目录
导包
特征工程
基本模型
超参数优化
导包
import pandas as pd
import numpy as np
import xgboost as xgb
import pickle
import sys
import matplotlib.pyplot as plt
from sklearn.metrics import make_scorer
from sklearn.metrics import mean_absolute_error
from sklearn.preprocessing import LabelEncoder, LabelBinarizer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold, train_test_split
from xgboost import XGBRegressor
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
%config InlineBackend.figure_format = 'retina'特征工程
# 测试集特征
train = pd.read_csv('allstate-claims-severity/train.csv')
train['log_loss'] = np.log(train['loss'])
features = [x for x in train.columns if x not in ['id','loss','log_loss']]
cat_features =[x for x in train.select_dtypes(include = ['object']) if x not in ['id','loss','log_loss']]
num_features =[x for x in train.select_dtypes(exclude = ['object']) if x not in ['id','loss','log_loss']]
print('训练集-离散特征Categorical: {} features'.format(len(cat_features)))
print('训练集-连续值特征Numerical:{} features'.format(len(num_features)))
# 得到训练集x和y
train_x = train[features]
train_y = train['log_loss']
# 离散特征单独处理成pandas的category类型
for c in range(len(cat_features)):
train_x[cat_features[c]] = train_x[cat_features[c]].astype('category').cat.codes
print('Xtrain:',train_x.shape) # Xtrain: (188318, 130)
print('ytrain:',train_y.shape) # ytrain: (188318,)
# 截止到这个位置,训练集已经可用
train_x
train_y基本模型
import pandas as pd
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息,以便输出更清晰
# 自定义评估函数,用于计算平均绝对误差(MAE)
def xg_eval_mae(yhat, dtrain):
y = dtrain.get_label()
# 对预测值和真实值进行指数变换,然后计算MAE
return 'mae', mean_absolute_error(np.exp(y), np.exp(yhat))
# 定义XGBoost回归模型类
class XGBoostRegressor(object):
def __init__(self, **kwargs):
# 初始化模型参数,包括用户自定义参数和默认参数
self.params = kwargs
self.params.update({
'verbosity': 0, # 设置日志等级
'objective': 'reg:squarederror', # 设置目标函数为平方误差
'seed': 0, # 设置随机种子
'num_boost_round': 100 # 设置boosting round的数量
})
self.bst = None # 初始化模型对象为None
def fit(self, x_train, y_train):
# 训练模型
dtrain = xgb.DMatrix(x_train, label=y_train)
try:
self.bst = xgb.train(
params=self.params, # 模型参数
dtrain=dtrain, # 训练数据
num_boost_round=self.params['num_boost_round'], # boosting round数量
feval=xg_eval_mae, # 自定义评估函数
maximize=False # 评估函数的最大化标志
)
except Exception as e:
print("Error during training:", e)
self.bst = None
def predict(self, x_pred):
# 预测函数
if self.bst is None:
raise ValueError("Model not trained. Call 'fit' before 'predict'.")
dpred = xgb.DMatrix(x_pred)
return self.bst.predict(dpred)
def kfold(self, x_train, y_train, nfold=5):
# 交叉验证函数
dtrain = xgb.DMatrix(x_train, label=y_train)
cv_results = xgb.cv(
params=self.params, # 模型参数
dtrain=dtrain, # 训练数据
num_boost_round=self.params['num_boost_round'], # boosting round数量
nfold=nfold, # 交叉验证的折数
feval=xg_eval_mae, # 自定义评估函数
maximize=False, # 评估函数的最大化标志
early_stopping_rounds=10, # 提前停止的轮数
metrics={'mae'} # 评估指标
)
return pd.DataFrame(cv_results)
def plot_feature_importances(self):
# 绘制特征重要性
if self.bst is None:
raise ValueError("Model not trained. Call 'fit' before plotting feature importances.")
feat_imp = pd.Series(self.bst.get_score(importance_type='weight')).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
plt.show()
def get_params(self, deep=True):
# 获取模型参数
return self.params
def set_params(self, **params):
# 设置模型参数
self.params.update(params)
return self
def save_model(self, filepath):
# 保存模型到本地文件
if self.bst is not None:
self.bst.save_model(filepath)
else:
raise ValueError("Model not trained. Call 'fit' before saving the model.")
