五 springcloud,业务,消息中间件

5.1 Spring Cloud 5大组件有哪些
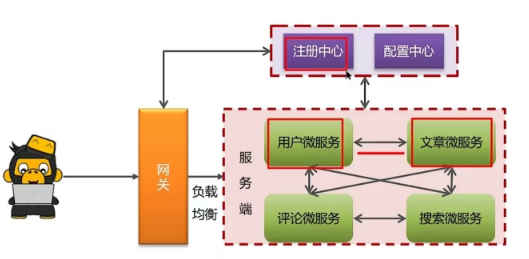

5.2 服务注册和发现是什么意思? Sprin Cloud如何实现服务注册发现?
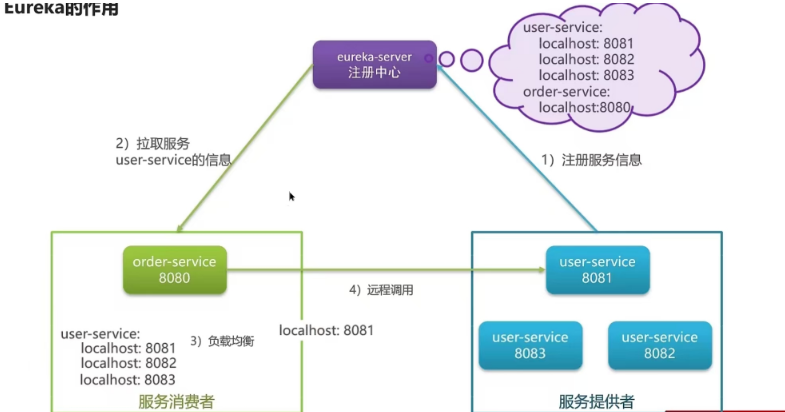
- 我们当时项目采用的eureka作为注册中心,这个也是spring cloud体系中的一个核心组件
- 服务注册: 服务提供者需要把自己的信息注册到eureka,由eureka来保存这些信息,比如服务名称、ip、端口等等
- 服务发现:消费者向eureka拉取服务列表信息,如果服务提供者有集群,则消费者会利用负载均衡算法,选择一个发起调用
- 服务监控: 服务提供者会每隔30秒向eureka发送心跳,报告健康状态,如果eureka服务90秒没接收到心跳,从eureka中剔除
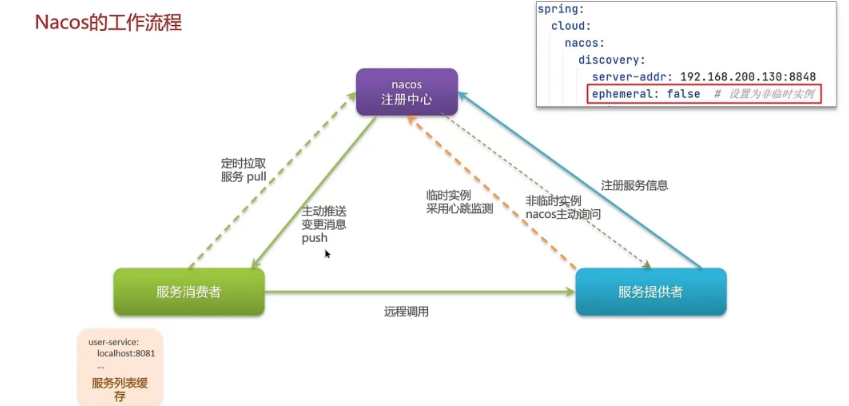
5.3 nacos与eureka的区别?
- Nacos与eureka的共同点(注册中心)
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
- Nacos与Eureka的区别(注册中心)
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式,Eureka采用AP方式
- Nacos还支持了配置中心,eureka则只有注册中心,也是选择使用nacos的一个重要原因
5.3 Ribbon负载均衡策略有哪些

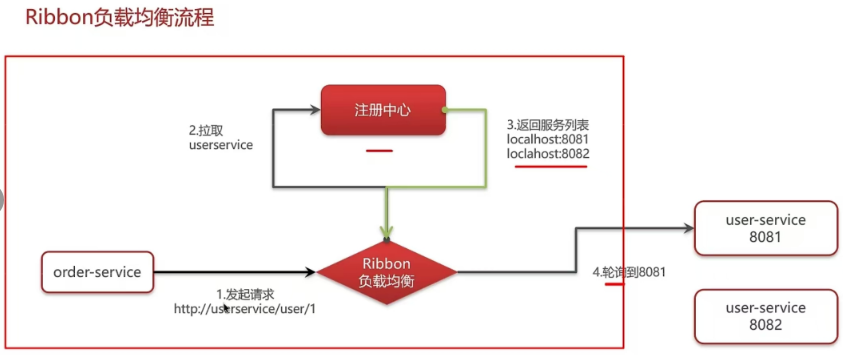
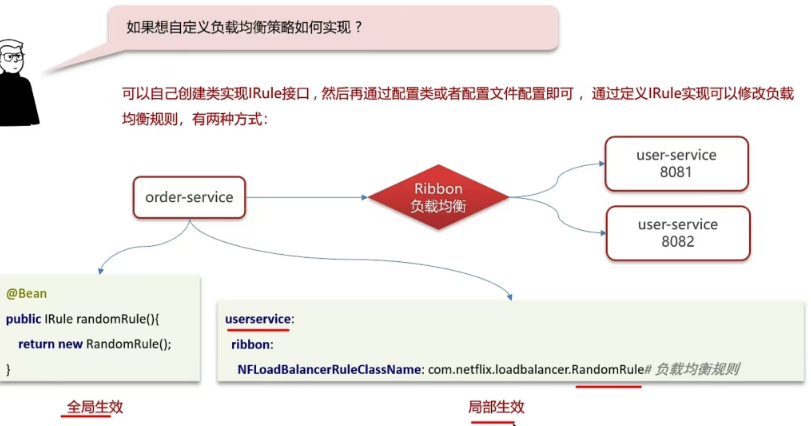
5.4 自定义负载均衡策略如何实现?

