大模型专栏介绍
😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文为大模型专栏子篇,大模型专栏将持续更新,主要讲解大模型从入门到实战打怪升级。如有兴趣,欢迎您的阅读。
💡适合人群:本科生、研究生、大模型爱好者,期待与你一同探索、学习、进步,一起卷起来叭!
🔗篇章一:本篇主要讲解Python基础、数据分析三件套、机器学习、深度学习、CUDA等基础知识、学习使用AutoDL炼丹
🔗篇章二:本篇主要讲解基本的科研知识、认识数据和显卡、语言模型如RNN、LSTM、Attention、Transformer、Bert、T5、GPT、BLOOM、LLama、Baichuan、ChatGLM等系列、强化学习教程、大模型基础知识及微调等
🔗篇章三:本篇主要讲解智能对话、大模型基础实战如Ollama、Agent、QLoar、Deepspeed、RAG、Mobile Agent等、大模型领域前沿论文总结及创新点汇总
目录
- CUDA
- 炼丹
CUDA
CUDA:CUDA中线程也可以分成三个层次:线程、线程块和线程网络。
- 线程(Thread):CUDA中基本执行单元,由硬件支持、开销很小,每个线程执行相同代码;
- 线程块(Block):若干线程的分组,Block内一个块至多512个线程、或1024个线程(根据不同的GPU规格),线程块可以是一维、二维或者三维的;
- 线程网络(Grid):若干线程块Block的网格,Grid是一维和二维的。
GPU有很多线程,在CUDA里被称为Thread,同时我们会把一组Thread归为一个Block,而Block又会被组织成一个Grid。

SM(StreamingMultiprocessor):GPU上有很多计算核心也就是SM,SM是一块硬件,包含了固定数量的运算单元,寄存器和缓存。在具体的硬件执行中,一个SM会同时执行一组线程,在CUDA里叫warp,直接可以理解这组硬件线程warp会在这个SM上同时执行一部分指令,这一组的数量一般为32或者64个线程。一个Block会被绑定到一个SM上,即使这个Block内部可能有1024个线程,但这些线程组会被相应的调度器来进行调度,在逻辑层面上我们可以认为1024个线程同时执行,但实际上在硬件上是一组线程同时执行,这一点其实就和操作系统的线程调度一样。意思就是假如一个SM同时能执行64个线程,但一个Block有1024个线程,那这1024个线程是分1024/64=16次执行。
GPU在管理线程的时候是以block为单元调度到SM上执行。每个block中以warp(一般32个线程或64线程)作为一次执行的单位(真正的同时执行)。
- 一个GPU包含多个SM,而每个SM又包含多个Core,SM支持并发执行多达几百的Thread。
- 一个Block只能调度到一个SM上运行,直到ThreadBlock运行完毕。一个SM可以同时运行多个Block(因为有多个Core)。
- 写CUDAkernel的时候,跟SM对应的概念是Block,每一个Block会被调度到某个SM执行,一个SM可以执行多个block。CUDA程序就是很多的Blocks均匀的喂给若干SM来调度执行。
再看一张图,加深一下理解,CUDA软件和硬件结构:

规格参数:不同的GPU规格参数不一样,执行参数不同,比如Fermi架构:
- 每一个SM上最多同时执行8个Block。(不管Block大小)
- 每一个SM上最多同时执行48个warp。
- 每一个SM上最多同时执行48*32=1536个线程。
内存:一个Block会绑定在一个SM上,同时一个Block内的Thread是共享一块ShareMemory(一般就是SM的一级缓存,越靠近SM的内存就越快)。GPU和CPU也一样有着多级Cache还有寄存器的架构,把全局内存的数据加载到共享内存上再去处理可以有效的加速。

CPU&GPU训练时间对比,直观感受一下差距:
- 模型:BERT-base
- 训练数据集:180000
- batch_size:32
- CPU(Xeon®Gold51182CPU24Core):40:30:00
- CPU(Xeon®Platinum8255C1CPU40Core):16:25:00
- GPU(P40):3:00:00
- GPU(V100):1:17:00
GPU并行方式:
- 数据并行(DataParallelism):在不同的GPU上运行同一批数据的不同子集;
- 流水并行(PipelineParallelism):在不同的GPU上运行模型的不同层;
- 张量并行(TensorParallelism):将单个数学运算(如矩阵乘法)拆分到不同的GPU上运行;
- 混合专家系统(Mixture-of-Experts):只用模型每一层中的一小部分来处理数据。

