Multi-Lane Distribution and Merging:
CSI-2 是一个通道可扩展的规范。对于需要比单个数据通道提供更多带宽的应用,或者那些希望避免高时钟频率的应用,可以通过增加数据通道的数量来扩展数据路径,从而近似线性地提高总线的峰值带宽。为了确保使用多个数据通道的主机处理器和外设之间的兼容性,在更高层数据与串行比特或符号流之间的映射被明确定义。
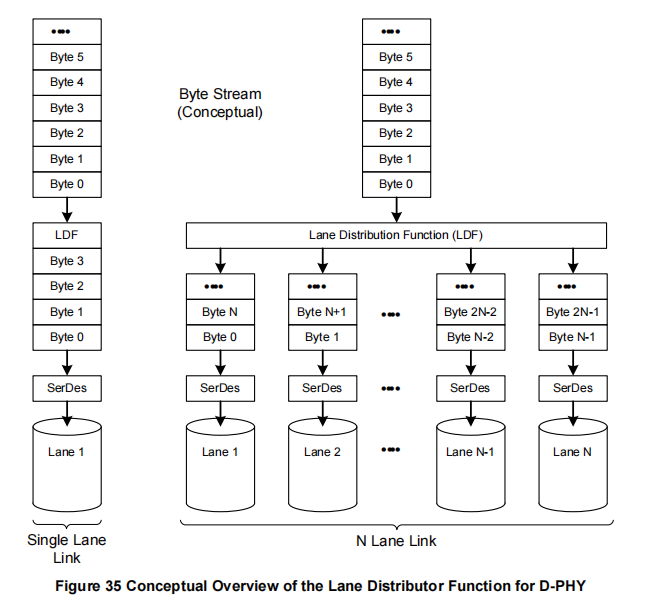
概念上,在物理层和更高功能层之间存在一个处理多通道配置的层。正如图35和图36所示,分别对应D-PHY和C-PHY物理层选项,CSI-2发送器包含一个通道分配功能(LDF-Lane Distribution Function),该功能接受来自低级协议层的包字节序列,并将它们分配到N个通道中,每个通道是独立的物理层逻辑(如串行器等)和传输电路单元。
-
单通道链路(Single Lane Link)
● 左侧展示了一个单通道链路的流程:
○ 字节流(Byte Stream):表示由多个字节(Byte 0, Byte 1, Byte 2, 等)组成的数据流,按顺序从高到低排列。
○ 通道分配功能(LDF):在单通道情况下,LDF功能将数据直接传送给一个通道,并保持字节的顺序不变(Byte 0, Byte 1, Byte 2,...)。
○ SerDes(串行器/解串器):负责将LDF分配的并行字节流转换为串行数据流,并将其发送到通道1进行传输。
-
多通道链路(N Lane Link)
● 右侧展示了一个具有多个通道(N个通道)的链路流程:
○ 字节流(Byte Stream):同样由多个字节组成的数据流。
