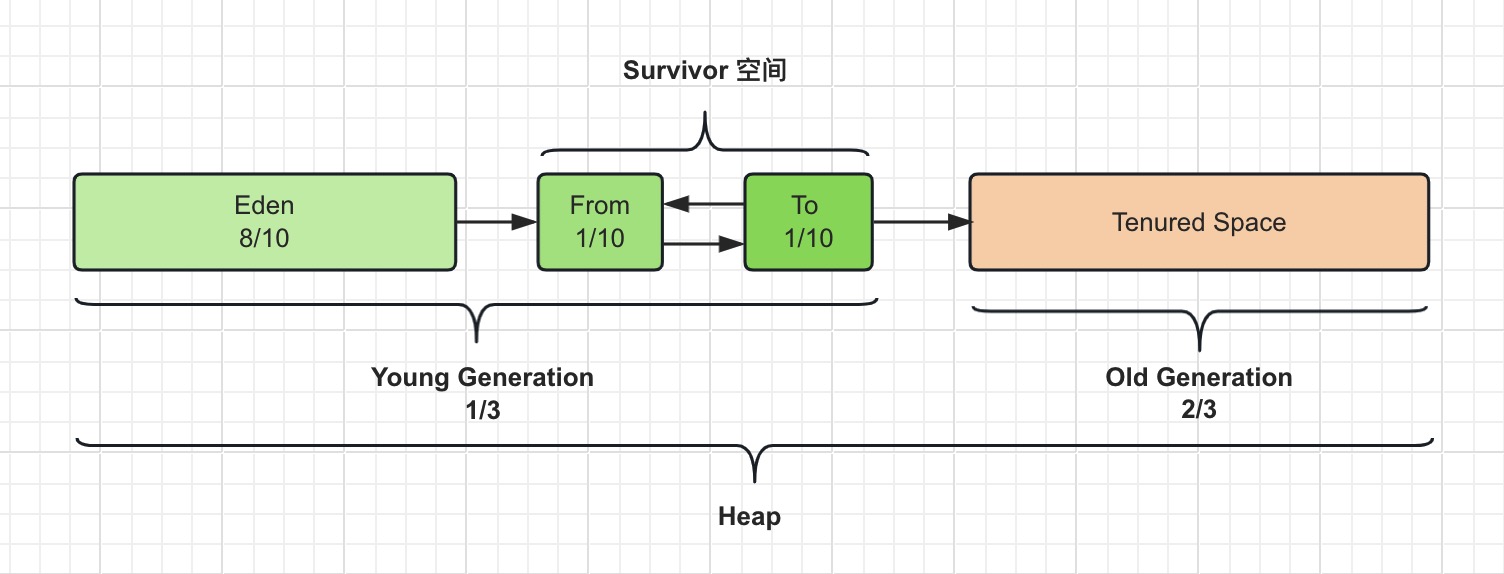
基于CNN卷积神经网络迁移学习的图像识别实现
- 基于CNN卷积神经网络迁移学习的图像识别实现
- 写在前面
- 一,原理介绍
- 迁移学习的基本方法
- 1.样本迁移(Instance based TL)
- 2.特征迁移(Feature based TL)
- 3.模型迁移(Parameter based TL)
- 4.关系迁移(Relation based TL)
- 二. 准备工作
- 1.依赖库安装
- 2.IDE设置
- 3.检查GPU-cuda核心是否可用
- 三. 具体实现
- 1.导入所需软件包
- 2.加载数据
- 3.可视化数据
- 4.训练模型
- 5.可视化模型预测
- 6.卷积神经网络微调
- 7.评估和训练
- 8.神经网络固定特征提取
- 9.自定义测试集测试
- 10.结论
- 1. 微调(Fine-tuning)
- 2. 使用固定特征提取器(Fixed Feature Extractor)
- 总结
- 四.全部代码
- 写在最后
基于CNN卷积神经网络迁移学习的图像识别实现
写在前面
笔者是一名ADAS底层软件工程师。在繁忙的嵌入式软件开发工作之余,我对新技术的保持浓厚兴趣。近年来,深度学习特别是卷积神经网络(CNN)的迅猛发展。尽管我的主要工作集中在车载系统和嵌入式应用,但我深知新技术对未来的巨大潜力。因此,我自学CNN及其在迁移学习中的应用,并希望将自己的学习经验整理成文。这篇博客不仅是我个人学习的总结,也是希望为那些对CNN迁移学习感兴趣的同学提供实用的参考。通过这篇笔记,我将分享一些关键概念和部署经验,包括如何进行模型微调、固定特征提取器的使用方法,以及如何利用训练好的模型进行实际预测。我真诚希望这篇博客能对大家有所帮助,欢迎大家在评论区留言交流,共同探讨和学习!
