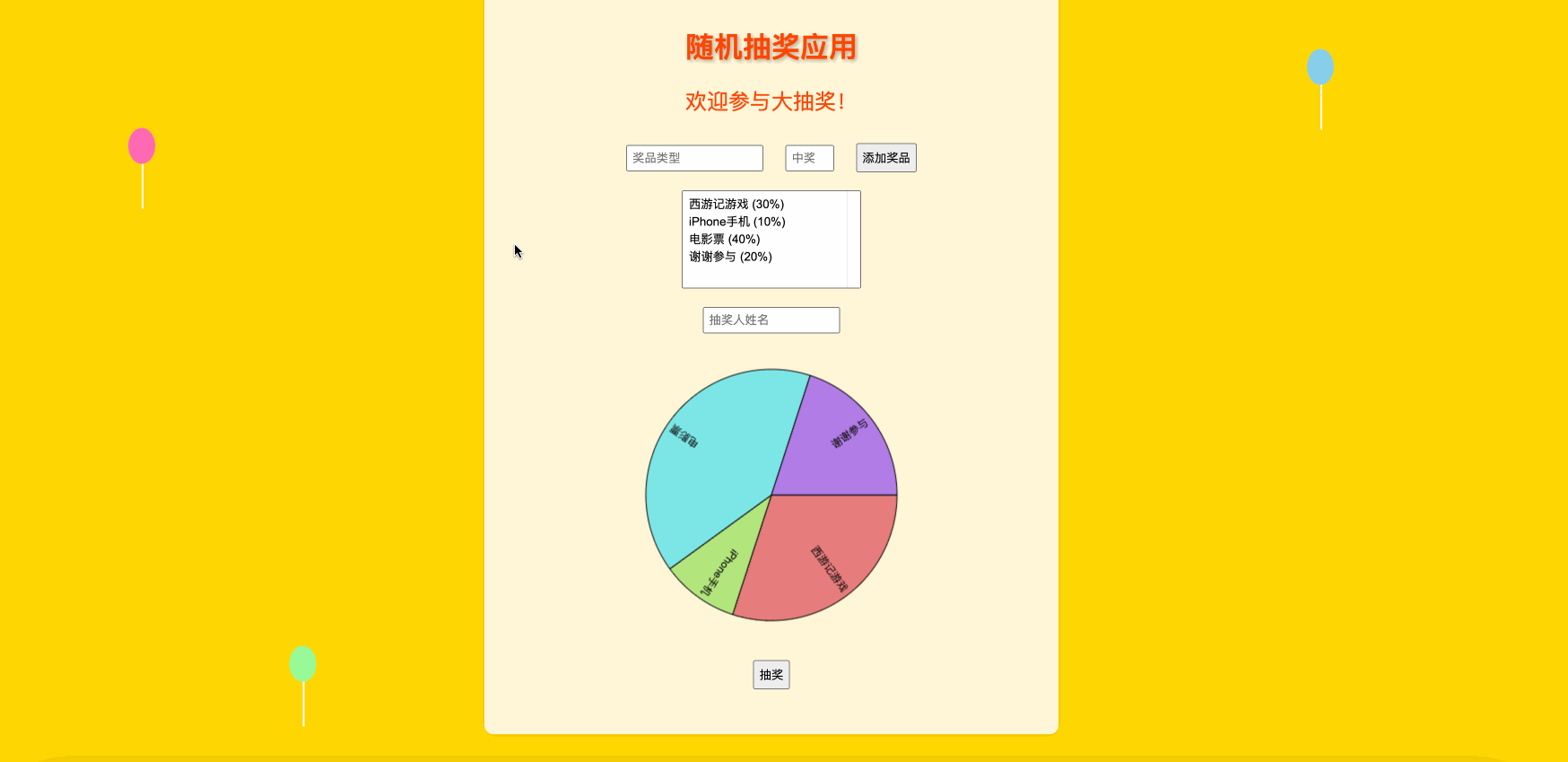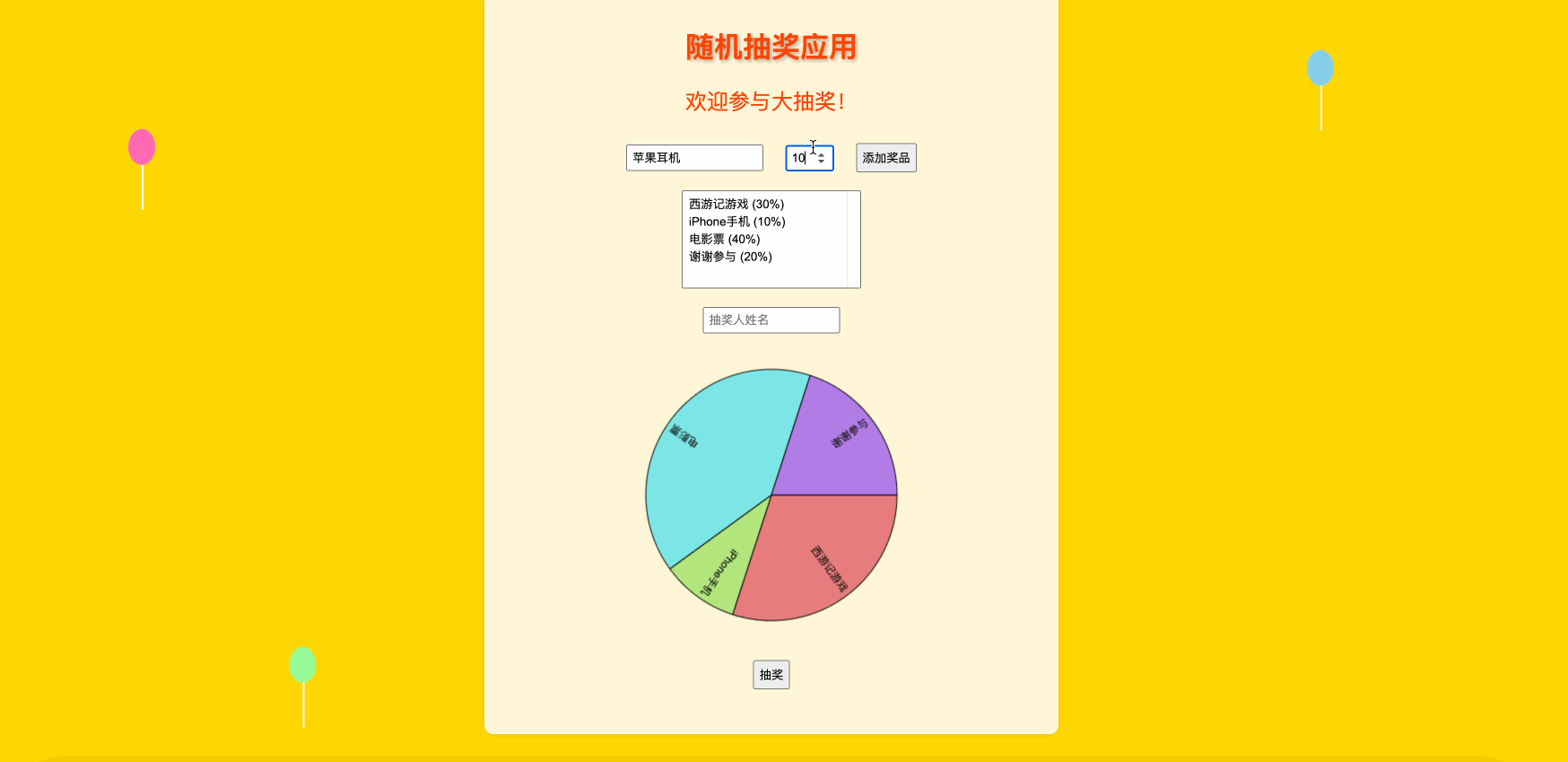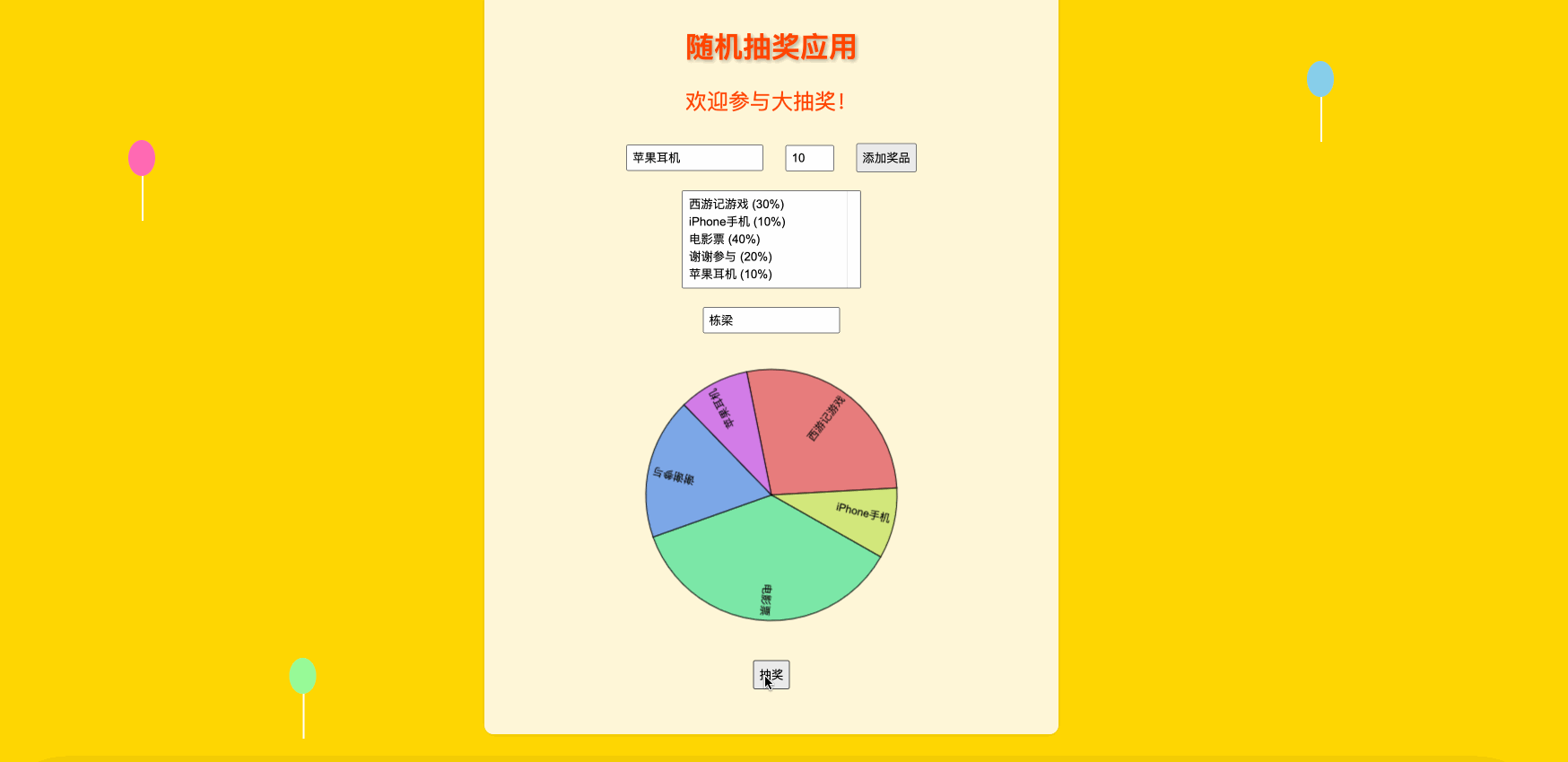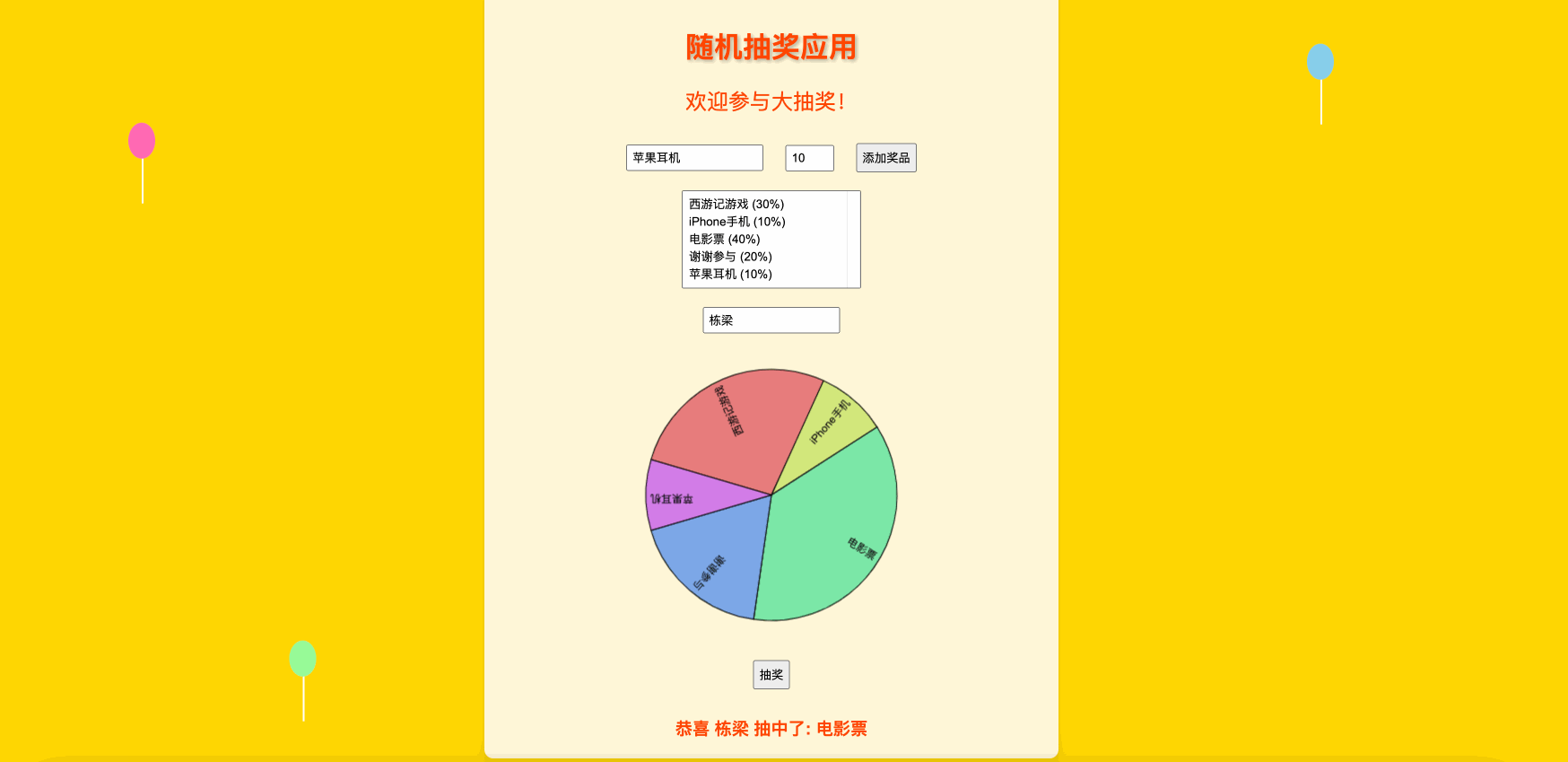
文章目录
- 1、Swin Transformer的介绍
- 1.1 Swin Transformer解决图像问题的挑战
- 1.2 Swin Transformer解决图像问题的方法
- 2、Swin Transformer的具体过程
- 2.1 Patch Partition 和 Linear Embedding
- 2.2 W-MSA、SW-MSA
- 2.3 Swin Transformer代码解析
- 2.3.1 代码解释
- 2.4 W-MSA和SW-MSA的softmax计算
- 2.4.1 代码实现
- 2.5 patch merging 实现过程
- 3、不同Swin Transformer版本的区别
1、Swin Transformer的介绍
下面是Swin Transformer论文的Abstract,

