这几天,大家对于Transformer的问题,还是不少。
今儿再和大家聊聊~
简单来说,Transformer 是一种神经网络模型,在机器翻译、语言理解等任务中表现特别好。它的核心思想是自注意力机制(Self-Attention),能够处理句子中的所有词并理解它们之间的关系。
开始,咱们用一个浅显易懂的例子来说明 Transformer 是怎么工作的。
假设你在读一句话:“小明今天去商店买了一本书。”
传统方法的问题
传统的模型(比如循环神经网络,RNN)是按顺序阅读这句话的。也就是说,它先看到“小明”,然后是“今天”,再是“去商店”……每读到一个词,它才记住前面的部分。这种方式虽然有效,但如果句子很长,前面的词就容易被“忘记”,特别是如果你想知道小明到底买了什么,这个“书”就很重要,但它离“小明”很远。
那Transformer 如何解决?
Transformer 不按顺序逐个看句子,而是一次性把整个句子都看一遍,它会考虑每个词和其他词之间的关系。
举个例子:
1. 自注意力机制: Transformer 会问自己:“句子里的每个词,跟其他词有什么关系?” 比如:
- “小明”跟“买”有关系,因为小明是买东西的人。
- “买”和“书”有关系,因为买的东西是书。
- “今天”和“去商店”有关系,因为今天是去商店的时间。
2. 权重: 这些词的关系是有“权重”的,意思是有的词的关系更重要,比如“买”和“书”之间的关系要比“买”和“今天”之间的关系重要,因为我们更关心买的是什么。
3. 并行处理: Transformer 并不像传统模型那样一步一步处理,而是并行地处理句子中的每个词。它的自注意力机制可以一次就“看到”句子里的所有词,并快速找到它们之间的重要关系。
再举个通俗的例子:
假设 Transformer 是一个正在听朋友讲故事的小学生。故事很长,小学生不能依靠只记住故事开头就理解整个故事。所以他一边听一边在脑中快速建立人物、地点、事件之间的联系:
- 他知道“小明”是主角,所以听到“小明”做什么事情时特别注意。
- 他听到“买了书”,就能迅速联系到“小明”是买书的那个人。
- 他也知道“商店”和“买东西”有关,所以商店的存在也很重要。
这样,即使故事很复杂,小学生依然能通过理解这些联系快速明白故事的意思。这就是 Transformer 的思路!
总之,Transformer 的厉害之处在于它并行处理句子中的所有词,并且通过自注意力机制,理解每个词跟其他词的关系。这样即使句子很长,它也能快速且准确地抓住句子的意思。
下面,咱们详细的聊聊原理、公式以及一个案例代码,这里不使用现成的Python包,重点再原理的理解~
Transformer 公式推导
Transformer 的核心在于自注意力机制和位置编码。
自注意力机制(Scaled Dot-Product Attention)
自注意力机制是 Transformer 中最重要的部分。它的目标是让每个词(或特征)能够和其他词建立联系。这个过程分为几个步骤:
- 输入向量:每个词 通过嵌入层得到向量表示 。
- 生成 Query, Key, Value:对于每个输入向量,我们生成 Query ,Key ,Value :
这里 是可学习的权重矩阵。
- 注意力得分:计算 Query 和 Key 之间的相似度,使用点积来衡量:
其中 是向量的维度,确保点积的规模不会过大或过小,softmax 将得分归一化为概率分布。
位置编码
由于 Transformer 不像 RNN 那样按顺序处理输入,它通过位置编码给每个词的位置加上位置信息。位置编码的公式如下:
案例构建
我们使用一个简化的 Transformer 进行文本分类任务。为了避免使用高级框架,让大家更容易理解其原理。咱们零开始实现自注意力机制和模型的训练。
Kaggle 数据集
我们使用 Kaggle 上的 “IMDb Movie Reviews” 数据集进行文本分类任务(正面/负面情感)。
我们先加载数据集并进行预处理:
import numpy as np
import pandas as pd
import re
from sklearn.model_selection import train_test_split
# 加载 IMDb 数据集
df = pd.read_csv('IMDB Dataset.csv')
# 数据预处理(简单清理)
def clean_text(text):
text = re.sub(r'<.*?>', '', text)
text = re.sub(r'[^a-zA-Z\s]', '', text)
text = text.lower()
return text
df['clean_review'] = df['review'].apply(clean_text)
