文章目录
- 前言
- 一、协同过滤
- 1. 基于用户的协同过滤(UserCF)
- 2. 基于物品的协同过滤(ItemCF)
- 3. 相似度计算方法
- 二、相似度计算方法
- 1. 欧氏距离
- 2. 皮尔逊相关系数
- 3. 杰卡德相似系数
- 4. 余弦相似度
- 三、推荐模块案例
- 1.基于文章的协同过滤推荐功能
- 2.基于用户的协同过滤推荐功能
前言
在信息过载的时代,推荐系统成为连接用户与内容的桥梁。本文聚焦于协同过滤算法,这一实现个性化推荐的核心技术。我们将探讨基于用户和基于物品的两种协同过滤方法,并分析它们的优缺点。同时,深入讨论相似度计算方法,这是影响推荐效果的关键。通过两个具体案例——基于文章和基于用户的协同过滤推荐功能,我们将展示协同过滤算法在实际应用中的魅力。这些案例不仅帮助理解算法原理,也提供了实战参考。希望本文能引导你掌握协同过滤算法精髓,并能在实践中灵活运用,为构建精准、高效的推荐系统贡献力量。
一、协同过滤
协同过滤(Collaborative Filtering, CF) 是一种广泛应用于推荐系统中的算法,它通过分析用户的行为和偏好,发现用户之间的相似性(或物品之间的相似性),从而为用户推荐他们可能感兴趣的物品。常用来实现推荐模块的协同过滤算法主要分为两类:基于用户的协同过滤(User-Based Collaborative Filtering, UserCF) 和 基于物品的协同过滤(Item-Based Collaborative Filtering, ItemCF)。
1. 基于用户的协同过滤(UserCF)
基本思想:
基于用户的协同过滤算法通过分析用户对物品的喜好来找到与用户兴趣相似的其他用户,然后将这些相似用户喜欢的、且目标用户尚未听说过的物品推荐给目标用户。这种方法认为,如果两个用户在过去的喜好上有很多重叠,那么他们未来可能也会对相同的物品感兴趣。
算法步骤:
- 收集用户行为数据: 通常包括用户评分、购买、浏览等行为数据。
- 计算用户相似度: 使用相似度计算方法(如余弦相似度、皮尔逊相关系数等)来计算用户之间的相似度。
- 生成推荐列表: 根据相似用户的喜好来预测目标用户对未评分物品的兴趣程度,并生成推荐列表。
优点:
- 能够捕捉到用户的动态兴趣变化。
- 对于新用户来说,只要有足够的相似用户,也能产生不错的推荐效果。
缺点:
- 随着用户数量的增加,计算用户相似度的开销会急剧上升。
- 对于用户兴趣分布不均匀的情况,可能无法找到足够多的相似用户。
2. 基于物品的协同过滤(ItemCF)
基本思想:
基于物品的协同过滤算法通过分析用户对不同物品的喜好来找到与目标物品相似的其他物品,然后将这些相似物品推荐给喜欢目标物品的用户。这种方法认为,如果两个物品被很多相同的用户喜欢,那么这两个物品之间就存在某种相似性,因此可以将一个物品推荐给喜欢另一个物品的用户。
算法步骤:
- 收集用户行为数据: 与用户CF相同。
- 计算物品相似度: 使用相似度计算方法(如余弦相似度、杰卡德相似度等)来计算物品之间的相似度。
- 生成推荐列表: 根据用户对已评分物品的喜好和物品之间的相似度来预测用户对未评分物品的兴趣程度,并生成推荐列表。
优点:
- 能够处理大规模数据集,因为物品之间的相似度是静态的,可以离线计算并存储。
- 能够发现物品之间的隐式关系,提高推荐的多样性。
缺点:
- 对于新用户来说,如果没有足够的行为数据,可能无法产生有效的推荐。
- 推荐的实时性较差,因为物品之间的相似度是预先计算好的。
3. 相似度计算方法
在实现协同过滤算法时,常用的相似度计算方法包括:
- 余弦相似度: 衡量两个向量在方向上的相似程度,取值范围在[-1,1]之间。
- 皮尔逊相关系数: 在余弦相似度的基础上考虑了向量的大小(即评分的尺度),更适合处理具有不同评分尺度的用户数据。
- 杰卡德相似系数: 主要用于衡量两个集合之间的相似度,适用于用户-物品交互数据非常稀疏的情况。
综上所述,协同过滤算法通过利用用户或物品之间的相似性来产生推荐,具有实现简单、效果显著等优点,是推荐系统中常用的算法之一。然而,它也存在一些局限性,如冷启动问题、稀疏性问题等,需要在实际应用中结合其他算法和技术来加以解决。
二、相似度计算方法
1. 欧氏距离
在协同过滤算法中,物品之间的相似度计算是推荐系统的重要组成部分,而欧几里得距离(Euclidean Distance) 作为一种常用的距离度量方式,也可以被转化为相似度指标来评估物品之间的相似程度。
欧几里得距离,也称为欧式距离,是在多维空间中两点之间的直线距离。在二维空间中,它可以通过勾股定理来计算;在多维空间中,则可以通过计算各维度上差的平方和的平方根来得到。对于物品之间的相似度计算,我们可以将每个物品视为多维空间中的一个点,其中每个维度代表物品的一个特征(如用户对物品的评分、物品的某些属性等)。
欧几里得距离转化为相似度:
虽然欧几里得距离本身表示的是两点之间的物理距离,但在实际应用中,我们通常希望得到一个表示相似度的值,而不是距离。因此,需要将欧几里得距离转化为相似度。然而,需要注意的是,欧几里得距离与相似度是成反比的,即距离越大,相似度越小;距离越小,相似度越大。
为了将欧几里得距离转化为相似度,可以采用以下几种方法:
- 距离的倒数: 直接使用距离的倒数作为相似度值,即1/d。但这种方法在距离接近0时会导致相似度值趋于无穷大,因此可能需要进一步处理(如加1或设置上限)。
- 距离的倒数加常数: 为了避免上述问题,可以在距离的倒数上加一个常数(如1),即1/(d+1)。这样,即使距离很小,相似度值也不会过大。
- 归一化处理: 将计算得到的相似度值进行归一化处理,使其落在某个特定的区间内(如[0,1]),以便与其他相似度计算方法的结果进行比较。
- 使用其他相似度度量: 虽然欧几里得距离本身不适合直接作为相似度度量,但可以通过其他方式(如余弦相似度、皮尔逊相关系数等)来计算物品之间的相似度。
2. 皮尔逊相关系数
皮尔逊相关系数(Pearson Correlation Coefficient) 是统计学中用于度量两个变量X和Y之间线性相关程度的一种方法。在协同过滤算法中,特别是基于用户的协同过滤(UserCF)中,皮尔逊相关系数被广泛应用于计算用户之间的相似度。
在基于用户的协同过滤中,我们通常使用用户对物品的评分数据来计算用户之间的相似度。 设用户U1和用户U2分别对n个物品进行了评分,则可以通过计算这两个用户评分向量的皮尔逊相关系数来评估他们之间的相似度。具体地,将用户对每个物品的评分视为一个变量,则两个用户的评分向量就可以看作是这些变量的两个观测值序列。通过计算这两个序列的皮尔逊相关系数,我们就可以得到一个介于-1和1之间的数值,用于表示这两个用户之间的相似度。
3. 杰卡德相似系数
用户之间的相似度计算方法中的杰卡德相似系数(Jaccard Similarity Coefficient) 是一种用于衡量两个集合之间相似度的指标,它也可以应用于用户之间的相似度计算,特别是在用户行为数据(如购买记录、浏览历史等)可以表示为集合形式时。
应用场景:
在用户相似度计算中,杰卡德相似系数适用于以下场景:
- 电商推荐: 在电商平台中,可以根据用户的购买记录计算用户之间的杰卡德相似系数,从而找出具有相似购买行为的用户群体,并为他们推荐可能感兴趣的商品。
- 社交网络: 在社交网络中,可以根据用户的关注、点赞、评论等行为数据计算用户之间的杰卡德相似系数,以发现潜在的朋友关系或兴趣群体。
- 内容推荐: 在新闻、视频、音乐等内容推荐场景中,可以根据用户的历史浏览或消费记录计算用户之间的杰卡德相似系数,从而为用户推荐与其兴趣相似的内容。
4. 余弦相似度
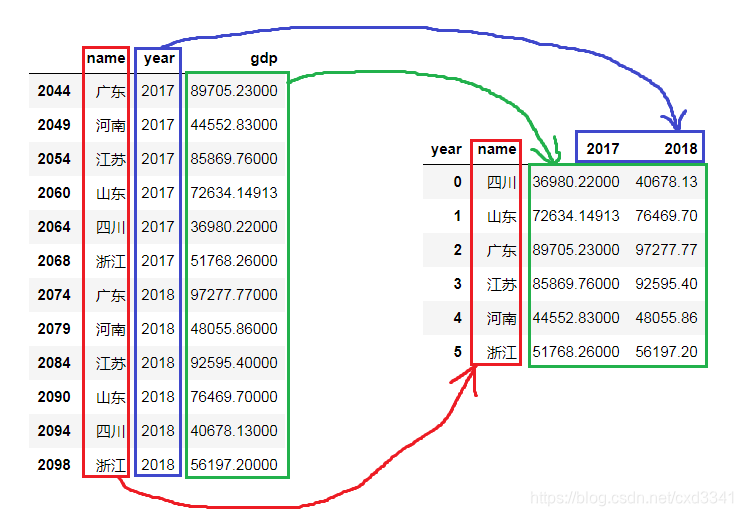
协同过滤中的余弦相似度是一种常用的用户或物品相似度计算方法,它通过计算两个向量在向量空间中夹角的余弦值来评估它们的相似度。
示例代码:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
userid =1008
exportdata = []
goodsidlist = []
def load_data(file_path):
global userid
global goodsidlist
'''导入用户商品数据
input: file_path(string):用户商品数据存放的文件
output: data(mat):用户商品矩阵
'''
filedata = pd.read_csv(file_path)
# print(filedata.values[0][0])
data1 = filedata.drop(['userid'],axis=1)
data = pd.DataFrame(data1)
goodsidlist = data.columns.values.tolist()
return np.mat(data)
def cos_sim(x, y):
'''余弦相似性
input: x(mat):以行向量的形式存储,可以是用户或者商品
y(mat):以行向量的形式存储,可以是用户或者商品
output: x和y之间的余弦相似度
'''
numerator = x * y.T # x和y之间的额内积
denominator = np.sqrt(x * x.T) * np.sqrt(y * y.T)
return (numerator / denominator)[0, 0]
def similarity(data):
'''计算矩阵中任意两行之间的相似度
input: data(mat):任意矩阵
output: w(mat):任意两行之间的相似度
'''
m = np.shape(data)[0] # 用户的数量
# 初始化相似度矩阵
w = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
if j != i:
# 计算任意两行之间的相似度
w[i, j] = cos_sim(data[i, ], data[j, ])
w[j, i] = w[i, j]
else:
w[i, j] = 0
return w
def user_based_recommend(data, w, user):
'''基于用户相似性为用户user推荐商品
input: data(mat):用户商品矩阵
w(mat):用户之间的相似度
user(int):用户的编号
