Pandas是一个Python包,提供快速、灵活且表达力强的数据结构,旨在使处理“关系型”或“带标签”数据。专门设计用于进行数据分析和操作,它是建立在numpy之上,提供了易于使用的数据结构和数据分析工具。Pandas最主要的数据结构是DataFrame和Series。
主要特点:
- 数据结构:
- Series:一种类似于一维数组的对象,可以存储任何数据类型(整数、字符串、浮点数等)。Series有一个关联的索引,这个索引默认是整数,但也可以是任何唯一的可哈希对象。
- DataFrame:类似于二维大小可变的、由不同类型的列组成的表格,具有行标签和列标签。DataFrame可以被看作是由多个Series组成的集合。
- 数据操作:
- Pandas提供了多种方法来操作数据,包括但不限于:添加、删除数据,选择子集,排序数据,合并数据集,处理缺失数据等。
- 数据清洗:
- 提供了许多方便的方法来清洗数据,如去除重复项、填充或删除缺失值、替换值等。
- 时间序列功能:
- Pandas在处理时间序列数据方面非常强大,支持日期范围的生成、频率转换以及移动窗口统计等。
- 读写文件格式:
- 支持多种数据格式的读取和写入,例如CSV、Excel、SQL数据库等。
目录
安装Pandas
创建一个DataFrame
读取数据
查看数据
数据选择
1. 方括号[]选择单列或多列
2. 条件表达式选择,在方括号内部
3. 按标签选择:df.loc[row, col]
4. 按位置选择:df.iloc[row, col]
处理缺失值
df.dropna(): 删除含有缺失值的行或列
df.fillna(value): 用特定值填充缺失值。
数据清洗
删除不需要的列.drop
重命名列.rename
检测重复值
去除重复行
apply函数
分组与聚合
合并数据
Pandas数据表格表示

一个DataFrame中的每一列都是Series
安装Pandas
Pandas可以通过pip或conda安装:
pip install pandas创建一个DataFrame
当使用Python列表字典时,字典键将用作列标题,每个列表中的值将用作DataFrame的列
import pandas as pd
df = pd.DataFrame(
{
"Name": [
"Braund, Mr. Owen Harris",
"Allen, Mr. William Henry",
"Bonnell, Miss. Elizabeth",
],
"Age": [22, 35, 58],