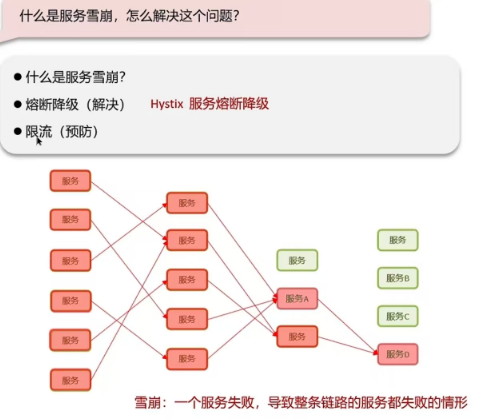
5.5 什么是服务雪崩,怎么解决这个问题
- 服务雪崩:一个服务失败,导致整条链路的服务都失败的情形
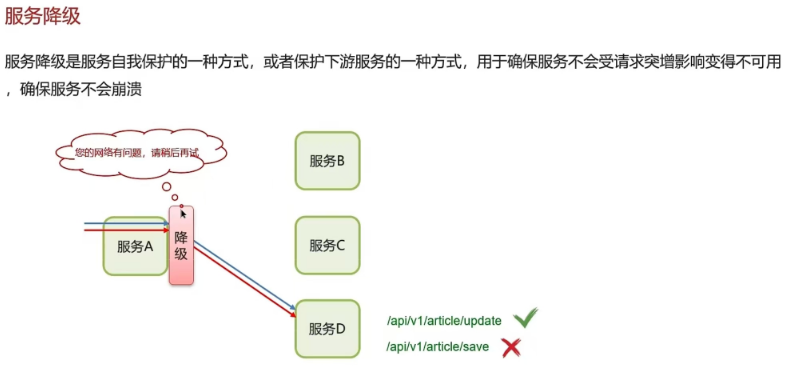
- 服务降级:服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃,一般在实际开发中与feign接口整合,编写降级逻辑
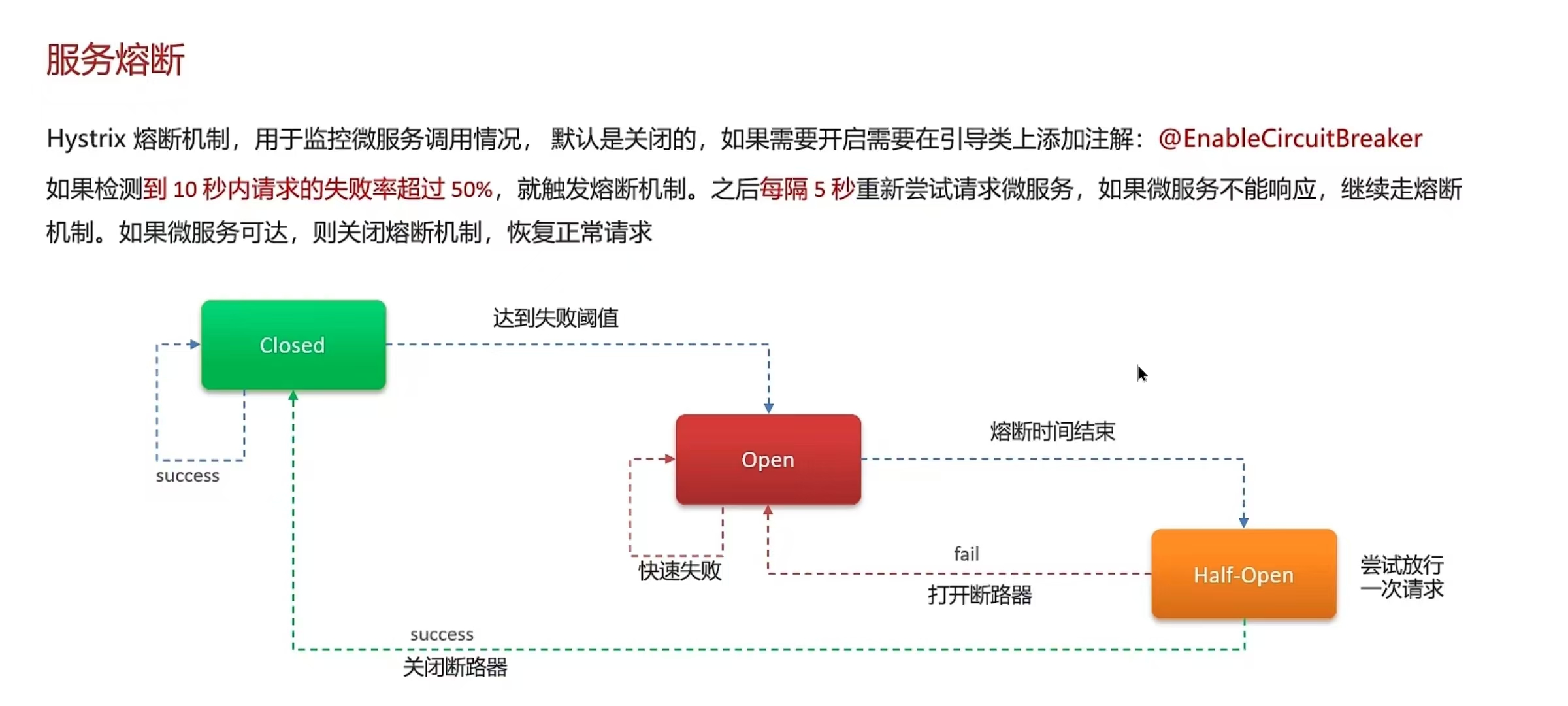
- 服务熔断:默认关闭,需要手动打开,如果检测到 10 秒内请求的失败率超过 50%,就触发熔断机制。之后每隔5秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求