一,原理介绍
们常常将迁移学习和神经网络的训练上存在误区将其混为一谈。实际上,这两个概念最初是独立的。迁移学习是机器学习的一个分支,其中有许多方法并不依赖于神经网络。然而,随着神经网络的快速发展、强大能力和广泛应用,迁移学习的研究逐渐与神经网络紧密联系起来。
迁移学习(transfer learning)通俗来讲,就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,用成语来说就是举一反三。由于直接对目标域从头开始学习成本太高,我们故而转向运用已有的相关知识来辅助尽快地学习新知识。比如,已经会下中国象棋,就可以类比着来学习国际象棋:已经会编写Java程序,就可以类比着来学习C#;已经学会英语,就可以类比着来学习法语;等等。世间万事万物皆有共性,如何合理地找寻它们之间的相似性,进而利用这个桥梁来帮助学习新知识,是迁移学习的核心问题。
迁移学习的基本方法
1.样本迁移(Instance based TL)
在源域中找到与目标域相似的数据,把这个数据的权值进行调整,使得新的数据与目标域的数据进行匹配。下图的例子就是找到源域的例子3,然后加重该样本的权值,使得在预测目标域时的比重加大。优点是方法简单,实现容易。缺点在于权重的选择与相似度的度量依赖经验,且源域与目标域的数据分布往往不同。

2.特征迁移(Feature based TL)
假设源域和目标域含有一些共同的交叉特征,通过特征变换,将源域和目标域的特征变换到相同空间,使得该空间中源域数据与目标域数据具有相同分布的数据分布,然后进行传统的机器学习。优点是对大多数方法适用,效果较好。缺点在于难于求解,容易发生过适配。

3.模型迁移(Parameter based TL)
假设源域和目标域共享模型参数,是指将之前在源域中通过大量数据训练好的模型应用到目标域上进行预测,比如利用上千万的图象来训练好一个图象识别的系统,当我们遇到一个新的图象领域问题的时候,就不用再去找几千万个图象来训练了,只需把原来训练好的模型迁移到新的领域,在新的领域往往只需几万张图片就够,同样可以得到很高的精度。优点是可以充分利用模型之间存在的相似性。缺点在于模型参数不易收敛。

4.关系迁移(Relation based TL)
假设两个域是相似的,那么它们之间会共享某种相似关系,将源域中逻辑网络关系应用到目标域上来进行迁移,比方说生物病毒传播到计算机病毒传播的迁移。

对于CNN的迁移学习网上有很多大神的讲解都非常精彩,笔者只是简单介绍基本的概念,只要呢让大家明白为什么要进行迁移学习足以,我们还是着手实践,格物致知。
文章推荐:
链接: 微软亚洲研究院对迁移学习问题的回答
二. 准备工作
关于开发环境笔者是用Anaconda+PyCharm,个人认为这样包管理和开发都比较方便,当然因人而异,适合自己就好
1.依赖库安装
我将CondaList打出来,各位对照着版本安装就可以conda list
# Name Version Build Channel
ca-certificates 2024.7.2 haa95532_0 defaults
contourpy 1.1.1 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
filelock 3.15.4 pypi_0 pypi
fonttools 4.53.1 pypi_0 pypi
fsspec 2024.6.1 pypi_0 pypi
importlib-resources 6.4.4 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
libffi 3.4.4 hd77b12b_1 defaults
matplotlib 3.7.5 pypi_0 pypi
mpmath 1.3.0 pypi_0 pypi
networkx 3.1 pypi_0 pypi
numpy 1.24.4 pypi_0 pypi
openssl 3.0.14 h827c3e9_0 defaults
pillow 10.4.0 pypi_0 pypi
pip 24.2 py38haa95532_0 defaults
pyparsing 3.1.4 pypi_0 pypi
python 3.8.19 h1aa4202_0 defaults
python-dateutil 2.9.0.post0 pypi_0 pypi
setuptools 72.1.0 py38haa95532_0 defaults
six 1.16.0 pypi_0 pypi
sqlite 3.45.3 h2bbff1b_0 defaults
sympy 1.13.2 pypi_0 pypi
torchvision 0.19.0 pypi_0 pypi
typing-extensions 4.12.2 pypi_0 pypi
vc 14.40 h2eaa2aa_0 defaults
vs2015_runtime 14.40.33807 h98bb1dd_0 defaults
wheel 0.43.0 py38haa95532_0 defaults
2.IDE设置
其实这就是Anaconda+PyCharm开发的方便之处了,直接新建项目并选择刚刚创建的conda环境就可以愉快的编写代码了。

下面是文件结构,所有的代码都写在main.py里了,所以创建python工程时直接生成一个mian文件就可以
这里是数据集下载链接🔗:数据集下载
模型文件夹需要手动创建一下,以保存原始,微调与固定特征提取器的模型。