○ 通道分配功能(LDF):在多通道情况下,LDF功能将字节流按照一定顺序分配到多个通道中进行并行传输。具体来说,LDF将字节按顺序依次分发到每个通道,举例:
■ 通道1:负责传输 Byte 0, Byte N, Byte 2N 等字节;
■ 通道2:负责传输 Byte 1, Byte N+1, Byte 2N+1 等字节;
■ 依此类推,每个通道都分配特定的字节序列。○ SerDes:每个通道有独立的SerDes模块,用于将LDF分配的字节流并行转换为串行数据流,并通过各自的通道进行传输。
-
通信流程总结
● 单通道情况下,所有字节按顺序传输到一个通道上,数据流没有分散;
● 多通道情况下,数据流被均匀分配到多个通道上,以实现更高的并行传输效率。每个通道都通过SerDes模块将并行的字节流转换为串行信号,并同步发送。
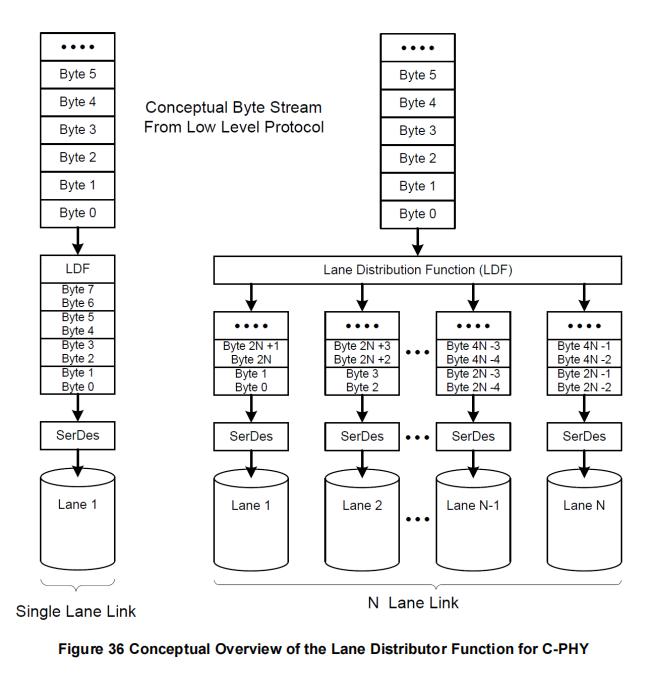
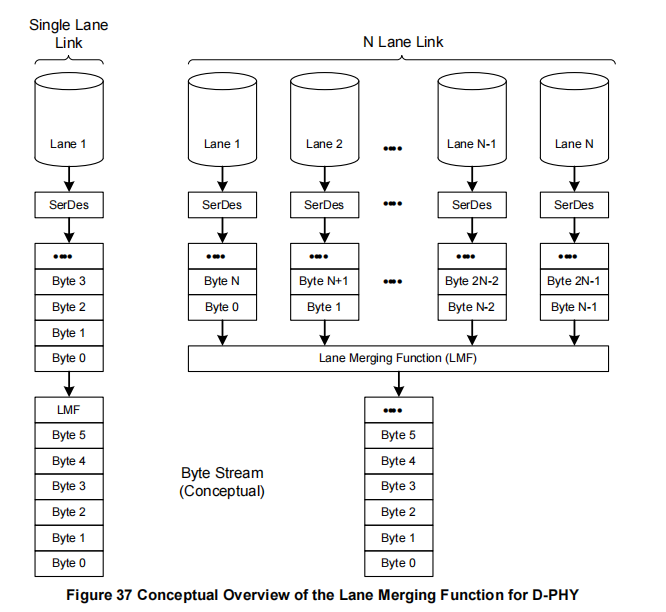
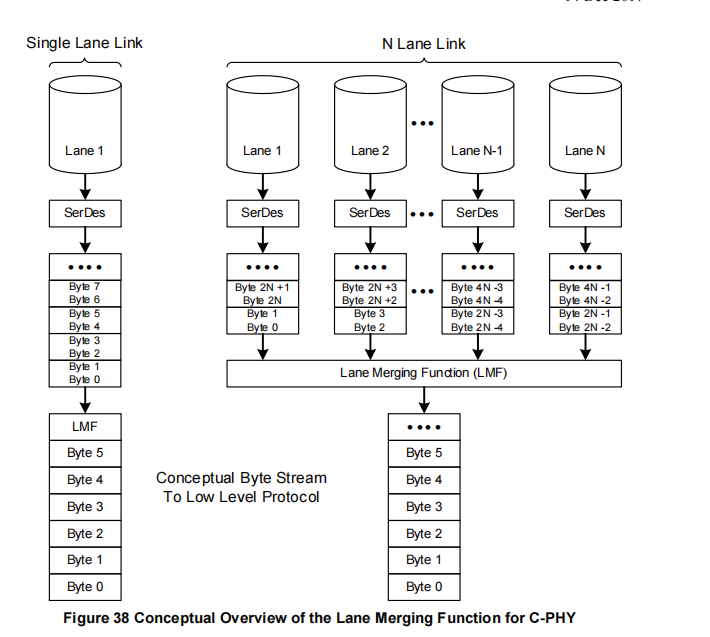
同样,正如图37和图38所示,分别对应D-PHY和C-PHY物理层选项,CSI-2接收器包含一个通道合并功能(LMF-Lane Merging Function),该功能从N个通道收集接收到的字节,并将它们合并成完整的包,再传递给接收器的低级协议层中的包解构器。
-
单通道链路(Single Lane Link)
● 在左侧展示了单通道链路的流程:
○ 通道1(Lane 1):数据通过单一通道传输。
○ SerDes(串行器/解串器):负责将接收到的串行数据流转换为并行数据流,并将其输出为字节流。
