题目
一、prim
本题是最小生成树的模板题。最小生成树 可以使用 prim算法 也可以使用 kruskal算法计算出来。
最小生成树是所有节点的最小连通子图, 即:以最小的成本(边的权值)将图中所有节点链接到一起。
图中有n个节点,那么一定可以用 n - 1 条边将所有节点连接到一起。
那么如何选择 这 n-1 条边 就是 最小生成树算法的任务所在。
例如本题示例中的无向有权图为:

那么在这个图中,如何选取 n-1 条边 使得 图中所有节点连接到一起,并且边的权值和最小呢?
(图中为n为7,即7个节点,那么只需要 n-1 即 6条边就可以讲所有顶点连接到一起)
prim算法 是从节点的角度 采用贪心的策略 每次寻找距离 最小生成树最近的节点 并加入到最小生成树中。
prim算法核心就是三步:
- 第一步,选距离生成树最近节点
- 第二步,最近节点加入生成树
- 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
在prim算法中,有一个数组特别重要,这里我起名为:minDist。
刚刚我有讲过 “每次寻找距离 最小生成树最近的节点 并加入到最小生成树中”,那么如何寻找距离最小生成树最近的节点呢?
minDist数组 用来记录 每一个节点距离最小生成树的最近距离。
(示例中节点编号是从1开始,minDist数组下标我也从 1 开始计数,下标0 就不使用了,这样 下标和节点标号就可以对应上了)
1 初始状态
minDist 数组 里的数值初始化为 最大数,因为本题 节点距离不会超过 10000,所以 初始化最大数为 10001就可以。
现在 还没有最小生成树,默认每个节点距离最小生成树是最大的,这样后面我们在比较的时候,发现更近的距离,才能更新到 minDist 数组上。
如图:

开始构造最小生成树
2
1、第一步:选距离生成树最近节点
选择距离最小生成树最近的节点,加入到最小生成树,刚开始还没有最小生成树,所以随便选一个节点加入就好(因为每一个节点一定会在最小生成树里,所以随便选一个就好),那选择节点1 (符合遍历数组的习惯,第一个遍历的也是节点1)
2、第二步:最近节点加入生成树
此时 节点1 已经算最小生成树的节点。
3、第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新所有节点距离最小生成树的距离,如图:

注意下标0,就不管它了,下标 1 与节点 1 对应,这样可以避免把节点搞混。