D:\PYTHON_CODE_WORKSPACE\BEESORANTS_DL-------------------主文件名
│ main.py-----------------------------------------------全部代码
│ readme.md
├─.idea
├─hymenoptera_data---------------------------------------数据集
│ ├─train-----------------------------------------------训练数据集
│ │ ├─ants
│ │ │ 0013035.jpg
│ │ │ ...
│ │ │ VietnameseAntMimicSpider.jpg
│ │ │
│ │ └─bees
│ │ 1092977343_cb42b38d62.jpg
│ │ ...
│ │ 969455125_58c797ef17.jpg
│ │ 98391118_bdb1e80cce.jpg
│ │
│ └─val------------------------------------------------测试数据集
│ ├─ants
│ │ 10308379_1b6c72e180.jpg
│ │ ...
│ │ Hormiga.jpg
│ │
│ └─bees
│ 1032546534_06907fe3b3.jpg
│ ...
│ 936182217_c4caa5222d.jpg
│ abeja.jpg
│
├─model-------------------------------------------------模型
│ best_model_params.pt
│ finetuned_model_params.pt
│ initial_model_params.pt
│
├─redme_img
│
└─test_img----------------------------------------------自定义测试集
220px-Acrobat.ant1web.jpg
40708249_1415445497609.jpg
3.检查GPU-cuda核心是否可用
在开始编译模型开始预测之前,先看一下cuda核心版本和是否可用
输入nvidia-smi我的CUDA核心版本为12.5,从网上找到对应的pyrorch版本下载即可(但其实我更推荐conda下载)
Tue Sep 3 20:21:43 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 555.99 Driver Version: 555.99 CUDA Version: 12.5 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3060 ... WDDM | 00000000:01:00.0 On | N/A |
| N/A 49C P8 14W / 130W | 252MiB / 6144MiB | 3% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1060 C+G ...1.28.6010\updated_web\WXWorkWeb.exe N/A |
| 0 N/A N/A 6532 C+G ...5n1h2txyewy\ShellExperienceHost.exe N/A |
+-----------------------------------------------------------------------------------------+
打开Anaconda.Nvigator,选择open with python当然你也可以在环境文件夹打开python解释器,依次输入下面指令:
import torch导入torch包
print(torch.__version__)打印torch版本验证是否安装成功
torch.cuda.is_available()验证GPU是否可用,虽然CPU也完全可以完成模型的计算(15-20m),但是GPU则更快(8m)

如果是FALSE的话那大概率是版本不符,如果你遇到了这种情况请从网上搜索一些相关教程,还是很多的,我比较幸运版本都完全匹配,和我一样的配置可以直接照抄我的conda list。
三. 具体实现
下面我会分块讲解每块代码是做什么的,以便你能完全理解代码,全部代码最后附上
1.导入所需软件包
# License: BSD
# Author: Sasank Chilamkurthy
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
from PIL import Image
from tempfile import TemporaryDirectory
cudnn.benchmark = True
plt.ion() # interactive mode
2.加载数据
我们将使用 torchvision 和 torch.utils.data 包来加载 数据。
我们今天要解决的问题是训练一个模型来对蚂蚁和蜜蜂进行分类。我们大约有 120 张蚂蚁和蜜蜂的训练图像。 每个类有 75 个验证图像。通常,这是如果从头开始训练,则要推广的小型数据集。由于我们 在使用迁移学习,我们应该能够合理地进行概括
此数据集是 imagenet 的一个非常小的子集
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
3.可视化数据
def imshow(inp, title=None):
