目录
- 介绍
- PVT原理
- PVT的核心思想和结构
- PVT模块结构
- 体素分支
- 点分支
- 代码实现

- 论文题目:PVT: Point-Voxel Transformer for Point Cloud Learning
- 发布期刊:International Journal of Intelligent Systems
- 通讯地址:杭州电子科技大学&伦敦大学学院
- 代码地址:https://github.com/HaochengWan/PVT
介绍
这篇论文的主要内容是提出了一种新的点云学习架构,名为点体素变换器(Point-Voxel Transformer, PVT)。PVT结合了基于点的方法和基于体素的方法的优点,通过引入稀疏窗口注意力(Sparse Window Attention, SWA)模块,能够高效地从3D数据中捕获有用的特征。
论文的主要贡献包括:
- 提出PVT架构:这是第一个将基于点和基于体素的网络优势深度结合的Transformer方法。
- 引入稀疏窗口注意力(SWA)模块:该模块实现了与输入体素分辨率线性相关的计算复杂度,同时避开了空体素的无效计算。
- 实验验证了PVT的有效性:在多种点云学习任务(如分类和语义分割)上,PVT显示出了竞争力,并实现了相较于其他基于变换器模型10倍的推理速度提升。
PVT原理
Point-Voxel Transformer (PVT) 是一种用于点云学习的新型神经网络架构。它结合了基于点(point-based)和基于体素(voxel-based)的方法的优点,旨在提高点云数据处理的效率和性能。
PVT的核心思想和结构
-
结合点和体素的优势:
- 基于点的方法:直接在点云数据上进行操作,可以保留每个点的精确位置和细节信息,但是计算代价较高,尤其是在处理大规模点云数据时。
- 基于体素的方法:通过将点云数据转换为规则的三维网格(体素),使用3D卷积神经网络进行特征提取。这种方法计算效率高,但在体素化过程中会丢失细粒度的位置信息。
PVT 通过融合这两种方法的优势,既保持了高效的计算性能,又保留了点云的精确位置信息。
-
稀疏窗口注意力模块(Sparse Window Attention, SWA):
- PVT引入了一个新的模块——稀疏窗口注意力(SWA),它能够在非空体素内局部聚合特征,避免了对空体素的无效计算,从而降低了计算复杂度。SWA的计算复杂度与体素分辨率线性相关,而不是传统方法的平方复杂度。
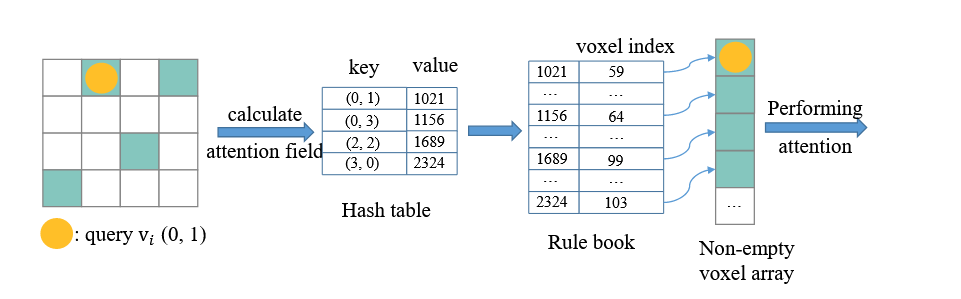
- PVT引入了一个新的模块——稀疏窗口注意力(SWA),它能够在非空体素内局部聚合特征,避免了对空体素的无效计算,从而降低了计算复杂度。SWA的计算复杂度与体素分辨率线性相关,而不是传统方法的平方复杂度。
- 双分支架构:
- 体素分支(Voxel Branch):负责从体素空间中聚合局部特征。体素分支使用SWA模块在体素网格内进行局部注意力计算,从而高效地提取局部特征。
- 点分支(Point Branch):直接在点云数据上执行自注意力(self-attention)计算,捕获全局特征。该分支使用了两种不同的自注意力变体来处理不同尺度的点云数据:一种是相对注意力(Relative Attention, RA),用于小规模点云;另一种是外部注意力(External Attention, EA),用于大规模点云。