此时所有非生成树的节点距离 最小生成树(节点1)的距离都已经跟新了 。
- 节点2 与 节点1 的距离为1,比原先的 距离值10001小,所以更新minDist[2]。
- 节点3 和 节点1 的距离为1,比原先的 距离值10001小,所以更新minDist[3]。
- 节点5 和 节点1 的距离为2,比原先的 距离值10001小,所以更新minDist[5]。
注意图中标记了 minDist数组里更新的权值,是哪两个节点之间的权值,例如 minDist[2] =1 ,这个 1 是 节点1 与 节点2 之间的连线,清楚这一点对最后我们记录 最小生成树的权值总和很重要。
3
1、第一步:选距离生成树最近节点
选取一个距离 最小生成树(节点1) 最近的非生成树里的节点,节点2,3,5 距离 最小生成树(节点1) 最近,选节点 2(其实选 节点3或者节点2都可以,距离一样的)加入最小生成树。
2、第二步:最近节点加入生成树
此时 节点1 和 节点2,已经算最小生成树的节点。
3、第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来,更新节点距离最小生成树的距离,如图:
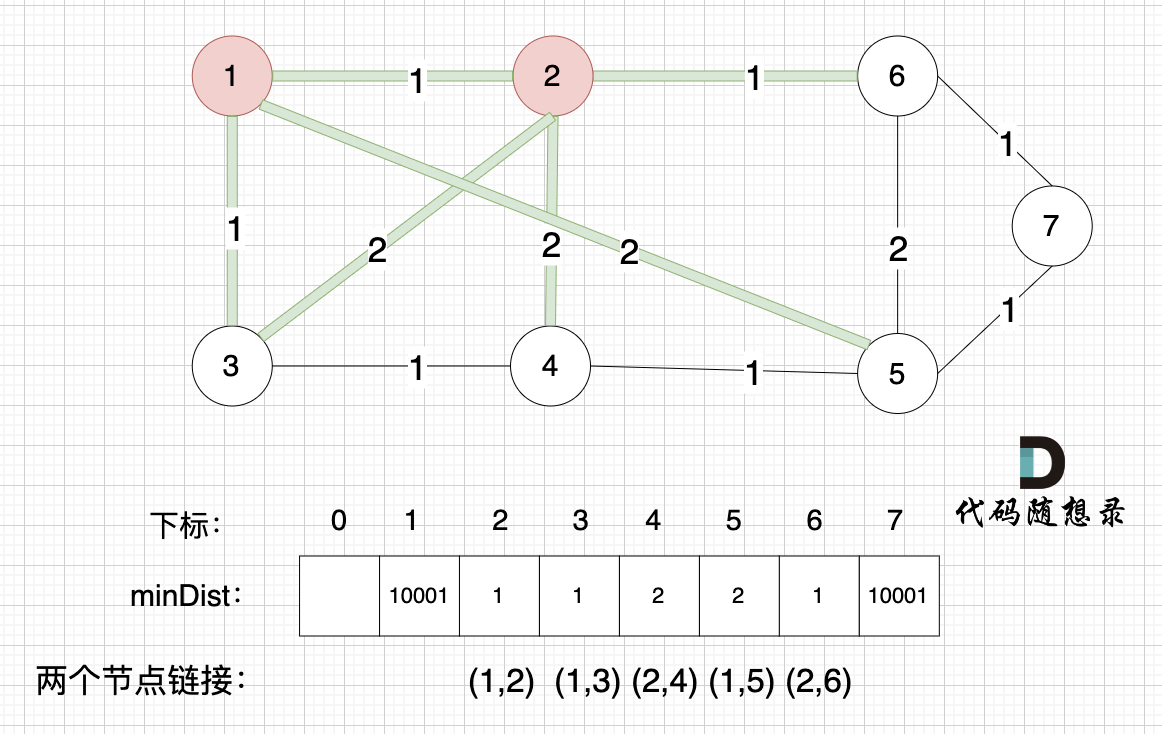
此时所有非生成树的节点距离 最小生成树(节点1、节点2)的距离都已经更新了 。
- 节点3 和 节点2 的距离为2,和原先的距离值1 小,所以不用更新。
- 节点4 和 节点2 的距离为2,比原先的距离值10001小,所以更新minDist[4]。
- 节点5 和 节点2 的距离为10001(不连接),所以不用更新。
- 节点6 和 节点2 的距离为1,比原先的距离值10001小,所以更新minDist[6]。
4
1、第一步:选距离生成树最近节点
选择一个距离 最小生成树(节点1、节点2) 最近的非生成树里的节点,节点3,6 距离 最小生成树(节点1、节点2) 最近,选节点3 (选节点6也可以,距离一样)加入最小生成树。
2、第二步:最近节点加入生成树
此时 节点1 、节点2 、节点3 算是最小生成树的节点。
3、第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:
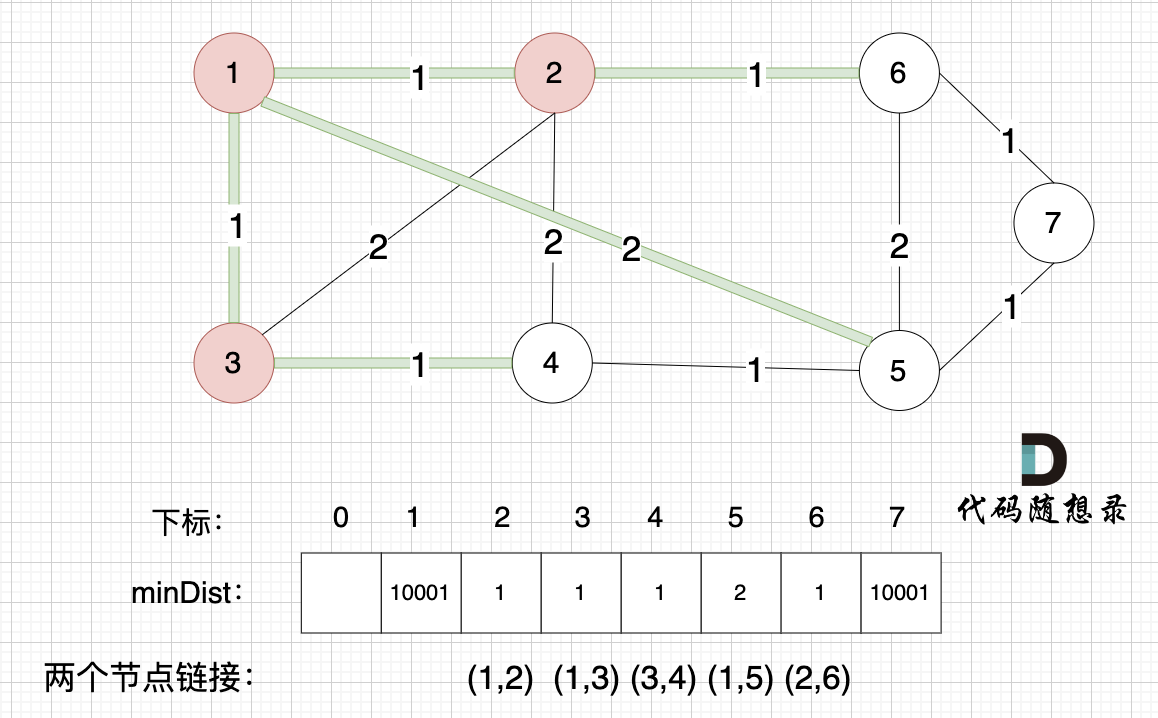
所有非生成树的节点距离 最小生成树(节点1、节点2、节点3 )的距离都已经更新了 。
