1、Elasticsearch Profile 工具介绍
在使用 ES 进行检索查询时,我们常常要去优化一些复杂的查询语句,这里 ES 结合 lucene 的生态制作了 Profile API 和图形化的 Profile 分析界面以供用户使用。
这里我们来简单讲解一下这个工具 API,希望能给广大的 ES 检索用户提供一些帮助。
这里的 profile API 以 ES 8.15 版为准。
1.1 Profile API
Profile API 给用户提供了更细粒度的查询执行细节,暴露出的每个查询执行类的主要方法执行时间是用户排障优化的主要依据。
我们先来看一下 Profile 的主要执行:
GET /my-index-000001/_search
{
"profile": true,//开启 profile 参数
"query" : {
"match" : { "message" : "GET /search" }
}
}就会发现返回的 json 结果里包含一个 profile 模块。由于 json 返回比较长,这里就不贴了,我们简要的来看看 profile 模块主要的组成结构:
{
"profile": {
"shards": [
{
"id": "[q2aE02wS1R8qQFnYu6vDVQ][my-index-000001][0]", //这里返回了分片的 id,由 节点名[q2aE02wS1R8qQFnYu6vDVQ] + 索引名[my-index-000001] + 分片号 [0]
"node_id": "q2aE02wS1R8qQFnYu6vDVQ",
"shard_id": 0,
"index": "my-index-000001",
"cluster": "(local)", //是不是本地集群解析的
"searches": [
{
"query": [...], // query 阶段的耗时,其中包括各种 query 执行类、执行描述以及相关方法的执行耗时
"rewrite_time": 51443, // 总共的 rewrite 耗时
"collector": [...] // collector 阶段的耗时,包括阶段名称、阶段描述和执行耗时
}
],
"aggregations": [...], //分析聚合阶段的各个执行类、执行描述以及相关方法的耗时
"fetch": {...} //fetch 阶段的执行类、执行描述以及相关方法的耗时
}
]
}
}注意:
添加
_search?human=true可以增加 profile 数据的可读性,在主要阶段的耗时数据后加上ms,micros单位。在各阶段 breakdown 的方法里,数据单位默认都是纳秒(time_in_nanos)
1.2 kibana 的 Search Profiler
行业内有句话“一图胜千言”,清晰明了的图形化工具能大大提高分析的效率。
更何况 ES 默认返回 json 数据常常成百上千行,很容易让人读不下去。
因此 ES 在 kibana 上做了一个图形化分析模块,在 Dev Tools -> Search Profiler。