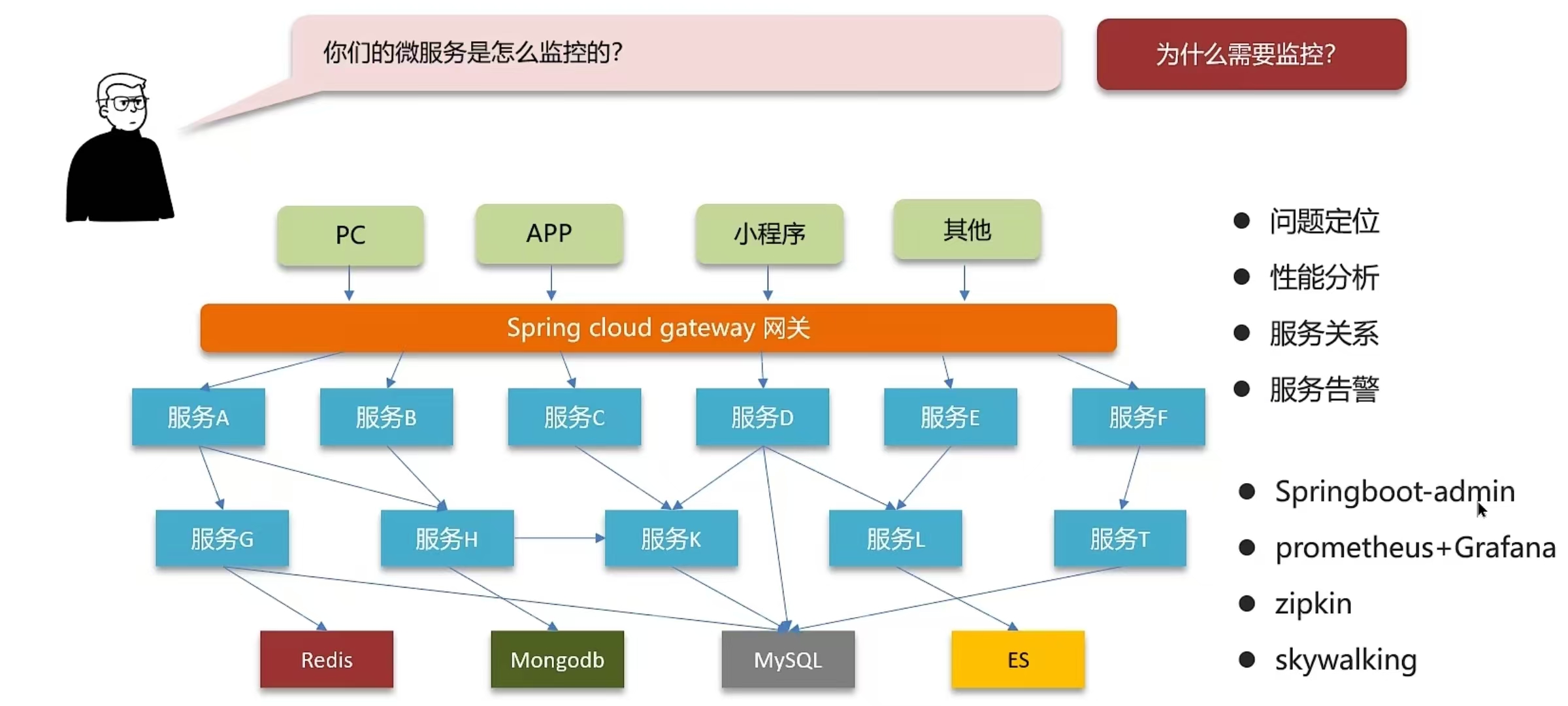
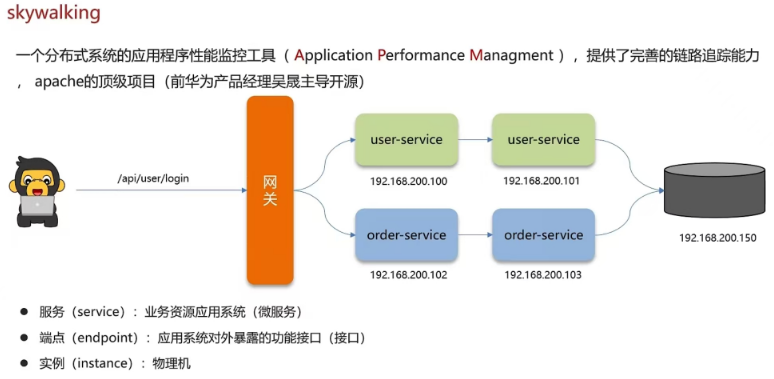
5.6 微服务是怎么监控的,skyWorking
我们项目中采用的skywalking进行监控的
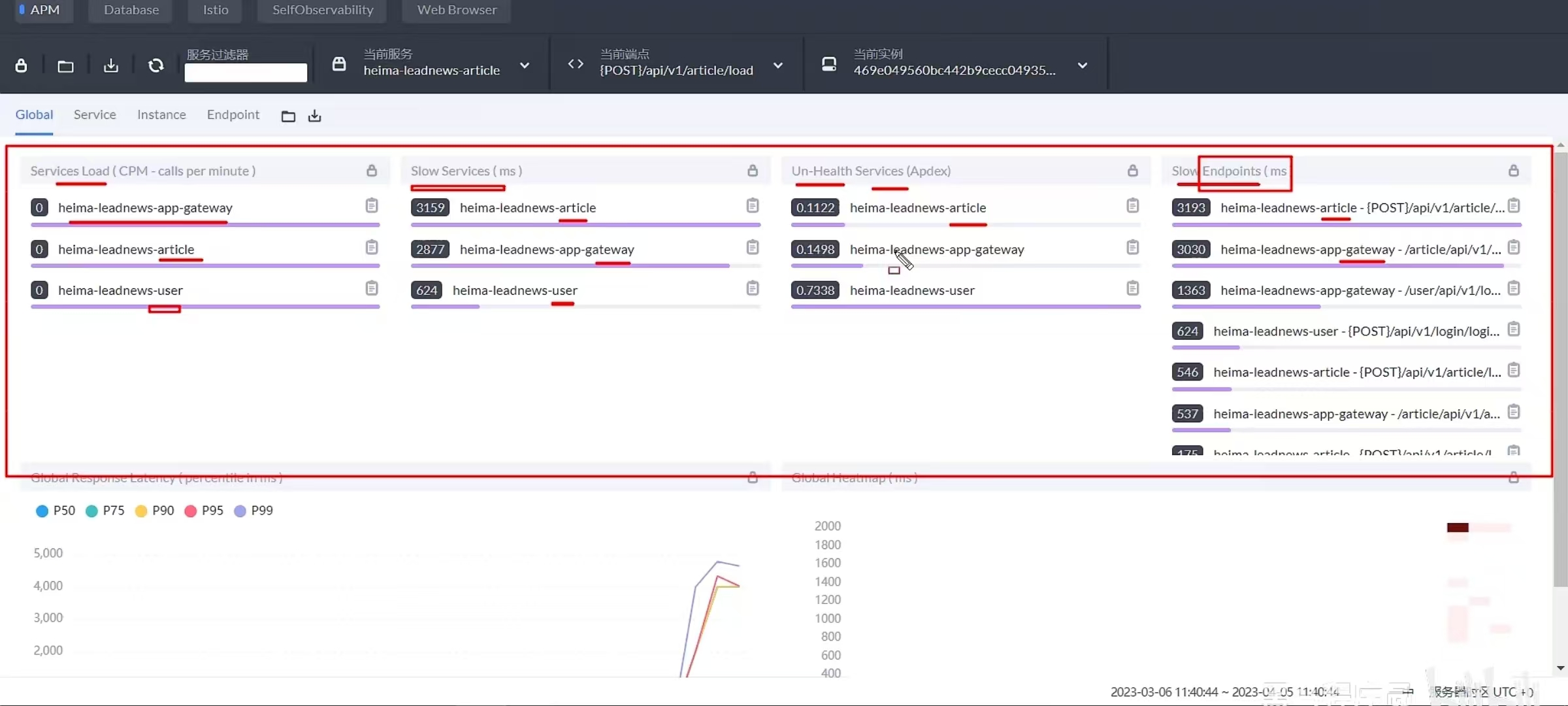
- 1,skywalking主要可以监控接口、服务、物理实例的一些状态。特别是在压测的时候可以看到众多服务中哪些服务和接口比较慢,我们可以针对性的分析和优化。
- 2,我们还在skywalking设置了告警规则,特别是在项目上线以后,如果报错,我们分别设置了可以给相关负责人发短信和发邮件,第一时间知道项目的bug情况,第一时间修复