# 特征工程
train = pd.read_csv('allstate-claims-severity/train.csv')
train['log_loss'] = np.log(train['loss']) # 对target进行对数变换
features = [x for x in train.columns if x not in ['id', 'loss', 'log_loss']] # 选择特征列
cat_features = [x for x in train.select_dtypes(include=['object']) if x not in ['id', 'loss', 'log_loss']] # 选择类别特征
num_features = [x for x in train.select_dtypes(exclude=['object']) if x not in ['id', 'loss', 'log_loss']] # 选择数值特征
print('训练集-离散特征Categorical: {} features'.format(len(cat_features)))
print('训练集-连续值特征Numerical: {} features'.format(len(num_features)))
train_x = train[features]
train_y = train['log_loss']
# 检查loss列是否为非负
if any(train['loss'] < 0):
raise ValueError("Column 'loss' must be non-negative for log transformation.")
# 离散特征单独处理成pandas的category类型
for c in range(len(cat_features)):
train_x[cat_features[c]] = train_x[cat_features[c]].astype('category').cat.codes
# 模型训练
bst = XGBoostRegressor(eta=0.1,
colsample_bytree=0.5,
subsample=0.5,
max_depth=5,
min_child_weight=3,
num_boost_round=100)
kfold_results = bst.kfold(train_x, train_y, nfold=5)
# 绘制MAE结果
kfold_results.mean(axis=1).plot(title='K-Fold MAE')
plt.xlabel('Boosting Round')
plt.ylabel('MAE')
plt.show()
# 再次训练模型
bst.fit(train_x, train_y)
# 保存模型到本地
model_filename = 'xgboost_model.json'
bst.save_model(model_filename)
test = pd.read_csv('allstate-claims-severity/test.csv')
test_x = test[features]
# 将类别数据的类别用数字替换
for c in range(len(cat_features)):
test_x[cat_features[c]] = test_x[cat_features[c]].astype('category').cat.codes
# 预测命令:
test_y = bst.predict(test_x)
