多模态如今是越来越火了,与之相关的研究方向在各大顶会基本都成了投稿热门,趁着这波风向,我也给想发论文但找不着idea的同学推荐一个创新思路:迁移学习+多模态融合。
这种结合可以轻松搞定提高性能这一核心问题,通过将源领域学习到的多模态知识迁移到目标领域,就可以快速适应目标领域的任务需求。
不仅如此,这种在不同模态之间实现更有效知识传递和信息融合的能力,也能提高模型在新任务上的准确率。比如胸部X光模型MultiFusionNet,在两类分类中取得了99.6%的高准确率。
为了让大家更好的掌握这个创新思路,然后运用到自己的文章中,今天我就来分享10种迁移学习+多模态融合创新方法,都是今年最新,代码基本都有。
论文原文+开源代码需要的同学看文末
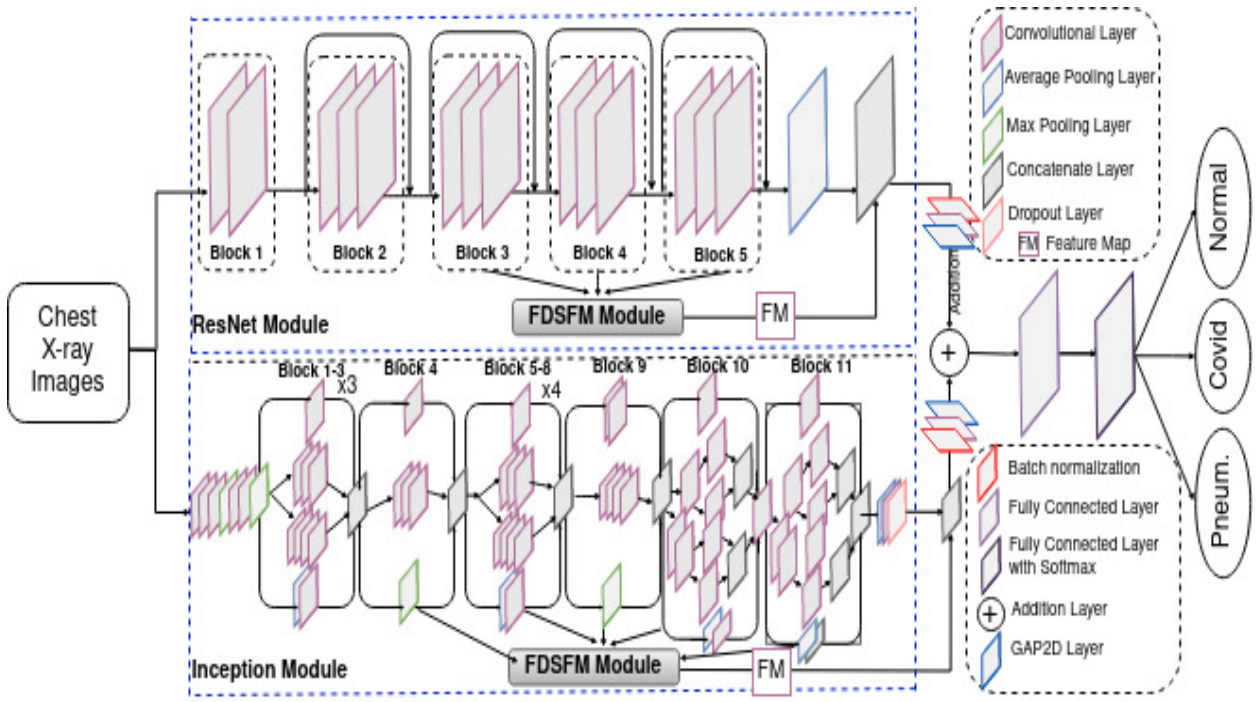
MultiFusionNet: multilayer multimodal fusion of deep neural networks for chest X-ray image classification