"""Display image for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
运行代码后输出四张图片和标签

4.训练模型
这段代码定义用于训练模型的函数 train_model。
使用通用模型ResNet-18,它首先记录训练开始的时间,然后在每个训练周期(epoch)中,通过迭代训练集和验证集的数据来调整模型的参数。训练过程中,模型在训练阶段被设置为训练模式,在验证阶段被设置为评估模式。每次经过验证阶段后,如果模型在验证集上的准确率比之前最好的一次更好,它会保存当前的模型参数。训练完成后,函数将加载并返回在验证集上表现最好的模型权重。
通用模型 ResNet-18 通常是为了在图像分类任务中利用其强大的特征提取能力。ResNet-18 是一个深度残差网络(Residual Network)
包含 18 层卷积和全连接层。它在 ImageNet 数据集上进行了预训练,因此能够识别和提取图像中的复杂特征。这些预训练的特征可以用于各种
计算机视觉任务,如分类、检测等。下面是如何使用 ResNet-18 的步骤:
1-加载预训练模型:我们可以使用 PyTorch 提供的 torchvision.models 模块来加载一个预训练的 ResNet-18 模型,该模型已经在ImageNet 数据集上训练好了。
2-冻结早期层:根据任务的需要,我们可以选择冻结模型的早期层,只训练最后一层。这意味着前几层的权重保持不变,我们只调整最后一层的权重。
3-修改输出层:ResNet-18 的原始输出层用于 1000 类分类,但我们可能只需要区分更少的类别(例如蜜蜂和蚂蚁)。因此,我们需要替换掉模型的最后一层,使其输出我们需要的类别数量。
4-训练模型:在我们特定的数据集上(例如蜜蜂和蚂蚁的图像数据集)进行训练,通过多轮次的训练调整最后一层的权重,使得模型能够准确地分类新图像。
5-评估模型:在验证集上评估模型的性能,如果表现良好,我们可以保存最优的模型权重。
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
# Create a temporary directory to save training checkpoints
with TemporaryDirectory() as tempdir:
best_model_params_path = os.path.join(tempdir, 'best_model_params.pt')
torch.save(model.state_dict(), best_model_params_path)
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
torch.save(model.state_dict(), best_model_params_path)
print()
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:4f}')
# load best model weights
model.load_state_dict(torch.load(best_model_params_path, weights_only=True))
return model
使用通用模型 ResNet-18 通常是为了在图像分类任务中利用其强大的特征提取能力。ResNet-18 是一个深度残差网络(Residual Network),包含 18 层卷积和全连接层。它在 ImageNet 数据集上进行了预训练,因此能够识别和提取图像中的复杂特征。这些预训练的特征可以用于各种计算机视觉任务,如分类、检测等。
下面是如何使用 ResNet-18 的步骤:
-
加载预训练模型:我们可以使用 PyTorch 提供的
torchvision.models模块来加载一个预训练的 ResNet-18 模型,该模型已经在 ImageNet 数据集上训练好了。 -
冻结早期层:根据任务的需要,我们可以选择冻结模型的早期层,只训练最后一层。这意味着前几层的权重保持不变,我们只调整最后一层的权重。
-
修改输出层:ResNet-18 的原始输出层用于 1000 类分类,但我们可能只需要区分更少的类别(例如蜜蜂和蚂蚁)。因此,我们需要替换掉模型的最后一层,使其输出我们需要的类别数量。
-
训练模型:在我们特定的数据集上(例如蜜蜂和蚂蚁的图像数据集)进行训练,通过多轮次的训练调整最后一层的权重,使得模型能够准确地分类新图像。
-
评估模型:在验证集上评估模型的性能,如果表现良好,我们可以保存最优的模型权重。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transforms
# 设置数据转换
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 数据集路径
data_dir = 'hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载 ResNet-18 模型,使用预训练权重
model_ft = models.resnet18(weights='IMAGENET1K_V1')
num_ftrs = model_ft.fc.in_features
# 修改最后一层以匹配我们的分类任务(蜜蜂和蚂蚁,2 类)
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# 优化器设置