- 节点 4 和 节点 3的距离为 1,和原先的距离值 2 小,所以更新minDist[4]为1。
为什么只比较 节点4 和 节点3 的距离呢?因为节点3加入 最小生成树后,非 生成树节点 只有 节点 4 和 节点3是链接的,所以需要重新更新一下 节点4距离最小生成树的距离,其他节点距离最小生成树的距离 都不变。
5
1、第一步:选距离生成树最近节点
继续选择一个距离 最小生成树(节点1、节点2、节点3) 最近的非生成树里的节点:

minDist数组 是记录了 所有非生成树节点距离生成树的最小距离,所以 从数组里我们能看出来,非生成树节点 4 和 节点 6 距离 生成树最近。
任选一个加入生成树,我们选 节点4(选节点6也行) 。
注意,我们根据 minDist数组,选取距离 生成树 最近的节点 加入生成树,那么 minDist数组里记录的其实也是 最小生成树的边的权值。
2、第二步:最近节点加入生成树
此时 节点1、节点2、节点3、节点4 算是 最小生成树的节点。
3、第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:
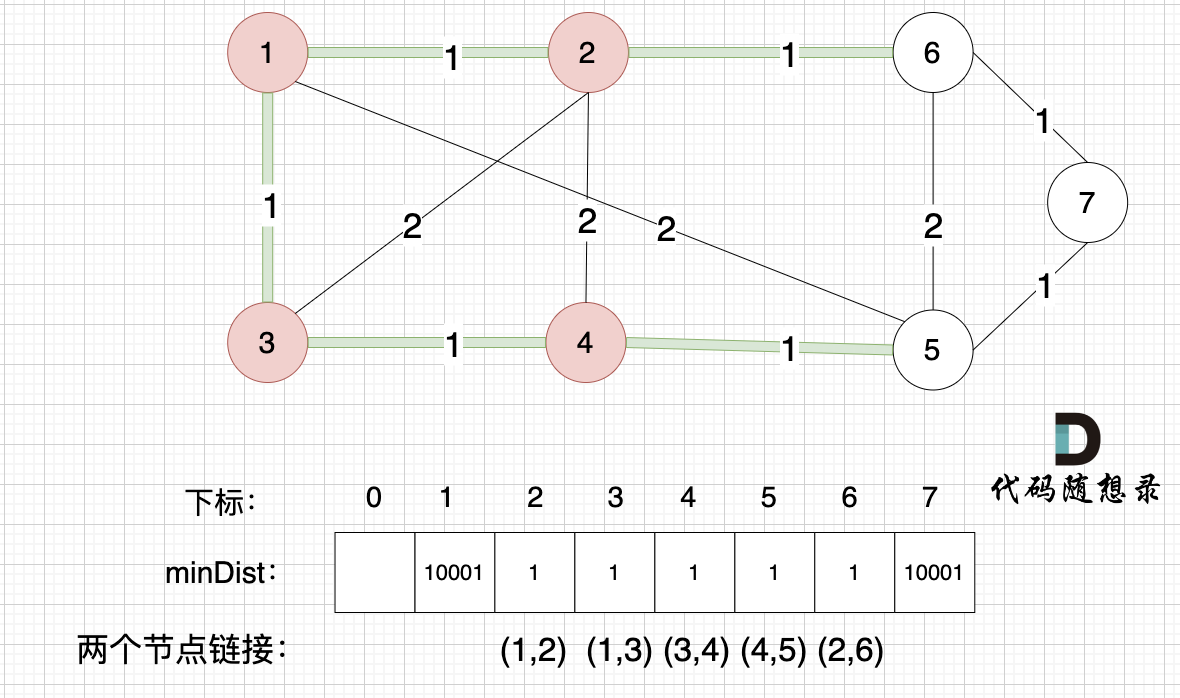
minDist数组已经更新了 所有非生成树的节点距离 最小生成树(节点1、节点2、节点3、节点4 )的距离 。
- 节点 5 和 节点 4的距离为 1,和原先的距离值 2 小,所以更新minDist[5]为1。
6
1、第一步:选距离生成树最近节点
继续选距离 最小生成树(节点1、节点2、节点3、节点4 )最近的非生成树里的节点,只有 节点 5 和 节点6。
选节点5 (选节点6也可以)加入 生成树。
2、第二步:最近节点加入生成树
节点1、节点2、节点3、节点4、节点5 算是 最小生成树的节点。
3、第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来更新节点距离最小生成树的距离,如图:
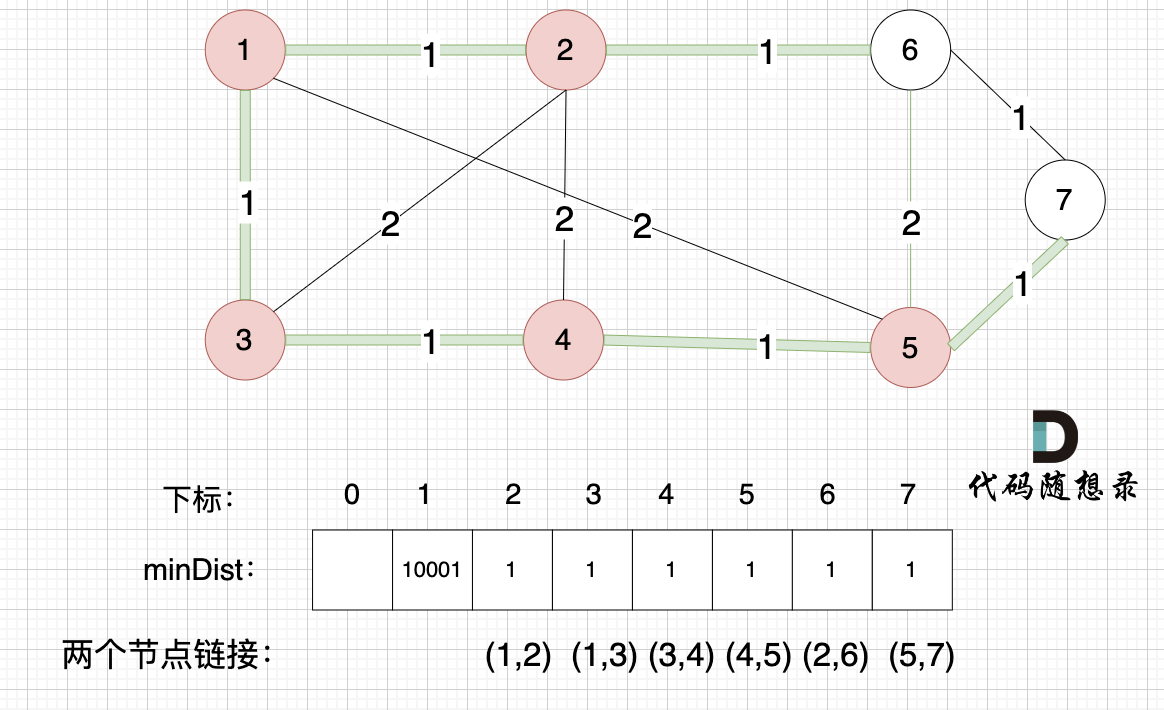
minDist数组已经更新了 所有非生成树的节点距离 最小生成树(节点1、节点2、节点3、节点4 、节点5)的距离 。
- 节点 6 和 节点 5 距离为 2,比原先的距离值 1 大,所以不更新
- 节点 7 和 节点 5 距离为 1,比原先的距离值 10001小,更新 minDist[7]
7
1、第一步:选距离生成树最近节点