方法:论文提出了一种结合了迁移学习和多模态融合的方法,用于胸部X光图像分类。该方法强调从不同层次提取特征并将它们融合,考虑了每一层捕获的区分性信息,并提出了一种不同尺寸特征图融合模块,以有效地合并来自不同层的特征图。MultiFusionNet在三类和两类分类中分别取得了97.21%和99.60%的显著较高准确率。
创新点:
-
提出了一种新颖的深度学习模型,即多层多模态融合模型,用于增强肺部疾病的分类准确性。
-
设计了一个独立的特征图转换模块,用于解决在多个层次生成的特征图具有不同大小的问题。
-
提供了一个更大的数据集(Cov-Pneum),用于X射线图像,通过处理和合并多个公开可用的数据集,并在该数据集上评估了多个最新研究模型的性能。

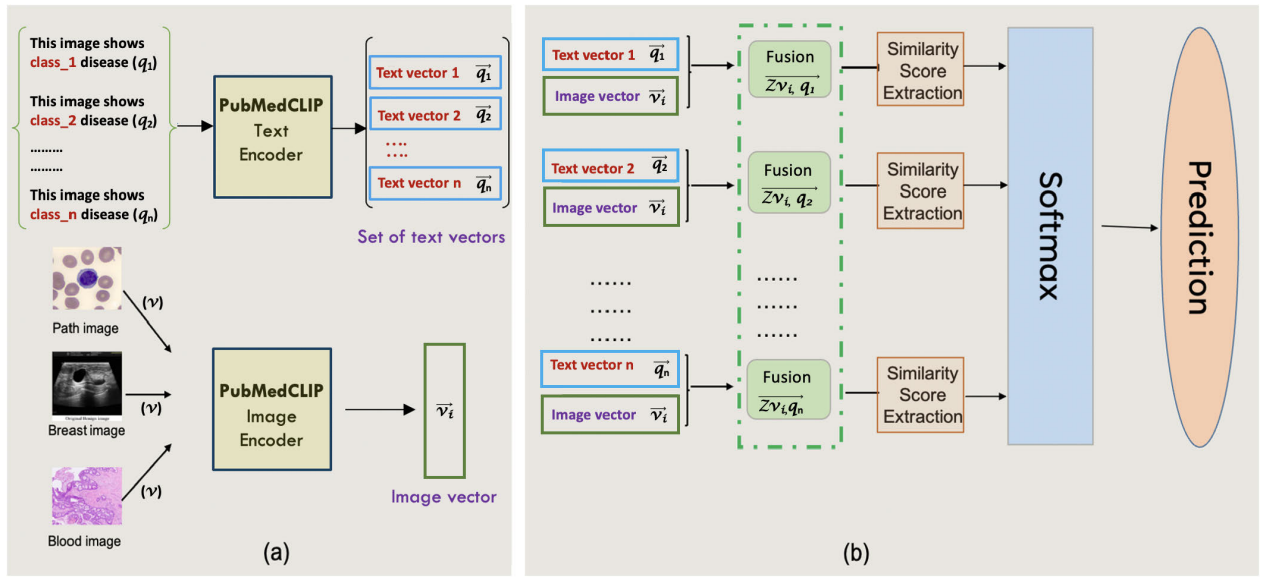
A Multimodal Transfer Learning Approach Using PubMedCLIP for Medical Image Classification
方法:论文提出了一种新的医学图像分类的迁移学习方法,通过结合预训练的PubMedCLIP模型和多模态特征融合,提出了一个多模态学习框架,通过将图片和文本输入进行特征融合,提高了图像分类的准确性,并降低了标注成本。实验证明该方法在不同医学图像数据集上实现了准确率超过90%的优异性能。
创新点:
-
提出了一种有效利用图像标签进行模型训练的方法,通过将文本提示与图像内容相连接,以提高性能。
-
通过逐渐增加提示模板中的上下文信息来改进模型的性能。
-
提出了一种新的特征融合方法,以进一步提高模型的性能。

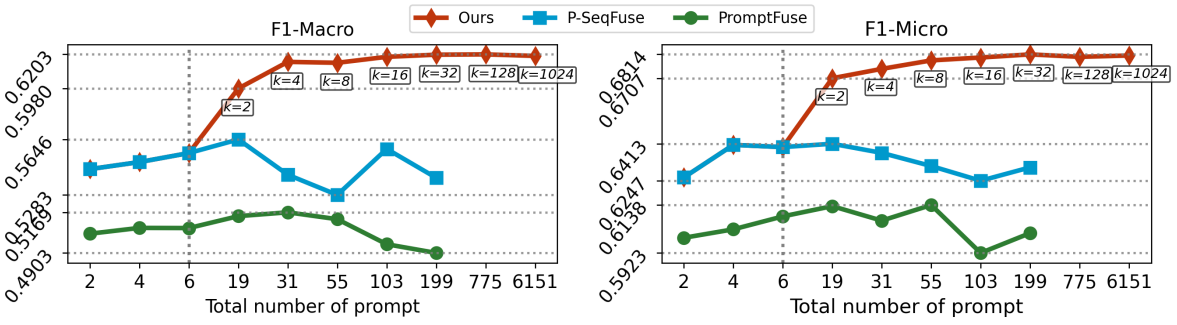
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts
方法:论文提出了一种新的多模态融合方法,用于提高迁移学习的参数效率和可扩展性。MoPE技术通过混合专家提示的方式,实现了对不同模态数据的有效融合,且在只需要大约0.8%的可训练参数的情况下,就实现了与全参数微调相匹配或更优的性能。
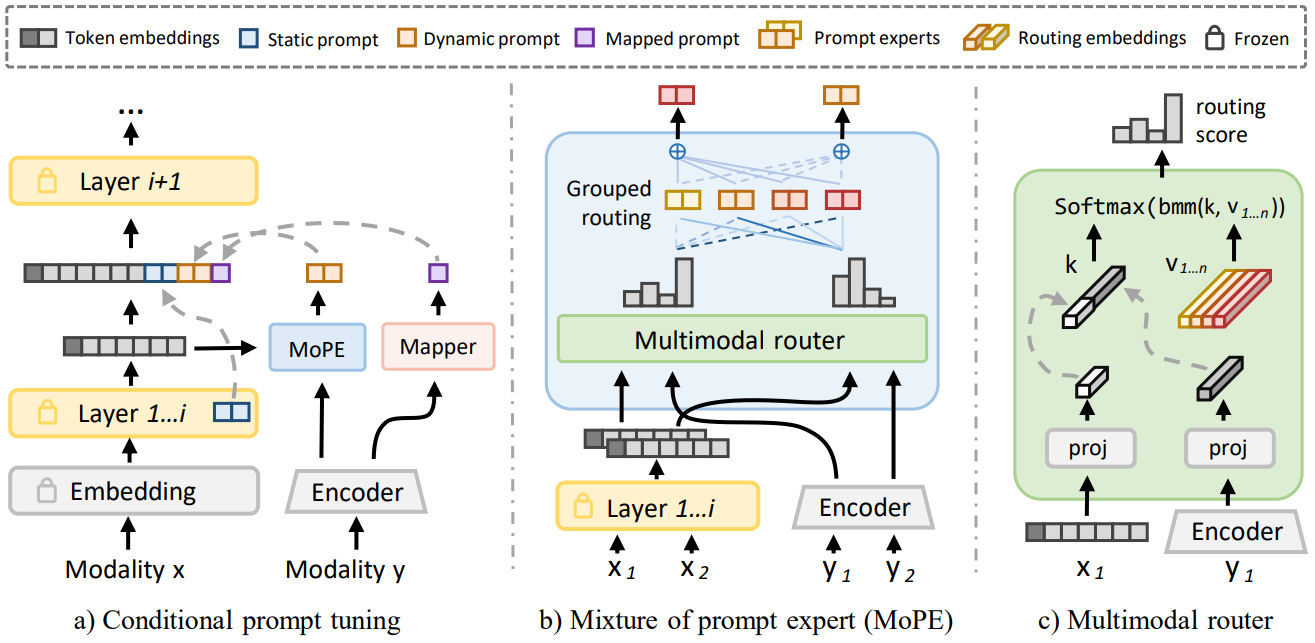
创新点:
-
通过将传统prompt拆分为静态和动态prompt以及映射prompt的方式,提出了一种条件prompt调整的方法,以实现自适应的prompt调整。
-
基于MoPE的设计,通过使用多个prompt专家和一个路由器来增加prompt调整的表达力。这种方法在多模态融合中表现出更高的表达力,并且在数据和可训练参数数量增加时具有更好的扩展性。
