Pytorch多GPU分布式训练代码编写
一、数据并行
1.单机单卡
-
模型拷贝
- model.cuda() 原地操作
-
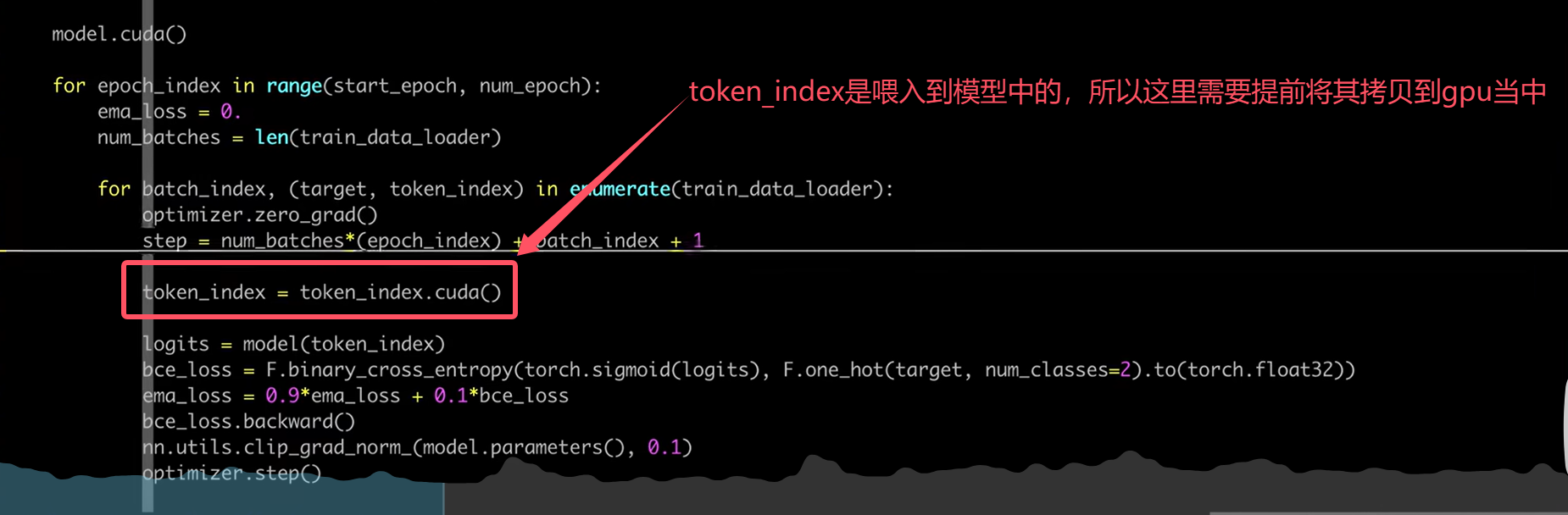
数据拷贝(每步)
- data=data.cuda() 非原地操作
-
基于torch.cuda.is_available()来判断是否可用
-
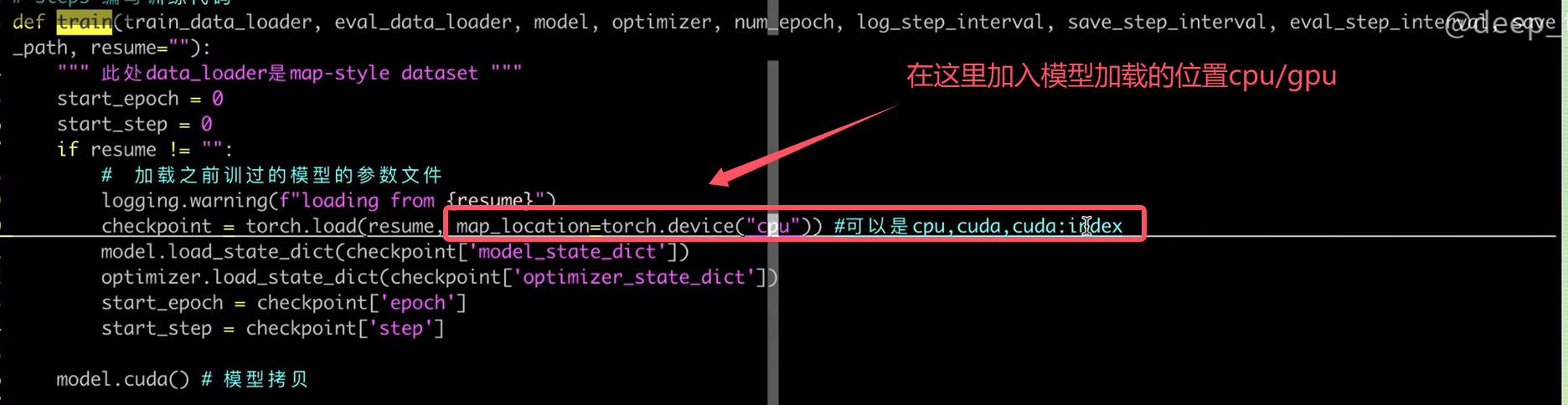
模型保存与加载
- torch.save 来保存模型、优化器、其他变量
- torch.load(file.pt,map_location=torch.device(“cuda”/“cuda:0”/“cpu”))
实际演示:
-
环境检测
-
代码中操作
if __name__ =="__main__": if torch.cuda.is_available(): logging.warning("Cuda