继续选距离 最小生成树(节点1、节点2、节点3、节点4 、节点5)最近的非生成树里的节点,只有 节点 6 和 节点7。
2、第二步:最近节点加入生成树
选节点6 (选节点7也行,距离一样的)加入生成树。
3、第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
节点1、节点2、节点3、节点4、节点5、节点6 算是 最小生成树的节点 ,接下来更新节点距离最小生成树的距离,如图:
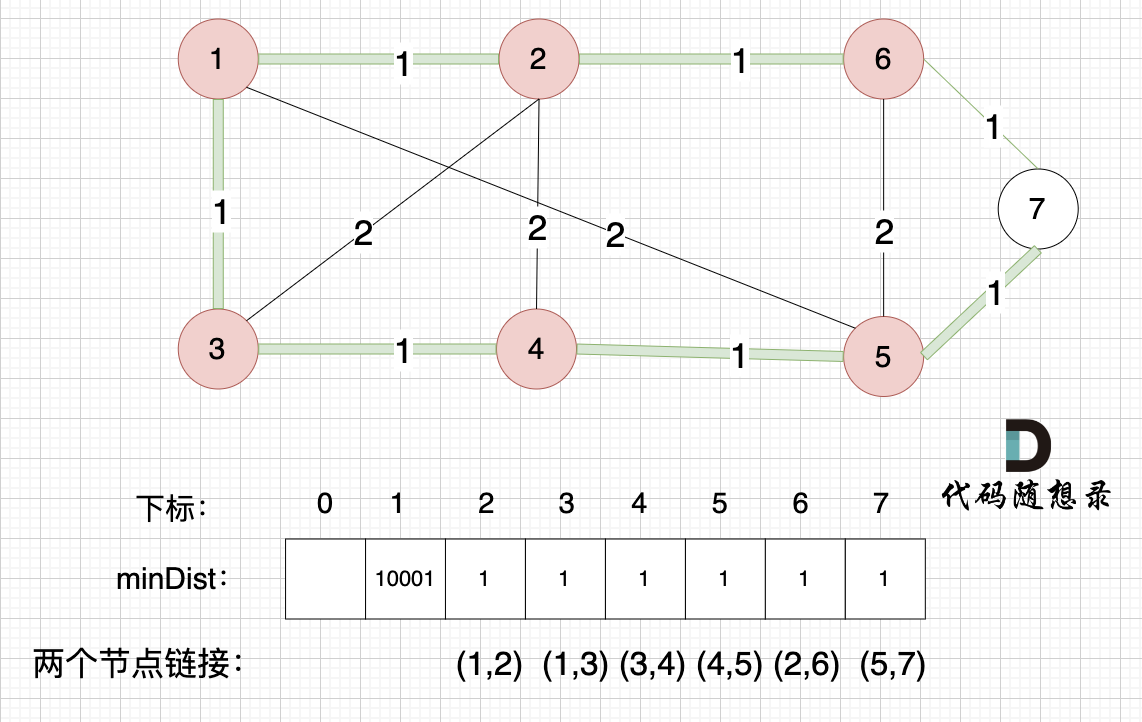
类推,最后,节点7加入生成树,如图:

最后
最后就生成了一个 最小生成树, 绿色的边将所有节点链接到一起,并且 保证权值是最小的,因为我们在更新 minDist 数组的时候,都是选距离 最小生成树最近的点 加入到树中。minDist数组 也就是记录的是最小生成树所有边的权值。
那么我们要求最小生成树里边的权值总和 就是 把 最后的 minDist 数组 累加一起。
#include<iostream>
#include<vector>
#include <climits>
using namespace std;
int main() {
int v, e;
int x, y, k;
cin >> v >> e;
// 填一个默认最大值,题目描述val最大为10000
vector<vector<int>> grid(v + 1, vector<int>(v + 1, 10001));
while (e--) {
cin >> x >> y >> k;
// 因为是双向图,所以两个方向都要填上
grid[x][y] = k;
grid[y][x] = k;
}
// 所有节点到最小生成树的最小距离
vector<int> minDist(v + 1, 10001);
// 这个节点是否在树里
vector<bool> isInTree(v + 1, false);
// 我们只需要循环 n-1次,建立 n - 1条边,就可以把n个节点的图连在一起
for (int i = 1; i < v; i++) {
// 1、prim三部曲,第一步:选距离生成树最近节点
int cur = -1; // 选中哪个节点 加入最小生成树
int minVal = INT_MAX;
for (int j = 1; j <= v; j++) { // 1 - v,顶点编号,这里下标从1开始
// 选取最小生成树节点的条件:
// (1)不在最小生成树里
// (2)距离最小生成树最近的节点
if (!isInTree[j] && minDist[j] < minVal) {
minVal = minDist[j];
cur = j;
}
}
// 2、prim三部曲,第二步:最近节点(cur)加入生成树
isInTree[cur] = true;
// 3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
// cur节点加入之后, 最小生成树加入了新的节点,那么所有节点到 最小生成树的距离(即minDist数组)需要更新一下
// 由于cur节点是新加入到最小生成树,那么只需要关心与 cur 相连的 非生成树节点 的距离 是否比 原来 非生成树节点到生成树节点的距离更小了呢
for (int j = 1; j <= v; j++) {
// 更新的条件:
// (1)节点是 非生成树里的节点
// (2)与cur相连的某节点的权值 比 该某节点距离最小生成树的距离小
// 很多录友看到自己 就想不明白什么意思,其实就是 cur 是新加入 最小生成树的节点,那么 所有非生成树的节点距离生成树节点的最近距离 由于 cur的新加入,需要更新一下数据了
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}
}
// 统计结果
int result = 0;
for (int i = 2; i <= v; i++) { // 不计第一个顶点,因为统计的是边的权值,v个节点有 v-1条边
result += minDist[i];
}
cout << result << endl;
}
时间复杂度为 O(n^2),其中 n 为节点数量。
拓展
如果让打印出来 最小生成树的每条边呢? 或者说 要把这个最小生成树画出来呢?此时就需要把 最小生成树里每一条边记录下来。
此时有两个问题:
- 1、用什么结构来记录
- 2、如何记录
如果记录边,其实就是记录两个节点就可以,两个节点连成一条边。
使用一维数组就可以记录。 parent[节点编号] = 节点编号, 这样就把一条边记录下来了。(当然如果节点编号非常大,可以考虑使用map)
使用一维数组记录是有向边,不过我们这里不需要记录方向,所以只关注两条边是连接的就行。
parent数组初始化代码:
vector<int> parent(v + 1, -1);
接下来就是第二个问题,如何记录?