○ 字节流(Byte Stream):在单通道情况下,字节流依次为 Byte 0, Byte 1, Byte 2,...,不需要进一步合并。
○ 通道合并功能(LMF):在单通道情况下,LMF直接将接收到的字节流传递至上层协议处理,不需要进行数据合并。
-
多通道链路(N Lane Link)
● 在右侧展示了多通道链路的流程:
○ 多通道数据接收:N个通道同时接收不同字节的数据流。每个通道通过独立的SerDes模块进行数据的串并行转换,得到相应的字节:
■ 通道1:接收并转换 Byte 0, Byte N,...。
■ 通道2:接收并转换 Byte 1, Byte N+1,...。
■ 通道N:接收并转换 Byte N-1, Byte 2N-1,...。○ 通道合并功能(LMF):将来自不同通道的字节重新合并为连续的字节流。LMF根据每个通道接收到的字节,按顺序排列出完整的数据包,例如:
■ Byte 0, Byte 1, ..., Byte N-1, Byte N, ..., 形成完整的字节流。○ 字节流(Byte Stream):合并后的字节流传输至高层协议处理。
-
通信流程总结
● 单通道情况下,数据按顺序通过单个通道传输,并不需要进行字节的合并,LMF仅将接收到的字节直接传递。
● 多通道情况下,LMF从多个通道接收不同字节的数据,将它们按照正确的顺序合并为一个完整的字节流,传递至上层协议处理。
通道分配器接受任意字节长度的数据传输,缓冲 Nb 个字节(其中 N 为通道数,b 为 1 或 2,分别对应 D-PHY 或 C-PHY 物理层选项),然后以并行方式通过 N 个通道发送 Nb 个字节的组,每个通道接收 b 个字节。在发送数据之前,所有通道并行执行 SoT 序列,向对应的接收单元指示数据包的第一个字节即将开始传输。完成 SoT 之后,各通道通过轮询的方式并行发送来自第一个数据包的连续字节组。