1.1 Swin Transformer解决图像问题的挑战
原论文中的Abstract讲到:Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text。 也就是说在一张图片中,不同的object有不同的尺度,以及与NLP相比,图像处理需要更多的token,下面来看在CNN中是如何解决不同的object有不同的尺度这个问题的,CNN是通过Conv和Pool对特征图中像素的不同感受野来检测不同尺度的物体,如下图所示,

为什么多尺度检测对于Swin Transformer是有挑战性的,请看下图最左边的Transformer结构,当图片的宽高像素是 h × w \sf{h} \times \sf{w} h×w,所以一共有 h × w \sf{h} \times \sf{w} h×w 个token,输入给Transformer时,输出也是 h × w \sf{h} \times \sf{w} h×w ,所以Transformer并没有做下采样操作,下图中间的是ViT的结构,下图最右边的是Swin Transformer结构,MSA是multi-head self-attention的缩写,

1.2 Swin Transformer解决图像问题的方法
Swin Transformer如何解决相比NLP中更多的token呢,Swin Transformer提出了hierarchical Transformer,hierarchical Transformer是由shifted windows计算出来的,
下面是MSA,W-MSA,SW-MSA的示意图, 如果对于MSA处理56x56个像素的图片,需要计算 313 6 2 3136^2 31362次的相似度,计算量较大;W-MSA将56x56个像素分割成8x8个windows,每个windows由7x7个像素组成,每个windows单独计算MSA,作用是减少计算量,缺点是windows之间没有信息交互,计算相似度为;SW-MSA可以解决windows之间没有信息交互的问题,例如下图最右边的示例,把一个8x8的图片的分成4个windows,然后分割grid向右下角移动 window // 2,这样分割的windows就可以包含多个windows之间的信息,