我们再来回顾一下 prim三部曲,
- 第一步,选距离生成树最近节点
- 第二步,最近节点加入生成树
- 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
既然 minDist数组 记录了 最小生成树的边,是不是就是在更新 minDist数组 的时候,去更新parent数组来记录一下对应的边呢。
所以 在 prim三部曲中的第三步,更新 parent数组,代码如下:
for (int j = 1; j <= v; j++) {
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
parent[j] = cur; // 记录最小生成树的边 (注意数组指向的顺序很重要)
}
}
如果是二维数组,来记录两个点链接,例如 parent[节点编号A][节点编号B] = 1 ,parent[节点编号B][节点编号A] = 1,来表示 节点A 与 节点B 相连,那就没有上面说的这个注意事项了,当然这么做的话,就是多开辟的内存空间。
以下是输出最小生成树边的代码,不算最后输出, 就额外添加了两行代码:
#include<iostream>
#include<vector>
#include <climits>
using namespace std;
int main() {
int v, e;
int x, y, k;
cin >> v >> e;
vector<vector<int>> grid(v + 1, vector<int>(v + 1, 10001));
while (e--) {
cin >> x >> y >> k;
grid[x][y] = k;
grid[y][x] = k;
}
vector<int> minDist(v + 1, 10001);
vector<bool> isInTree(v + 1, false);
//加上初始化
vector<int> parent(v + 1, -1);
for (int i = 1; i < v; i++) {
int cur = -1;
int minVal = INT_MAX;
for (int j = 1; j <= v; j++) {
if (!isInTree[j] && minDist[j] < minVal) {
minVal = minDist[j];
cur = j;
}
}
isInTree[cur] = true;
for (int j = 1; j <= v; j++) {
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
parent[j] = cur; // 记录边
}
}
}
// 输出 最小生成树边的链接情况
for (int i = 1; i <= v; i++) {
cout << i << "->" << parent[i] << endl;
}
}
按照本题示例,代码输入如下:
1->-1
2->1
3->1
4->3
5->4
6->2
7->5
注意,这里是无向图,添加了箭头仅仅是为了方便看出是边的意思。
对比一下 边的链接情况:
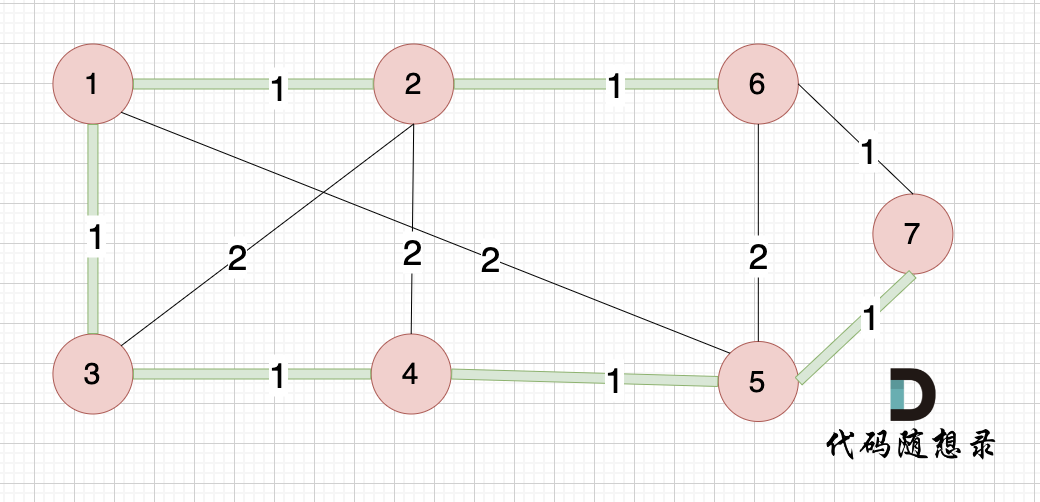
绿色的边 是最小生成树,和输出完全一致。
总结
prim算法三部曲:
- 第一步,选距离生成树最近节点
- 第二步,最近节点加入生成树