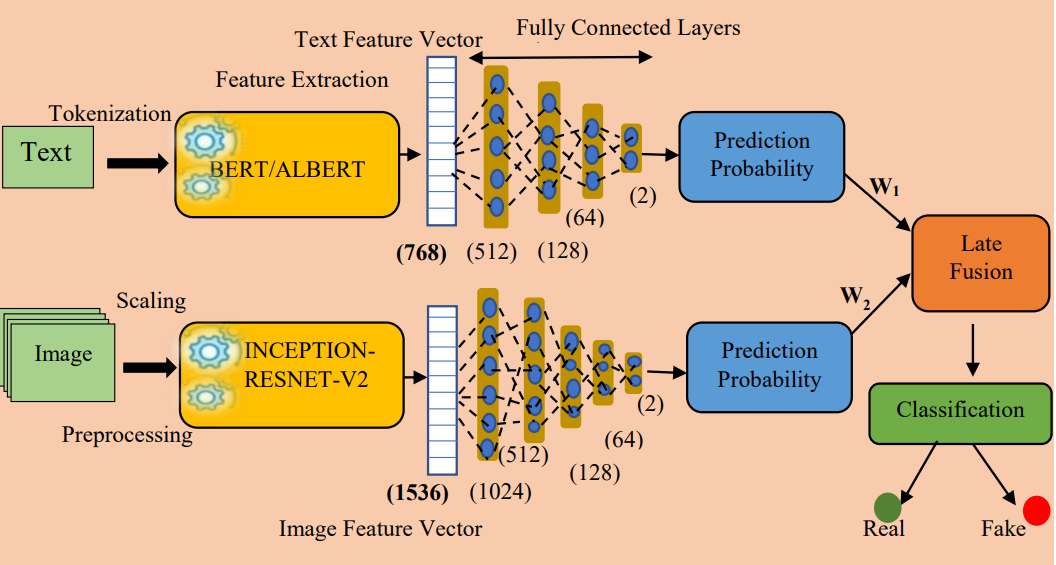
Multi-modal fusion using Fine-tuned Self-attention and transfer learning for veracity analysis of web information
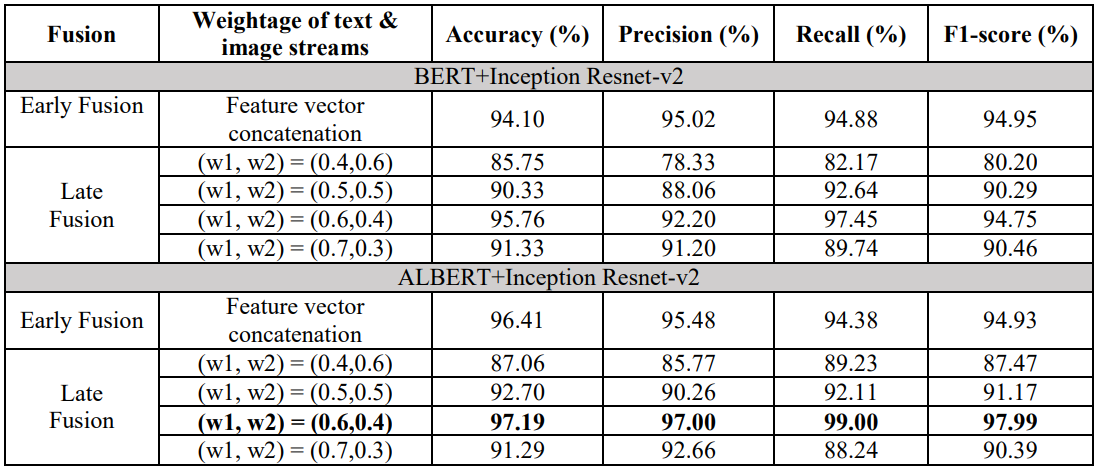
方法:论文中提到的多模态融合方法结合了迁移学习的优势,通过微调预训练模型来提高特定任务的性能。这种方法在多模态数据的准确性等多个评估指标上有显著的性能提升,在All Data数据集上达到了97.19%的最高准确率。
创新点;
-
使用多模态融合架构进行虚假信息的真实性分析,综合考虑了文本和图像的属性。
-
使用BERT和ALBERT语言模型提取文本特征,并使用Inception-ResNet-v2深度神经网络模型提取图像特征,以实现多模态数据的真实性分析。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“迁移多模态”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