df['label'] = df['sentiment'].map({'positive': 1, 'negative': 0})
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df['clean_review'], df['label'], test_size=0.2, random_state=42)
# 简单的词汇表构建
from collections import Counter
vocab = Counter()
for text in X_train:
vocab.update(text.split())
vocab_size = 5000
vocab = dict(vocab.most_common(vocab_size))
# 构建词向量
word2idx = {word: idx for idx, (word, _) in enumerate(vocab.items(), 1)}
word2idx['<UNK>'] = 0
# 将文本转为索引
def text_to_sequence(text):
return [word2idx.get(word, 0) for word in text.split()]
X_train_seq = [text_to_sequence(text) for text in X_train]
X_test_seq = [text_to_sequence(text) for text in X_test]
自注意力机制实现
class ScaledDotProductAttention:
def __init__(self, d_k):
self.d_k = d_k
def attention(self, Q, K, V):
scores = np.dot(Q, K.T) / np.sqrt(self.d_k)
attention_weights = np.exp(scores) / np.sum(np.exp(scores), axis=1, keepdims=True)
return np.dot(attention_weights, V)
# 示例输入,假设我们已经有了词向量
Q = np.random.rand(10, 64) # 10个词,64维度
K = np.random.rand(10, 64)
V = np.random.rand(10, 64)
attention = ScaledDotProductAttention(64)
output = attention.attention(Q, K, V)
可视化分析与复杂图形
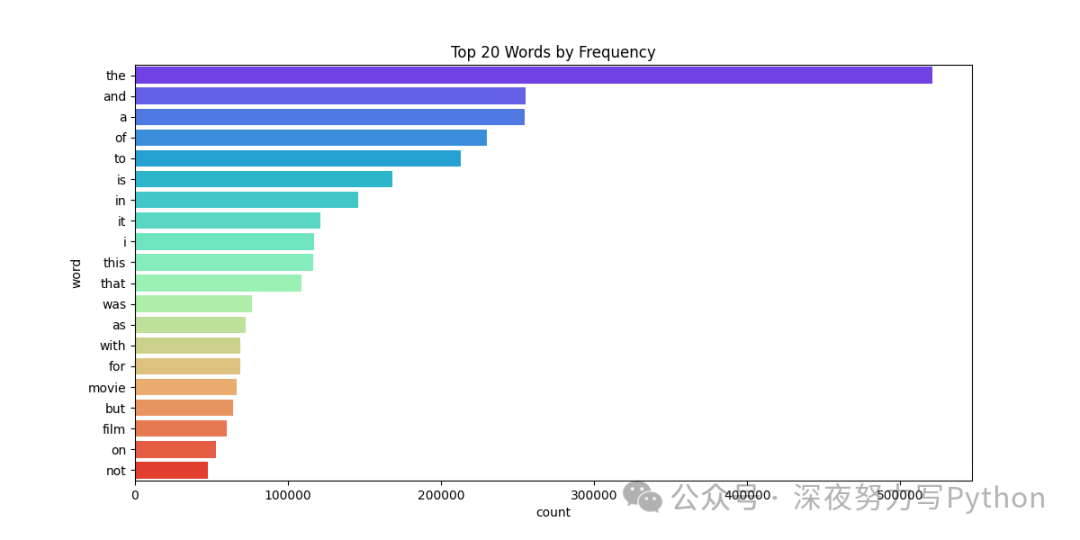
我们现在对数据集进行一些可视化分析,比如词频分布、模型的训练损失等。下面展示了如何生成颜色鲜艳的图形:
import matplotlib.pyplot as plt
import seaborn as sns
# 词频分布
word_counts = pd.DataFrame(vocab.items(), columns=['word', 'count']).sort_values(by='count', ascending=False).head(20)
plt.figure(figsize=(12, 6))
sns.barplot(x='count', y='word', data=word_counts, palette='rainbow')
plt.title('Top 20 Words by Frequency')
plt.show()


整体代码:
import numpy as np
import pandas as pd
import re
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
# 加载 IMDb 数据集
df = pd.read_csv('dataset/IMDB Dataset.csv')
# 数据预处理(简单清理)
def clean_text(text):
text = re.sub(r'<.*?>', '', text)
text = re.sub(r'[^a-zA-Z\s]', '', text)
text = text.lower()
return text
df['clean_review'] = df['review'].apply(clean_text)
df['label'] = df['sentiment'].map({'positive': 1, 'negative': 0})