is available!") os.environ["CUDA_VISIBLE_DEVICES"]="0" #指定使用第0号gpu else: logging.warning("Cuda is not available! Exit!") return -
命令行操作
CUDA_VISIBLE_DEVICE="0" python xxx.py
-
-
模型拷贝

-
数据拷贝
-
模型保存与加载
以上便是单机单卡的模型的加载和训练
2.单机多卡
- 检测GPU数目
- torch.cuda.device_count()
- 可用通过命令行CUDA_VISIBLE_DEVICES=”“ 来限制GPU卡的使用
- torch.nn.DataParallel API(已经淘汰)
- 简单一行代码,包裹model即可
- model=DataParallel(model.cuda(),device_ids=[0,1,2,3])
- data=data.cuda()
- 模型保存与加载
- torch.save 注意模型需要调用model.module.state_dict()
- torch.load 需要注意map_location的使用
- 缺点
- 单进程,效率慢
- 不支持多机情况
- 不支持模型并行
- 注意实现
- 此处的【dataloder中】batch_size应该是每个GPU的batch_size的总和
- 简单一行代码,包裹model即可
演示,我们将之前的单卡的程序改造成多卡:
- 检测GPU数量
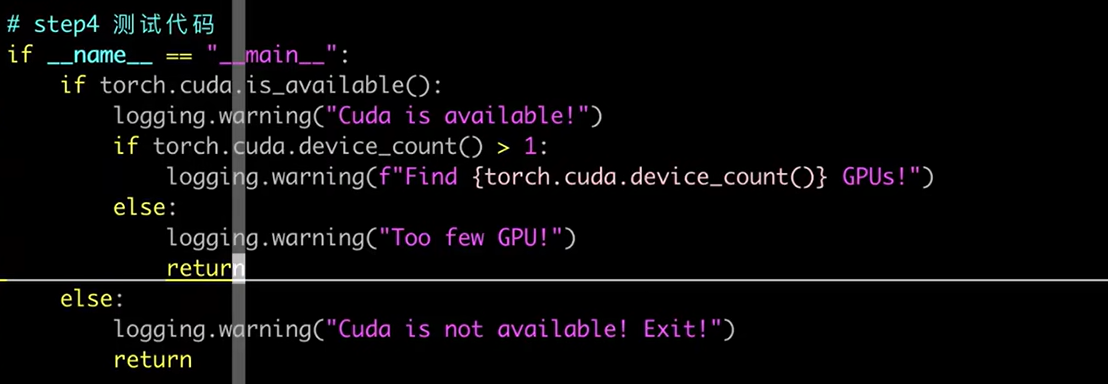
-
用DataParallel来包裹住模型
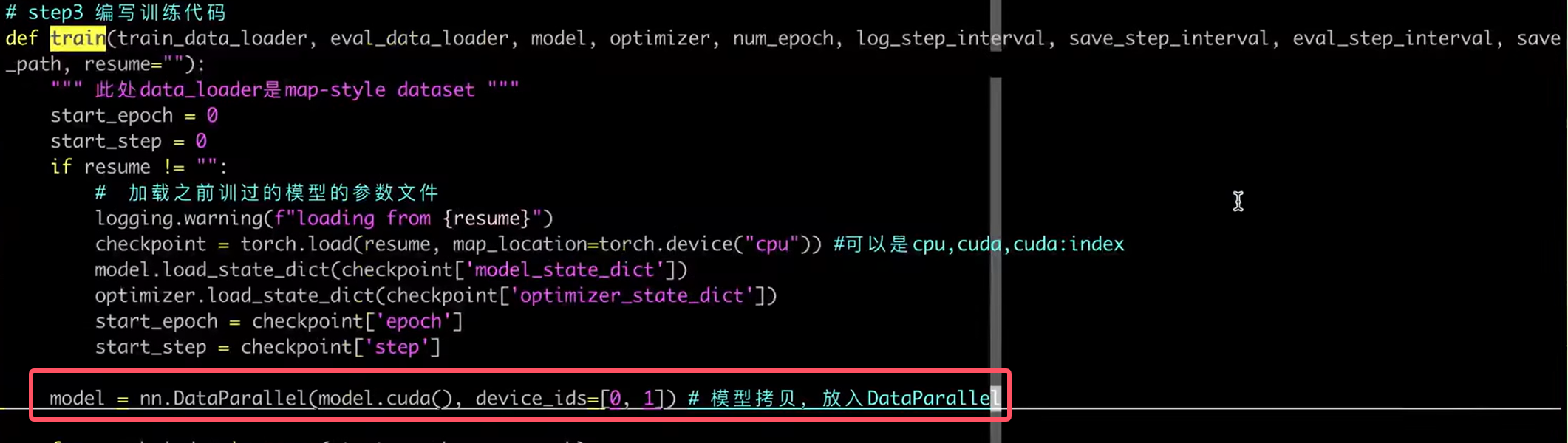
-
save的地方需要修改

-
load时的注意事项