5.7 你们项目中有没有做过限流?怎么做的?
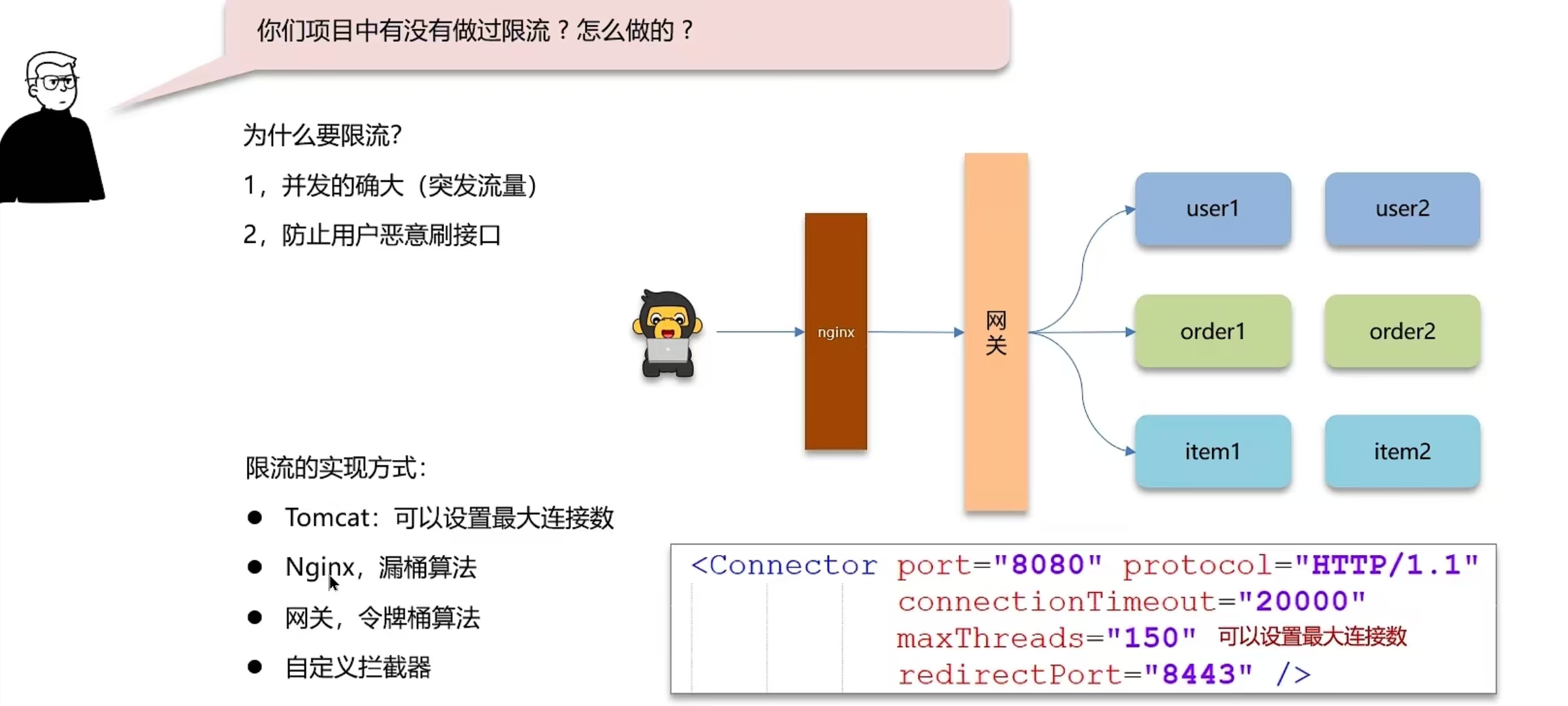


1,先来介绍业务,什么情况下去做限流,需要说明QPS具体多少
我们当时有一个活动,到了假期就会抢购优惠券,QPS最高可以达到2000,平时10-50之间,为了应对突发流量
需要做限流
- 1,常规限流,为了防止恶意攻击,保护系统正常运行,我们当时系统能够承受最大的QPS是多少(压测结果
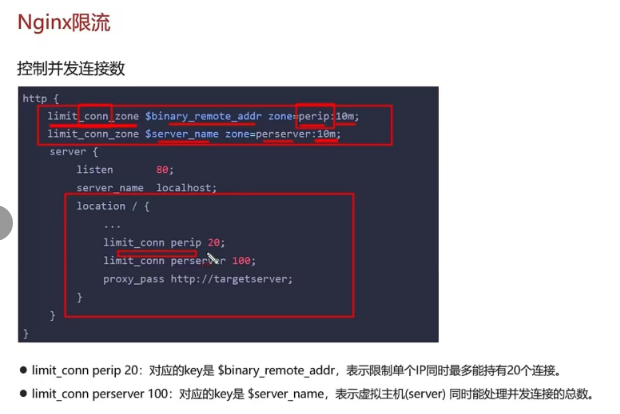
- 2,nginx限流:控制速率(突发流量),使用的漏桶算法来实现过滤,让请求以固定的速率处理请求,可以应对突发流量。控制并发数,限制单个ip的链接数和并发链接的总数
