最近这几年,自然语言处理和计算机视觉这两大领域真是突飞猛进,让机器不仅能看懂文字,还能理解图片。这两个领域的结合,催生了视觉语言模型,也就是Vision language models (VLMs) ,它们能同时处理视觉信息和文字数据。

VLMs就像是AI界的新宠,能搞定那些既需要看图又需要读文的活儿,比如给图片配文字、回答有关图片的问题,或者根据文字描述生成图片。以前这些活儿都得靠不同的系统来干,但现在VLMs提供了一个统一的解决方案。咱们得好好研究研究这些视觉语言模型。
那视觉语言模型到底是啥?
简单来说,视觉语言模型就是把计算机视觉和自然语言处理这两大技术合二为一。
计算机视觉就是让机器能看懂图像和视频里的东西,比如认出里面有什么物体、图案之类的。
而自然语言处理呢,就是让机器能理解和生成人类的语言,这样机器就能读得懂、分析得了,还能自己写东西。
VLMs就是通过构建一种能同时处理视觉和文本输入的模型,把这两个领域给连接起来了。这背后靠的是深度学习的一些高级架构,尤其是那些变换器(Transformer)模型,它们在像GPT-4o、Llama、Gemini和Gemma这样的大型语言模型中发挥了关键作用。
这些基于变换器的架构被调整来处理多种类型的输入,让VLMs能捕捉到视觉信息和语言数据之间那些复杂的联系。
VLMs到底是怎么个工作法?
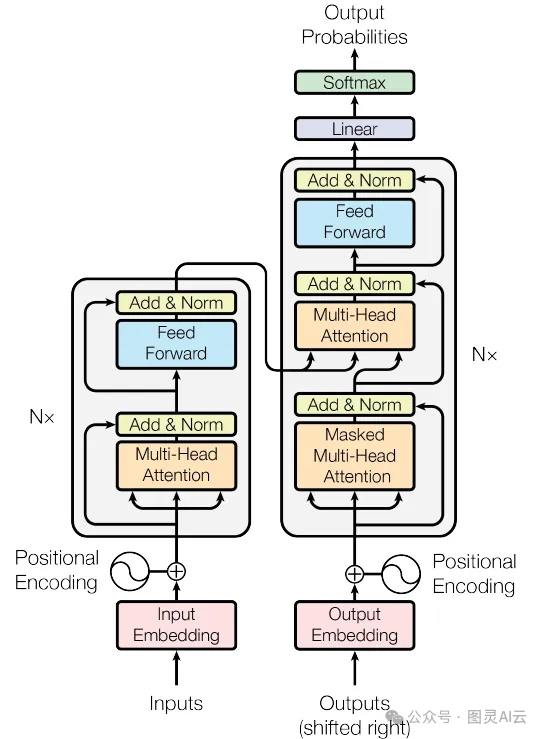
你记得那个为了处理自然语言而搞出来的变换器模型吗?就是那个能处理长距离的依赖关系,还能抓住数据里上下文联系的厉害玩意儿。这个模型现在已经成了很多高级AI系统的中坚力量。
这个变换器架构,最早是在2017年的一篇论文《Attention is All You Need》( https://arxiv.org/abs/1706.03762 )里提出来的。
Transformer网络架构
在VLMs的世界里,变换器被调整成了能同时处理图像和文本,让这两种不同类型的信息能够无缝地整合在一起。想要更详细了解 Transformer 的话,可以参见之前的文章:《Transformer架构的详解》及《用PyTorch构建Transformer模型实战》