# 保存预测结果
test['predicted_loss'] = np.exp(test_y)
test[['id', 'predicted_loss']].to_csv('submission.csv', index=False)bst.get_params()
在XGBoost中,这些超参数控制着模型的训练过程和行为。下面是每个超参数的含义:
eta(学习率):
-
- 控制每一步迭代中权重调整的幅度。较小的值意味着模型需要更多的迭代次数来训练,但可能会获得更好的性能和泛化能力。
colsample_bytree(每棵树的特征采样比率):
-
- 每棵树在训练时用到的特征数量的比例。值在0到1之间,用于随机特征选择,以增加模型的多样性并防止过拟合。
subsample(训练样本的采样比率):
-
- 训练每棵树时使用的样本比例。值在0到1之间,同样用于增加模型的多样性和防止过拟合。
max_depth(树的最大深度):
-
- 树的最大深度。树越深,模型越复杂,可能会有更好的性能,但也更容易过拟合。
min_child_weight(子节点最小权重):
-
- 决定最小数据权重和,需要在叶子节点上观察到进一步分裂。增加这个值可以防止模型学习到过于复杂的模式。
num_boost_round(提升轮数):
-
- 总共要执行的提升(boosting)轮数。更多的轮数可能会提高模型的性能,但也可能增加过拟合的风险。
verbosity(日志等级):
-
- 控制XGBoost打印的输出信息的详细程度。等级越高,打印的信息越少。
objective(目标函数):
-
- 指定学习任务和相应的学习目标或预测类型。在这个例子中,
'reg:squarederror'表示回归任务,使用平方误差作为损失函数。
- 指定学习任务和相应的学习目标或预测类型。在这个例子中,
seed(随机种子):
-
- 控制随机数生成器的种子。用于结果的可重复性。
这些超参数的合理设置对于模型的性能至关重要。通常,需要通过交叉验证等方法来调整这些参数,以找到最佳的模型配置。
{'eta': 0.1,
'colsample_bytree': 0.5,
'subsample': 0.5,
'max_depth': 5,
'min_child_weight': 3,
'num_boost_round': 100,
'verbosity': 0,
'objective': 'reg:squarederror',
'seed': 0}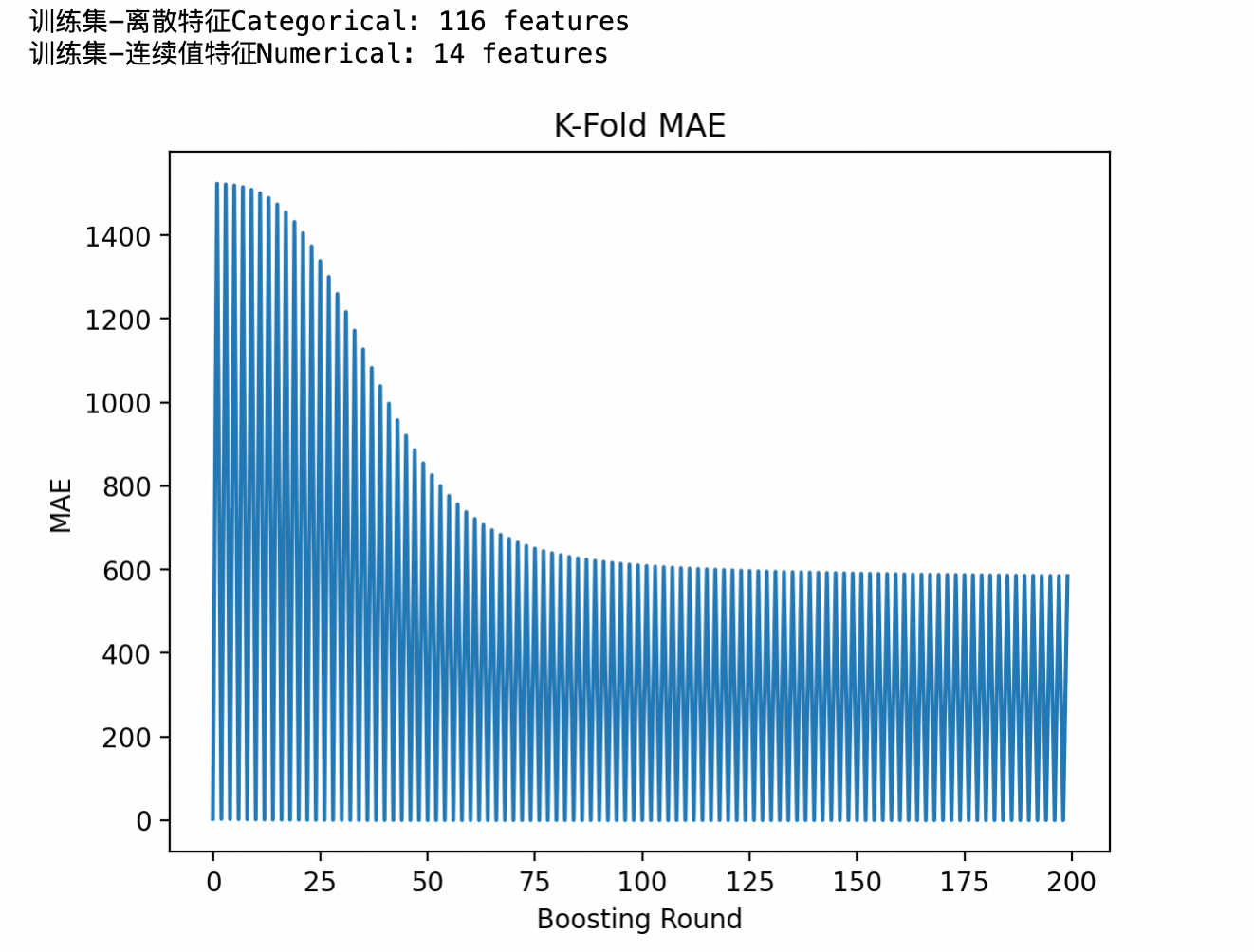
超参数优化
利用GridSearchCV算法,找出最合适的num_boost_round和学习率eta超参数
import pandas as pd
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import mean_absolute_error
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息,以便输出更清晰
# 读取数据并进行预处理
train = pd.read_csv('allstate-claims-severity/train.csv')
train['log_loss'] = np.log(train['loss']) # 对target进行对数变换
features = [x for x in train.columns
if x not in ['id', 'loss', 'log_loss']] # 选择特征列