你可以将需要被解析的索引名和查询 DSL 贴入相应的区域进行直接执行Profile解析。
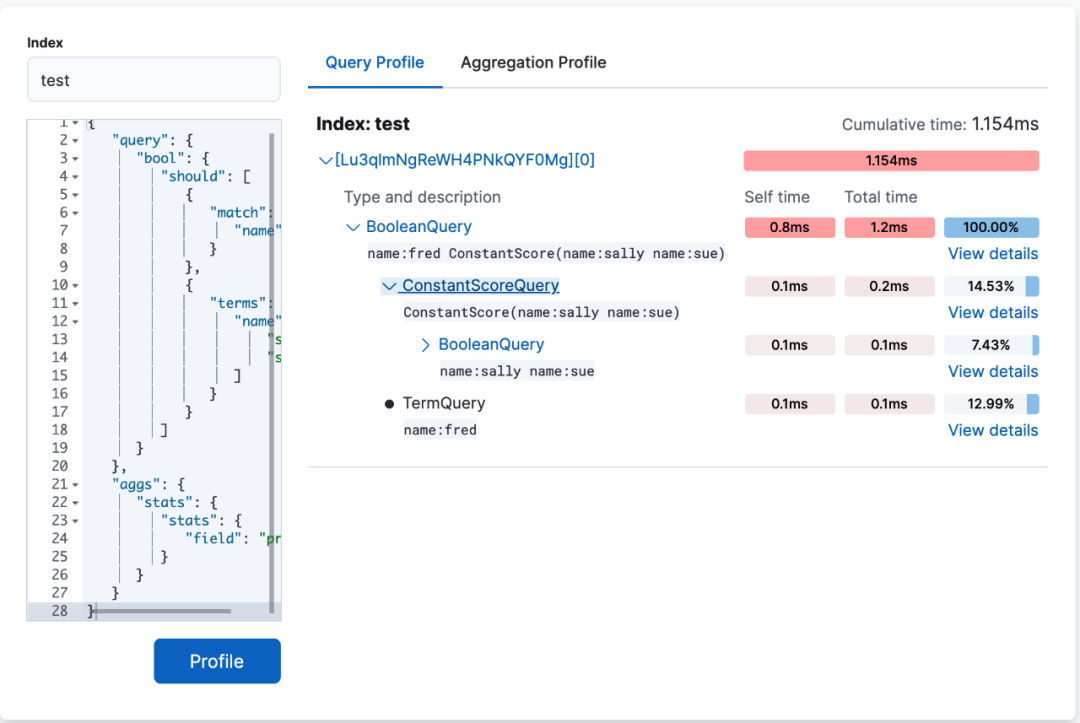
除了 query 阶段,也可以看到有 aggregation 聚合阶段。
view detail 我们还可以看到各个执行方法的耗时。
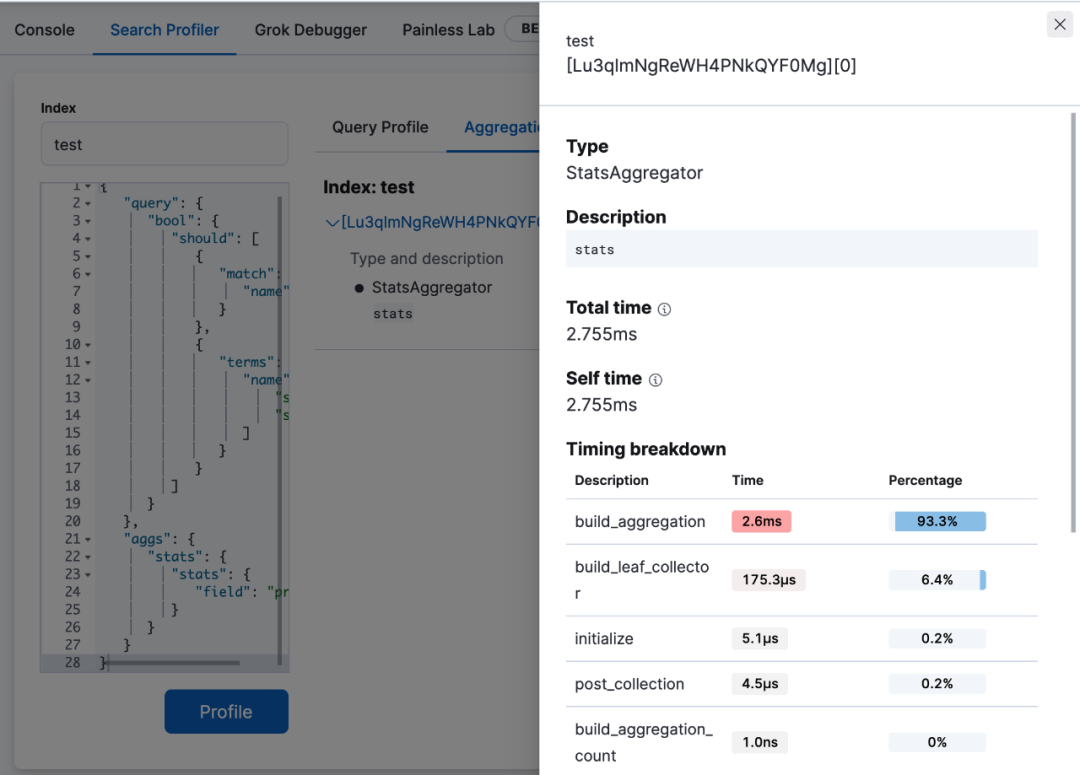
除了解析执行语句,也可以直接解析 profile 结果,将 profile API 返回 json 数据直接贴入查询 DSL (Elasticsearch 查询语句)的区域执行。
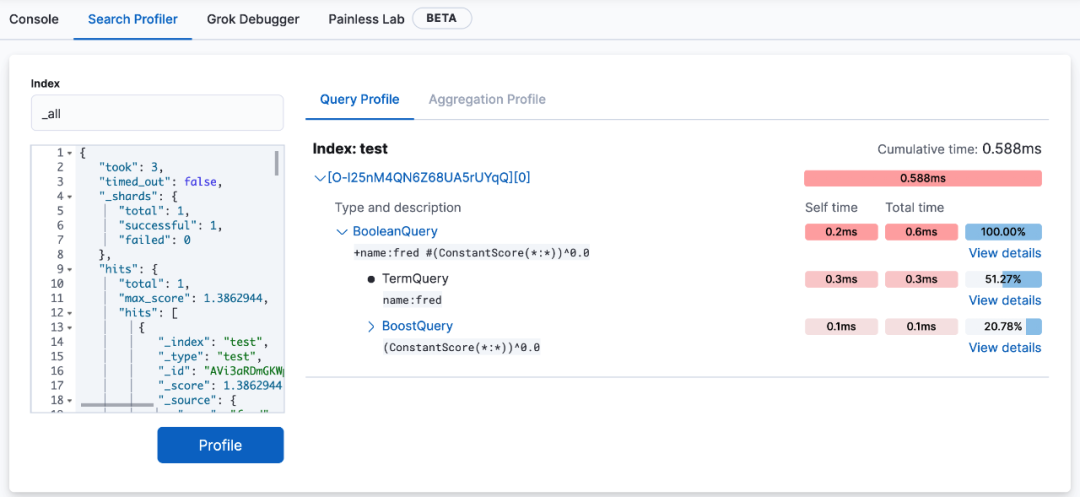
kibana 的 Search Profiler 的一个最大优势在于,清晰明了的展现了耗时分布,关注每个执行类的 self time 可以快速找到查询语句中最大的耗时条件。
不管是 Profile API 还是 kibana 的 Search Profiler,提供的只是 ES 执行查询各阶段的方法细节。
想要判断出各个阶段的执行效率是否最佳,有没有使用误区,我们还得从 ES 查询主要阶段说起。
2、Elatsicsearch 检索核心原理
ES 是一个分布式系统,一个索引数据查询需要汇总每个索引分片的结果。
如下图,search 请求发送给 ES 后,会由内部的协调节点发送到数据节点,由数据节点上的分片去执行具体的查询任务。
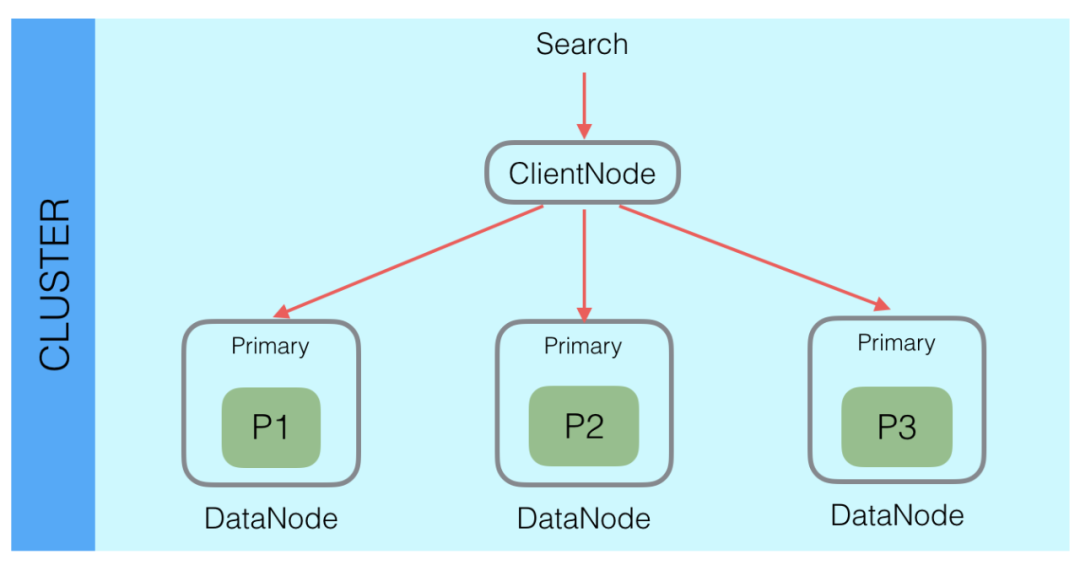
同时,大多数的 ES 查询请求是一个二阶段的查询。
第一阶段数据节点上的分片接收到协调节点传来的查询请求,分片执行查询任务后,会将查询到匹配的 DocID 反馈给协调节点,协调节点会对各个分片的结果进行汇总。
第二阶段协调节点根据汇总后的 DocID,到数据对应的分片上去获取完整文档。
整个过程叫做 query and fetch,query 和 fetch 也是分片在这两个阶段主要执行的任务,也是 profile 主要分析的阶段(低版本只分析 query 阶段)。
进行二阶段查询的主要原因是为了减少 fetch 阶段的资源损耗,获取完整的文档信息涉及数据文件的读取和解压缩,需要相对多的 IO 和 cpu 资源。
为了保证数据的召回率和准确性,query 阶段需要在每个分片上获取查询完整结果,比如一个查询需要 Top 10 的结果,每个分片都会找出它的 Top 10,返回给协调节点。如果有 10 个分片,那么就需要返回 100 个结果,再由协调节点排出所有分片的 Top 10。
如果由一阶段完成,则需要 fetch 100 个文档,二阶段则只需要 fetch 10 个文档。
完整的二阶段查询流程如下图:
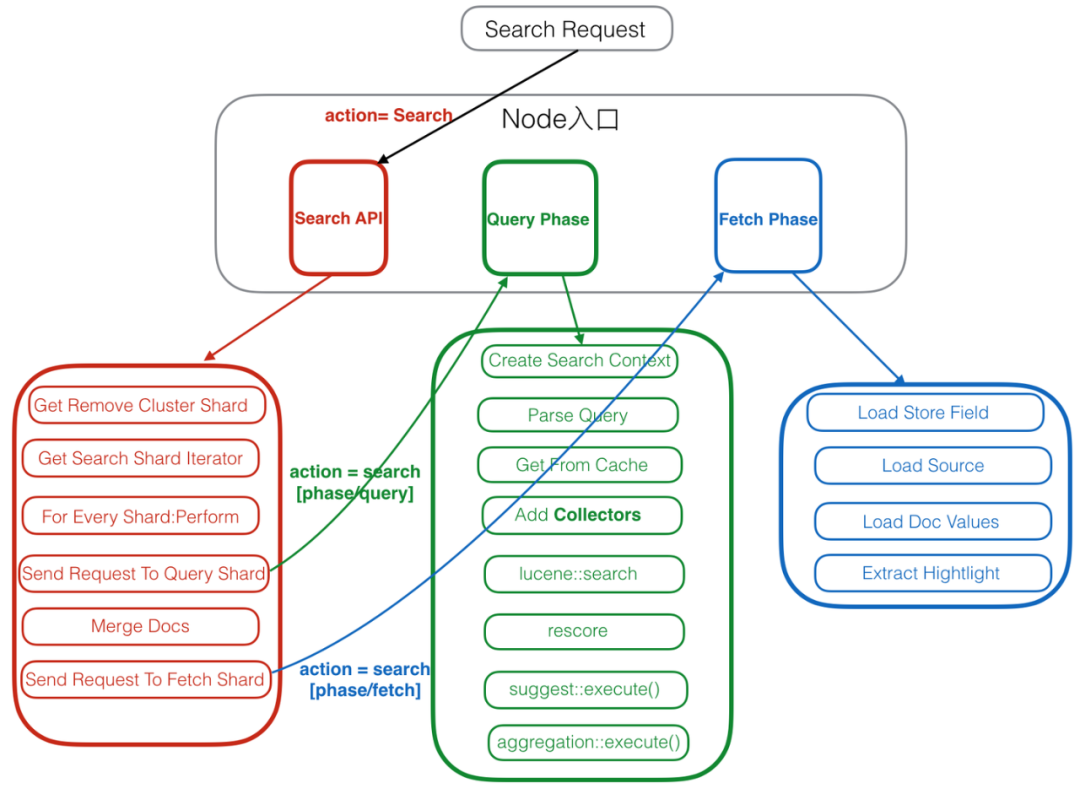
注:这里的流程图来自于文末的参考文档《Elasticsearch内核解析 - 查询篇》
3、Profile API 可解析的阶段
现在我们来看看 Profile API 可以解析的阶段。
3.1 query 查询阶段
