作者:顾汉杰(执少)
什么是高基数 GroupBy
简单来说,想要分析的数据,拥有超多的“唯一值计数”(Distinct Count),而我们需要对这些数据进行分组分析(如统计次数、排名、计算均值、分位值等)。
高基数聚合计算在很多运营分析场景中都是刚需,它涉及对值不一样的海量数据进行分组聚合计算,以洞察用户行为、游戏玩家路径、市场趋势或产品表现等运营分析的关键指标。例如,在电商平台上,分析一段时间内不同商品类别在各个地区的销量分布,或者在游戏运营分析场景中,追踪玩家在游戏中的独特操作行为和路径,这些都需要处理基数极高的数据(如 ItemId、RequestId、TraceId 等,动辄上千万甚至亿级别的基数)。
现在的问题是,用户在进行此类分析时,由于数据量和复杂度的不同,SQL 执行耗时往往可能从数秒到数分钟甚至数小时不等,“高基数 GroupBy 执行太慢”,几乎成为用户的普遍认知,也是众多数据库和 OLAP 引擎重点关注的对象。SLS SQL 也持续关注这一点,并对此进行了相应的性能优化,本文即旨在向用户介绍 SLS 中的实现原理、查询加速手段以及适用场景。
GroupBy 的实现原理
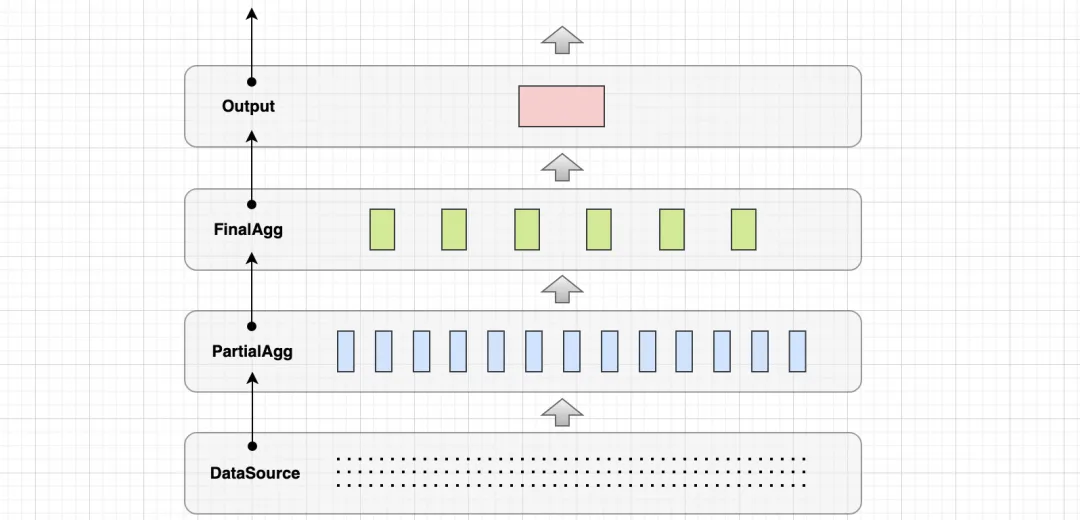
GroupBy 是几乎所有 OLAP 引擎必备的基础聚合能力,分布式计算引擎一般将海量数据以 Hash 散列的方式分布到不同节点进行分组(分桶)计算,每个分组内对数据进行聚合,然后再基于堆(往往使用 PriorityQueue)进行排序或 Limit,最终输出给用户需要的数据,比如 TopN 排行结果等。
这个过程中,我们可能还会用到预聚合技术:利用数据的局部性原理,对原始数据进行预聚合(PartialAgg),然后再发往最终聚合节点(FinalAgg),以减少网络间数据传输开销。
所以,总体来说,GroupBy 聚合计算大致会经历以下四个过程:DataSource -> PartialAgg -> FinalAgg -> Output。
其中,DataSource 和 PartialAgg 一般是绑定在一起执行,而 FinalAgg 以及 Output 则由分布式网络中的另外一些节点执行。