Lane Distribution for the D-PHY Physical Layer Option:
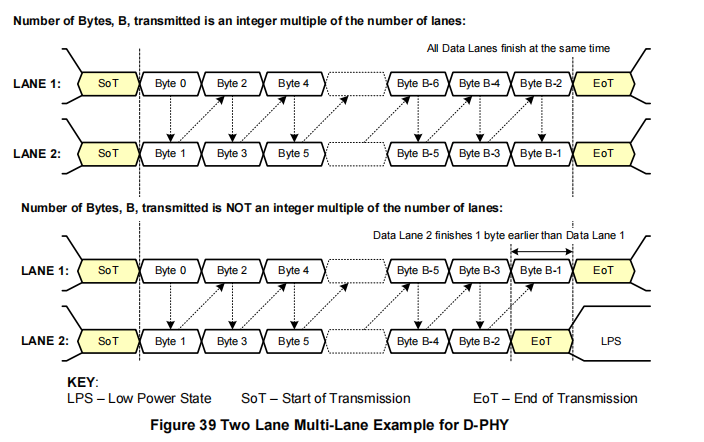
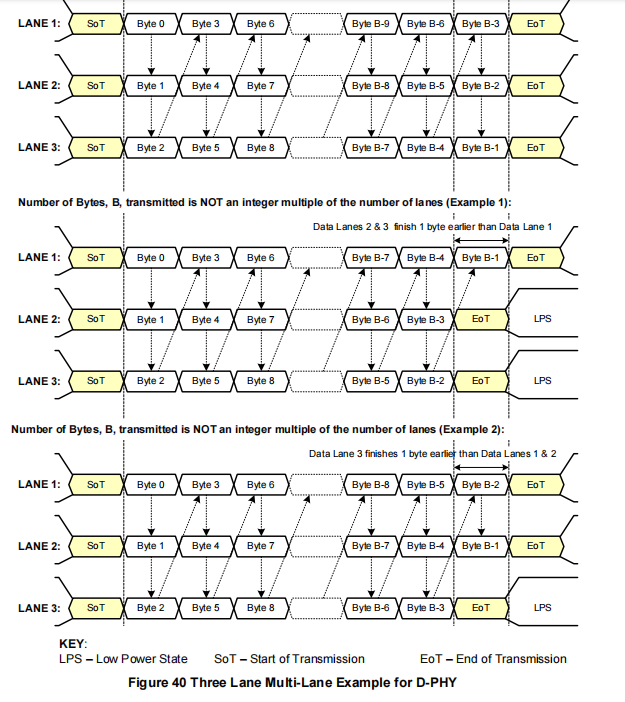
图39、图40、图41和图42展示了几个示例:
-
2通道系统(图39):数据包的字节0发送到通道1,字节1发送到通道2,字节2发送到通道1,字节3发送到通道2,字节4发送到通道1,依此类推。
-
3通道系统(图40):数据包的字节0发送到通道1,字节1发送到通道2,字节2发送到通道3,字节3发送到通道1,字节4发送到通道2,依此类推。
-
N通道系统(图41):数据包的字节0发送到通道1,字节1发送到通道2,字节N-1发送到通道N,字节N发送到通道1,字节N+1发送到通道2,依此类推。
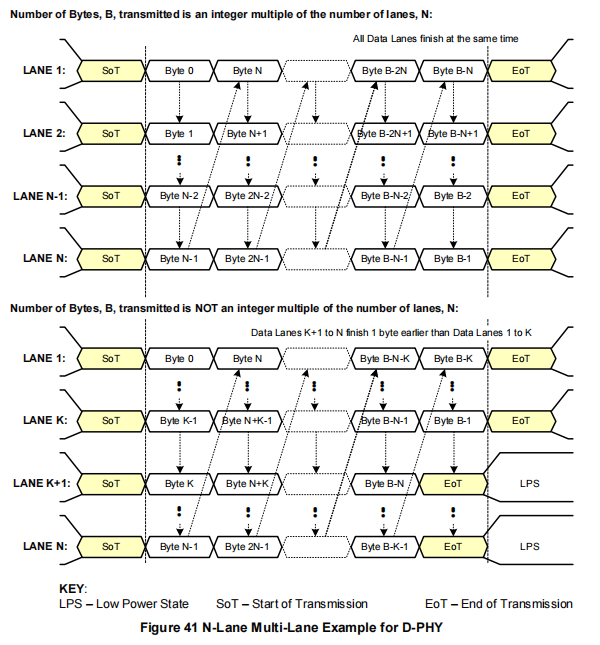
-
N通道系统(图42),当N > 4时进行短包(4字节)传输:数据包的字节0发送到通道1,字节1发送到通道2,字节2发送到通道3,字节3发送到通道4,通道5到通道N不接收字节,保持在LPS状态。

在传输结束时,可能会有“多余”的字节,因为总字节数可能不是通道数量N的整数倍。某些通道可能会比其他通道更早发送完它们的最后一个字节。当通道分配器缓冲最后一组少于N个字节的数据并并行发送到N个数据通道时,它会在没有数据可传输的通道中取消“有效数据”信号。对于发送4字节短包且具有4个以上数据通道的系统,那些没有接收字节进行传输的通道应保持在LPS状态。
每个D-PHY数据通道独立运行。