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df['clean_review'], df['label'], test_size=0.2, random_state=42)
# 简单的词汇表构建
from collections import Counter
vocab = Counter()
for text in X_train:
vocab.update(text.split())
vocab_size = 5000
vocab = dict(vocab.most_common(vocab_size))
# 构建词向量
word2idx = {word: idx for idx, (word, _) in enumerate(vocab.items(), 1)}
word2idx['<UNK>'] = 0
# 将文本转为索引
def text_to_sequence(text):
return [word2idx.get(word, 0) for word in text.split()]
X_train_seq = [text_to_sequence(text) for text in X_train]
X_test_seq = [text_to_sequence(text) for text in X_test]
class ScaledDotProductAttention:
def __init__(self, d_k):
self.d_k = d_k
def attention(self, Q, K, V):
scores = np.dot(Q, K.T) / np.sqrt(self.d_k)
attention_weights = np.exp(scores) / np.sum(np.exp(scores), axis=1, keepdims=True)
return np.dot(attention_weights, V)
# 示例输入,假设我们已经有了词向量
Q = np.random.rand(10, 64) # 10个词,64维度
K = np.random.rand(10, 64)
V = np.random.rand(10, 64)
attention = ScaledDotProductAttention(64)
output = attention.attention(Q, K, V)
# 词频分布
word_counts = pd.DataFrame(vocab.items(), columns=['word', 'count']).sort_values(by='count', ascending=False).head(20)
plt.figure(figsize=(12, 6))
sns.barplot(x='count', y='word', data=word_counts, palette='rainbow')
plt.title('Top 20 Words by Frequency')
plt.show()
# 模型训练过程中的损失变化(假设我们有训练的 loss 记录)
losses = np.random.rand(100) # 假设有 100 轮训练的损失
plt.figure(figsize=(12, 6))
plt.plot(losses, color='magenta')
plt.title('Training Loss Over Time')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
这几个重点,大家可以注意下~
- 使用基础 Python 实现了一个简化版的 Transformer,并应用了自注意力机制的核心概念。
- 选择了 IMDb 数据集来做情感分类任务,进行了词频可视化和训练损失曲线的绘制。
- 接下来的步骤可以继续扩展,如实现多头注意力、完整的前馈网络,进一步改进模型的表现。
整体案例通过自底向上的方式构建 Transformer,尽可能帮助大家深入理解其原理,尤其是注意力机制的核心思想。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


![[SDK]-菜单 和 树控件](https://i-blog.csdnimg.cn/direct/65e4fe26c85b4a488556847f2729bc41.gif)





![[基于 Vue CLI 5 + Vue 3 + Ant Design Vue 4 搭建项目] 01 安装 nodejs 环境](https://i-blog.csdnimg.cn/direct/662a16f0307f452daa8a84a11f9b1cbb.png#pic_center)