"Sex": ["male", "male", "female"],
}
)
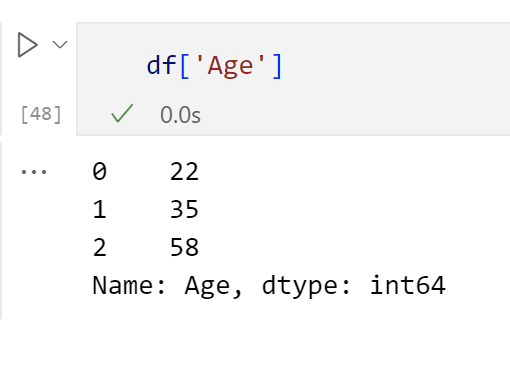
df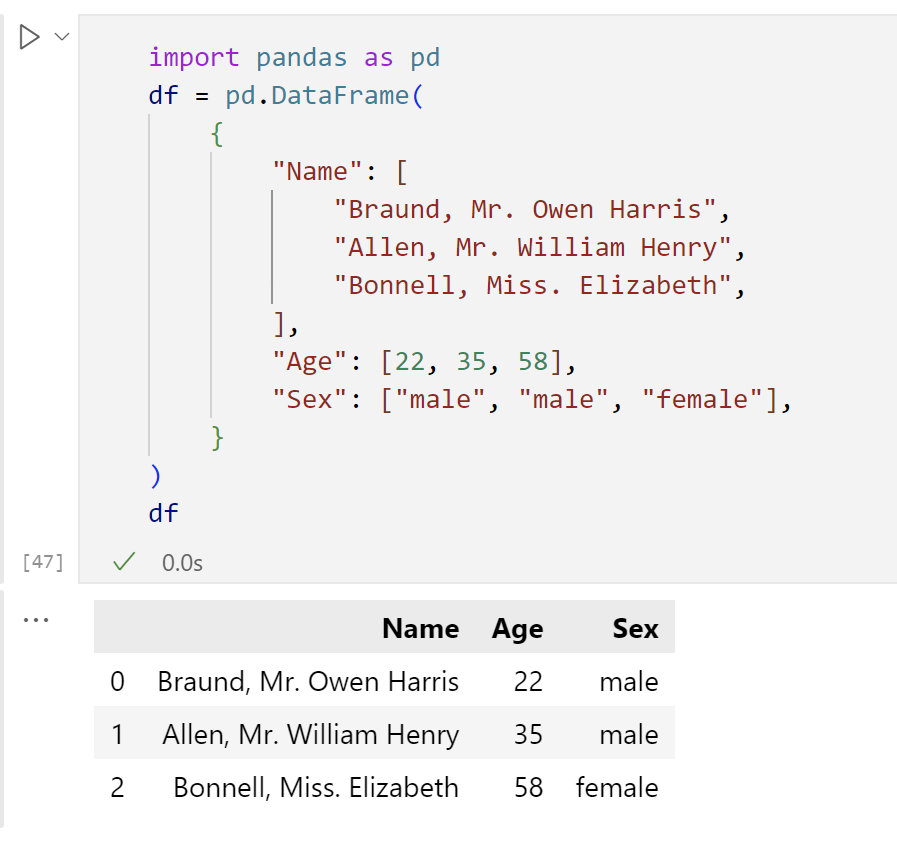
选择pandas DataFrame的单个列时,结果是一个pandas Series,选择该列:在方括号[]中使用列标签。
读取数据
从csv文件读取数据:
pd.read_csv('data_path.csv')从Excel文件读取数据:
pd.read_excel('data_path.xlsx')查看数据
- df.head(n): 查看前n行,默认前5行。
- df.tail(n): 查看最后n行,默认最后5行。
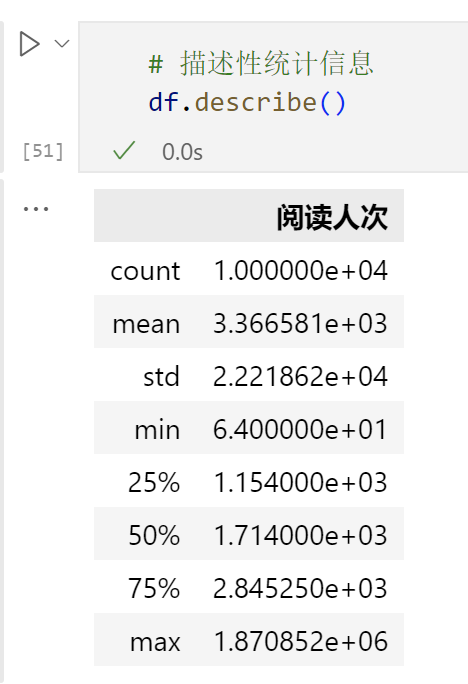
- df.describe(): 提供数据的基本统计摘要。
- df.info(): 显示DataFrame的信息概览。
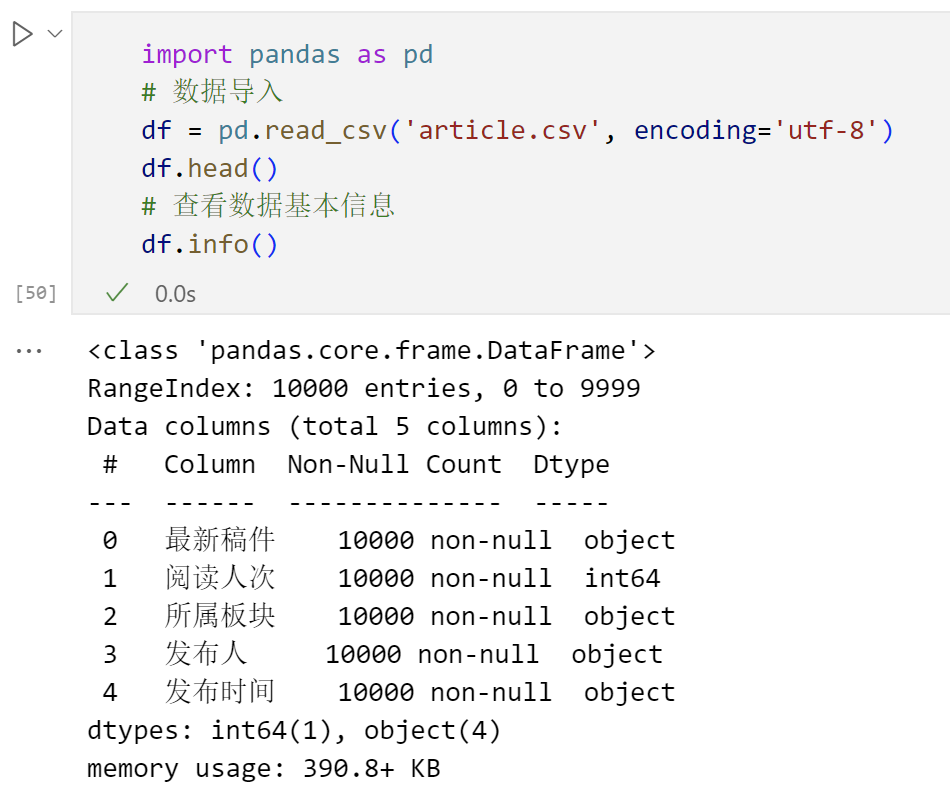
数据选择
1. 方括号[]选择单列或多列
# 单列
df['col1']
# 多列
df[['col1', 'col2']]2. 条件表达式选择,在方括号内部
df[df['col1'] > 33]
df[df['col2'].isin(['v1', v2])]3. 按标签选择:df.loc[row, col]
有效输入:单个标签,标签列表或数组,切片对象,例:
df.loc[1, 'col'] # 选择行索引为1,列标签为'col'的数据
df.loc[[1,2,4], 'col'] # 选择行索引为1,2,4,列标签为'col'的数据
df.loc[[1,2,4], ['col1', 'col2']] # 选择行索引为1,2,4,列标签为'col1'和'col2'的数据
df.loc[1:3, 'col'] # 行切片,包头包尾
df.loc[1:3, 'col1':'col3'] # 多行多列,包头包尾4. 按位置选择:df.iloc[row, col]
有效输入:一个整数,一个整数列表或数组,一个带有整数的切片对象
df.iloc[2,3] # 获取单个元素,行索引2,列索引3的数据
df.iloc[[1,3,5], [0,1]] # 获取多行多列,行索引1,3,5 列索引0,1的数据
# 切片选择
df.iloc[2:5, 0:3] # 包头不包尾处理缺失值
df.dropna(): 删除含有缺失值的行或列
常用的参数及其说明:
- axis:指定是要删除行还是列中的 NaN 值。