尽管多个通道都会同时以并行的“开始包”代码启动,但它们可能在不同的时间完成传输,且可能相差一个周期(字节)发送“结束包”代码。
链路接收端的N个PHY将并行接收的字节收集起来,并将它们传递给通道合并层。通道合并层会重构传输中原始的字节序列,然后将这些字节分割为独立的数据包,以供包解码层处理。
Lane Distribution for the C-PHY Physical Layer Option:
图43和图44展示了几个示例:
-
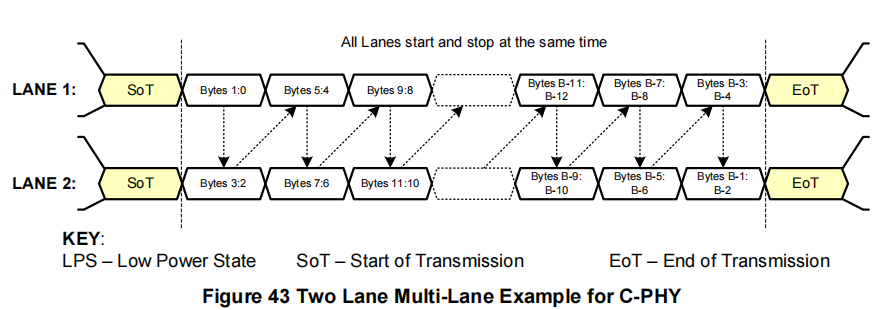
2通道系统(图43):数据包中的字节1和字节0作为一个16位字发送到通道1的C-PHY模块,字节3和字节2发送到通道2,字节5和字节4发送到通道1,字节7和字节6发送到通道2,字节9和字节8发送到通道1,依此类推。
-
3通道系统(图44):数据包中的字节1和字节0作为一个16位字发送到通道1的C-PHY模块,字节3和字节2发送到通道2,字节5和字节4发送到通道3,字节7和字节6发送到通道1,字节9和字节8发送到通道2,依此类推。
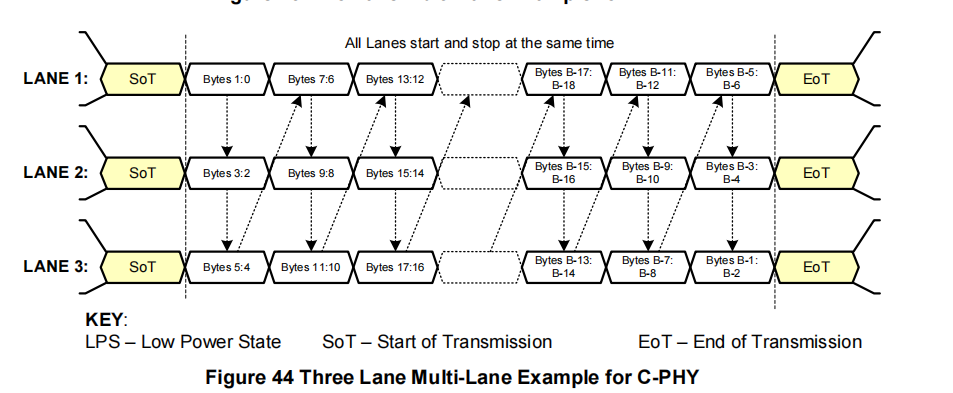
图45展示了适用于N通道系统(N ≥ 1)的标准行为:数据包中的字节1和字节0作为一个16位字发送到通道1的C-PHY模块,字节3和字节2发送到通道2,字节2N-1和字节2N-2发送到通道N,字节2N+1和字节2N发送到通道1,依此类推。数据包的最后两个字节B-1和B-2发送到通道N,其中B是数据包的总字节数。
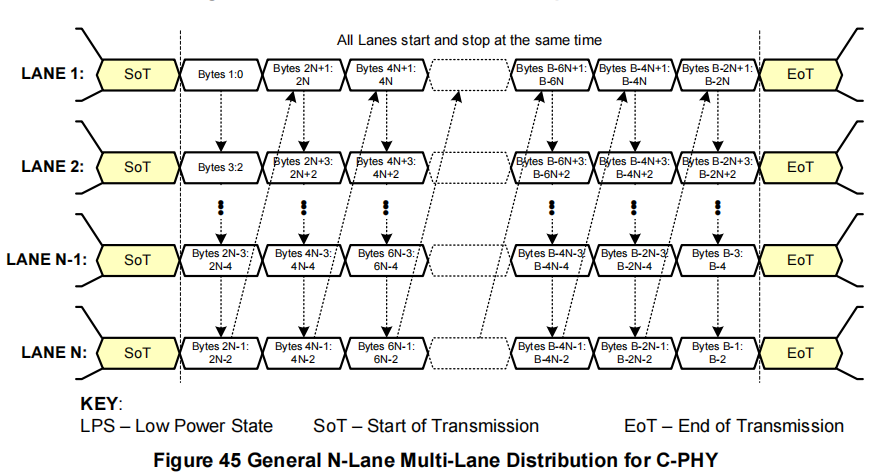
