很高兴为您带来 Databend 2024 年 8 月的最新更新、新功能和改进!我们希望这些增强功能对您有所帮助,并期待您的反馈。
Kafka Connect Sink Connector 插件
我们推出了一种将 Kafka 连接到 Databend 的新方式:databend-kafka-connect,这是一个 Kafka Connect sink connector 插件。该插件支持 Append Only 和 Upsert 两种写入模式,并能根据数据的 schema 自动在 Databend 中创建目标表。了解更多详情,请查看文档。
想亲身体验如何将 Kafka 消息加载到 Databend,请探索以下教程:
- 使用 bend-ingest-kafka 从 Kafka 加载数据:使用 bend-ingest-kafka 从 Kafka 加载数据 | Databend
- 使用 databend-kafka-connect 从 Kafka 加载数据:使用 databend-kafka-connect 从 Kafka 加载数据 | Databend
全文模糊搜索
全文搜索函数 MATCH 和 QUERY 现在可以在语法中包括以下选项,以支持模糊搜索:
fuzziness: 允许在指定的 Levenshtein 距离内匹配关键字。operator: 指定多个查询关键字如何组合。可以设置为 OR(默认)或 AND。OR 返回包含任何查询关键字的结果,而 AND 返回包含所有查询关键字的结果。lenient: 控制在查询文本无效时是否报告错误。默认为 false。如果设置为 true,当查询文本无效时不会报告错误,结果集将为空。
以下是一些简单的例子:
使用模糊度 fuzziness=1 时,查询关键字 "box" 允许匹配像 "fox" 这样的单词,因为 "box" 和 "fox" 的 Levenshtein 距离为 1:
SELECT id, score(), content FROM t WHERE match(content, 'box', 'fuzziness=1');使用 operator=AND 时,以下查询要求结果中同时包含 "action" 和 "works":
SELECT id, score(), content FROM t WHERE query('content:action works', 'fuzziness=1;operator=AND');由于 fuzziness=1,它还会匹配像 "Actions" 和 "words" 这样的单词,因此会返回 "Actions speak louder than words"。
FUSE_STATISTIC 新增直方图信息
FUSE_STATISTIC 函数现在包括一个新的统计特性:直方图。这个新功能提供了有关每列数据分布的详细信息:
bucket id: 桶的标识符。min: 桶内的最小值。max: 桶内的最大值。ndv(number of distinct values) : 桶内唯一值的计数。count: 桶内的总值数量。
以下是一个简单的例子:
SELECT * FROM FUSE_STATISTIC('default', 'sample');
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ column_name │ distinct_count │ histogram │
├─────────────┼────────────────┼────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ name │ 6 │ [bucket id: 0, min: "Alice", max: "Alice", ndv: 1.0, count: 1.0], [bucket id: 1, min: "Bob", max: "Bob", ndv: 1.0, count: 1.0], [bucket id: 2, min: "Charlie", max: "Charlie", ndv: 1.0, count: 1.0], [bucket id: 3, min: "Diana", max: "Diana", ndv: 1.0, count: 1.0], [bucket id: 4, min: "Eve", max: "Eve", ndv: 1.0, count: 1.0], [bucket id: 5, min: "Frank", max: "Frank", ndv: 1.0, count: 1.0] │
│ age │ 5 │ [bucket id: 0, min: "25", max: "25", ndv: 1.0, count: 1.0], [bucket id: 1, min: "28", max: "28", ndv: 1.0, count: 1.0], [bucket id: 2, min: "28", max: "28", ndv: 1.0, count: 1.0], [bucket id: 3, min: "30", max: "30", ndv: 1.0, count: 1.0], [bucket id: 4, min: "35", max: "35", ndv: 1.0, count: 1.0], [bucket id: 5, min: "40", max: "40", ndv: 1.0, count: 1.0] │
│ user_id │ 6 │ [bucket id: 0, min: "1", max: "1", ndv: 1.0, count: 1.0], [bucket id: 1, min: "2", max: "2", ndv: 1.0, count: 1.0], [bucket id: 2, min: "3", max: "3", ndv: 1.0, count: 1.0], [bucket id: 3, min: "4", max: "4", ndv: 1.0, count: 1.0], [bucket id: 4, min: "5", max: "5", ndv: 1.0, count: 1.0], [bucket id: 5, min: "6", max: "6", ndv: 1.0, count: 1.0] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘Databend Cloud 体验优化
我们给 Databend Cloud 带来了一些新功能,准备好迎接更棒的体验吧!