cat_features = [
x for x in train.select_dtypes(include=['object'])
if x not in ['id', 'loss', 'log_loss']
] # 选择类别特征
for c in cat_features:
train[c] = train[c].astype('category').cat.codes # 将类别特征转换为数值
train_x = train[features]
train_y = train['log_loss']
# 划分训练集和验证集
x_train, x_val, y_train, y_val = train_test_split(train_x,
train_y,
test_size=0.2,
random_state=0)
# 设置XGBoost模型和参数网格
xgb_reg = xgb.XGBRegressor(colsample_bytree=0.5,
subsample=0.5,
max_depth=5,
min_child_weight=3,
objective='reg:squarederror',
seed=0)
# 设置GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300, 400, 500], # 尝试不同的num_boost_round值
'eta': [0.01, 0.05, 0.1, 0.2] # 尝试不同的学习率
}
grid_search = GridSearchCV(estimator=xgb_reg,
param_grid=param_grid,
scoring='neg_mean_absolute_error',
cv=3,
verbose=1)
grid_search.fit(x_train, y_train)
# 打印最佳参数和得分
print("Best parameters:", grid_search.best_params_)
print("Best MAE:", -grid_search.best_score_)
# 打印每个参数组合及其得分
results = grid_search.cv_results_
for mean_score, params in zip(results['mean_test_score'], results['params']):
print(np.sqrt(-mean_score), params) # 打印MAE而不是负MAE
# 使用最佳参数再次训练模型
best_params = grid_search.best_params_
best_xgb_reg = xgb.XGBRegressor(n_estimators=best_params['n_estimators'],
eta=best_params['eta'],
colsample_bytree=0.5,
subsample=0.5,
max_depth=5,
min_child_weight=3,
objective='reg:squarederror',
seed=0)
best_xgb_reg.fit(x_train, y_train)
# 预测验证集
predictions = best_xgb_reg.predict(x_val)
mae = mean_absolute_error(y_val, predictions)
print("Validation MAE:", mae)