对于N通道发送器,通道n(1 ≤ n ≤ N)的C-PHY模块应发送由低级协议层生成的B字节数据包中的以下{ms byte : ls byte}字节对:{Byte 2*(kN+n)-1 : Byte 2(k*N+n)-2},其中k = 0, 1, 2, …, B/(2N) - 1,Byte 0是数据包中的第一个字节。低级协议层应确保B是2N的整数倍。
也就是说,在数据包传输结束时,不会有“多余”字节,因为总字节数始终是通道数量N的偶数倍。通道分配器在并行发送最后一组2N个字节到N个通道后,会同时取消对所有通道的“有效数据”信号,向每个C-PHY通道模块发出信号,表示它们可以开始EoT(结束传输)序列。
每个C-PHY通道模块独立运行,但所有通道上的数据包传输同时开始和结束。
链路接收端的N个C-PHY接收模块并行收集字节对,并将它们传递到通道合并层。该层重新构建传输中的原始字节序列,之后可以将这些字节分割为独立的数据包,供数据包解码层使用。
Multi-Lane Interoperability(多通道互操作性):
当使用多个数据通道时,通道分配和合并层应通过相机控制接口(CCI)进行可重新配置。
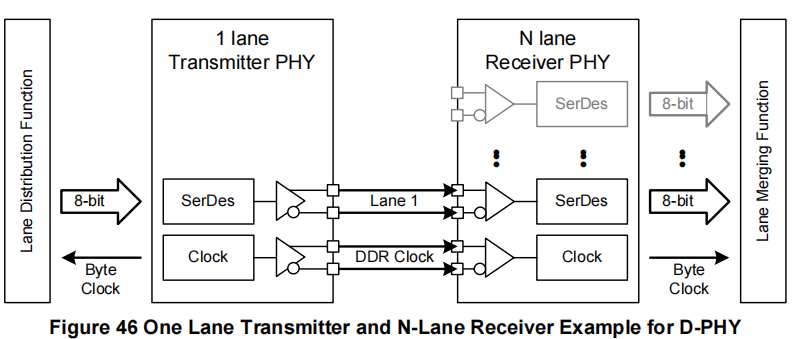
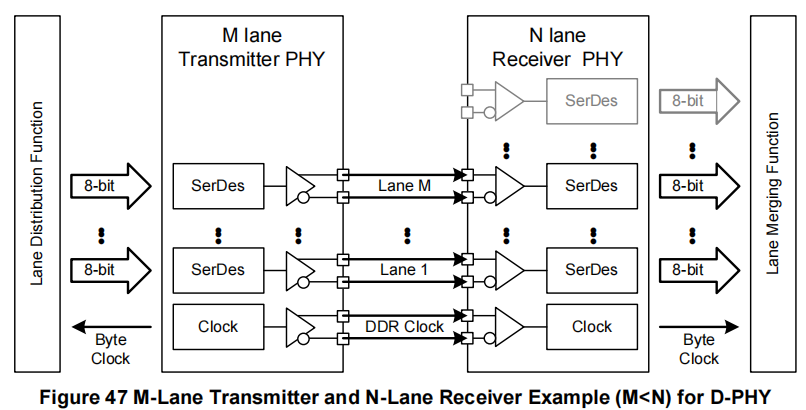
当使用多个数据通道时,通过在CSI-2发送器和接收器内对通道分配和合并层进行CCI配置,N通道接收器应连接到M通道发送器。因此,如果M <= N,具有N个数据通道的接收器应能够与具有M个数据通道的发送器配合使用。同样地,如果M >= N,具有M个通道的发送器应能够与具有N个通道的接收器配合使用。发送器的通道1到M应连接到接收器的通道1到N。
有两种情况:
-
