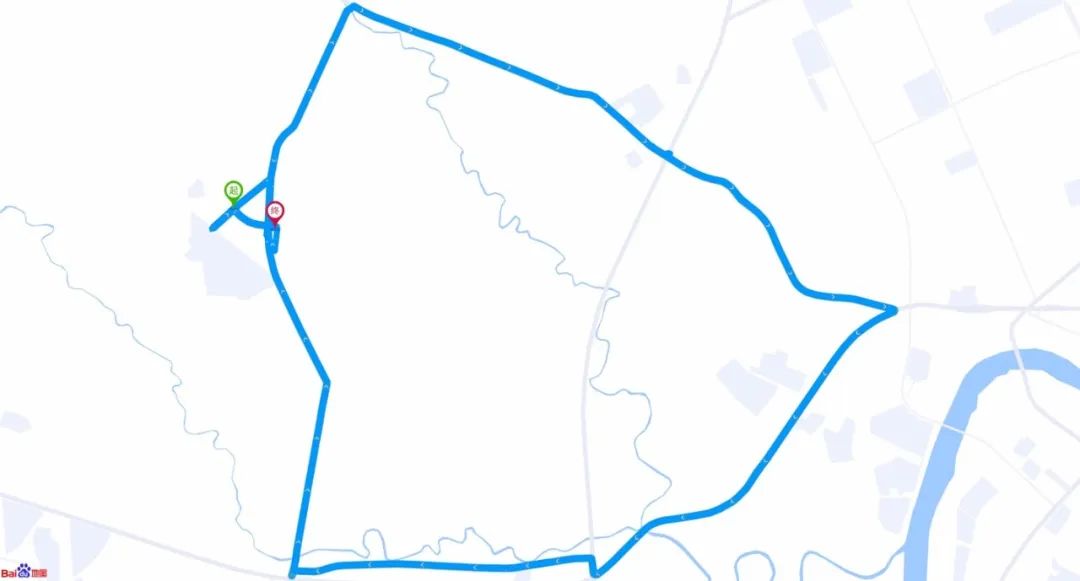
顺时针
重合率分析响应:
{
"status": 0,
"message": "OK",
"data": {
"similarity": 14.08, // 整体重合率
"standard_track_distance": 19038.64, // 逆时针轨迹总长
"track_distance": 22015.05, // 顺时针轨迹总长
"unmatched_distance": 19378.15,
"matched_distance": 2636.89, // 顺时针轨迹中重合长度
"standard_match_ratio": 16.51,
"standard_matched_distance": 3144.75 // 逆时针轨迹中重合长度
}
}2.3.4 起终点位置不同,行驶轨迹相同
相同轨迹序列,将起点处部分轨迹挪到终点后(调整起点位置),整体重合率为99.46%(轨迹非闭合,缺口位置识别为不重合)。
原始轨迹

变换起点位置后
重合率分析结果(部分):
{
"status": 0,
"message": "OK",
"data": {
"similarity": 99.46, // 整体重合率
"standard_track_distance": 19038.64,
"track_distance": 18985.78,
"unmatched_distance": 75.46,
"matched_distance": 18910.31,
"standard_match_ratio": 99.32,
"standard_matched_distance": 18910.31
}
}03 使用体验提升
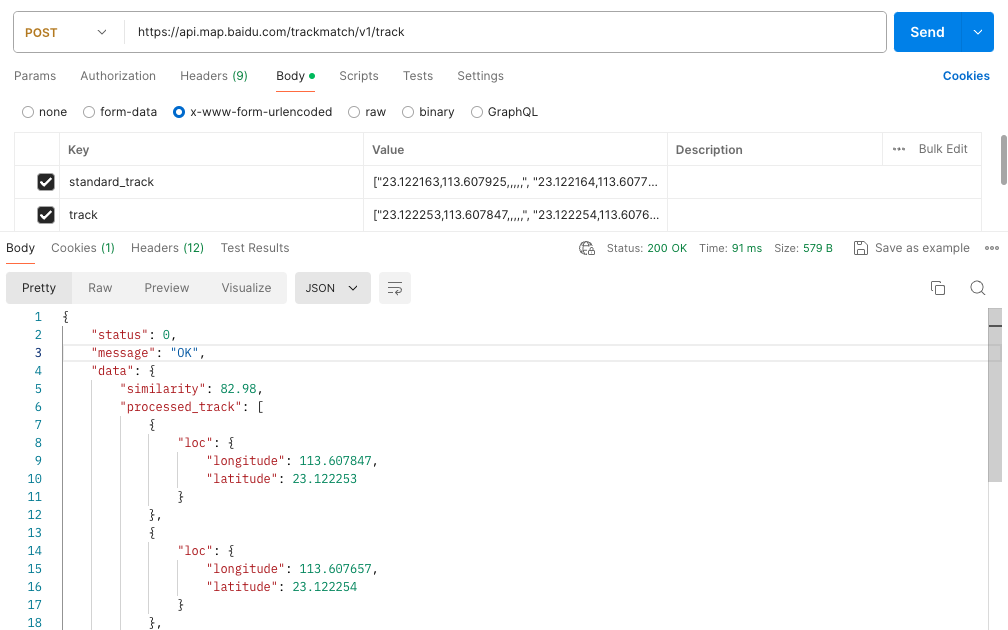
轨迹重合率分析是一类Web API接口服务,开发者可以从官网接口文档直接获取多语言版本的请求demo。
优化后的API极大降低了使用难度,开发者仅需填充standard_track(基准轨迹)和track(待匹配轨迹)两个参数即可开始分析。
分析不再依赖时间戳,除经纬度外的其他字段均缺省时,仍能保证分析准确。
04 效果展示
回到最开始的问题,对于危化品运输行业和网约车行业遇到的实际问题,重合率分析服务有怎样的表现呢?
4.1 危化品运输
基准路线:全长397km,轨迹点35244个
待分析轨迹:全长393km,轨迹点32202个
详细结果如下,经过分析,该车辆有25.1km的行程偏离预定路线(unmatched_distance)。
重合率分析结果(部分):
{
"status": 0,
"message": "OK",
"data": {
"similarity": 93.09, // 综合重合率
"standard_track_distance": 397258.78, // 基准轨迹长度
"track_distance": 393006.23, // 待分析轨迹长度
"unmatched_distance": 25144.21, // 待分析轨迹中偏离基准轨迹长度
"matched_distance": 367862.01,
"standard_match_ratio": 92.6, // 基准轨迹中可以匹配上的长度占总长的比例
"standard_matched_distance": 367865.2 // 基准轨迹中可以与待分析轨迹重合的长度
}
}
基准轨迹不匹配的轨迹逐点标识,可以粗略看出存在两个部分
4.2 网约车行业(顺风车拼单)
顺风车拼单可以拆解为以下3个步骤:
(1)发现拼单机会:计算多条路线间的重合率,选出重合率最高的组合。
(2)得到拼单轨迹:使用路线规划服务对重合率最高的组合重新算路。
(3)评估拼单影响:计算拼单轨迹与原始轨迹重合率。