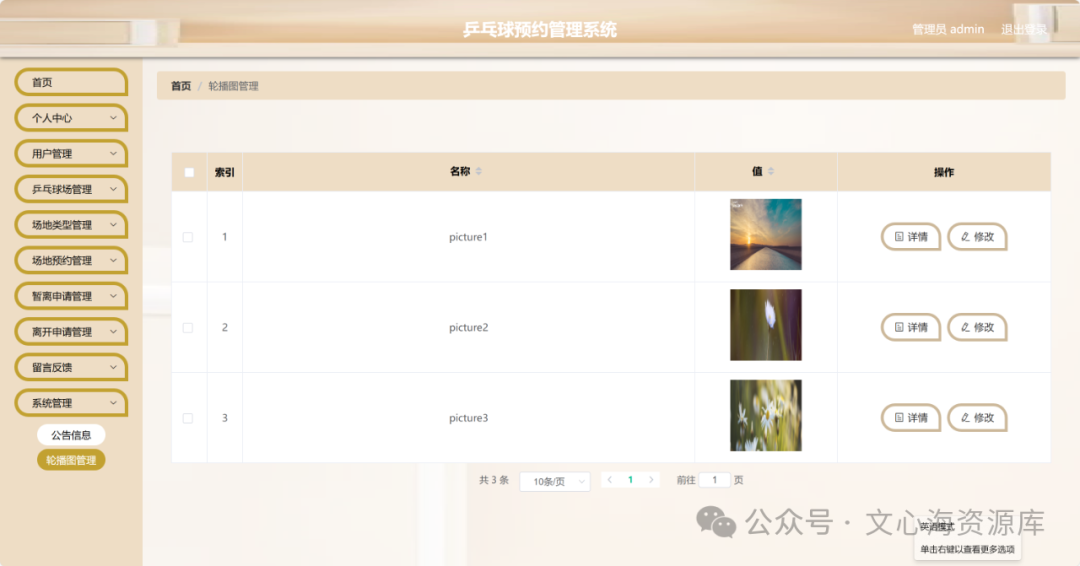
体验 SLS 高基数 GroupBy 查询加速
有了上面的基础知识和了解后,我们开门见山,直接带大家来感受一下 SLS 中的上亿级别高基数 GroupBy 的查询加速体验。
为了更客观地评估和分析下面的性能变化,我们必须先讲清楚我们的测试数据和测试用例情况。
测试数据
我们采用了模拟的类似 Nginx 服务访问日志,保存在一个 Project/Logstore 中,SQL独享版 CU 数设置为 5000。测试数据 Schema 如下:
{ RequestId: varchar, /*测试数据会确保每个请求ID确保全局唯一*/ ClientIP: varchar, Method: varchar, Latency: int, Status: int, ...}
测试用例
我们准备了 3 种测试用例,分别对应 3 种不同的业务分析场景:
- 高基单列聚合:对 28 亿条请求日志,按 RequestId 字段进行 GroupBy 统计计数(实际基数为 28 亿)
- 高基多列聚合:对 45 亿条请求日志,按 ClientIp、Status、Latency 字段进行 3 列 GroupBy 统计计数(实际基数为 15 亿)
- 低基数值聚合:对 1.5 万亿条请求日志,按 Latency 字段统计 Top100 的频次(实际基数为 735 万)
测试说明
- 由于我们系统中设计有多级缓存,为了避免缓存对于测试的影响干扰,我们会在每次查询时通过添加 not <不存在的keyword> 过滤条件来避开缓存,以确保每次查询都进行完整的物理执行,公平地对比整体执行性能。
- 测试过程使用的是真实线上服务(地域为上海),测试数据真实存储在 SLS Logstore 中,但因分片数以及数据分布特征不尽相同,因此不同用户的数据实测结果可能略有差异,但相同量级应该大同小异。
🚗 走,上车!
案例 1:
高基单列聚合,对 28 亿条请求日志,按 RequestId 字段进行 GroupBy 统计计数(实际基数为 28 亿)
第一步,进行基准测试,使用普通 SQL 模式,查询大约需要 17s。