Query 阶段是一阶段查询的主体,我理解是主要在二阶段查询流程中lucene::search和rescore这2个环节,这里 Profile API 将查询涉及的 lucene 执行代码类构成的一个查询树,这个查询树通过名称和描述把查询条件与执行类进行完整的勾兑,这样可以精确定位到是哪个查询条件造成了慢查询的主要耗时。
查询树重写的过程是将查询语句拆分成一个个不可被拆解的基础查询(比如 term 查询)的过程。
大部分时候查询树的结构与查询 DSL 的结构相似,有些情况下会重写的面目全非,比如:ngram 分词器,它会根据 ngram 分词器将查询内容进行细维度的拆解,最终形成一大堆 TermQuery。
下面一个例子是一个 match 查询的拆解,首先来看查询条件。
GET /_search
{
"query": {
"match": {
"message": {
"query": "get search"
}
}
}
}返回的结果。
"query": [
{
"type": "BooleanQuery",
"description": "message:get message:search",
"time_in_nanos": "11972972",
"breakdown": {...},
"children": [
{
"type": "TermQuery",
"description": "message:get",
"time_in_nanos": "3801935",
"breakdown": {...}
},
{
"type": "TermQuery",
"description": "message:search",
"time_in_nanos": "205654",
"breakdown": {...}
}
]
}
]这里的主要过程:
将 match 查询重写成一个 boolean 查询,这个 boolean 查询描述是
message:get message:search,展现了其总耗时(包括它的子查询耗时)和 breakdown。boolean 查询下还有两个子查询,是对 message 字段进行 get 和 search 这两个文本的 TermQuery。
分别展示了 TermQuery 的耗时/描述/breakdown。
值得注意的是,Query 阶段是 ES 查询中最容易出现慢查询的阶段。
3.2 collector 聚集阶段
Collector 也由各类的子 Collector 组成,它们的主要目标是在分片内收集各个 segment 的查询结果,实现排序,对自定义结果集过滤和收集等,这也导致了在查询流程中,Add Collectors在执行 lucene 的 search 之前。
Collector 耗时独立于 Query 耗时。
它们是独立进行计算和组合的。由于 Lucene 执行的性质,不可能将来自 Collector 的耗时“合并”到 Query 部分。
"collector": [
{
"name": "QueryPhaseCollector",
"reason": "search_query_phase",
"time_in_nanos": 775274,