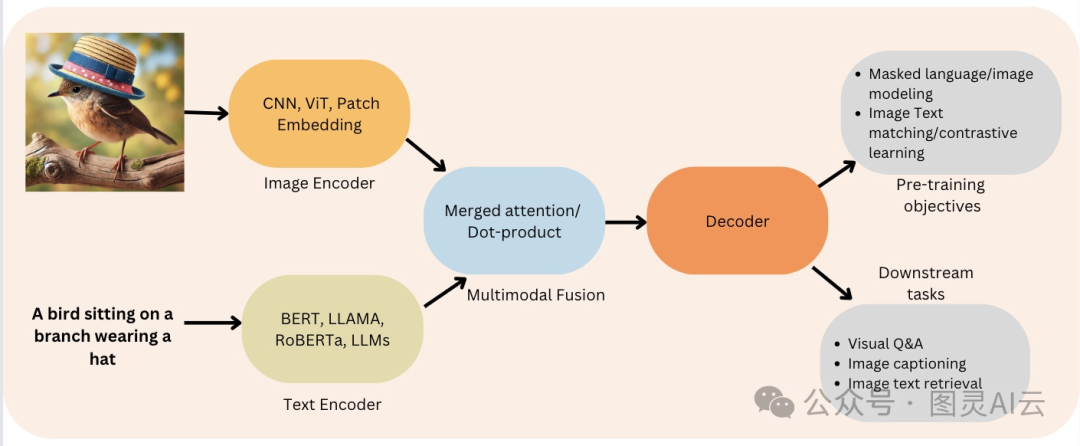
一般来说,一个典型的VLM架构包括两个主要的部分:图像编码器和文本解码器。
-
图像编码器:这家伙的职责是处理视觉数据,比如图片,然后提取出里面的关键特征,比如物体、颜色、纹理等等,把它们转换成模型能懂的格式。
-
文本解码器:这个部件负责处理文本数据,根据图像编码器提供的视觉特征来生成输出。
Encoder-Decoder 功能
这两个部件在VLM里头就像是多模态融合的大管家。
通过把这两部分结合起来,VLMs能干的事儿可多了,比如能给图片写出详细的描述,回答有关图片的问题,甚至根据文字描述生成全新的图片呢!VLMs工作的过程大概是这样的:
-
图像分析:图像编码器先检查图片,然后生成一个代码,这个代码代表了图片的关键视觉特征。
-
信息结合:文本解码器拿到这个代码后,会把它和任何文本输入(比如一个问题)结合起来,一起处理。
-
生成输出:文本解码器用这种结合后的理解来生成一个回应,比如给图片配上字幕,或者回答问题。
大多数VLMs用的是视觉变换器(Vision Transformer, ViT)作为图像编码器,这个编码器已经在大量的图像数据集上预训练过,确保它能有效地捕捉到多模态任务需要的视觉特征。
文本解码器则是基于语言模型,经过微调后能处理视觉数据上下文中的语言生成的复杂性。这种视觉和语言处理能力的高度结合,让VLMs成为了一种非常通用而且强大的模型。
开发VLMs的一个重大挑战就是要有大型而且多样化的数据集,里面得包含视觉和文本信息。这些数据集对于训练模型理解和生成多模态内容非常关键。
训练VLMs的过程,就是把图像和它们相应的文本描述成对地输入到模型里,让模型学会视觉元素和语言表达之间的复杂关系。
为了处理这些数据,VLMs通常会用到嵌入层,把视觉和文本输入都转换成高维空间里的表示,这样它们就可以在那里被比较和结合起来。
这种嵌入过程让模型能够理解两种模态之间的联系,并且生成既连贯又符合上下文的输出。想要了解更多关于嵌入的细节,可以参见 《大话LLM之向量嵌入》 及 《LLM向量嵌入知多少》两篇文章。
那现在有哪些比较主流的开源的视觉语言模型?