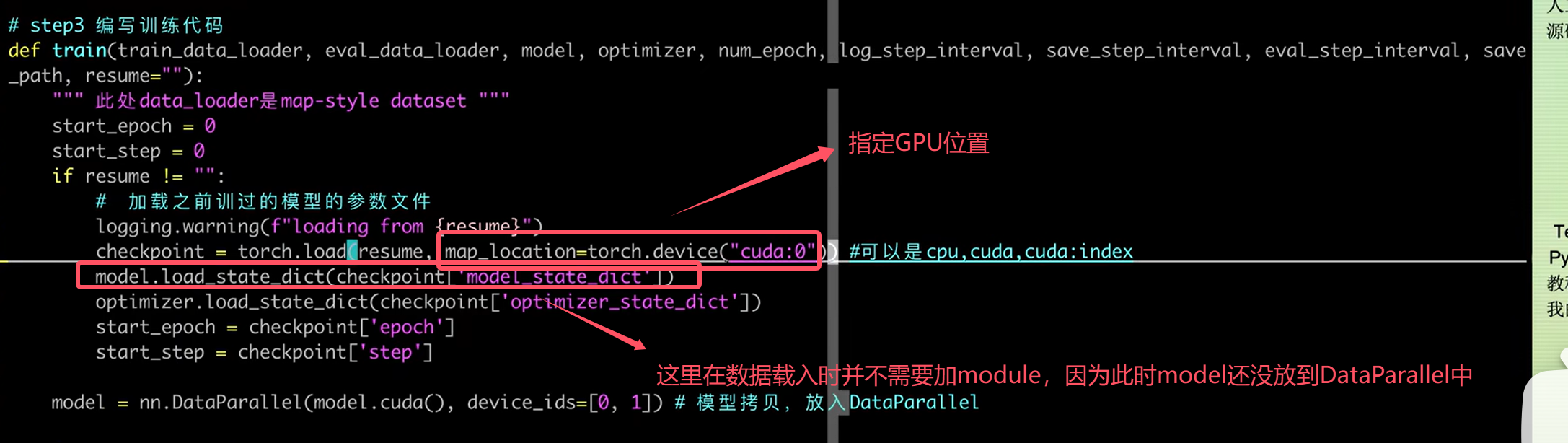
-
batch_size的设置

- torch.nn.parallel.DistributedDataParallel(推荐)
- 多进程执行多卡训练,效率高
- 代码编写流程
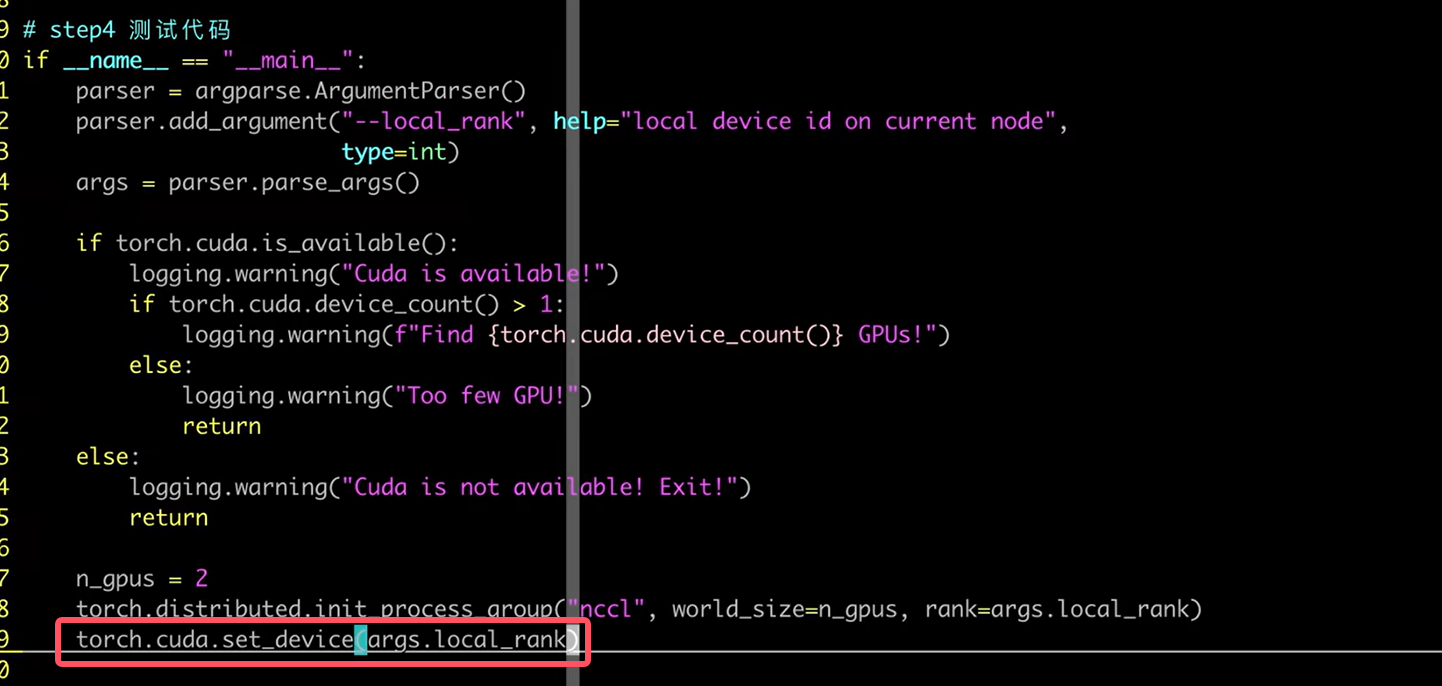
- torch.distributed.init_process_group(“nccl”,world_size=n_gpus,rank=args.local_rank)
- torch.cuda.set_device(args.local_rank) 该语句作用相当于CUDA_VISIBLE_DEVICES环境变量
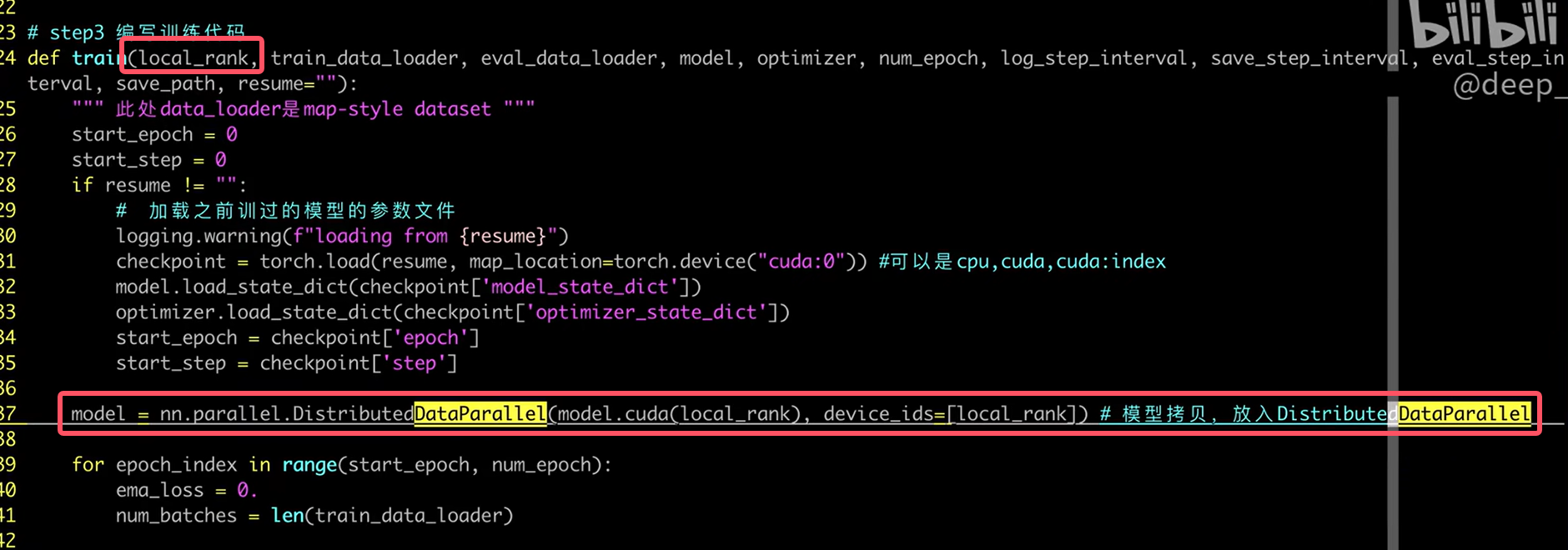