"children" : [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": 775274
}
]
}
]Collector 提供的信息相对较少只提供了名称/原因/耗时。各类原因如下:
search_top_hits:对文档进行评分和排序的收集器。这是最常见的收集器,在大多数简单搜索中都会看到
search_count:仅统计符合查询条件的文档数量但不获取源的收集器。当size: 0指定 时,可以看到此信息
search_query_phase:一个收集器,将收集热门匹配项以及聚合作为查询阶段的一部分。它支持在n找到匹配文档后终止搜索执行(当 terminate_after指定时),以及仅返回得分大于的匹配文档n(当min_score提供时)。此外,它还能够根据提供的过滤匹配的热门匹配项post_filter。
search_timeout:在指定时间段后停止执行的收集器。当timeout指定了顶级参数时,就会出现这种情况。
aggregation:Elasticsearch 用于针对查询范围运行聚合的收集器。单个aggregation 收集器用于收集所有聚合的文档,因此您将在名称中看到聚合列表。
global_aggregation:针对全局查询范围(而不是指定查询)执行聚合的收集器。
3.3 rewrite 重写阶段
Lucene中的所有查询都经历了一个“重写”过程。查询(及其子查询)可能被重写一次或多次,直到只剩基础查询。
这个过程允许Lucene执行优化,例如删除冗余子句,替换一个查询以获得更有效的执行路径等。
例如,Boolean→Boolean→TermQuery可以重写为TermQuery,最终把 boolean 查询全都解析完。Query 查询树的变化也正是这个重写过程的体现。
重写过程复杂且难以显示,因为查询可能会发生巨大变化。总重写时间不是显示中间结果,该值是累积的,包含重写所有查询的总时间。
3.4 aggregations 聚合阶段
聚合部分的结构与 Query 部分类似,也是将查询树的结构展现出来。
有时候聚合可能会返回 debug 信息,这些信息描述了聚合的底层执行的特性,但大部分情况下没什么用。随着版本、聚合和聚合执行策略等条件的变化,这些信息差异很大。
3.5 fetch 获取阶段
这个就是二阶段查询中 fetch 阶段的耗时分析。
其主要内容就是加载 store_field/source/docvalue 三类存储信息。使用者也可以根据这三类字段处理格式的使用耗时,进行实际方案的选择。
其中,next_reader展示的是每个 segment 的读取计数和耗时,load_stored_fields中加载存储字段所花费的时间。
Debug 包含的是一些非耗时信息,特别是会展示 stored_fields 列出的 fetch 必须加载的存储字段;如果它是一个空列表,那么 fetch 将完全跳过加载存储字段。
4、使用局限
当然 Profile API 和 kibana 的 Search Profiler 也有相关的使用限制:
Profile API 不会测试网络的开销。所有的耗时数据不包含节点间的网络耗时。
Profile API 不包含在任务对列拥堵耗时、内存构建耗时、协调节点合并的耗时。
kibana-Search Profiler 并不完全展示 Profile API 的信息。比如没有 fetch 阶段;没有底层方法的执行次数。
kibana-Search Profiler 统计的总耗时是各个分片耗时的 sum 值,而一个查询的耗时取决于各分片耗时的 max 值。
5、小结
在 Elasticsearch 中,分片是一个最小级别的“工作单元”,它保存了索引中所有数据的一部分,同时每一个分片还是一个Lucene实例。
因此 Elasticsearch 分片执行查询过程基础类都与 lucene 相关,了解 lucene 的查询类可以增加对查询执行细节的理解。
相比起 lucene 的学习成本,Profile API 则提供了一种更为直观高效又低成本的慢查询分析工具。
通过聚焦各个执行阶段的耗时,我们直接可以定位到最大耗时的查询条件,它有可能是整个查询过于复杂,也有可能是某个字段类型不适合查询的场景。
也就是说,解决慢查询的方法并不一定要从 ES/lucene 本身去寻找,因为造成慢查询的原因并不只源于程序本身,它会是各种各样的原因,甚至是系统配置的错误、网络不稳定等等。
而 Profile API 给我们提供了更直接的印证。
6、更多慢查询优化建议
除了使用 Profile API 定位耗时的查询条件外,这里附带一些慢查询优化的建议,供读者参考:
6.1 合理利用缓存
ES 设计了多种缓存模式,有效利用缓存能保持查询的低延迟,做好缓存的监控。
6.2 设计好字段类型
特别是针对关键词字段,number 和 keyword 类型在查询和聚合方面有完全不同的查询效率,资源足够的情况下,设计双字段。
有兴趣的读一下这篇,
https://elasticsearch.cn/article/446
6.3 区分精确匹配和全文检索的使用场景。
精确匹配注重查询效率但是需要设计好数据模型;
全文检索可以面对自然语言信息的提炼,但是解析效果依赖分词器,并占用资源较多。
6.4 注意 MultiTermQuery 的出现
MultiTermQuery 是 wildcard/正则/前缀等查询常见的执行子类,这些查询容易引发大规模的资源消耗。
6.5 灵活使用 doc value
Fetch 阶段的高耗时,可以通过行存属性 source 与列存属性 doc value 的读取测试比较来选取最优方案。
7、附加 breakdown:lucene 执行类的类属方法
这里的介绍主要用于参考,lucene 实现类的方法是各种基础算法的实现,优化或者规避这些方法造成的高耗时需要对 ES 源码以及 lucene 数据文件有相当的理解和知识储备。
这也导致了,即便能看到慢查询具体的花费时间在哪个方法上,你也没办法轻易的改变它(除非自己重新实现基础的算法去维护私有版本或者贡献给社区 PR)。
每个阶段各个主要方法的耗时体现在 breakdown 内,下面做了详尽汇总,仅供参考:
7.1 query 阶段