这个领域可真是海了去了,Hugging Face Hub上就有不少现成的开源模型。这些模型大小不一,功能各异,许可证也各不相同,给不同需求的用户提供了丰富的选择。下面咱们就来看看一些特别出色的开源VLMs,以及它们的关键特点:
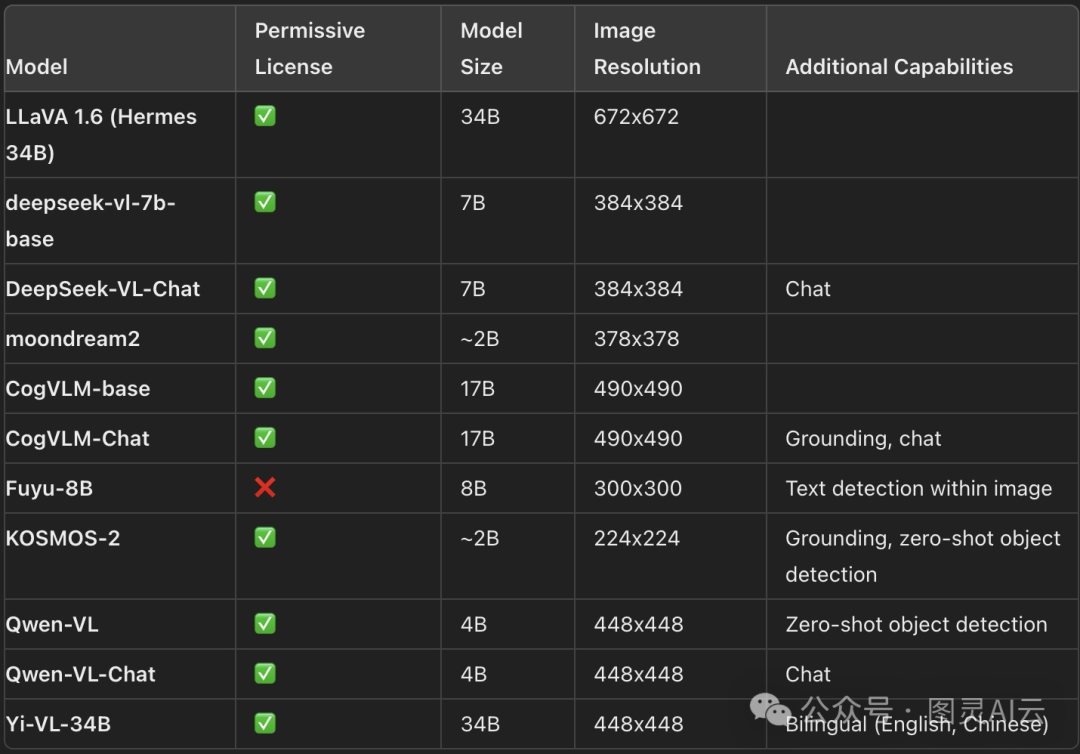
最新的VLMs及其关键特点
要找到最适合自己特定需求的VLMs,面对这么多选项确实有点难。不过,有几个工具和资源能帮上忙:
-
Vision Arena:这是一个动态排行榜,基于模型输出的匿名投票。用户上传一张图片和一个提示,然后系统会从两个不同的模型中随机抽取输出,让用户选择他们更喜欢哪个。这个排行榜完全是基于人的喜好来构建的,给模型提供了一个公平的排名。
-
Open VLM Leaderboard:这个排行榜会根据不同的指标和平均分数给各种VLMs打分,还提供了筛选器,可以按照模型的大小、许可证和不同指标的性能来排序。
-
VLMEvalKit:这是一个工具包,专门设计用来在VLMs上运行基准测试,也是Open VLM Leaderboard的技术支持。还有一个评估套件叫LMMS-Eval,它提供了一个命令行界面,让用户可以使用Hugging Face Hub上托管的数据集来评估模型。
虽然Vision Arena和Open VLM Leaderboard提供了很多有价值的信息,但它们只能包括那些已经被提交的模型,而且需要定期更新,才能加入新模型。
我们怎么评估这些视觉语言模型?