第二步,切换到增强 SQL 模式,并设置 session 参数 set session hash_partition_count=40(此值默认最大为 20),查询降到 10s。
这是什么魔法操作?
上文提到底层并行度已经足够分散,但我们面对的是一个 28 亿条绝对高基的测试数据集(每一个 RequestId 都不一样),即使底层并行度足够,FinalAgg 阶段仍将面临极大的聚合计算压力,而我们默认 FinalAgg 阶段的并行度与 shard 分片数相关但最大为 20,这里我们将这个能力开放给用户结合自身情况可以进行动态调整。

第三步,设置 session 参数 set session hash_partition_count=64/128/200,查询进一步降到 7s/4.5s/3.7s。



加速效果还不错。。。
通过增加 FinalAgg 阶段的并行度,我们看到查询从原来的 17s 降低到了 3.7s!同时,我们也看到并行度的增加对于查询延时的加速效果也逐渐收敛,这是因为在增加并行度的同时,也增加了额外的网络通信和调度开销。所以我们为该 session 参数设置了系统上限为 200,再往上其实可能也不会带来太大的加速收益。
以为这样就收工了,并没有!
第四步,设置 session 参数 set session high_cardinality_agg=true,查询降到 2.1s!

这又是发生了什么?
针对高基数场景的数据特征,我们将数据在底层走了一个不同的流转模式进行数据聚合,大幅提高效率。我们同样开放了相应的 session 参数供用户按需使用。
最终,高基单列聚合,我们将查询从原来的 17s 降至 2s,体验到了 8 倍的加速快感。
案例 2:
高基多列聚合,对 45 亿条请求日志,进行多列 GroupBy 统计计数(实际多列组合维基为 15 亿)
第一步,进行基准测试,使用普通 SQL 模式,查询大约需要 24s。

第二步,切换到增强 SQL 模式,并设置 session 参数 set session hash_partition_count=40(此值默认最大为 20),查询降 到11s。

第三步,提升并行度 set session hash_partition_count=64/128/200,查询进一步降到 7.3s/5.9s/5.8s。



第四步,设置 session 参数 set session high_cardinality_agg=true,查询降到 2.9s!

最终,高基多列聚合,我们将查询从原来的 24s 降至 3s,同样也体验到了 8 倍的加速快感。
案例 3:
低基数值聚合,对 1.5 万亿条请求日志,按 Latency 字段统计 Top100 的频次(实际基数为 735 万)
第一步,进行基准测试,使用普通 SQL 模式,查询虽然只有 4.3s,但是因数据量大小限制被截断而结果不精确。

第二步,切换到增强 SQL 模式,查询只需 23.4s 即可精确查询,此时增强 SQL 体现出在面对超大规模数据量时的威力。

第三步,设置 session 参数 set session hash_partition_count=40/64/128/200(此值默认最大为 20),查询延时维持到 22-23s 之间,可以看到,在低基聚合场景中,通过提升 FinalAgg 并行度来加速查询,效果十分有限。
通过系统的监控分析,可以发现此时计算压力主要在 PartialAgg,FinalAgg 并不存在计算瓶颈,因此对它的提升,并不会对整体查询有明显的加速效果。




第四步,让我们再试试高基优化参数 set session high_cardinality_agg=true,结果是执行超时。
这说明,高基优化参数并不适用于低基聚合场景,在低基维度下,面对超大规模数据(测试数据超过 1.5 万亿)的聚合计算,默认的预聚合技术(PartialAgg+FinalAgg)能够有效发挥计算效能,仍然是不二之选。
结论和建议
本文主要介绍了 SLS 中的高基数 GroupBy 查询加速原理,并设计了 3 种典型场景的测试用例,通过 SLS 线上服务的实际测试表现,带大家体验了高基聚合计算 8 倍查询加速、万亿数据 20s 查询的极致快感。
在测试过程中,也一一向读者解释了其中的具体细节和原理,为什么会这样?为什么能加速?为什么加速不明显等等。以下是给 SLS 用户关于此方面的查询实践和建议:
- 数据规模不大时,使用默认模式即可;
- 数据规模很大而数据分片不多时,建议开启增强 SQL 模式,可以极大提升数据底层并行度;
- 高基聚合时,可以尝试以下两个 session 参数,可能带来数倍查询加速效果:
- set session hash_partition_count= 设置多少合适?建议 20-64 以内,过犹不及
- set session high_cardinality_agg=true/false 是否设置取决于数据离散度
- 低基聚合,以上两个 session 参数并不十分适用,通过默认增强 SQL 模式即可实现查询加速和精确。