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# 学习率调度器
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
# 训练模型
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25)
# 训练完成后可以使用训练好的模型进行预测或评估
通过以上步骤,你可以利用预训练的 ResNet-18 模型进行迁移学习,将其应用于不同的图像分类任务中。这样可以节省训练时间,并提升小数据集任务上的性能。
5.可视化模型预测
用于显示一些图像预测的通用函数
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title(f'predicted: {class_names[preds[j]]}')
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
6.卷积神经网络微调
加载预训练模型并重新配置最终的全连接层。
model_ft = models.resnet18(weights='IMAGENET1K_V1')
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to ``nn.Linear(num_ftrs, len(class_names))``.
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
运行后会下载resnet18-f37072fd。pth模型用于预训练,输出如下:
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /var/lib/ci-user/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth
0%| | 0.00/44.7M [00:00<?, ?B/s]
47%|####7 | 21.0M/44.7M [00:00<00:00, 219MB/s]
95%|#########5| 42.6M/44.7M [00:00<00:00, 223MB/s]
100%|##########| 44.7M/44.7M [00:00<00:00, 221MB/s]
7.评估和训练
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,num_epochs=25)
在这段代码中,model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25) 调用了 train_model 函数,并传递了几个参数。每个参数在这里都有其特定的作用和含义:
-
model_ft:- 含义: 这是要训练的模型(在这里是经过预训练的 ResNet-18 模型)。
model_ft包含了模型的架构和当前的权重。 - 作用: 该模型会在训练过程中被更新(优化),以更好地适应特定任务(如蜜蜂和蚂蚁的分类)。
- 含义: 这是要训练的模型(在这里是经过预训练的 ResNet-18 模型)。
-
criterion:- 含义: 损失函数(在这里是交叉熵损失函数
CrossEntropyLoss)。 - 作用: 损失函数用于衡量模型的预测结果与实际标签之间的差异。模型的目标是最小化这个损失,以提高预测的准确性。
- 含义: 损失函数(在这里是交叉熵损失函数
-
optimizer_ft:- 含义: 优化器(在这里是随机梯度下降优化器
SGD)。 - 作用: 优化器负责更新模型的权重,以最小化损失函数的输出。通过调整学习率和动量,优化器能够帮助模型更快地收敛到最优解。
- 含义: 优化器(在这里是随机梯度下降优化器
-
exp_lr_scheduler:- 含义: 学习率调度器(在这里是
StepLR调度器)。 - 作用: 学习率调度器用于在训练过程中逐步降低学习率。这样可以帮助模型在训练的后期以较小的步伐调整权重,从而更精细地调整模型的参数,提高模型的最终性能。在这里,学习率每过 7 个 epoch 会按照
gamma=0.1的因子进行衰减。
- 含义: 学习率调度器(在这里是
-
num_epochs=25:- 含义: 训练的轮次数量。
- 作用: 这个参数决定了训练的总轮次。在这里,模型将会被训练 25 个 epoch(每个 epoch 包含一次完整的训练集和验证集的前向传播和反向传播)。
运行代码后开始训练,输出如下:

对模型结果进行评估,得到下面结果:
visualize_model(model_ft)

visualize_model 函数的主要目的是展示模型在验证集(或测试集)上对图像的预测结果。通过查看模型对几个样本图像的预测,你可以直观地理解模型的表现,判断它是否能够正确识别图像中的对象。
8.神经网络固定特征提取
下面这段代码,我们需要冻结除最后一层之外的所有网络,设置冻结参数,以便不再计算梯度。requires_grad = Falsebackward()
model_conv = torchvision.models.resnet18(weights='IMAGENET1K_V1')
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that only parameters of final layer are being optimized as