- model=DistributedDataParallel(model.cuda(args.local_rank),device_ids=[args.local_rank])
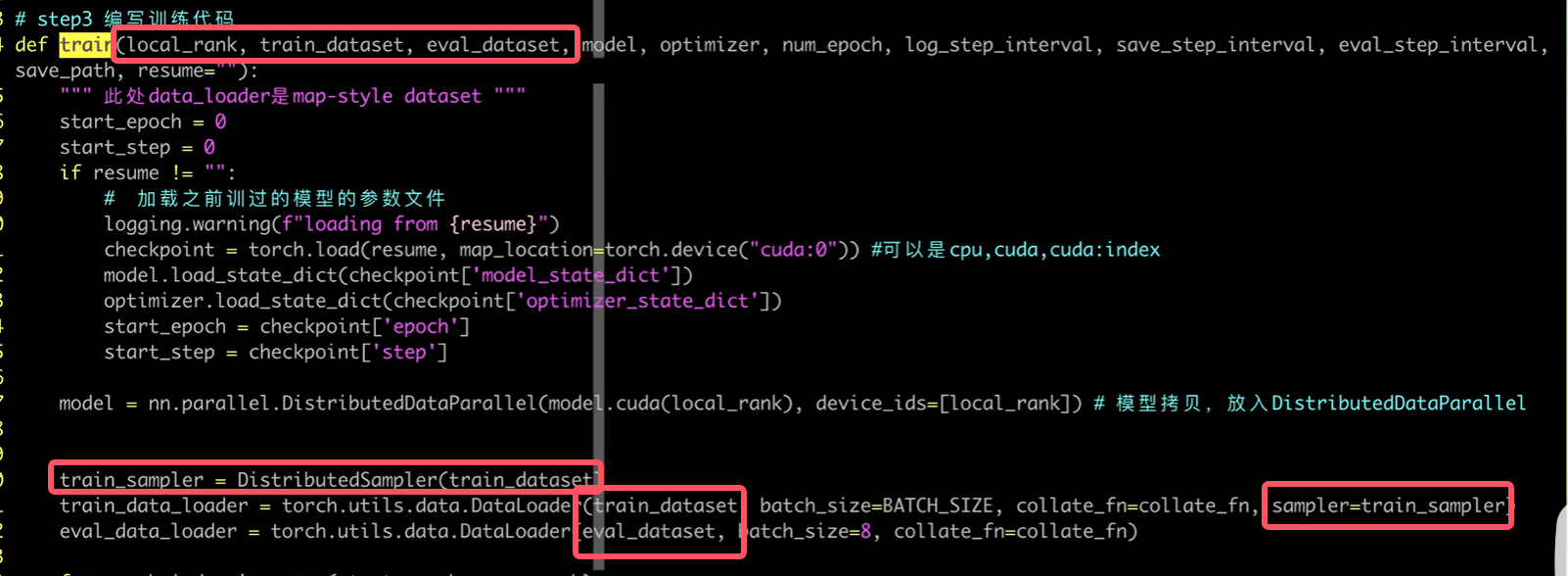
- train_sampler=DistributedSampler(train_dataset)源码位于torch/utils/data/distributed.py
- train_dataloader=DataLoader(…,sampler=train_sampler)
- data=data.cuda(args.local_rank)
- 执行命令
- python -m torch.distributed.launch - - nproc_per_node=n_gpus train.py
- 模型保存与加载
- torch.save 在local_rank=0 的位置进行保存,同样注意调用model.module.state_dict()