output: predict(list):推荐列表
'''
m, n = np.shape(data)
interaction = data[user, ] # 用户user与商品信息
# print(interaction)
# 1、找到用户user没有互动过的商品
not_inter = []
for i in range(n):
if interaction[0, i] == 0: # 没有互动的商品
not_inter.append(i)
# 2、对没有互动过的商品进行预测
predict = {}
for x in not_inter:
item = np.copy(data[:, x]) # 找到所有用户对商品x的互动信息
for i in range(m): # 对每一个用户
if item[i, 0] != 0: # 若该用户对商品x有过互动
if x not in predict:
predict[x] = w[user, i] * item[i, 0]
else:
predict[x] = predict[x] + w[user, i] * item[i, 0]
# 3、按照预测的大小从大到小排序
return sorted(predict.items(), key=lambda d:d[1], reverse=True)
def top_k(predict, k):
'''为用户推荐前k个商品
input: predict(list):排好序的商品列表
k(int):推荐的商品个数
output: top_recom(list):top_k个商品
'''
top_recom = []
len_result = len(predict)
if k >= len_result:
top_recom = predict
else:
for i in range(k):
top_recom.append(predict[i])
return top_recom
if __name__ == "__main__":
# 1、导入用户商品数据
# print ("------------ 1. load data ------------")
data = load_data("orders.csv")
# 2、计算用户之间的相似性
# print ("------------ 2. calculate similarity between users -------------")
w = similarity(data)
# 3、利用用户之间的相似性进行推荐
# print ("------------ 3. predict ------------userid:::"+str(userid))
predict = user_based_recommend(data, w, userid)
# 4、进行Top-K推荐
# print ("------------ 4. top_k recommendation ------------")
top_recom = top_k(predict, 5)
relist=[]
for i in top_recom:
key = i[0]
relist.append(goodsidlist[key])
print(relist)
三、推荐模块案例
业务背景:
在一个大型的在线内容平台,用户可以阅读各种类型的文章,包括新闻、博客、教程等。随着平台上内容的不断增长,用户面临着信息过载的问题,很难快速找到自己感兴趣的内容。为了提高用户体验,增加用户参与度和满意度,平台决定开发一个基于协同过滤算法的推荐模块,帮助用户发现个性化的内容。
1.基于文章的协同过滤推荐功能
创建一个基于文章的协同过滤推荐功能的 Django 应用涉及到多个步骤,包括设计模型、收集用户行为数据、计算相似度和生成推荐。以下是一个简化的示例,展示如何使用 Django 实现协同过滤推荐功能。
步骤一:设计模型
Category(分类表)
字段名 数据类型 描述 name VARCHAR(100) 分类名称,唯一 Article(文章表)
字段名 数据类型 描述 title VARCHAR(255) 标题 content TEXT 内容 author VARCHAR(100) 作者 cateid ForeignKey(Category) 分类,外键关联分类表 tags ManyToManyField(Tag) 标签,多对多关联标签表 Tag(标签表)
字段名 数据类型 描述 name VARCHAR(100) 标签名称,唯一 UserBrowseRecord(用户浏览记录表)
字段名 数据类型 描述 user_id ForeignKey(User) 用户ID,外键关联用户表 article_id ForeignKey(Article) 文章ID,外键关联文章表 tag_id ForeignKey(Tag) 标签ID,外键关联标签表 count INTEGER 浏览次数,默认为0
步骤二:收集用户行为数据
在这个示例中,假设用户已经浏览过多篇文章,用户浏览记录表UserBrowseRecord已有对应的浏览记录。
步骤三:计算相似度并生成推荐