# opposed to before.
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
这段代码加载了一个使用 IMAGENET1K_V1 权重预训练的 ResNet-18 模型,冻结了除最后一层全连接层以外的所有层的参数,并将最后一层替换为一个适应二分类任务(蜜蜂和蚂蚁)的全连接层,然后设置优化器只更新最后一层的参数。
Q:为什么要使这些参数在训练中保持不变?
A:在迁移学习中,通常会冻结预训练模型的大部分参数,只训练最后几层(如最后一层全连接层)。这是因为预训练模型(例如使用 IMAGENET1K_V1 权重的 ResNet-18)已经在一个大规模的数据集(ImageNet-1000)上学习到了非常通用的特征,这些特征能够很好地表示图像中的低级和中级信息(如边缘、纹理、形状等)。
通过冻结这些层的参数,可以:
- 减少训练时间和计算资源:冻结大部分层减少了需要更新的参数数量,因此训练速度更快,资源消耗更低。
- 避免过拟合:预训练的特征已经被证明是有效的,通过只训练最后一层,可以防止模型过度拟合到新的、小规模的数据集上。
- 利用通用特征:前几层学习到的特征是通用的,适用于多种任务,通过保留这些特征,可以提高模型在新任务上的表现。
这种方法有效地将预训练模型的强大特征提取能力与新任务的特定需求结合起来,从而实现更好的模型性能。

训练并评估模型
model_conv = train_model(model_conv, criterion, optimizer_conv,exp_lr_scheduler, num_epochs=25)
visualize_model(model_conv)
plt.ioff()
plt.show()
运行结果如下:

9.自定义测试集测试
将需要识别的图片放在test_img文件夹中,并将测试图片路径赋值给img_path,模型路径赋值于model调用visualize_model_predictions函数实现对自定义图片的识别
def visualize_model_predictions(model,img_path):
was_training = model.training
model.eval()
img = Image.open(img_path)
img = data_transforms['val'](img)
img = img.unsqueeze(0)
img = img.to(device)
with torch.no_grad():
outputs = model(img)
_, preds = torch.max(outputs, 1)
ax = plt.subplot(2,2,1)
ax.axis('off')
ax.set_title(f'Predicted: {class_names[preds[0]]}')
imshow(img.cpu().data[0])
model.train(mode=was_training)
visualize_model_predictions(model_conv,img_path='data/hymenoptera_data/val/bees/72100438_73de9f17af.jpg')
plt.ioff()
plt.show()
运行代码后可以看到图像被正确的识别,结果如下:

10.结论
微调(fine-tuning)和使用卷积神经网络(ConvNet)作为固定特征提取器是两个不同的方法,尽管它们都用于迁移学习。它们的关系可以理解为:
1. 微调(Fine-tuning)
微调是迁移学习的一种策略,其中一个预训练的模型在新的数据集上进行进一步训练。微调的主要步骤包括:
- 加载预训练模型:通常从一个大数据集(如ImageNet)上训练的模型开始。
- 替换输出层:将模型的最后一层(通常是全连接层)替换为适合新任务的层。例如,若原始模型是为1000类分类任务设计的,而你需要进行2类分类任务,则需要替换为一个具有2个输出单元的全连接层。
- 训练:在新任务的数据集上训练模型时,可以选择是否训练整个网络的所有层,或者只训练新的全连接层。微调通常会解冻一些原本被冻结的层,并对这些层进行训练。
2. 使用固定特征提取器(Fixed Feature Extractor)
固定特征提取器是一种简单的迁移学习方法,其中预训练模型的特征提取部分被冻结,只有新添加的分类层(全连接层)会被训练。具体步骤包括:
- 加载预训练模型:从一个大数据集上训练的模型开始。
- 冻结特征提取层:将模型中除最后一层外的所有卷积层设置为不可训练(
requires_grad=False)。 - 添加新的分类层:在冻结的特征提取器之后添加一个新的全连接层,用于进行新的分类任务。
- 训练:仅训练新的全连接层,固定的卷积层部分不进行训练。
总结
-
微调和固定特征提取器不是相互独立的,而是两种迁移学习的策略。微调是更灵活的方法,能够调整整个网络(或者大部分网络),适应新任务。固定特征提取器则是一种较为简单的方法,仅训练新的分类层,同时保持特征提取部分不变。
-
顺序结构:在实际应用中,可以先使用固定特征提取器策略,然后逐步转向微调。如果固定特征提取器的结果不尽如人意,可以尝试微调以进一步提高性能。
-
相互独立:这两个方法在实现上是相互独立的,但可以根据具体需求选择其一或者组合使用。
四.全部代码
说明:
flag == 1:进行微调,训练整个模型。flag == 2:使用固定特征提取器,仅训练新加的分类层。flag == 3:使用训练好的模型进行预测。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
from PIL import Image
from tempfile import TemporaryDirectory
#选择操作
flag = 1
def main():
cudnn.benchmark = True
plt.ion() # interactive mode
