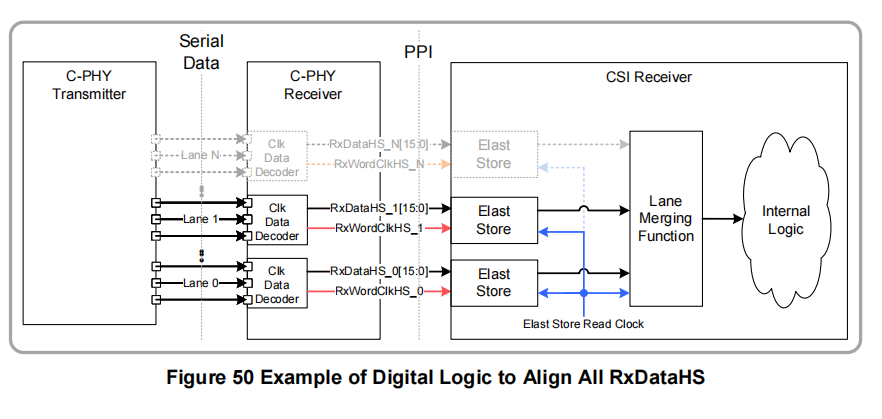
示例代码:
from scipy.stats import norm
# 定义参数
p0 = 0.10 # 标称次品率
alpha = 0.05 # 95% 信度下的显著性水平
beta = 0.10 # 90% 信度下的显著性水平
E = 0.01 # 允许的误差范围
# 计算95%信度下的样本量
Z_alpha_2 = norm.ppf(1 - alpha / 2)
n_95 = ((Z_alpha_2 * (p0 * (1 - p0))**0.5) / E)**2
# 计算90%信度下的样本量
Z_beta_2 = norm.ppf(1 - beta / 2)
n_90 = ((Z_beta_2 * (p0 * (1 - p0))**0.5) / E)**2
# 打印结果
print(f"在95%信度下,所需的最小样本量为: {int(n_95)}")
print(f"在90%信度下,所需的最小样本量为: {int(n_90)}")
# 假设检验函数
def hypothesis_test(sample_size, p0, alpha):
# 生成样本数据(这里使用p0作为实际次品率进行模拟)
samples = [1 if norm.rvs() < p0 else 0 for _ in range(sample_size)]
sample_mean = sum(samples) / sample_size
# 计算95%置信区间
Z = norm.ppf(1 - alpha / 2)
lower_bound = sample_mean - Z * (p0 * (1 - p0) / sample_size)**0.5
upper_bound = sample_mean + Z * (p0 * (1 - p0) / sample_size)**0.5
# 判断是否接收
if lower_bound > p0:
return "接收零配件"
else:
return "拒收零配件"
# 进行95%信度下的假设检验
result_95 = hypothesis_test(int(n_95), p0, alpha)
print(f"在95%信度下,假设检验结果: {result_95}")
# 进行90%信度下的假设检验
result_90 = hypothesis_test(int(n_90), p0, beta)
print(f"在90%信度下,假设检验结果: {result_90}")可视化代码:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 定义参数
p0 = 0.10 # 标称次品率
alpha = 0.05 # 95% 信度下的显著性水平
beta = 0.10 # 90% 信度下的显著性水平
E = 0.01 # 允许的误差范围
# 计算95%信度下的样本量
Z_alpha_2 = norm.ppf(1 - alpha / 2)
n_95 = ((Z_alpha_2 * (p0 * (1 - p0))**0.5) / E)**2
# 计算90%信度下的样本量
Z_beta_2 = norm.ppf(1 - beta / 2)
n_90 = ((Z_beta_2 * (p0 * (1 - p0))**0.5) / E)**2
# 样本量与置信区间宽度的关系
sample_sizes = np.arange(50, 1000, 50)
ci_widths_95 = [norm.ppf(1 - alpha / 2) * np.sqrt(p0 * (1 - p0) / size) for size in sample_sizes]
ci_widths_90 = [norm.ppf(1 - beta / 2) * np.sqrt(p0 * (1 - p0) / size) for size in sample_sizes]
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, ci_widths_95, label='95% CI Width')
plt.plot(sample_sizes, ci_widths_90, label='90% CI Width')
plt.xlabel('Sample Size')
plt.ylabel('Confidence Interval Width')
plt.title('Sample Size vs. Confidence Interval Width')
plt.legend()
plt.grid(True)
plt.show()
# 假设检验结果的模拟
def simulate_hypothesis_test(p, sample_sizes, alpha):
results = []
for size in sample_sizes:
samples = [1 if np.random.random() < p else 0 for _ in range(size)]
sample_mean = sum(samples) / size
Z = norm.ppf(1 - alpha / 2)
lower_bound = sample_mean - Z * np.sqrt(p * (1 - p) / size)
upper_bound = sample_mean + Z * np.sqrt(p * (1 - p) / size)
results.append((lower_bound > p0).any())
return results
# 模拟不同次品率下的决策结果
p_rates = np.linspace(0.05, 0.20, 10) # 次品率从5%到20%
results_95 = [simulate_hypothesis_test(p, [int(n_95)] * 1000, alpha).count(True) / 1000 for p in p_rates]
results_90 = [simulate_hypothesis_test(p, [int(n_90)] * 1000, beta).count(True) / 1000 for p in p_rates]
plt.figure(figsize=(10, 6))
plt.plot(p_rates, results_95, label='95% CI Decision', marker='o')
plt.plot(p_rates, results_90, label='90% CI Decision', marker='o')
plt.xlabel('True Defect Rate')
plt.ylabel('Proportion Accepted')
plt.title('Hypothesis Test Decision Simulation')
plt.legend()
plt.grid(True)
plt.show()可视化:
- 样本量与置信区间宽度的关系:展示不同样本量下,95%和90%置信区间的宽度变化。

- 假设检验结果的模拟:模拟多次抽样,展示在不同次品率下,95%和90%置信水平的决策结果。

本次竞赛相关思路会在博客园优先更新,可关注博主提前获取
原文链接:https://www.cnblogs.com/qimoxuan/articles/18401461