- torch.load 注意 map_location
- 注意事项
- train.py 中要有接受local_rank的参数选项,launch会传入这个参数
- 每个进程的batch_size应该是一个GPU所需要的batch_size大小
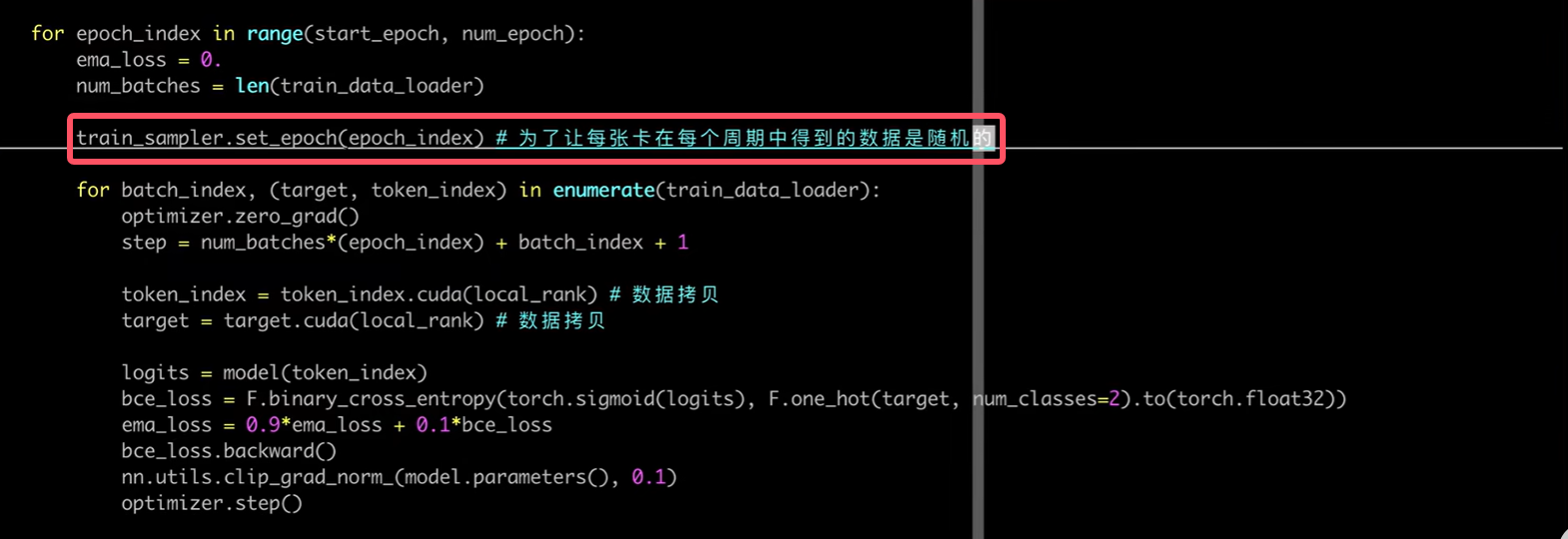
- 在每个周期开始处,调用train_sampler.set_epech(epoch)可以使得数据充分打乱
- 有了sampler,就不要在DataLoader中设置shuffle=True了
演示:
-
指定GPU数量
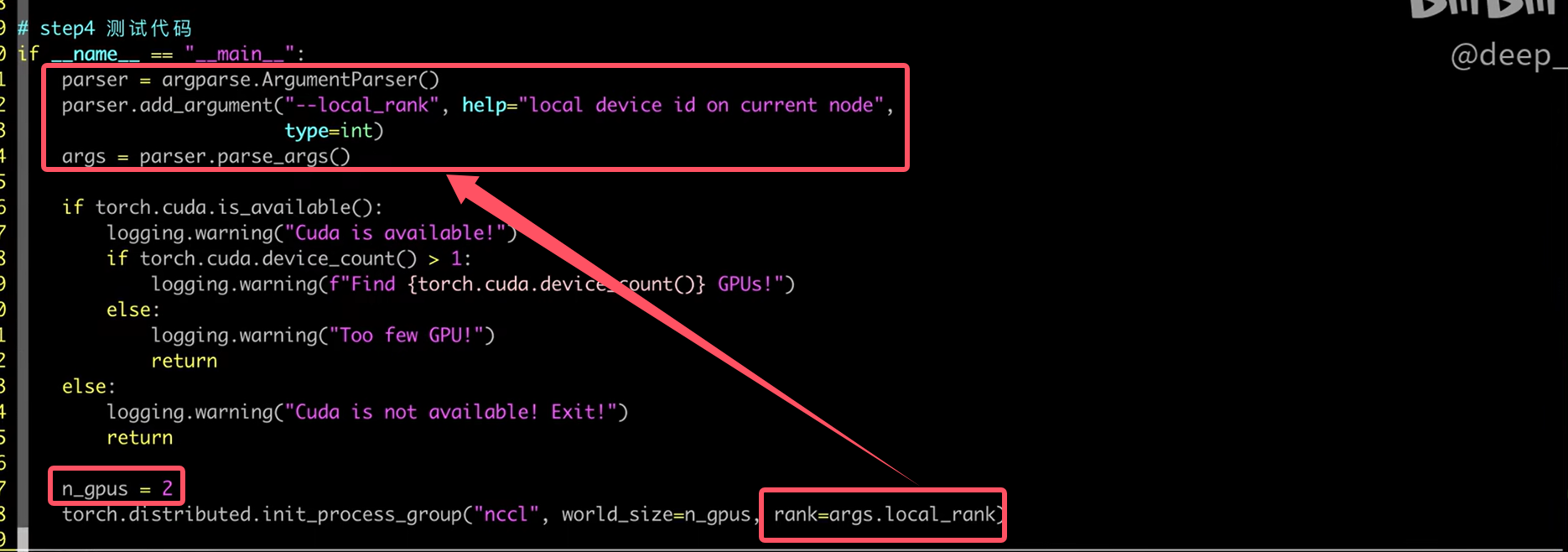
-
设置使用哪几张卡
-
模型拷贝
-
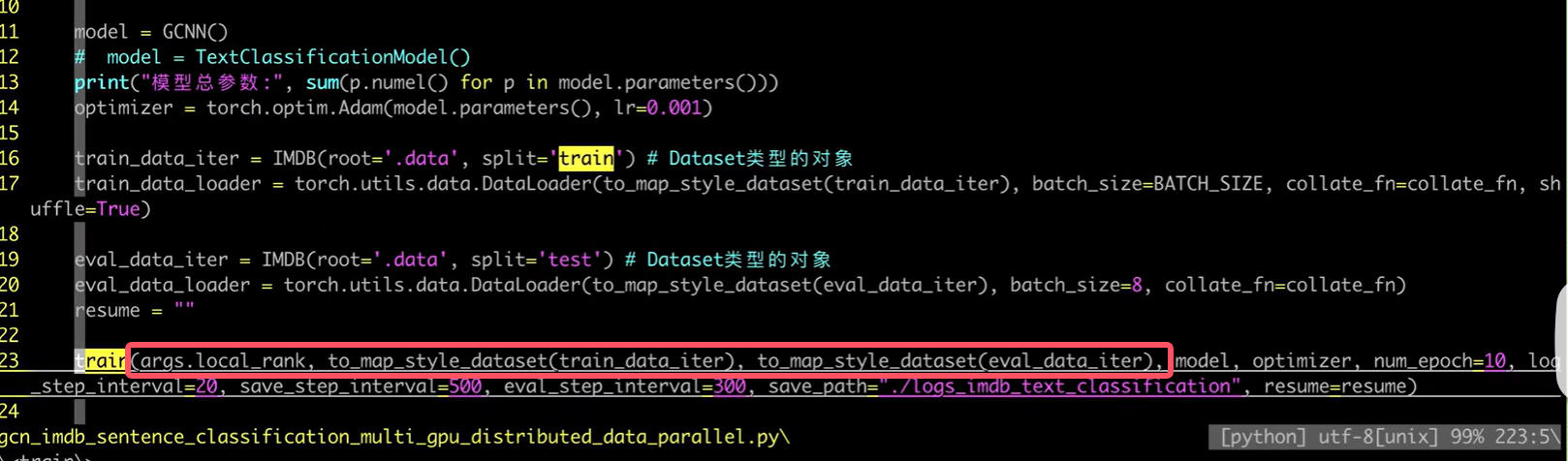