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp, title=None):
"""Display image for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
# 模型训练
def train_model(model, criterion, optimizer, scheduler, num_epochs=25, model_name="best_model_params.pt"):
since = time.time()
# 创建目录以保存模型
if not os.path.exists('model'):
os.makedirs('model')
best_model_params_path = os.path.join('model', model_name)
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
torch.save(model.state_dict(), best_model_params_path)
print()
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:4f}')
# load best model weights
model.load_state_dict(torch.load(best_model_params_path))
return model
# 可视化模型预测
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images // 2, 2, images_so_far)
ax.axis('off')
ax.set_title(f'predicted: {class_names[preds[j]]}')
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
imshow(out, title=[class_names[x] for x in classes])
# 微调特征提取器
if flag == 1:
model_ft = models.resnet18(weights='IMAGENET1K_V1')
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=25,
model_name="finetuned_model_params.pt")
visualize_model(model_ft)
# 固定特征提取器
elif flag == 2:
model_conv = torchvision.models.resnet18(weights='IMAGENET1K_V1')
for param in model_conv.parameters():
param.requires_grad = False
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
model_conv = train_model(model_conv, criterion, optimizer_conv, exp_lr_scheduler, num_epochs=25,
model_name="fixed_model_params.pt")
visualize_model(model_conv)
plt.ioff()
plt.show()
# 使用训练好的模型识别
elif flag == 3:
model_conv = models.resnet18()
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
model_conv.load_state_dict(torch.load('model/finetuned_model_params.pt'))
def visualize_model_predictions(model, img_path):
was_training = model.training
model.eval()
img = Image.open(img_path).convert("RGB")
img = data_transforms['val'](img)
img = img.unsqueeze(0)
img = img.to(device)
with torch.no_grad():
outputs = model(img)
_, preds = torch.max(outputs, 1)
ax = plt.subplot(2, 2, 1)
ax.axis('off')
ax.set_title(f'Predicted: {class_names[preds[0]]}')
imshow(img.cpu().data[0])
model.train(mode=was_training)
visualize_model_predictions(model_conv,img_path='D:/Python_Code_WorkSpace/BeesOrAnts_DL/test_img/40708249_1415445497609.jpg')
plt.ioff()
plt.show()
if __name__ == '__main__':
main()
写在最后
在这篇文章中,我们深入探讨了卷积神经网络(CNN)迁移学习的基本概念和实用技巧,这些知识是理解和实现端到端智能驾驶系统的基础。端到端智能驾驶系统旨在通过一个统一的深度学习框架,直接将传感器数据映射到驾驶决策,从而简化传统的多阶段处理流程。在未来的研究中,结合BEV(鸟瞰视角)图像和Transformer模型的先进方法正在成为热门趋势,它们可以有效提升对复杂驾驶场景的理解和处理能力。掌握CNN迁移学习将为进一步深入这些前沿技术打下坚实的基础,
加油,汽车人!