- 3,网关限流:在spring cloud gateway中支持局部过滤器RequestRateLimiter来做限流,使用的是令牌桶算法。可以根据ip或路径进行限流,可以设置每秒填充平均速率,和令牌桶总容量
5.8 CAP原理和BASE原理
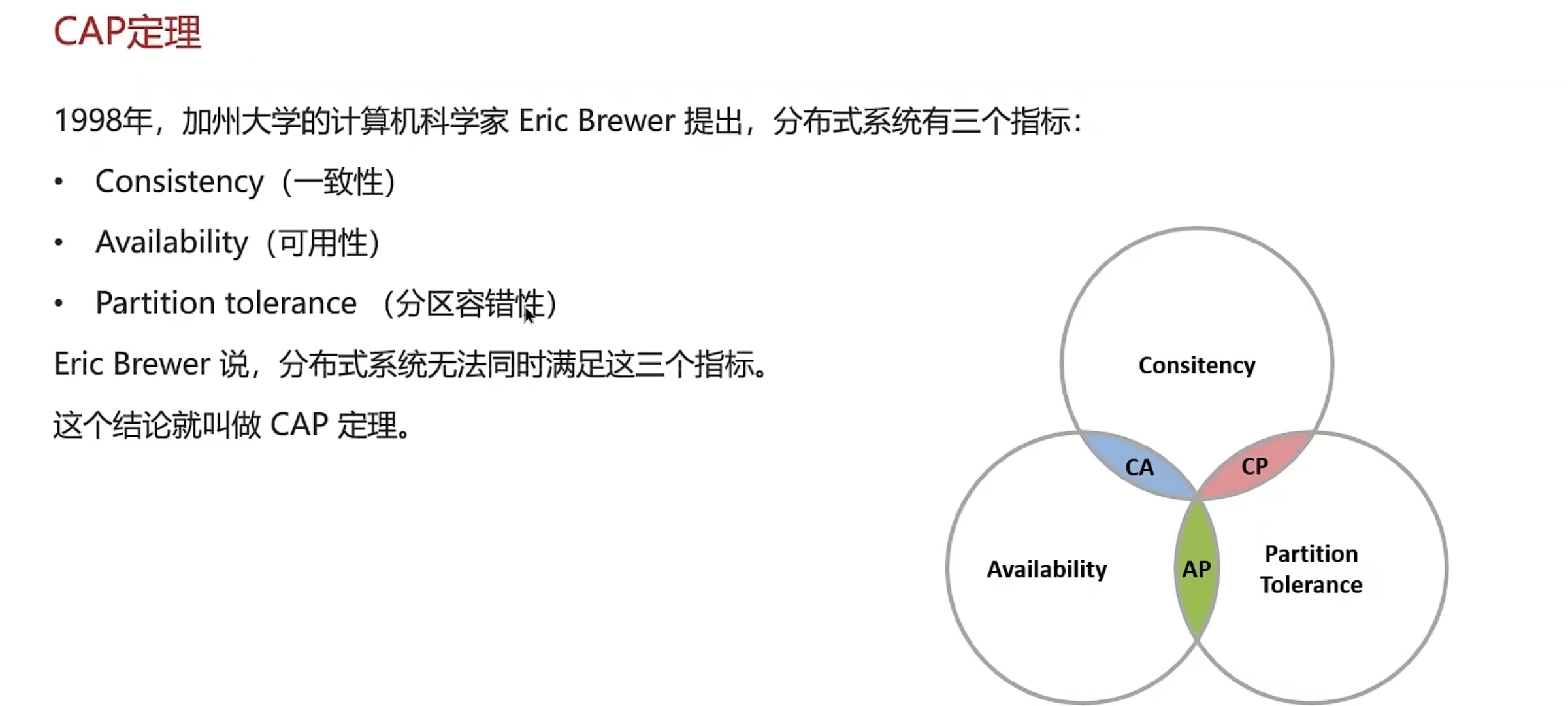
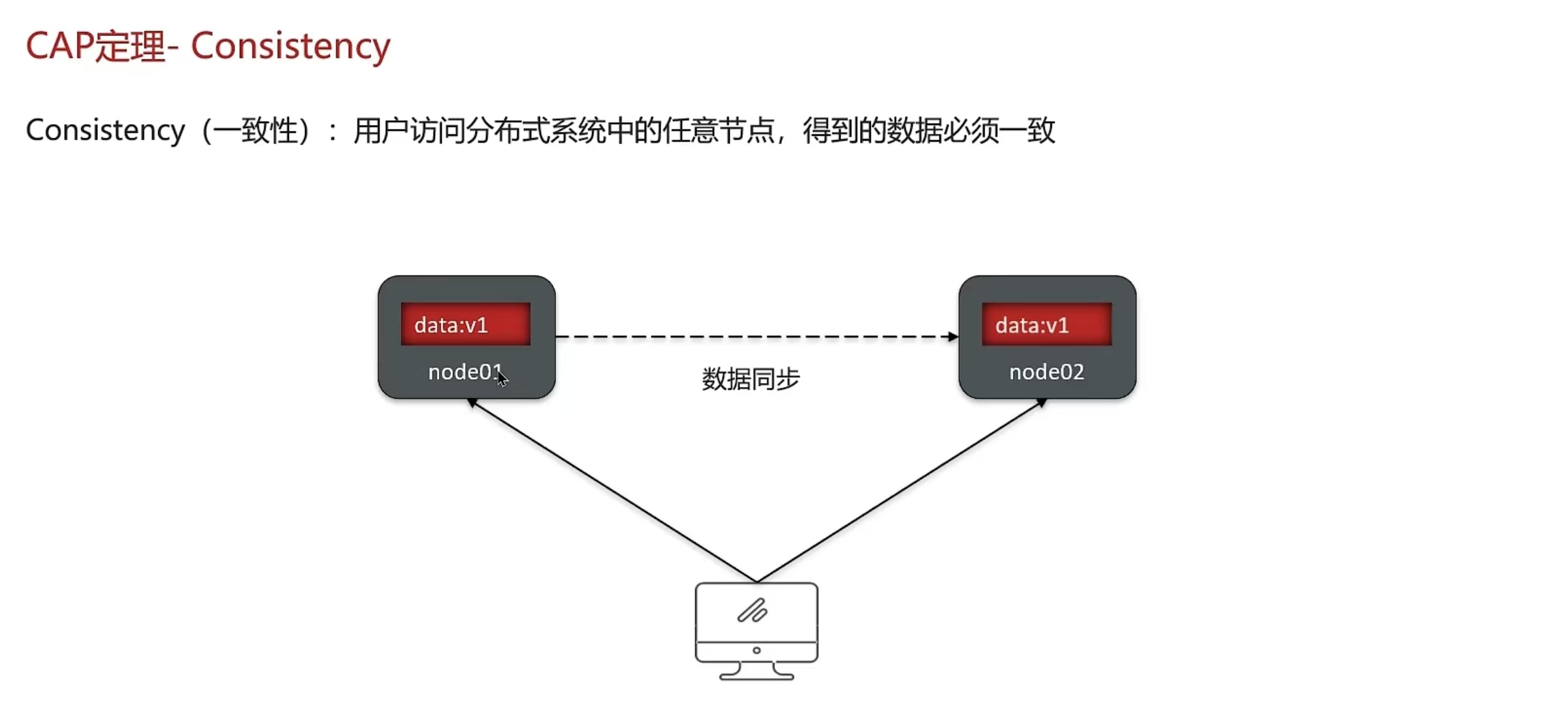
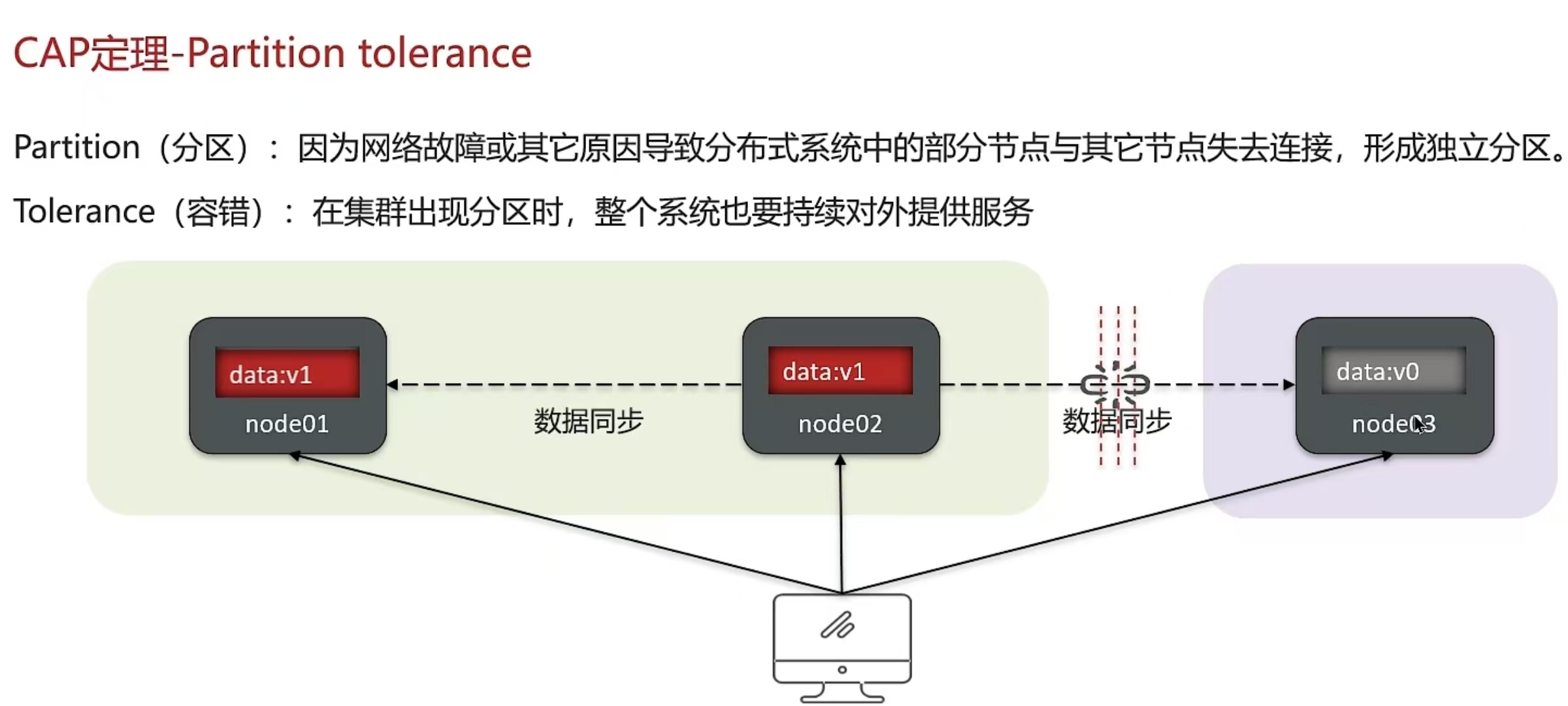
结论:
- 分布式系统节点之间肯定是需要网络连接的,分区(P)是必然存在的