- 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
理解这三部曲之后,更重要的 就是理解 minDist数组。
minDist数组 是prim算法的灵魂,它帮助 prim算法完成最重要的一步,就是如何找到 距离最小生成树最近的点。
minDist数组 的含义:记录 每一个节点距离最小生成树的最近距离。
也正是 因为 minDist数组 的作用,根据 minDist数组,选取距离 生成树 最近的节点 加入生成树,那么 minDist数组里记录的其实也是 最小生成树的边的权值。
所以求 最小生成树的权值和 就是 计算后的 minDist数组 数值总和。
二、kruskal
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
kruscal的思路:
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
下面我们画图举例说明kruscal的工作过程。
依然以示例中,如下这个图来举例。

将图中的边按照权值有小到大排序,这样从贪心的角度来说,优先选 权值小的边加入到 最小生成树中。
排序后的边顺序为[(1,2) (4,5) (1,3) (2,6) (3,4) (6,7) (5,7) (1,5) (3,2) (2,4) (5,6)]
(1,2) 表示节点1 与 节点2 之间的边。权值相同的边,先后顺序无所谓。
开始从头遍历排序后的边。
选边(1,2),节点1 和 节点2 不在同一个集合,所以生成树可以添加边(1,2),并将 节点1,节点2 放在同一个集合。
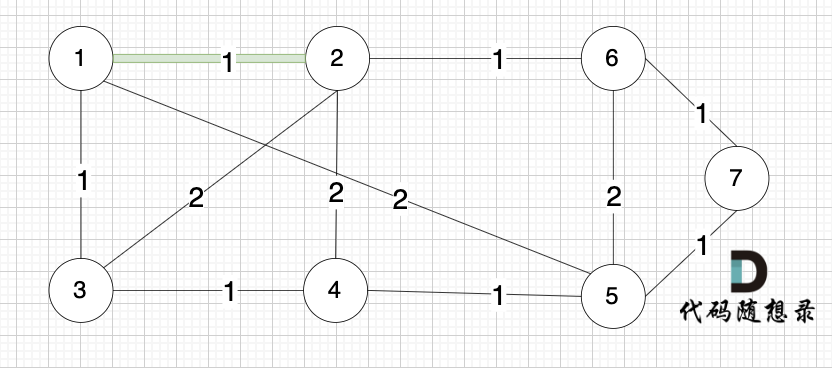
选边(4,5),节点4 和 节点 5 不在同一个集合,生成树可以添加边(4,5) ,并将节点4,节点5 放到同一个集合。

判断两个节点是否在同一个集合,就看图中两个节点是否有绿色的粗线连着就行
(以下选边是按照上面排序好的边的数组来选择的)
选边(1,3),节点1 和 节点3 不在同一个集合,生成树添加边(1,3),并将节点1,节点3 放到同一个集合。
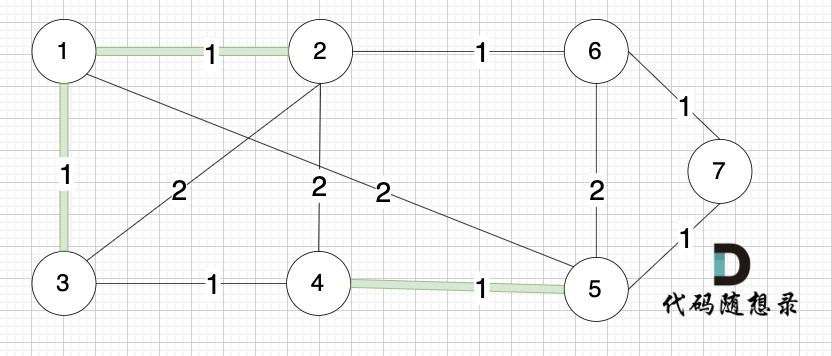
选边(2,6),节点2 和 节点6 不在同一个集合,生成树添加边(2,6),并将节点2,节点6 放到同一个集合。
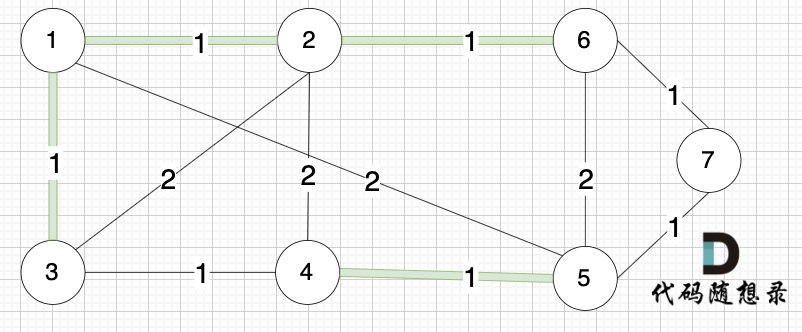
选边(3,4),节点3 和 节点4 不在同一个集合,生成树添加边(3,4),并将节点3,节点4 放到同一个集合。
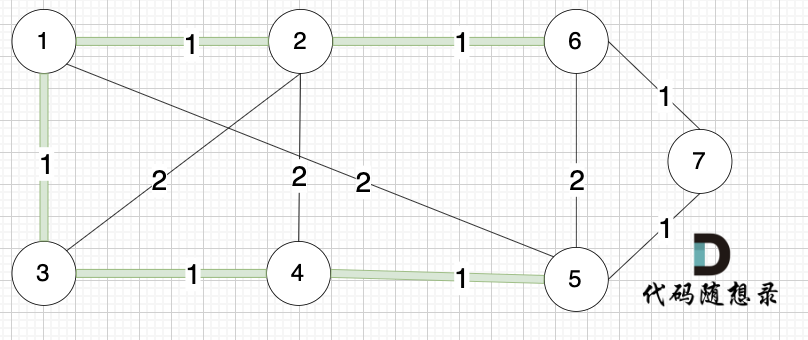
选边(6,7),节点6 和 节点7 不在同一个集合,生成树添加边(6,7),并将 节点6,节点7 放到同一个集合。
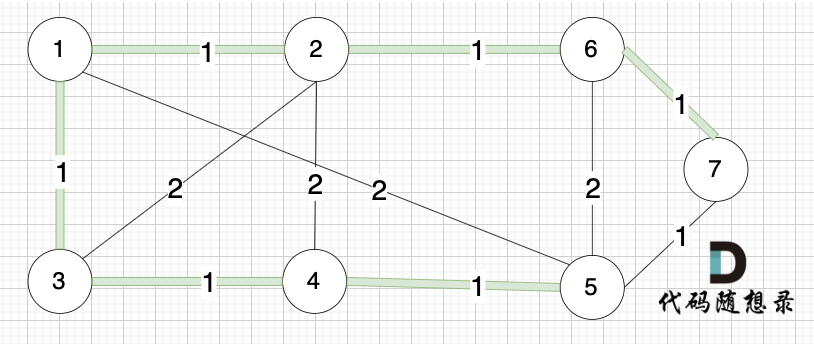
选边(5,7),节点5 和 节点7 在同一个集合,不做计算。
选边(1,5),两个节点在同一个集合,不做计算。
后面遍历 边(3,2),(2,4),(5,6) 同理,都因两个节点已经在同一集合,不做计算。
此时就已经生成了一个最小生成树,即:
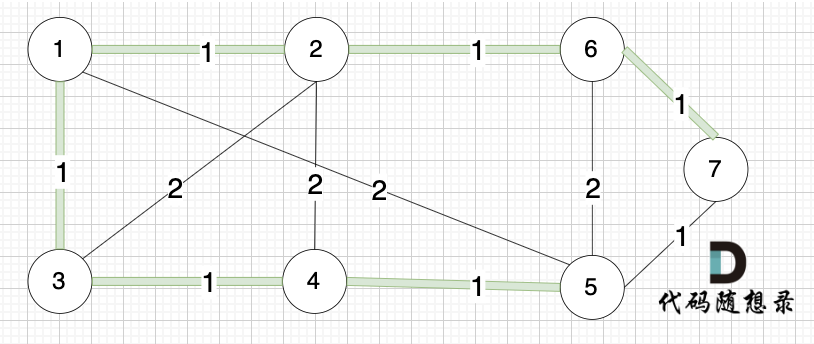
但在代码中,如果将两个节点加入同一个集合如何判断两个节点是否在同一个集合呢?