- 您现在可以将工作区分享给您组织中的所有人或特定的个人。
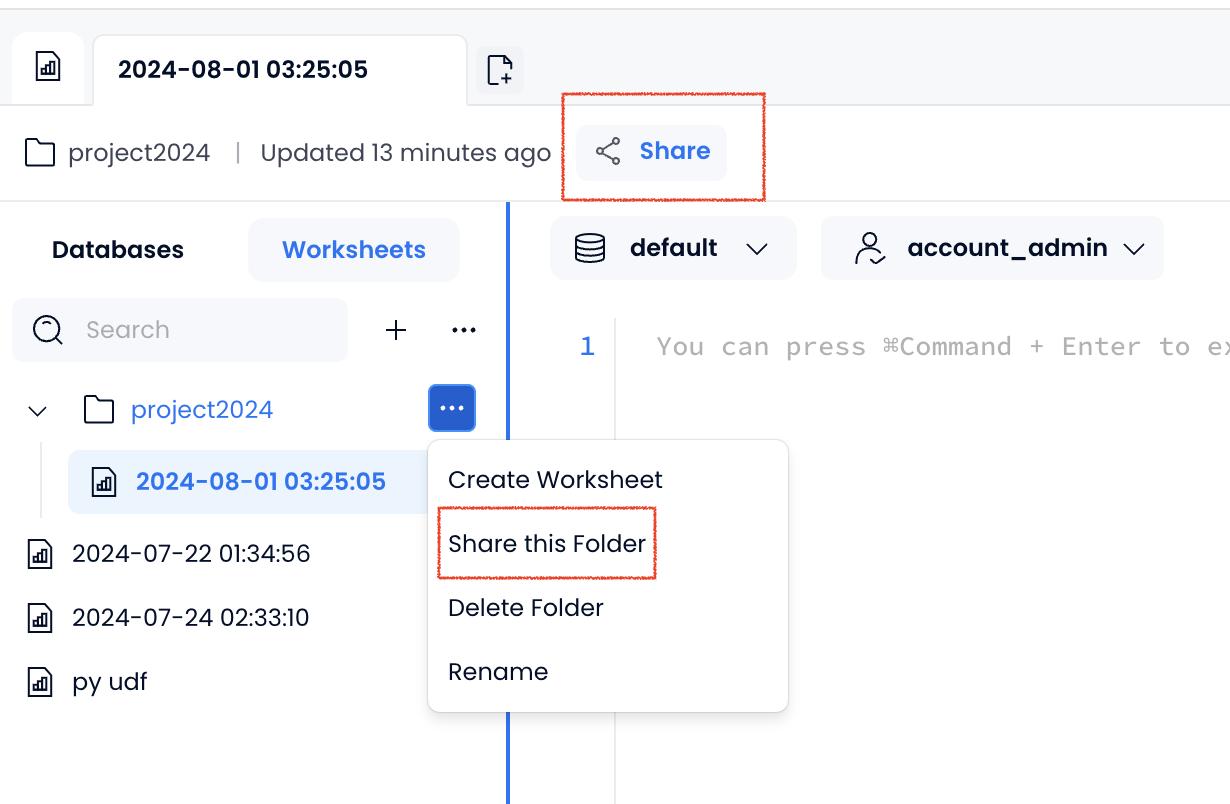
- 支持对计算集群进行批量重启、批量挂起、批量恢复和批量删除操作。

新 SQL 函数
我们新增了一些SQL函数:
- JQ : 允许您对存储在 Variant 列中的 JSON 数据应用 jq 过滤器。
- JSON_OBJECT_AGG : 将键值对转换为 JSON 对象。
- JSON_ARRAY_AGG : 将值转换为 JSON 数组,同时跳过 NULL 值。
- MONTHS_BETWEEN : 返回两个日期之间相隔的月份个数.
性能优化
了解我们最新的改进,这些提升使 Databend 更加高效、精确和可靠:
- 全局计划缓存: 引入了SQL执行计划缓存功能,通过缓存和重用查询计划,加速重复查询的处理,提升性能
- 十进制计算: 修复了十进制乘法问题,确保计算结果始终精确。
- UDF 执行: 优化了 JavaScript 运行时,减少了延迟,提高了用户自定义函数的执行速度。
- 网络操作: 改进了对网络错误的处理,使 Databend 在分布式环境中更具韧性。
- JOIN 性能: 提升了 JOIN 操作的效率,特别是在集群模式下,加快了查询处理速度,减少了复杂查询的延迟。