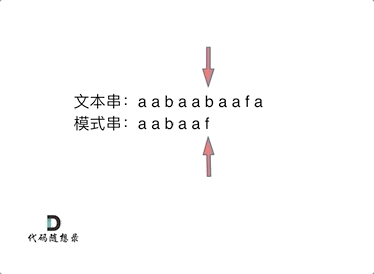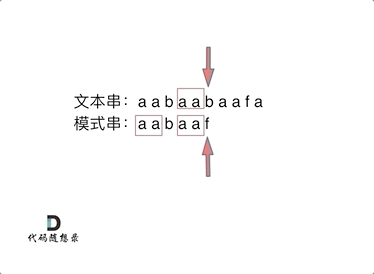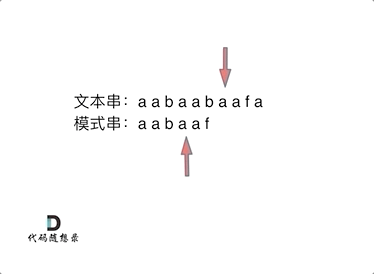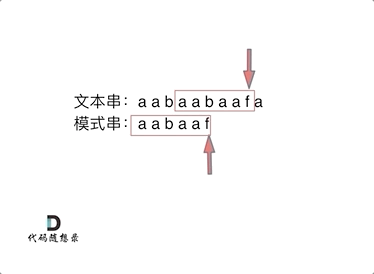
经常需要接触到各种各样的图像数据,为模型开发准备素材,在实际的项目中,一部分数据来源于真实的项目场景,但是这部分数据大都比较少,且获取的难度比较大,往往都是项目到了实施阶段的时候才有机会拿到数据,对于前期模型的开发构建来说很不友好,所以基本上前期介入的时候想要快速开发迭代模型,基本上都是需要从互联网上采集公开的数据素材才行的。

常见的几个搜索引擎都可以拿来给自己获取数据使用,比如:Google、Bing、Baidu、Sougou等等,根据自己的实际需要选择合适的即可。
这里简单以Google搜索引擎为例,看下实例实现:
import requests
from bs4 import BeautifulSoup
import re
def google_images_search(query):
# 构建Google Images搜索URL
query = query.replace(' ', '+')
url = f"https://www.google.com/search?q={query}&tbm=isch"
# 设置请求头以模拟浏览器行为
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
}
# 发送GET请求
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取图像URL
image_urls = []
for img in soup.find_all('img'):
img_url = img.get('src')
if img_url and img_url.startswith('http'):
image_urls.append(img_url)
return image_urls
else:
print(f"请求失败,状态码: {response.status_code}")
return []
# 输入关键词
keyword = input("请输入搜索关键词: ")
# 获取图像URL
image_urls = google_images_search(keyword)
# 打印图像URL
for i, url in enumerate(image_urls, 1):
print(f"图像 {i}: {url}")如果目标网站比较复杂的话,可以使用 selenium 进行更复杂的Web Scraping,如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
def google_images_search_selenium(query):
# 设置Chrome选项
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
options.add_argument('--disable-gpu')
# 初始化WebDriver
driver = webdriver.Chrome(options=options)
# 构建Google Images搜索URL
url = f"https://www.google.com/search?q={query}&tbm=isch"
# 打开网页
driver.get(url)
# 滚动页面以加载更多图像
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 提取图像URL
image_urls = []
images = driver.find_elements(By.CSS_SELECTOR, 'img.rg_i')
for img in images:
img_url = img.get_attribute('src')
if img_url and img_url.startswith('http'):
image_urls.append(img_url)
# 关闭WebDriver
driver.quit()
return image_urls
# 输入关键词
keyword = input("请输入搜索关键词: ")
# 获取图像URL
image_urls = google_images_search_selenium(keyword)
# 打印图像URL
for i, url in enumerate(image_urls, 1):
print(f"图像 {i}: {url}")上面代码的核心目的就是实现对于执行关键词进行检索,得到搜索结果对应图像的urls数据,接下来我们就需要遍历前面得到的urls集合来下载对应的图像数据。
python提供了很多好用的内置库和第三方库,能够帮助我们实现快捷便利的图像数据下载操作,当然了不是只能下载图像数据,这里因为我的目的是为了获取指定关键词下的图像数据,所以开发演示也都是以图像为例进行说明的。
方法1: 使用 urllib 模块
urllib 是Python标准库中用于处理URL的模块。
import urllib.request
data_url = "https://example.com/image.jpg"
save_path = "downloaded_image.jpg"
# 下载图像并保存到本地
urllib.request.urlretrieve(data_url, save_path)
print(f"图像已下载并保存为 {save_path}")方法2: 使用 requests 库
requests 是一个非常流行的第三方库,用于发送HTTP请求。
import requests
data_url = "https://example.com/image.jpg"
save_path = "downloaded_image.jpg"
# 发送GET请求下载图像
response = requests.get(data_url)
# 检查请求是否成功
if response.status_code == 200:
with open(save_path, 'wb') as file:
file.write(response.content)
print(f"图像已下载并保存为 {save_path}")
else:
print(f"下载失败,状态码: {response.status_code}")方法3: 使用 wget 库
wget 是一个第三方库,专门用于下载文件。
import wget
data_url = "https://example.com/image.jpg"
save_path = "downloaded_image.jpg"
# 下载图像并保存到本地
wget.download(data_url, out=save_path)
print(f"\n图像已下载并保存为 {save_path}")方法4: 使用 Pillow 库
Pillow 是一个强大的图像处理库,也可以用于下载和保存图像。
from PIL import Image
from io import BytesIO
import requests
data_url = "https://example.com/image.jpg"
save_path = "downloaded_image.jpg"
# 发送GET请求下载图像
response = requests.get(data_url)
# 检查请求是否成功
if response.status_code == 200:
# 使用Pillow打开图像
image = Image.open(BytesIO(response.content))
# 保存图像到本地
image.save(save_path)
print(f"图像已下载并保存为 {save_path}")
else:
print(f"下载失败,状态码: {response.status_code}")方法5: 使用 os 和 urllib 模块
这种方法结合了 os 模块来处理文件路径和 urllib 模块来下载图像。
import os
import urllib.request
data_url = "https://example.com/image.jpg"
save_path = os.path.join(os.getcwd(), "downloaded_image.jpg")
# 下载图像并保存到本地
urllib.request.urlretrieve(data_url, save_path)
print(f"图像已下载并保存为 {save_path}")方法6: 使用 asyncio 和 aiohttp 库
如果你需要异步下载图像,可以使用 asyncio 和 aiohttp 库。
import aiohttp
import asyncio
async def download_image(url, save_path):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
if response.status == 200:
with open(save_path, 'wb') as file:
while True:
chunk = await response.content.read(1024)
if not chunk:
break
file.write(chunk)
print(f"图像已下载并保存为 {save_path}")
else:
print(f"下载失败,状态码: {response.status}")
data_url = "https://example.com/image.jpg"
save_path = "downloaded_image.jpg"
# 运行异步任务
asyncio.run(download_image(data_url, save_path))上面几种方法都可以实现对目标链接图像数据的下载存储,当然了也不仅局限上面的几种方法,还有其他的方法就不再一一列举了,大家可以根据自己的实际需要,自由选择组合就可以很快的实现自己的数据采集器了。