具体分析过程如下:
(1)将候选集合中的3条轨迹分别计算整体重合率(similarity),重合率最高的组合“轨迹1&2”拼单机会最高。
轨迹 1&2 重合率(部分):
{
"status": 0,
"message": "OK",
"data": {
"similarity": 43.13 // 整体重合率
}
}轨迹 1&3 重合率(部分):
{
"status": 0,
"message": "OK",
"data": {
"similarity": 15.27 // 整体重合率
}
}轨迹 2&3 重合率(部分):
{
"status": 0,
"message": "OK",
"data": {
"similarity": 13.73 // 整体重合率
}
}(2)将轨迹2的起终点作为轨迹1的途径点重新算路,得到拼单轨迹。
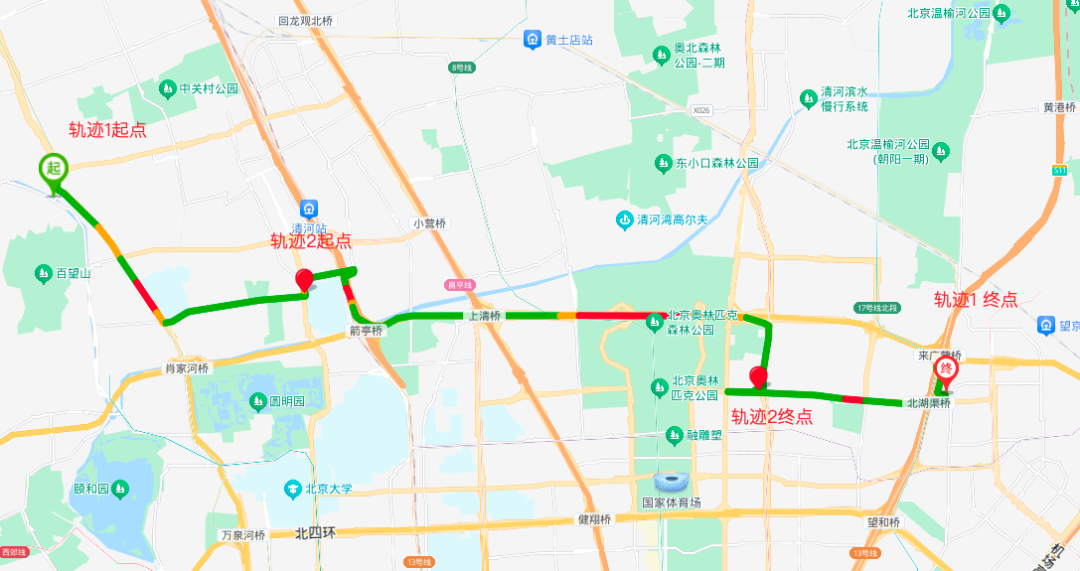
轨迹1送客途中接上轨迹2的乘客
(3)以原始轨迹为基准,将拼单后轨迹分别与原始轨迹计算重合率,可以得出:
1)拼单对轨迹2的乘客几乎没有影响(基准轨迹重合率100%)。
2)对轨迹1的乘客路线影响相对较大(基准轨迹重合率55%),但成本增加不大(距离增加1.3km)。
轨迹 1& 拼单后轨迹重合率(部分):
{
"status": 0,
"message": "OK",
"data": {
"standard_track_distance": 23092.86, // 轨迹1距离(米)
"track_distance": 24440.58, // 拼单后轨迹距离(米)
"standard_match_ratio": 55.41, // 基准轨迹重合率
}
}轨迹 2& 拼单后轨迹重合率(部分):
{
"status": 0,
"message": "OK",
"data": {
"standard_track_distance": 11981.52, // 轨迹2距离(米)
"track_distance": 24440.58, // 拼单后轨迹距离(米)
"standard_match_ratio": 100.0, // 基准轨迹重合率
}
}新版轨迹重合率分析API,以其强大的性能和广泛的应用场景,无疑将为开发者带来更加便捷、高效的位置服务体验。
新版本将于9月底在官网发布,敬请期待!
![]()
·END·
你还想了解哪些技术内容?
快来评论区留言告诉我们吧!




![[点云处理] cloud compare二次插件功能开发(三)CC插件总结与加速开发](https://img-blog.csdnimg.cn/img_convert/eb0d2849d0b92c7e744e3d7d2bdf29bb.png)