# 绘制验证集的MAE结果
plt.figure()
plt.plot(predictions, label='Predictions')
plt.plot(y_val.values, label='True Values')
plt.legend()
plt.title('XGBoost Predictions vs True Values')
plt.xlabel('Sample Index')
plt.ylabel('Log Loss')
plt.show()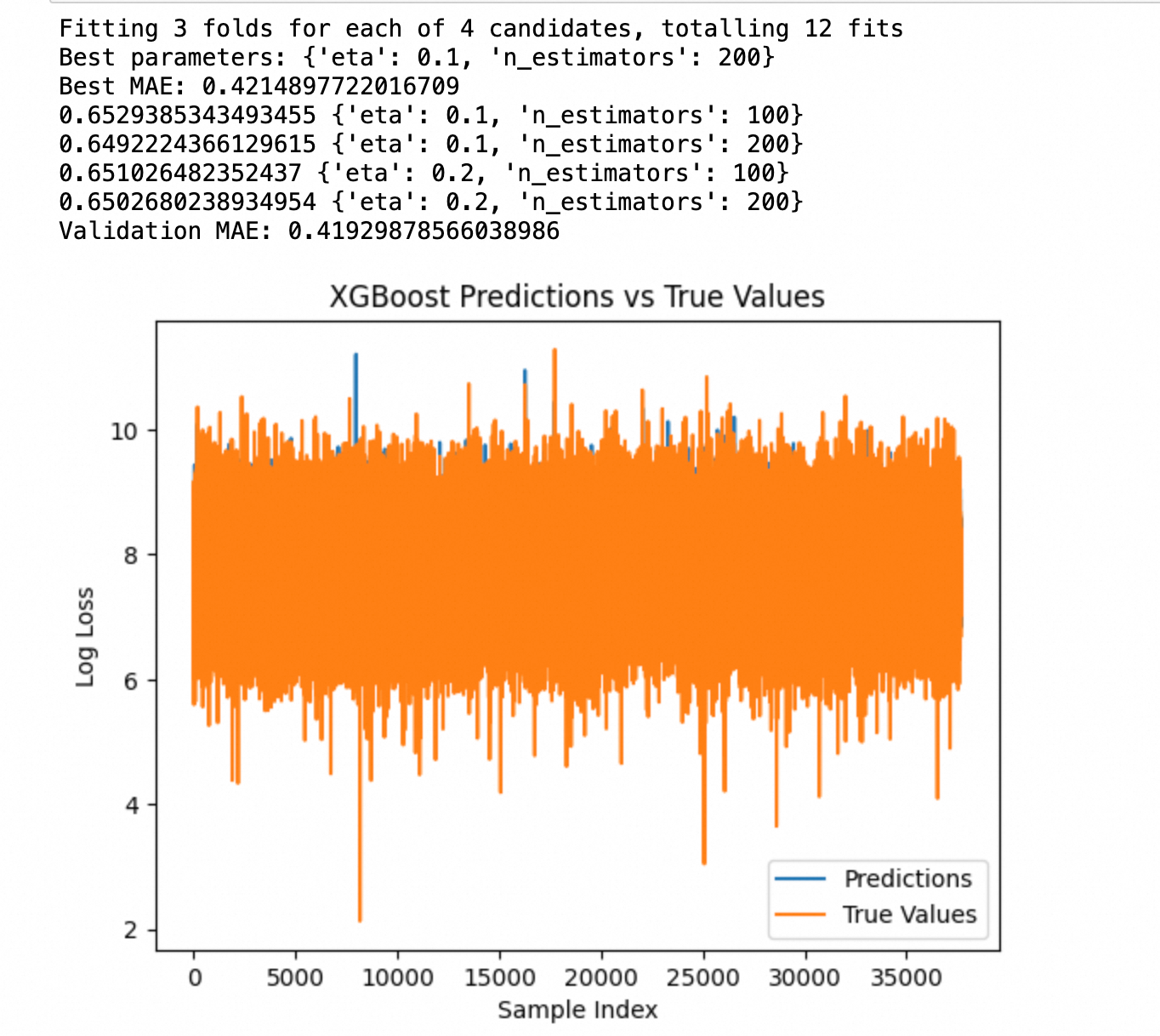
这段执行结果提供了通过GridSearchCV进行的模型超参数优化和验证的细节。以下是对这些输出的解释:
- 交叉验证过程:
-
- "Fitting 3 folds for each of 2 candidates, totalling 6 fits" 表示
GridSearchCV使用了3折交叉验证来评估两个不同的参数组合(在这个例子中是n_estimators的值)。总共进行了6次拟合(3折 x 2参数值)。
- "Fitting 3 folds for each of 2 candidates, totalling 6 fits" 表示
- 最佳参数和得分:
-
- "Best parameters: {'n_estimators': 200}" 表示在测试的参数组合中,当
n_estimators(即提升树的数量)设置为200时,模型的性能最佳。 - "Best MAE: 0.4214897722016709" 显示了使用最佳参数时的平均绝对误差(MAE)。这是在交叉验证过程中得到的最优结果。
- "Best parameters: {'n_estimators': 200}" 表示在测试的参数组合中,当
- 每个参数组合的得分:
-
- "0.6529385343493455 {'n_estimators': 100}" 和 "0.6492224366129615 {'n_estimators': 200}" 显示了每个参数组合的平均测试分数。这里显示的分数是负MAE,因为
GridSearchCV默认是寻找最小化的目标,所以使用负数表示。正值0.6529385343493455和0.6492224366129615实际上是MAE值,其中较小的值(对应n_estimators为200)表示更好的性能。
- "0.6529385343493455 {'n_estimators': 100}" 和 "0.6492224366129615 {'n_estimators': 200}" 显示了每个参数组合的平均测试分数。这里显示的分数是负MAE,因为
- 验证集上的MAE:
-
- "Validation MAE: 0.41929878566038986" 表示在独立的验证集上,使用最佳参数(
n_estimators=200)训练的模型的平均绝对误差。这个值用于最终评估模型在未知数据上的性能。
- "Validation MAE: 0.41929878566038986" 表示在独立的验证集上,使用最佳参数(
理解关键点:
- 较小的MAE值 表示模型预测与实际值之间的误差较小,即模型的预测性能较好。
- 交叉验证 是一种重要的技术,用于评估不同参数设置下模型的稳健性和泛化能力。
- GridSearchCV 提供了一个系统的方法来尝试多种参数组合,找到最优的模型配置。
在实际应用中,这些信息帮助我们理解模型在不同配置下的表现,并选择最佳的模型参数进行最终的模型部署和预测。



