PVT模块结构
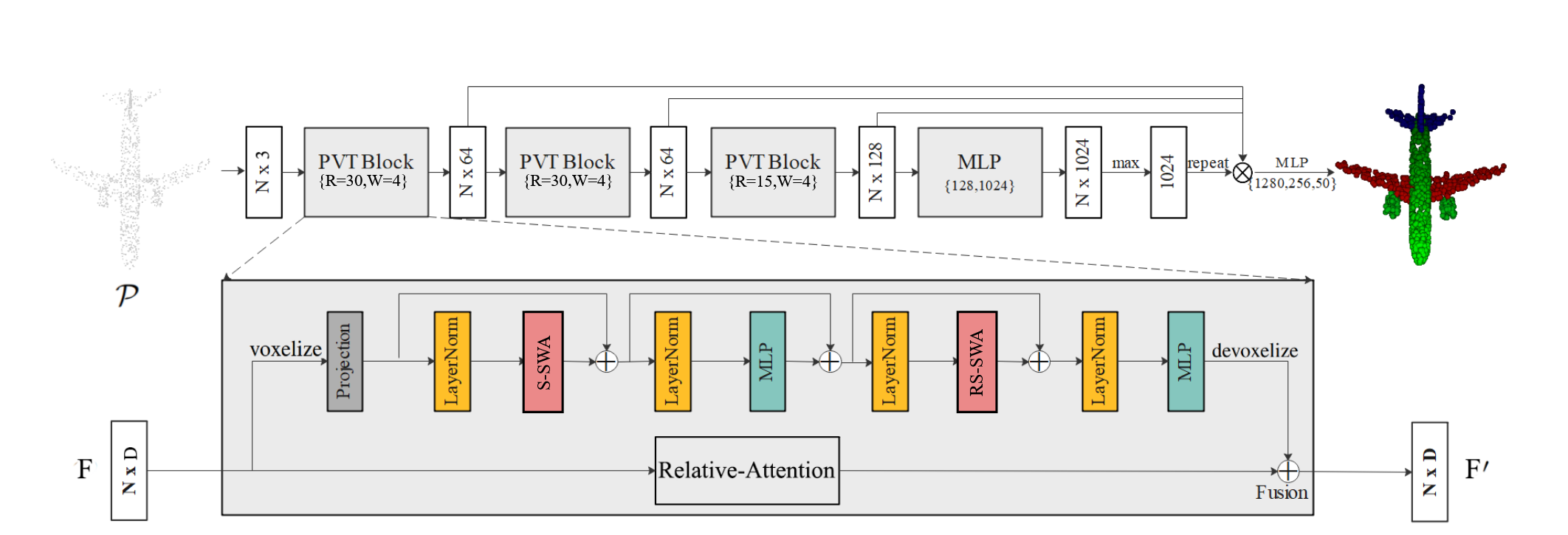
- 输入点云数据:将原始点云数据输入网络。
- 体素分支处理:
- 将点云数据体素化,形成稀疏体素结构。
- 使用稀疏窗口注意力(SWA)在局部体素窗口中计算局部特征。
- 应用循环窗口机制以增强跨窗口的信息交互。
- 将体素特征解体素化,映射回点空间。
- 点分支处理:
- 根据点云数据规模,使用相对注意力(RA)或外部注意力(EA)计算全局特征。
- 特征融合:
- 将体素分支的局部特征和点分支的全局特征相加,得到融合的特征表示。
- 输出:根据任务(如点云分类或语义分割)生成最终的结果。
体素分支
- 目的:用于提取点云数据的局部特征。
- 体素化(Voxelization):
- 将点云数据 PPP 转换为规则的三维网格或体素格式。每个体素包含一个或多个点,并生成一个稀疏体素结构表示。
- 稀疏窗口注意力模块(Sparse Window Attention, SWA):
- PVT引入了一个新的模块——稀疏窗口注意力(SWA),它能够在非空体素内局部聚合特征,避免了对空体素的无效计算,从而降低了计算复杂度。SWA的计算复杂度与体素分辨率线性相关,而不是传统方法的平方复杂度。
- 循环窗口机制(Shifted Window Mechanism):
- 使用循环窗口方法跨窗口聚合信息,这样能够在多个非重叠窗口之间进行信息交换,进一步提高特征提取的有效性和模型的感受野。
- 解体素化(Devoxelization):
- 将聚合后的体素特征映射回原始点云的特征空间,得到体素分支提取的局部特征。
点分支
- 目的:用于提取点云数据的全局特征。
- 相对注意力(Relative Attention, RA):
- 适用于小规模点云数据。通过在点云数据上直接计算自注意力,同时引入相对位置表示(Relative Position Representations, RPR),使得模型在处理刚性变换时具有更好的鲁棒性。
- 外部注意力(External Attention, EA):
- 适用于大规模点云数据。EA是一种线性注意力机制,通过使用两个小型可学习的共享存储单元,以避免平方复杂度(O(N^2)),使其更适合大规模点云数据的处理。
代码实现
下面是实现PVT模块的具体细节,详细可以参照github中的代码
class PVTConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, resolution, normalize=True, eps=0):
super().__init__()
# 初始化输入和输出通道、卷积核大小、分辨率、归一化参数
self.in_channels = in_channels # 输入特征的通道数
self.out_channels = out_channels # 输出特征的通道数
self.kernel_size = kernel_size # 卷积核大小