如果M <= N,则不会有性能损失——接收器有足够的数据通道与发送器匹配(见图46和图47)。
-
如果M > N,则可能会出现性能损失(例如,帧率降低),因为接收器的数据通道少于发送器(见图48和图49)。
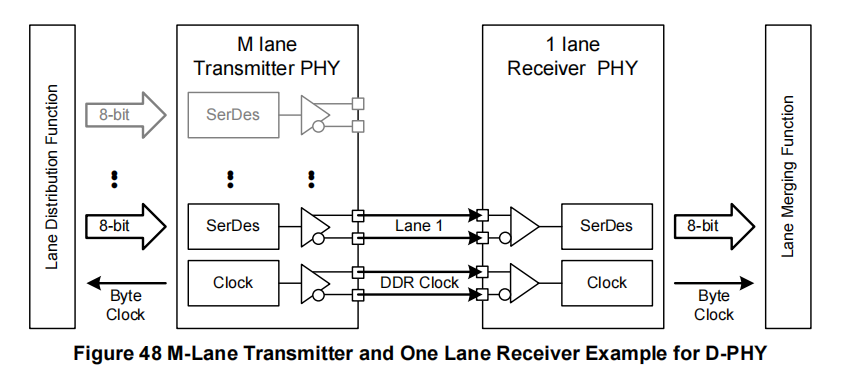
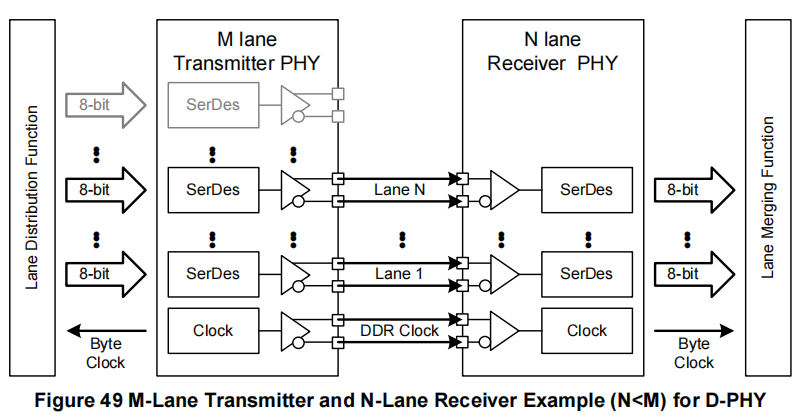
请注意,虽然示例显示的是D-PHY物理层选项,但C-PHY物理层选项处理方式类似,只是没有时钟通道。
C-PHY Lane De-Skew(C-PHY通道去偏):
C-PHY通道去偏指的是在传输过程中,纠正由于不同通道之间时序差异而导致的数据不对齐的过程。去偏功能确保各个通道接收到的数据能够准确同步,从而保证数据包的完整性和一致性。
在C-PHY传输中,由于每个通道可能会受到不同的信号延迟影响,导致数据字节在传输到接收端时发生时序偏差。去偏机制通过调整各个通道的数据接收时间,使数据在接收端能够正确对齐,确保后续数据处理能够顺利进行。
C-PHY规范(MIPI02)中的PPI(PHY Protocol Interface - 物理层协议接口)定义为每个通道定义了一个RxWordClkHS,并未涉及在一个链路中为所有通道使用一个共同的接收RxWordClkHS。图50展示了一种从弹性缓冲器时钟数据的方法,以便将所有的RxDataHS与一个RxWordClkHS对齐(去偏)。
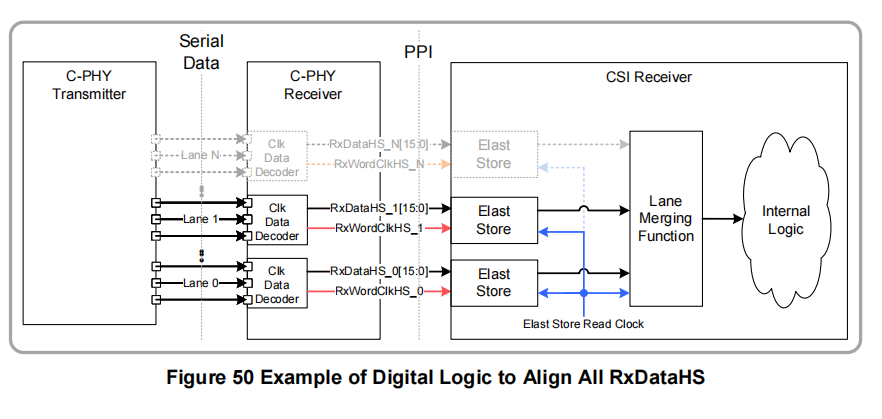
-
C-PHY发送器和接收器
-
C-PHY发送器:发送串行数据,通过多个物理通道(Lane 0 到 Lane N)并行传输数据流。每个通道都有各自的数据信号,并且以高速(HS)模式工作。