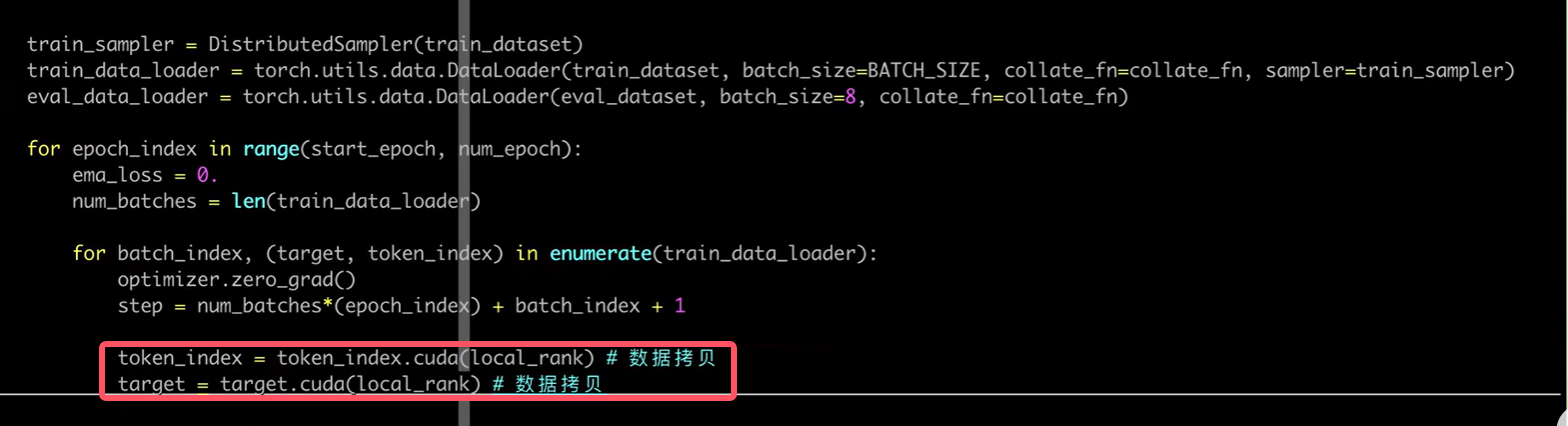
数据拷贝
我们本来传入train函数中的是data_loader,但是train_sampler=DistributedSampler(train_dataset)需要的是dataset,所以我们在向train函数中传递参数的时候需要稍加改动:
-
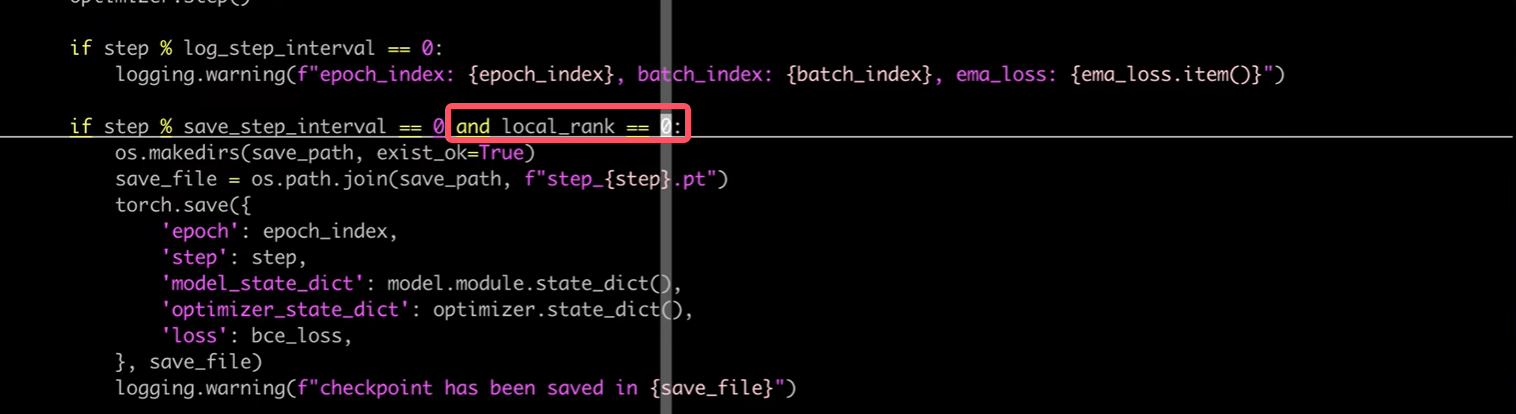
save时注意事项
我们只在编号0的GPU上进行保存
-
每个epoch打乱数据顺序
-
命令行运行

3.多机多卡
- torch.nn.parallel.DistributedDataParallel
- 代码编写流程
- 跟单机多卡一致
- 执行命令(以两节点为例,每个节点处有n_gpus个GPU)
- python -m torch.distributed.launch - -nproc_per_node=n_gpus - -nnodes=2 - -node_rank=0 - -master_addr=“主节点IP” - -master_port=主节点端口 train.py
- python -m torch.distributed.launch - -nproc_per_node=n_gpus - -nnodes=2 - -node_rank=1 - -master_addr=“主节点IP” - -master_port=主节点端口 train.py
- 模型保存与加载
- 同单机多卡基本一致
- 代码编写流程
二、模型并行
1.背景
- 模型参数太大,单个GPU无法容纳,需要将模型的不同层拆分到多个GPU上
2.示例
- 参考:http://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
3.模型保存与加载
- 分多个module进行分别保存与加载(略)