- 如果保证访问的高可用性(A),可以持续对外提供服务,但不能保证数据的强一致性--> AP
- 如果保证访问的数据强一致性(C),就要放弃高可用性-->CP
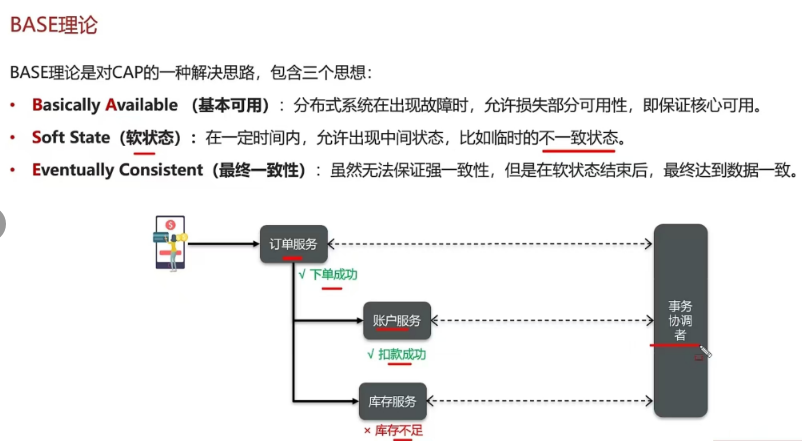

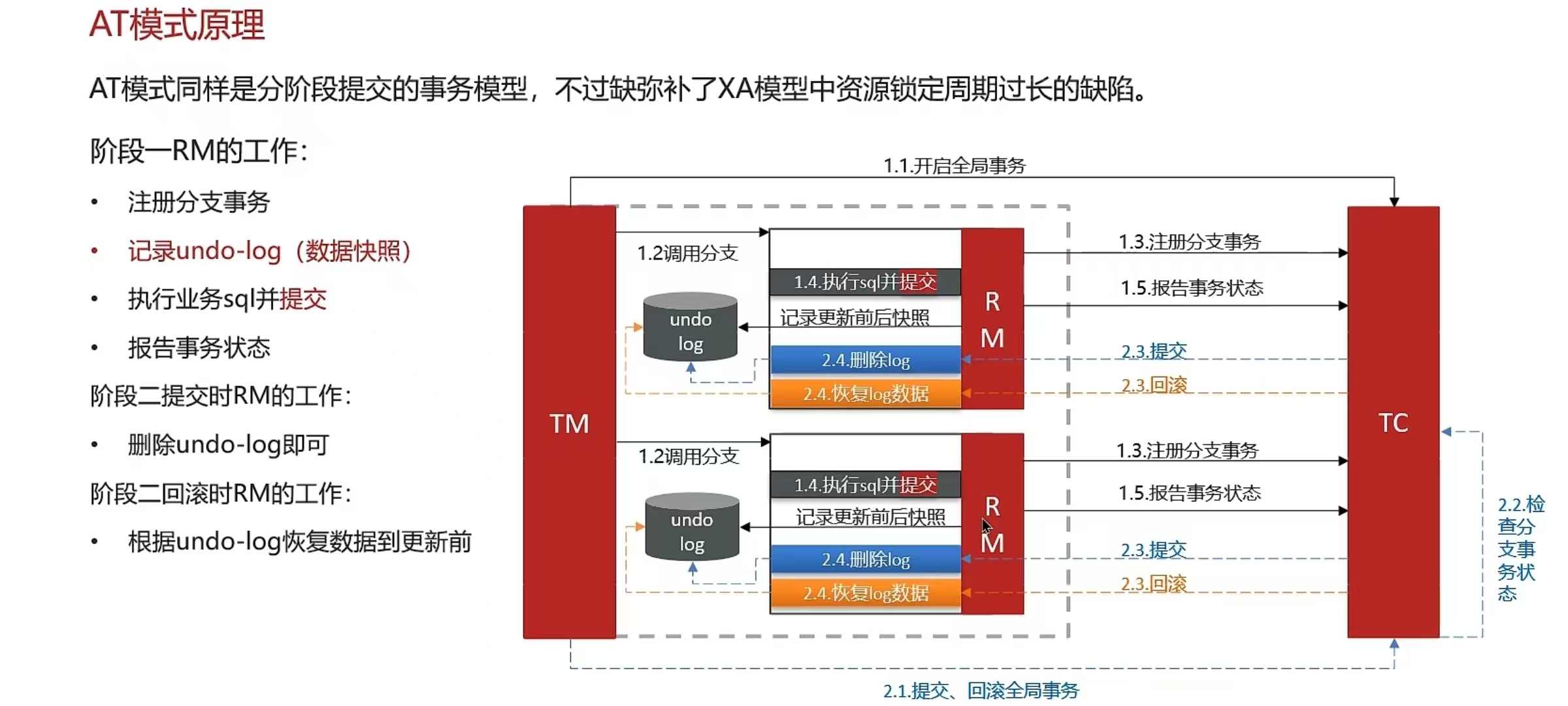
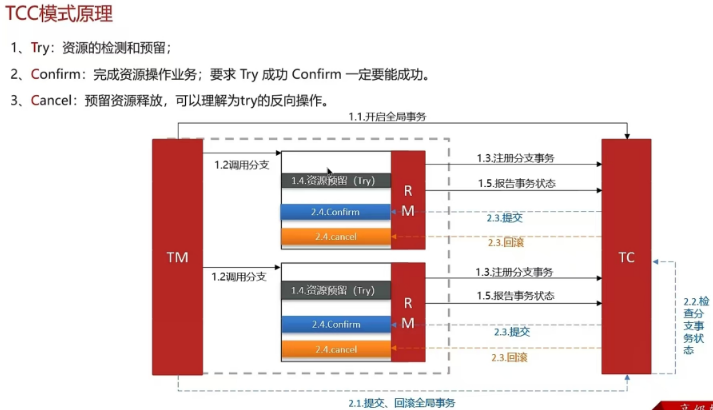
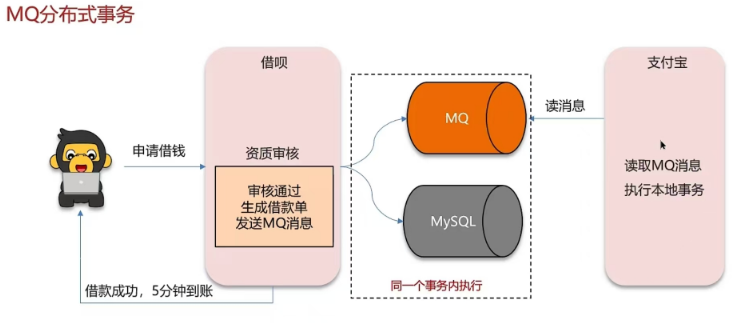
5.9 你们采用哪种分布式事务解决方案
- ·简历上写的是微服务项目
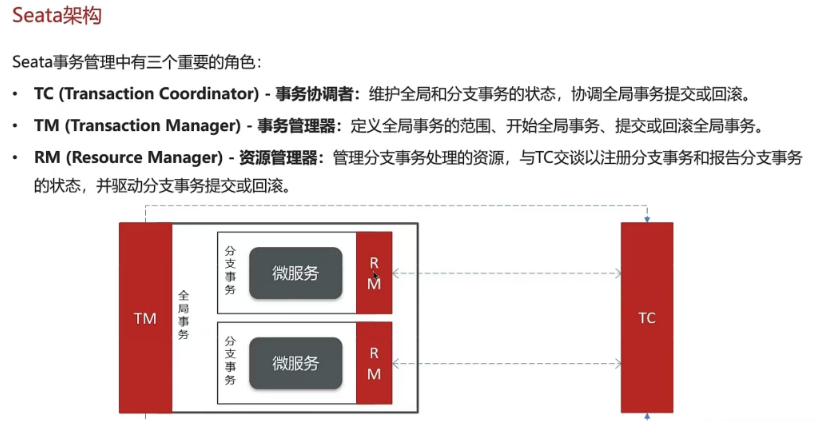
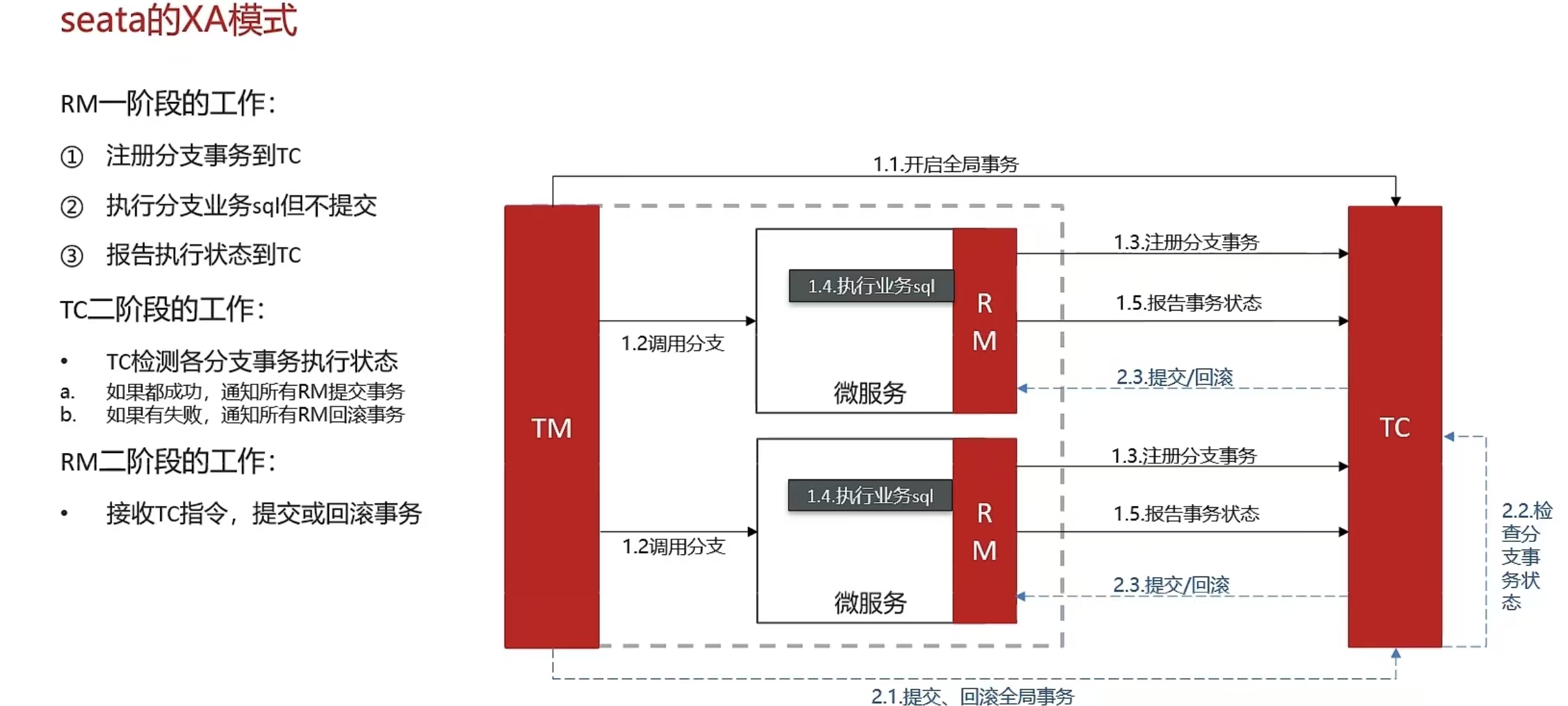