-
C-PHY接收器:接收这些来自不同通道的串行数据。每个通道有独立的Clk Data Decoder模块,负责解码从相应通道接收到的高速数据流。
-
时钟对齐机制
-
每个通道的数据通过其对应的解码器进行处理,生成相应的RxDataHS信号(例如,RxDataHS_N[15:0] 表示第N个通道的解码后数据)。这些数据流在不同的通道之间可能存在时序上的偏移。
-
为了解决这些偏移问题,RxWordClkHS_0信号用作主时钟,与所有通道的RxDataHS信号对齐。这个时钟信号通过对弹性缓冲器中的数据进行时钟同步,确保所有通道接收到的数据能够按照相同的时序对齐。
-
弹性缓冲(Elastic Store)
-
每个通道的数据经过解码后,进入弹性缓冲区(Elastic Store)。这个缓冲区的作用是临时存储解码后的数据,并根据主时钟(RxWordClkHS_0)的节奏将数据流同步化。
-
Elast Store Read Clock:这个信号负责从弹性缓冲区中读取已经对齐的数据流,确保这些数据以相同的时间基准传递给后续的处理模块。
-
通道合并功能(Lane Merging Function)
-
对齐后的数据流通过弹性缓冲区的读取时钟进入通道合并功能(Lane Merging Function)。该模块将来自不同通道的数据流合并,形成一个完整的数据包。
-
合并后的数据包传递给内部逻辑进行进一步处理。
-
通信流程总结
-
发送器通过多个物理通道并行发送数据,接收器通过解码器接收每个通道的数据。
-
为了确保多个通道的数据时序对齐,接收器使用RxWordClkHS_0作为统一的时钟基准,通过弹性缓冲区来同步各通道的数据流。
-
最终,合并后的数据被送入到内部逻辑进行处理。