数据并行:
将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播,相当于加大了batch_size。
每个GPU都加载模型参数,被称为“工作节点(workers)”,为每个GPU分配分配不同的数据子集同时进行处理,分别求解梯度,然后求解所有节点的平均梯度,每个节点各自进行反向传播。
各节点的同步更新策略:
①单独计算每个节点上的梯度;
②计算节点之间的平均梯度(阻塞,涉及大量数据传输,影响训练速度);
③单独计算每个节点相同的新参数。
Pytorch对于数据并行有很好的支持,数据并行也是最常用的GPU并行加速方法之一。
模型分层:
将模型按层分割,不同的层被分发到不同的GPU上运行。每个GPU上只有部分参数,因此每个部分的模型消耗GPU的显存成比例减少,常用于GPU显存不够,无法将一整个模型放在GPU上。

layer的输入和输出之间存在顺序依赖关系,因此在一个GPU等待其前一个GPU的输出作为其输入时,朴素的实现会导致出现大量空闲时间。这些空闲时间被称作“气泡”,而在这些等待的过程中,空闲的机器本可以继续进行计算。
张量并行:
如果在一个layer内“水平”拆分数据,这就是张量并行。许多现代模型(如Transformer)的计算瓶颈是将激活值与权重相乘。
矩阵乘法可以看作是若干对行和列的点积:可以在不同的GPU上计算独立的点积,也可以在不同的GPU上计算每个点积的一部分,然后相加得到结果。
无论采用哪种策略,都可以将权重矩阵切分为大小均匀的“shards”,不同的GPU负责不同的部分,要得到完整矩阵的结果,需要进行通信将不同部分的结果进行整合。
混合专家系统:
混合专家系统(MoE)是指,对于任意输入只用一小部分网络用于计算其输出。在拥有多组权重的情况下,网络可以在推理时通过门控机制选择要使用的一组权重,这可以在不增加计算成本的情况下获得更多参数。
每组权重都被称为“专家(experts)”,理想情况是,网络能够学会为每个专家分配专门的计算任务。不同的专家可以托管在不同的GPU上,这也为扩大模型使用的GPU数量提供了一种明确的方法。

Pytorch DDP:
- 在DDP模式下,会有N个进程被启动(一般N=GPU数量),
每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。 - 在模型训练时,
各个进程通过Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度; - 各个进程
用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
Ring all-reduce 算法:
定义 GPU 集群的拓扑结构:
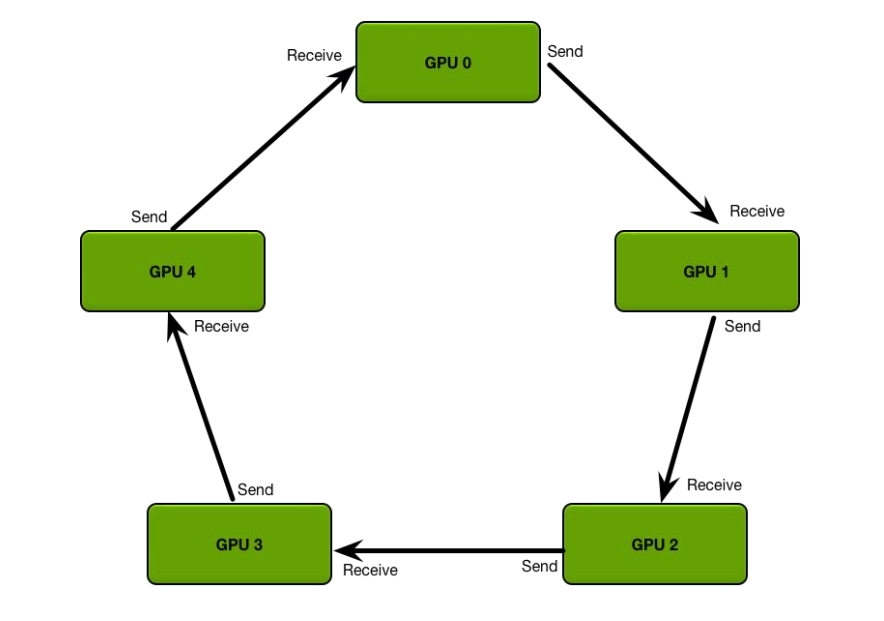
每个 GPU 只从左邻居接受数据、并发送数据给右邻居。
算法主要分两步:(举例:数组求和)
- scatter-reduce:会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分。
- allgather:GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度
Step1:将数组在每个GPU上都分块

Step2:N-1轮的scatter-reduce,每一轮中,每个GPU将自己的一个chunk发给右邻居,并接收左邻居发来的chunk,并累加。


Allgather:和scatter-reduce操作类似,只不过将每个chunk里面的操作由累加值变为替换。



在上面的过程中,N个GPU中的每一个将分别发送和接收N-1次scatter reduce值和N-1次all gather的值。每次,GPU将发送K/N个值,其中K是在不同GPU之间求和的数组中值的总数。
因此,往返每个GPU的数据传输总量为

由于所有传输都是同步发生的,因此减少的速度受到环中相邻GPU之间最慢(最低带宽)连接的限制。如果为每个GPU选择了正确的邻居,则该算法是带宽最佳的,并且是减少带宽的最快算法(假设与带宽相比,延迟成本可以忽略不计)。
通常,如果一个节点上的所有GPU在环中彼此相邻,则该算法的效果最佳。这样可以最大程度地减少网络争用的数量,否则可能会大大降低GPU-GPU连接的有效带宽。
炼丹
🔗购卡攻略:AutoDL