| 方法名 | 含义 | 涉及lucene的类或者方法 |
|---|---|---|
| create_weight | Lucene要求每个查询生成一个Weight对象,这个对象作为一个临时上下文对象来保存多个IndexSearcher与query相关的状态。权重度量显示了这个过程需要多长时间 | Query抽象类createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost):Constructs an appropriate Weight implementation for this query. |
| build_scorer | 此参数显示为查询构建Scorer所需的时间。Scorer是一种迭代匹配文档并为每个文档生成分数的机制(例如,“foo”与文档的匹配程度如何?)注意,这记录了生成Scorer对象所需的时间,而不是实际对文档进行评分。一些查询的Scorer初始化速度更快或更慢,这取决于优化、复杂性等。如果启用和/或适用于查询,这还可以显示与缓存相关的时间 | Scorer抽象类:A Scorer exposes an iterator() over documents matching a query in increasing order of doc id. |
| next_doc | Lucene 方法next_doc返回与查询匹配的下一个文档的 Doc ID。此统计数据显示确定下一个匹配的文档所需的时间,该过程根据查询的性质而有很大差异,不同的实现类以及数据结构会有完全不同的效率。Next_doc 是 advance() 的一种特殊形式,对于 Lucene 中的许多查询来说更为方便。它相当于 advance(docId() + 1) | DISI 抽象类 nextDoc():Advances to the next document in the set and returns the doc it is currently on, or NO_MORE_DOCS if there are no more docs in the set. |
| advance | advance是 next_doc 的“低级”版本:它用于查找下一个匹配的文档,但需要调用查询执行额外的任务,例如识别和跳过跳过等。但是,并非所有查询都可以使用 next_doc,因此advance这些查询也会计时。 | DISI抽象类 advance(int target):Advances to the first beyond the current whose document number is greater than or equal to target, and returns the document number itself. |
| match | 某些查询(例如短语查询)使用“两阶段”过程匹配文档。首先,文档“近似”匹配,如果近似匹配,则使用更严格(且昂贵)的过程再次检查。第二阶段验证是统计数据所衡量的match。由于只有少数查询使用这个两阶段过程,因此match统计数据通常为零 | PhraseMatcher类:Base class for exact and sloppy phrase matching |