self.resolution = resolution # 体素分辨率
self.boxsize = 3 # 体素化窗口大小
self.mlp_dims = out_channels # MLP的输出维度
self.drop_path1 = 0.1 # Dropout路径1的比例
self.drop_path2 = 0.2 # Dropout路径2的比例
# 体素化模块,用于将点云数据转换为体素网格
self.voxelization = Voxelization(resolution, normalize=normalize, eps=eps)
# 体素编码器模块,用于编码体素化后的特征
self.voxel_encoder = VoxelEncoder(in_channels, out_channels, kernel_size, resolution, self.boxsize,
self.mlp_dims, self.drop_path1, self.drop_path2)
# 3D注意力模块,用于增强体素特征
self.SE = SE3d(out_channels)
# 共享变换器模块,用于在点特征中引入全局上下文信息
self.point_features = SharedTransformer(in_channels, out_channels)
def forward(self, inputs):
# 输入包括原始特征(features)和点的坐标(coords)
features, coords = inputs
# 将输入特征进行体素化,得到体素特征(voxel_features)和对应的体素坐标(voxel_coords)
voxel_features, voxel_coords = self.voxelization(features, coords)
# 对体素特征进行编码,通过体素编码器提取特征
voxel_features = self.voxel_encoder(voxel_features)
# 通过3D注意力模块增强体素特征
voxel_features = self.SE(voxel_features)
# 对体素特征进行反体素化操作,将其映射回点云特征空间
voxel_features = F.trilinear_devoxelize(voxel_features, voxel_coords, self.resolution, self.training)
# 计算相对位置,用于相对注意力计算
pos = coords.permute(0, 2, 1) # 将点的坐标从(B, N, 3)转换为(B, 3, N)的形状
rel_pos = pos[:, :, None, :] - pos[:, None, :, :] # 计算相对位置矩阵
rel_pos = rel_pos.sum(dim=-1) # 计算相对位置的总和
# 将体素特征和点特征融合,得到最终的融合特征
fused_features = voxel_features + self.point_features(features, rel_pos)
# 返回融合后的特征和原始点的坐标
return fused_features, coords