通常得用到几种专门的基准测试,下面简要介绍几种,详情可参见:《大型语言模型基准测试:理解语言模型性能》:
-
MMMU:这个大规模多学科多模态理解和推理的基准测试,覆盖了超过11,500个多模态的挑战,需要用到像艺术和工程这样的不同学科的大学水平知识。
-
MMBench:这个基准测试包含了20种不同技能的3000个单选题,比如光学字符识别(OCR)和目标定位。它用CircularEval策略,就是把答案选项随机打乱,模型得一直能选出正确答案。
-
特定领域的基准测试:还有一些更专业的基准测试,比如MathVista(视觉数学推理)、AI2D(图表理解)、ScienceQA(科学问题回答)和OCRBench(文档理解),这些都能提供更专门的评估。
这些测试帮研究人员和开发者评估和比较不同VLMs的性能,让他们能更好地理解模型在特定任务和场景下的效果。通过这些测试,我们能更精确地知道模型处理多模态数据、理解复杂概念和生成准确响应的能力。
技术细节:预训练VLMs
预训练VLMs就是要把图像和文本的信息统一起来,然后输入到文本解码器里生成文本。这通常包括一个图像编码器、一个用来对齐图像和文本信息的嵌入投影器,还有一个文本解码器。不过,不同的模型可能会用不同的预训练策略。
很多时候,如果你能针对特定用途微调现有的模型,可能连预训练VLMs都不需要。像Transformers和SFTTrainer这样的工具,让微调模型变得简单,即使是资源有限的人也能轻松上手。
实现开源VLMs
下面是一个用HuggingFace的Transformers库,我们可以在自己的电脑上免费使用开源VLM LlavaNext模型:
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
processor = LlavaNextProcessor.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf"
)
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
model.to(device)
这样,我们就能在自己的项目中用上这些强大的开源VLMs了。
VLMs 有哪些应用场景?
VLMs 本事可不止是给图片加个字幕那么简单。这些模型就像是视觉和文本信息之间的超级翻译官,开启了一大堆应用的大门。咱们一块儿看看VLMs在各行各业里头都有哪些影响力大的应用。
-
视觉问题回答(Visual Question Answering, VQA)
想象一下,你给机器看张图,然后问它问题,比如“这图里最高的楼是什么颜色的?”或者“这图里有几个人?”VQA就是干这个的。这要求模型得能读懂图里的视觉信息,还得理解你问话的上下文。在医疗行业,VQA能帮忙分析医学影像,给诊断和治疗计划提供参考。在零售业,它能让顾客更直观地和商品图片互动,提升购物体验。
-
文本到图像生成
VLMs还有一个超酷的能力,就是能根据文字描述生成图片。比如你描述一个“山间宁静的日落,山谷中流淌着一条河流”,VLMs就能给你“画”出来。这对设计师和广告人来说是个宝,他们可以根据文字提示快速搞出视觉创意,让创造视觉内容的过程更高效。
-
图像检索
图像检索就是根据文字描述来找图片。VLMs能搞懂图片里有啥,也能搞懂你想找啥,帮你找到最匹配的图片。这能让搜索引擎更精准,让用户更容易找到他们想要的图片。无论是在网上购物还是医学图像分析,这个技能都很有用。
-
视频理解
VLMs不只能处理图片,还能处理视频,帮我们理解视频内容,甚至给视频加字幕。视频理解能分析视频里的视觉信息,然后生成描述性的文本,捕捉视频要表达的精髓。这个技能在视频搜索、视频摘要和内容审核等方面都能派上用场。比如,它能帮助用户根据文字找到特定的视频片段,或者快速生成视频摘要,让用户迅速了解视频内容。在内容审核方面,VLMs能帮忙识别视频中的不当内容,让网络平台更安全友好。
总之,视觉语言模型能同时处理视觉和文本数据,这本事让各种应用都有可能得到加强。随着这个领域的不断发展,我们可以预见,未来会有更多更复杂的VLMs出现,它们能完成更艰巨的任务,还能给出有价值的见解。