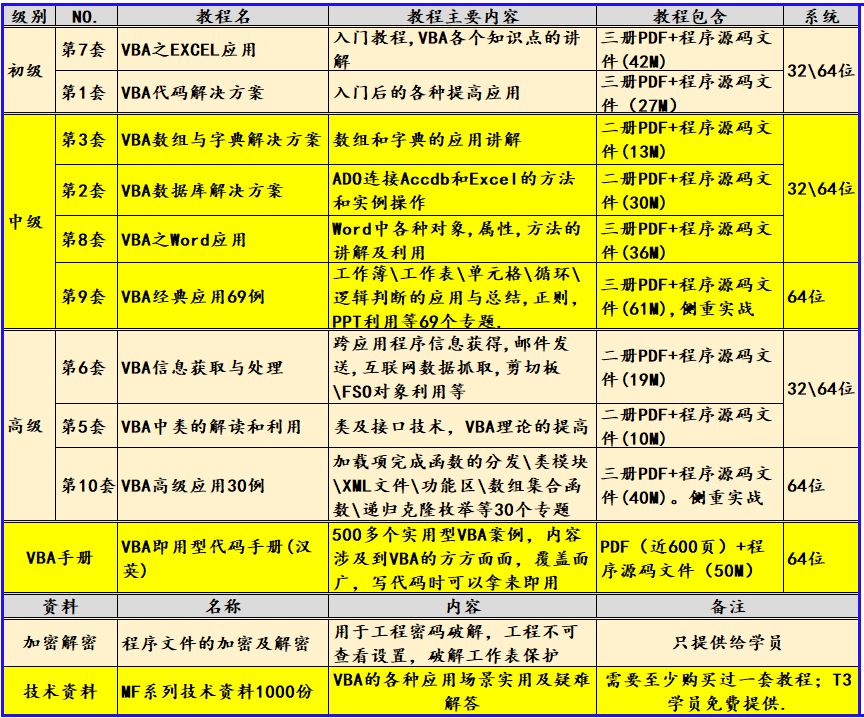
目录
- 词袋模型 概述
- 词袋模型 实例
- 第1步 构建语料库
- 第2步 对句子进行分词
- 第3步 创建词汇表
- 第4步 转换词袋表示
- 第5步 计算余弦相似度
- 词袋模型的局限性
词袋模型 概述
词袋模型,Bag-of-Words,是一种简单的文本表示方法,也是 NLP 中的一个经典模型。
它将文本中的词看作一个个独立的个体,不考虑它们在句子中的顺序,只关心每个词出现的频次。
e . g . e.g. e.g. 比如我们有两个句子
+ "我喜欢吃苹果"
+ "苹果是我喜欢的水果"
词袋模型会将这两个句子表示成如下向量:
+ {"我": 1, "喜欢": 1, "吃": 1, "苹果": 1}
+ {"苹果": 1, "是": 1, "我": 1, "喜欢": 1, "的": 1, "水果": 1}
而后,词袋模型通过比较两个向量之间的相似度,判断其关联性的强弱
词袋模型 实例

第1步 构建语料库
# 构建语料库
corpus = ["我特别特别喜欢看电影",
"这部电影真的是很好看的电影",
"今天天气真好是难得的好天气",
"我今天去看了一部电影",
"电影院的电影都很好看"]
第2步 对句子进行分词
使用 jieba 包对句子进行分词。
# 对句子进行分词
import jieba
corpus_tokenized = [list(jieba.cut(sentence)) for sentence in corpus]
corpus_tokenized
结果:
[['我', '特别', '特别', '喜欢', '看', '电影'],
['这部', '电影', '真的', '是', '很', '好看', '的', '电影'],
['今天天气', '真好', '是', '难得', '的', '好', '天气'],
['我', '今天', '去', '看', '了', '一部', '电影'],
['电影院', '的', '电影', '都', '很', '好看']]
第3步 创建词汇表
根据分词结果,创建该语料库的词汇表,其中每一个词对应一个编号。
# 创建词汇表
word_dict = {}
for sentence in corpus_tokenized:
for word in sentence:
if word not in word_dict:
word_dict[word] = len(word_dict)
word_dict
结果:
{'我': 0,
'特别': 1,
'喜欢': 2,
'看': 3,
'电影': 4,
'这部': 5,
'真的': 6,
'是': 7,
'很': 8,
'好看': 9,
'的': 10,
'今天天气': 11,
'真好': 12,
'难得': 13,
'好': 14,
'天气': 15,
'今天': 16,
'去': 17,
'了': 18,
'一部': 19,
'电影院': 20,
'都': 21}
第4步 转换词袋表示
由第三步可知,该词袋长度为 21,故对该语料库中5句话的每句话转换词袋表示。长度均为21,按照该词在该句中出现的次数表示为句向量。
# 根据词汇表将句子转换为词袋表示
bow_vectors = []
for sentence in corpus_tokenized:
sentence_vector = [0] * len(word_dict)
for word in sentence:
sentence_vector[word_dict[word]] += 1
bow_vectors.append(sentence_vector)
bow_vectors
结果:
[[1, 2, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 2, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]
第5步 计算余弦相似度
余弦相似度(Cosine Similarity),可以衡量两个文本向量之间的相似性。其值在(-1,1)之间波动,1为最相似。
余弦相似度关注向量之间的角度,而非距离。而角度,能够更好地反映文本向量在概念空间中的相对方向和相似性。
# 计算余弦相似度
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_a = np.linalg.norm(vec1)
norm_b = np.linalg.norm(vec2)
return dot_product / (norm_a * norm_b)
similarity_matrix = np.zeros((len(corpus), len(corpus)))
for i in range(len(corpus)):
for j in range(len(corpus)):
similarity_matrix[i][j] = cosine_similarity(bow_vectors[i], bow_vectors[j])
similarity_matrix
结果:
array([[1. , 0.2236068 , 0. , 0.40089186, 0.14433757],
[0.2236068 , 1. , 0.23904572, 0.23904572, 0.64549722],
[0. , 0.23904572, 1. , 0. , 0.15430335],
[0.40089186, 0.23904572, 0. , 1. , 0.15430335],
[0.14433757, 0.64549722, 0.15430335, 0.15430335, 1. ]])
词袋模型的局限性
词袋模型逻辑清晰,实现简单,但是存在着一个致命的缺陷,那就是忽略了文本中的上下文信息。词袋模型无法捕捉单词之间的语义关系,因为单词在向量空间中的相对位置没有意义。
2024.09.07