- Seata框架(XA、AT、TCC模式)
- MQ

5.10 分布式服务的接口幂等性如何设计?
幂等: 多次调用方法或者接口不会改变业务状态,可以保证重复调用的结果和单次调用的结果一致。
需要幂等场景:
- 用户重复点击(网络波动)
- MQ消息重复
- 应用使用失败或超时重试机制
解决方案:
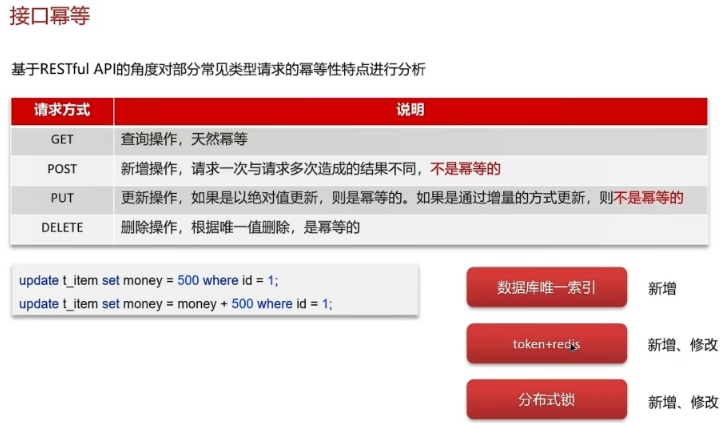
- 如果是新增数据,可以使用数据库的唯一索引
- 如果是新增或修改数据
- 分布式锁,性能较低
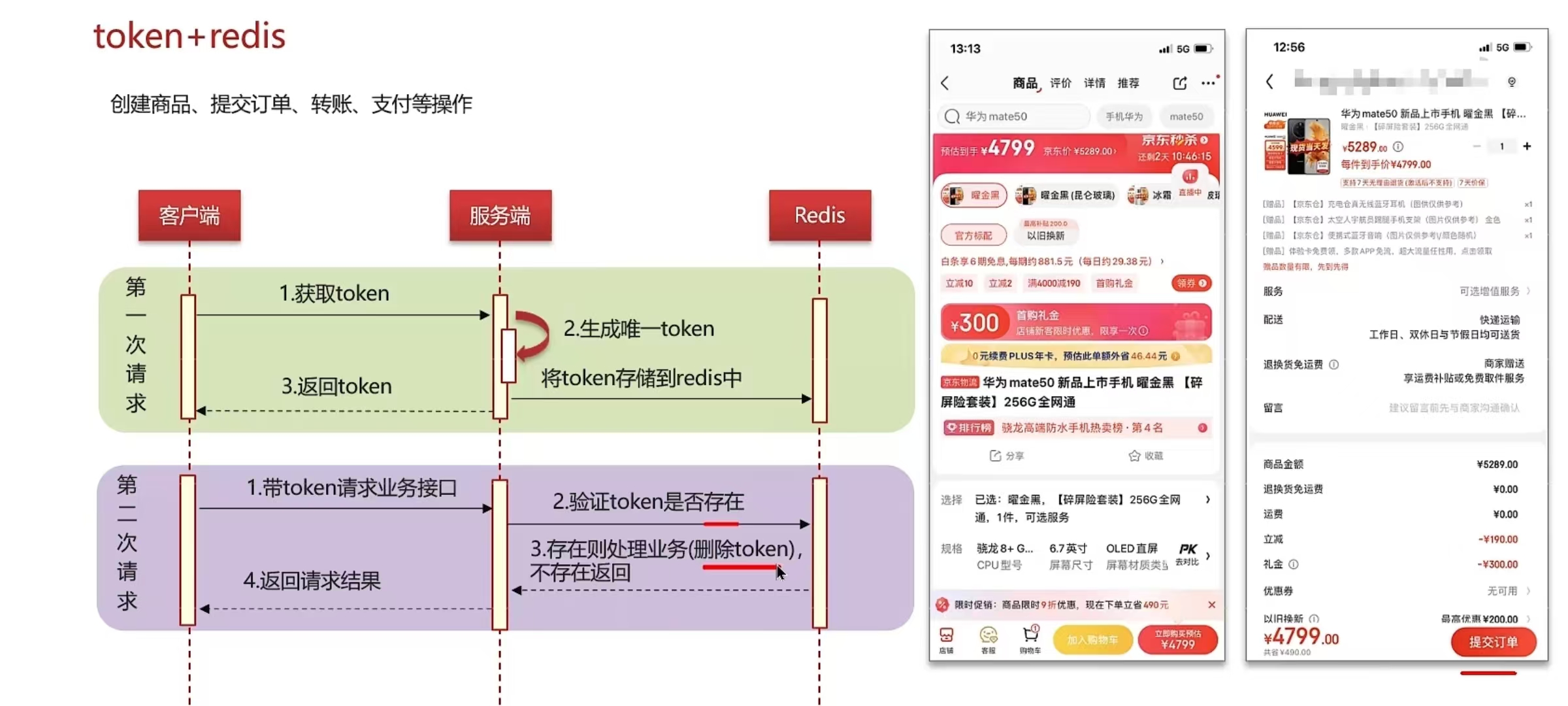
- 使用token+redis来实现,性能较好
- 第一次请求,生成一个唯一token存入redis,返回给前端