| score | 这记录了通过评分器对特定文档进行 Scorer 所花费的时间 | Scorer 抽象类 score():Returns the score of the current document matching the query. |
| *_count | 记录特定方法的调用次数。例如,"next_doc_count": 2, 表示该nextDoc()方法在两个不同的文档上被调用。这可以通过比较不同查询类之间的计数来帮助判断查询的选择性。 |
7.2 aggregations 阶段
| 方法名 | 含义 |
|---|---|
| build_aggregation | 创建聚合对象需要的时间 |
| initialize | 初始化聚合所耗费的时间 |
| collect | 对聚合结果进行 collect |
| build_leaf_collector | 运行聚合的 getLeafCollector() 方法所花费的时间 |
| post_collection | post 查询 collect 耗时 |
| reduce | reduce 属性保留以供将来使用,并且总是返回0 |
| *_count | 记录特定方法的调用次数 |
8、参考资料
[1] kibana search profiler:
https://www.elastic.co/guide/en/kibana/current/xpack-profiler.html
[2] Profile API:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-profile.html
[3] Elasticsearch内核解析 - 查询篇:
https://zhuanlan.zhihu.com/p/34674517
作者介绍
金多安,Elastic 认证专家,Elastic 资深运维工程师,死磕 Elasticsearch 知识星球嘉宾,星球Top活跃技术专家,搜索客社区日报责任编辑
铭毅天下审稿并做了部分微调。
更多推荐
Elasticsearch 使用误区之一——将 Elasticsearch 视为关系数据库!
Elasticsearch 使用误区之二——频繁更新文档
Elasticsearch 使用误区之三——分片设置不合理
Elasticsearch 使用误区之四——不合理的使用 track_total_hits
Elasticsearch Filter 缓存加速检索的细节,你知道吗?
深入解析 Elasticsearch IK 分词器:ik_smart 和 ik_max_word 的区别与应用场景
图解 Elasticsearch 的 Fielddata Cache 使用与优化
探究:Elasticsearch 文档的 _id 是 Lucene 的 docid 吗?
《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!