根据合适的任务选择GPU,以大模型训练为例:
| 任务类型 | 推荐GPU | 备注 |
|---|---|---|
| BERT训练 | RTX3090/RTX3080/RTX2080TI | 可以选择便宜的2080 |
| ⼤模型LoRA微调 | V100 32GB/V100 SXM2 32GB | V100 32GB 起步 |
| ⼤模型FT微调 | A100 40GB PCIE /A100 SXM 80GB | A100 40GB PCIE 起步 |
注意,SXM2/SXM4版本的GPU使⽤NVLINK,多卡性能优于PCIE版本。
GPU性能对⽐⽹址:🔗https://topcpu.net/cpu-c
注意,默认提供50GB硬盘,选择GPU⼀定选择可以扩容更多硬盘的服务器,不同任务的硬盘需求:
| 任务类型 | 推荐拓展硬盘 | 备注 |
|---|---|---|
| BERT训练 | 不需要拓展 | |
| ⼤模型LoRA微调 | 150GB及以上(理想300GB) | 500GB以内即可 |
| ⼤模型FT微调 | 300GB及以上(理想500GB) | 多多益善,不设限 |


选定后选择拓展硬盘、镜像:

配置SSH密钥登录,将⾃⼰电脑的ssh公钥复制到⾥⾯,配置ssh后,所有云服务器可以⽆密登录::

打开cmd终端,输入命令生成公私钥对:
ssh-keygen
我这里之前创建过:


打开git bash,执行cat命令:

添加SSH公钥:

将ssh命令复制到命令行中:

配置服务器网盘:


将模型下载到服务器中:

长时间关注显然使用情况命令:
watch -n -1 nvidia-smi

配置中文编码,防止中文乱码:
vim /etc/profile
#LANG=en_US.UTF-8
#LANGUAGE=en_US:en
#LC_ALL=en_US.UTF-8
export LANG=zh_CN.UTF-8
PATH=/root/miniconda3/bin:/usr/local/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
source /etc/profile
HuggingFace缓存配置:
如果不进⾏HuggingFace缓存配置,在⼤模型加载过程中的临时数据就会存放到系统盘,系统盘只有
25GB,会导致训练过程OOM。
mkdir /root/autodl-tmp/artboy && mkdir /root/autodl-tmp/tmp
vim ~/.bashrc
# enable programmable completion features (you don't need to enable
# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
# sources /etc/bash.bashrc).
#if [ -f /etc/bash_completion ] && ! shopt -oq posix; then
# . /etc/bash_completion
#fi
export HF_HOME=/root/autodl-tmp/artboy/.cache
export TEMP=/root/autodl-tmp/tmp
source /etc/profile
source /etc/autodl-motd
source ~/.bashrc
创建常用目录:
cd /root/autodl-tmp/artboy
mkdir finetune_code && mkdir data && mkdir base_model
ls
# 移动代码
cd finetune_code
mv ~/autodl-tmp/BertClassifier/ .
ls
配置虚拟环境:
conda create -n bert_env python=3.8.5
source activate bert_env
cd BertClassifier
bash install_req.sh
# cat install_req.sh
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# pip list
Package Version
------------------------ ----------
certifi 2024.6.2
charset-normalizer 3.3.2
cmake 3.29.3
filelock 3.14.0
fsspec 2024.6.0
huggingface-hub 0.23.3
idna 3.7
Jinja2 3.1.4
joblib 1.4.2
lit 18.1.6
MarkupSafe 2.1.5
mpmath 1.3.0
networkx 3.1
numpy 1.24.4
nvidia-cublas-cu11 11.10.3.66
nvidia-cuda-cupti-cu11 11.7.101
nvidia-cuda-nvrtc-cu11 11.7.99
nvidia-cuda-runtime-cu11 11.7.99
nvidia-cudnn-cu11 8.5.0.96
nvidia-cufft-cu11 10.9.0.58
nvidia-curand-cu11 10.2.10.91
nvidia-cusolver-cu11 11.4.0.1
nvidia-cusparse-cu11 11.7.4.91
nvidia-nccl-cu11 2.14.3
nvidia-nvtx-cu11 11.7.91
packaging 24.0
pip 24.0
PyYAML 6.0.1
regex 2024.5.15
requests 2.32.3
safetensors 0.4.3
scikit-learn 1.3.2
scipy 1.10.1
setuptools 69.5.1
sympy 1.12.1
threadpoolctl 3.5.0
tokenizers 0.19.1
torch 2.0.0
tqdm 4.66.4
transformers 4.41.2
triton 2.0.0
typing_extensions 4.12.1
urllib3 2.2.1
wheel 0.43.0
模型训练:
nohup bash multi_gpu.sh > 20240605_1800.log &
tail -f 20240605_1800.log
loading data from: data/cnew.train_debug.txt
100%|██████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 167.75it/s]
loading data from: data/cnew.val_debug.txt
100%|████████████████████████████████████████████████████████████| 500/500 [00:03<00:00, 129.41it/s]
Epoch 1 train: 11%|███▏ | 27/250 [00:41<05:41, 1.53s/it, acc=0, loss=2.08]
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2024.9.11
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!