如下图中最左边部分的1,2,3包含多个windows的信息,

下图黄色虚线框标记的是Swin Transformer处理模块,每次经过Swin Transformer模块,patch Merging使特征层减少一半,通道数增加一倍,


与ViT特征层不变不同,每次经过Swin Transformer模块,特征层减少一半,通道数增加一倍,

2、Swin Transformer的具体过程
2.1 Patch Partition 和 Linear Embedding
如下图,黄色虚线框的作用是下采样,

将224x224x3的特征图中的4x4x3的像素patch成1个token,然后通过concat操作,就得到了4x4x3=48个特征维度,把这个48个维度的向量看成一个token,所以224x224x3的特征图有56x56个token,每个token的特征维度是48,再经过一个映射把48个维度映射成96个维度,如下图所示,

Patch Partition 和 Linear Embedding在上面的示意图上是2个步骤,但是在代码中却是一步完成的,如下代码中的self.proj,

2.2 W-MSA、SW-MSA
如下图,2个连续的swin transformer结构与ViT的结构只有W-MSA、SW-MSA和MSA的区别,其他的MLP、Norm结构都相同,

下面是MSA和W-MSA的示意图,相较于MSA,W-MSA计算量较小,但是windows之间没有信息交互,

下面是SW-MSA的示意图,SW-MSA采用新的 window 划分方式,将 windows 向右下角移动 window size // 2,移动之后会发现windows的大小不一样,先把A+B向右移动,然后A+C再向下移动就解决了windows的大小不一样的问题,这样就可以并行地计算SW-MSA了,
需要注意到,移动之后每个window的像素并不是连续的,如何解决这个问题,请看下面的解释,

如下图,0作为query,其本身和其他window内的数字作为k,示意图中矩形框表示0和移动的像素的乘积,这个乘积再作 − 100 -100 −100计算,取softmax之后,值就接近于0了,

计算完成之后,再把移动之后的像素还原,

W-MSA、SW-MSA与MSA的不同还在于softmax的计算方式,W-MSA、SW-MSA与MSA的不同有W-MSA、SW-MSA是在softmax里面加入相对位置偏置,MSA是在输入加入位置编码,

2.3 Swin Transformer代码解析
代码:
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # [nW*B, Mh, Mw, C]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [nW*B, Mh*Mw, C]
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # [nW*B, Mh*Mw, C]
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [nW*B, Mh, Mw, C]
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # [B, H', W', C]
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
# FFN
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
2.3.1 代码解释
代码解释:

接上面的代码:

window_partition函数:

window_reverse函数:

MLP函数:

2.4 W-MSA和SW-MSA的softmax计算

W-MSA和SW-MSA的softmax计算分为2个步骤,
对于window size为2的矩阵,计算其relative position index矩阵,矩阵大小为 w i n d o w s i z e 2 \sf{windowsize}^2 windowsize2 x w i n d o w s i z e 2 \sf{windowsize}^2 windowsize2,relative position index矩阵的size和相似度矩阵的size一致,计算结果不用赘述,很容易看出来,相对位置的矩阵size是 2 M − 1 \sf{2M-1} 2M−1 x 2 M − 1 \sf{2M-1} 2M−1

relative position bias matrix是一个可学习的参数,是依照相对位置的所有组合方式而来, relative position bias B 的值来自 relative position bias matrix B ^ \sf{\hat{B}} B^ 的值,

2.4.1 代码实现
因为2维矩阵需要考虑2个维度的值,不方便计算,所以把2维坐标转为1维坐标,计算过程如下,


代码以及代码解释:
下图右边的代码假设window size为7,


2.5 patch merging 实现过程
patch merging在swin transformer中的位置如下,
patch merging的实现过程如下图,原来的像素在每隔1个像素组合,经过concat和LayerNorm以及Linear层之后size减倍,channel数加倍,

代码:

3、不同Swin Transformer版本的区别
区别在于stage1的channel数,stage3的Swin Transformer计算的次数,

参考:
1、原论文:https://arxiv.org/pdf/2103.14030
2、哔哩哔哩:https://www.bilibili.com/video/BV1xF41197E4/?p=6&spm_id_from=pageDriver