如果 axis=0 或 axis='index',则删除包含 NaN 的行。
如果 axis=1 或 axis='columns',则删除包含 NaN 的列。
- how:指定如何判断哪些行或列应该被删除。
'any':如果至少有一个 NaN,则该行/列会被删除(默认值)。
'all':只有当所有值都是 NaN 时才删除该行/列。
thresh:设置每行或每列中非空值的最小数量。如果某行或某列的非空值少于这个阈值,则该行/列将被删除。
- subset:指定 DataFrame 的一个子集(列),只在这个子集中检查 NaN 值。
- inplace:如果设置为 True,则直接修改原始 DataFrame;如果为 False(默认),则返回一个新的 DataFrame 并保留原 DataFrame 不变。
df.fillna(value): 用特定值填充缺失值。
数据清洗
删除不需要的列.drop
df.drop(columns=['col_name']): 删除'col_name'列
重命名列.rename
df.rename(columns={'old_name': 'new_name'})
检测重复值
df.duplicated(subset=['col_name'])
去除重复行
df.drop_duplicates(subset=['所属板块'], keep='first')
keep属性:first/last/False:保留每个重复组中
apply函数
apply函数允许用户沿着DataFrame的某个轴应用自定义函数
DataFrame.apply(func, axis=0)
- func:一个函数
- axis:0沿列方向,1沿行方向应用
Series.apply(func, axis=0)
例:
新增一列,是col列数据*2
df['new_col'] = df['col'].apply(lambda x: x*2)分组与聚合
groupby和agg按照指定列进行分组,然后进行聚合统计
# 按照'col1'列分组,统计分组后'col2'列的平均值
df.group('col1')['col2'].mean()
df.groupby('所属板块').agg({'阅读人次': 'mean', '发布时间':'min'})合并数据
pd.concat([df1, df2]):垂直(默认,axix=0)或水平连接(axis=1)两个DataFrame
pd.merge(left, right, on='key'): 内连接或外连接两个DataFrame