正常流程下,应该先构建一个方法用于计算用户之间的相似度(使用余弦相似度、皮尔逊相关系数等计算方法),并返回相似用户的分数;然后根据相似用户的评分来推荐文章。
但是也可通过设置定时任务,每天晚上跑一次,查询用户浏览记录表根据次数排序,取前5个标签,根据标签去获取商品表中浏览次数最高前10篇文章,放到缓存。用户在推荐页获取推荐文章时,直接从缓存中获取。class RecommendTest(APIView): def get(self, request): # 此函数中的内容可设置定时任务,定时更新对于不同用户的推荐信息 # 获取所有用户信息 users = User.objects.all() for user in users: # **对每个用户,获取其浏览记录,并将其推荐信息存储到redis中** uviews = UserBrowseRecord.objects.filter(user_id=user.id).order_by("-count").all()[:5] ids = [i.tag_id for i in uviews] recommend = Article.objects.filter(tags__in=ids).order_by("-id").all()[:10] recommend_data = ArticleSerializer(recommend,many=True).data r.set_str("usercommend"+str(user.id),json.dumps(recommend_data)) return Response({"code":200,"mes":"推荐信息存储成功"}) def post(self, request): #获取此userid缓存在redis中的推荐信息 userid = request.data.get("userid") data = r.get_str("usercommend"+str(userid)) return Response({"code":200,"mes":json.loads(data)})
2.基于用户的协同过滤推荐功能
1.收集数据,浏览记录表
2.查询与当前用户相似度最高的10个用户
3.查询那10个用户近期游览记录,取20条。与用户最近浏览取差集def recommend_articles(request): # 获取当前用户的所有购买的商品标签 user_ratings = list(UserBrowseRecord.objects.filter(user_id=1).values('article_id')) print("user_ratings ==> ",user_ratings) strs = [i['article_id'] for i in user_ratings] print("article_strs ==> ",strs) # 这文章被哪些人看过 userlist = UserBrowseRecord.objects.filter(article_id__in=strs).values("user_id", 'count') print("userlist ==> ",userlist) print("len(userlist) ==> ",len(userlist)) dict = {} for i in userlist: if i['user_id'] in dict: dict[i['user_id']] += i['count'] else: dict[i['user_id']] = i['count'] print("user_list ==> ",dict) # 相似度最高的用户列表 similar_users = sorted(dict.items(), key=lambda x: x[1], reverse=True)[:10] print("similar_users ==> ",similar_users) # 获取这些用户看过的文章/标签? user_articles = [i['article_id'] for i in UserBrowseRecord.objects.filter(user_id__in=[i[0] for i in similar_users]).values('article_id')] print("user_articles ==> ",user_articles) # 文章 与 用户看过取差集 recommend_articles = list(set(user_articles) - set(strs)) print("recommend_articles ==> ",recommend_articles) # 根据tagid 获取此标签对应的阅读量最多的文章取前10个 # recommend_articles_list = Article.objects.filter(id__in=recommend_articles).order_by("-id")[:10] return JsonResponse({"code": 200, 'recommend_articles_list': recommend_articles})