- 第二次请求,业务处理,携带之前的token,到redis进行验证,如果存在,可以执行业务,删除token;如果不存在,则直接返回,不处理业务

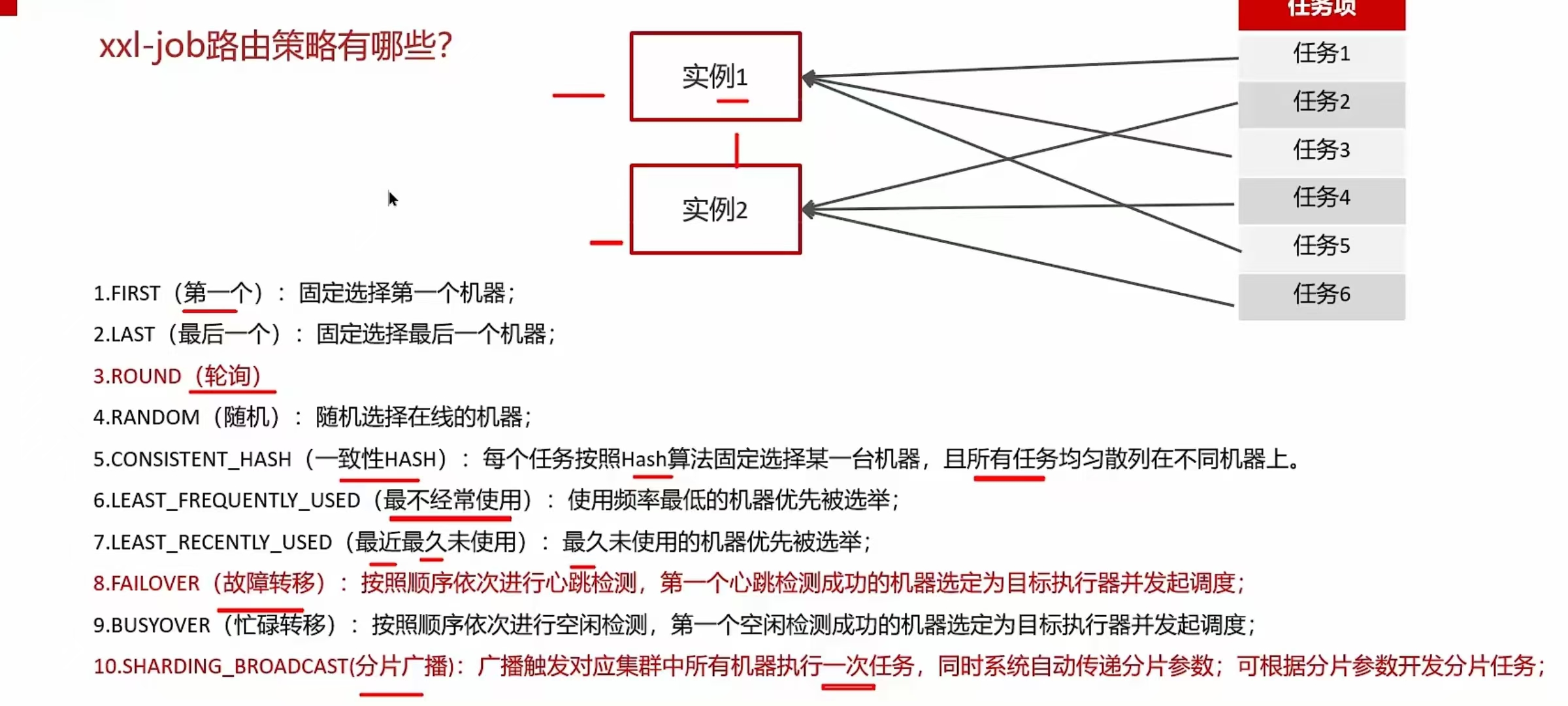
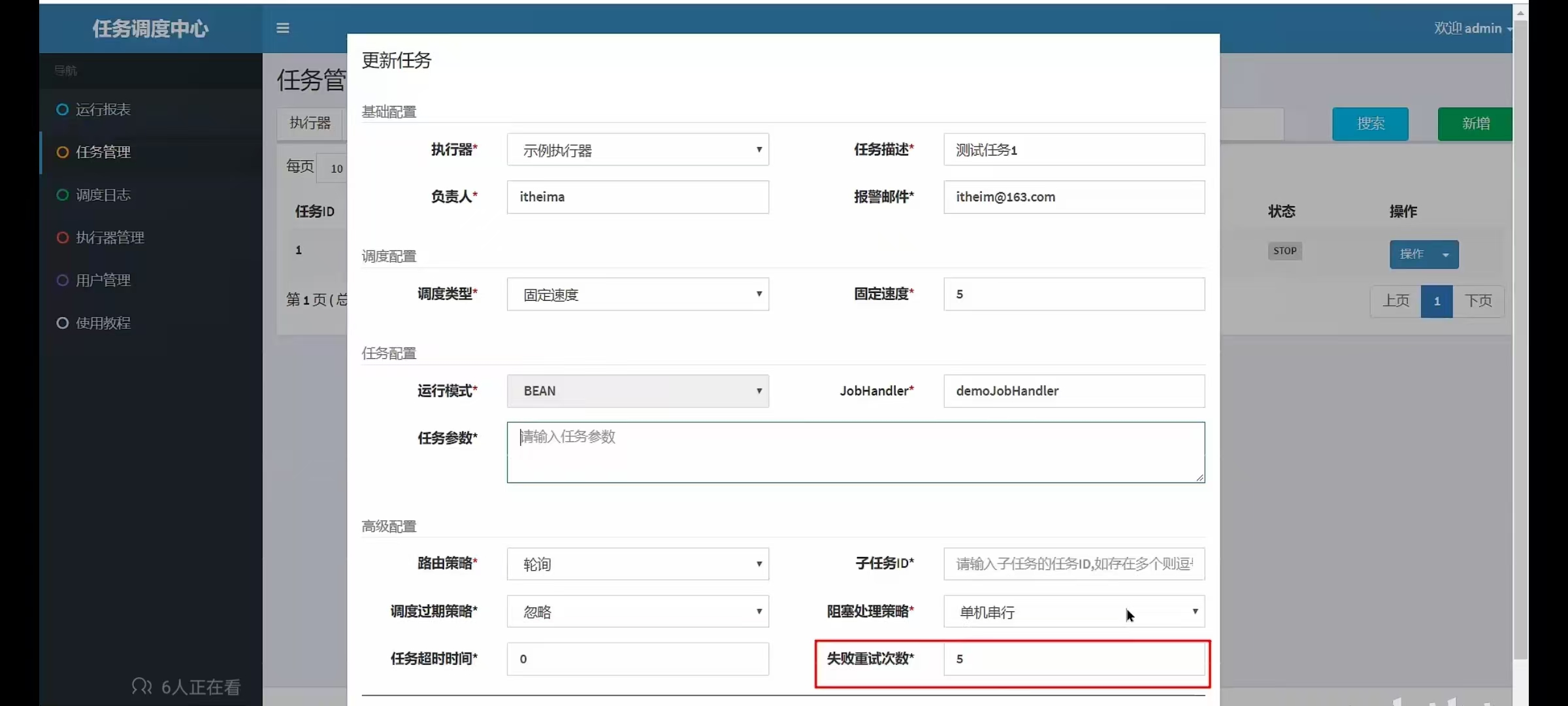
5.11 你们项目中使用了什么分布式任务调度(xxl-job)
xxl-job解决的问题
- 解决集群任务的重复执行问题
- cron表达式定义灵活
- 定时任务失败了,重试和统计
- 任务量大,分片执行
可能产生的问题:
- xxl-job路由策略有哪些?
- xxl-job任务执行失败怎么解决?
- 如果有大数据量的任务同时都需要执行,怎么解决?