并查集主要就两个功能:
- 将两个元素添加到一个集合中
- 判断两个元素在不在同一个集合
这正好符合 Kruskal算法的需求
本题代码如下:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// l,r为 边两边的节点,val为边的数值
struct Edge {
int l, r, val;
};
// 节点数量
int n = 10001;
// 并查集标记节点关系的数组
vector<int> father(n, -1); // 节点编号是从1开始的,n要大一些
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
// 并查集的查找操作
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
}
// 并查集的加入集合
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
int main() {
int v, e;
int v1, v2, val;
vector<Edge> edges;
int result_val = 0;
cin >> v >> e;
while (e--) {
cin >> v1 >> v2 >> val;
edges.push_back({v1, v2, val});
}
// 执行Kruskal算法
// 按边的权值对边进行从小到大排序
sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {
return a.val < b.val;
});
// 并查集初始化
init();
// 从头开始遍历边
for (Edge edge : edges) {
// 并查集,搜出两个节点的祖先
int x = find(edge.l);
int y = find(edge.r);
// 如果祖先不同,则不在同一个集合
if (x != y) {
result_val += edge.val; // 这条边可以作为生成树的边
join(x, y); // 两个节点加入到同一个集合
}
}
cout << result_val << endl;
return 0;
}
时间复杂度:nlogn (快排) + logn (并查集) ,所以最后依然是 nlogn 。n为边的数量。
关于并查集时间复杂度,可以看我在 并查集理论基础 (opens new window)的讲解。
拓展一
如果题目要求将最小生成树的边输出的话,应该怎么办呢?
Kruskal 算法 输出边的话,相对prim 要容易很多,因为 Kruskal 本来就是直接操作边,边的结构自然清晰,不用像 prim一样 需要再将节点连成线输出边 (因为prim是对节点操作,而 Kruskal是对边操作,这是本质区别)
本题中,边的结构为:
struct Edge {
int l, r, val;
};
那么只需要找到 在哪里把生成树的边保存下来就可以了。
当判断两个节点不在同一个集合的时候,这两个节点的边就加入到最小生成树, 所以添加边的操作在这里:
vector<Edge> result; // 存储最小生成树的边
// 如果祖先不同,则不在同一个集合
if (x != y) {
result.push_back(edge); // 记录最小生成树的边
result_val += edge.val; // 这条边可以作为生成树的边
join(x, y); // 两个节点加入到同一个集合
}
整体代码如下
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
struct Edge {
int l, r, val;
};
int n = 10001;
vector<int> father(n, -1);
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]);
}
void join(int u, int v) {
u = find(u);
v = find(v);
if (u == v) return ;
father[v] = u;
}
int main() {
int v, e;
int v1, v2, val;
vector<Edge> edges;
int result_val = 0;
cin >> v >> e;
while (e--) {
cin >> v1 >> v2 >> val;
edges.push_back({v1, v2, val});
}
sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {
return a.val < b.val;
});
vector<Edge> result; // 存储最小生成树的边
init();
for (Edge edge : edges) {
int x = find(edge.l);
int y = find(edge.r);
if (x != y) {
result.push_back(edge); // 保存最小生成树的边
result_val += edge.val;
join(x, y);
}
}
// 打印最小生成树的边
for (Edge edge : result) {
cout << edge.l << " - " << edge.r << " : " << edge.val << endl;
}
return 0;
}
按照题目中的示例,打印边的输出为:
1 - 2 : 1
1 - 3 : 1
2 - 6 : 1
3 - 4 : 1
4 - 5 : 1
5 - 7 : 1
和我们 模拟画的图不一样,差别在于 代码生成的最小生成树中 节点5 和 节点7相连的。

其实造成这个差别 是对边排序的时候 权值相同的边先后顺序的问题导致的,无论相同权值边的顺序是什么样的,最后都能得出最小生成树。
拓展二
什么情况用哪个算法更合适呢。
Kruskal 与 prim 的关键区别在于,prim维护的是节点的集合,而 Kruskal 维护的是边的集合。 如果 一个图中,节点多,但边相对较少,那么使用Kruskal 更优。
节点未必一定要连着边那, 例如 这个图,但节点数量 和 上述我们讲的例子是一样的。
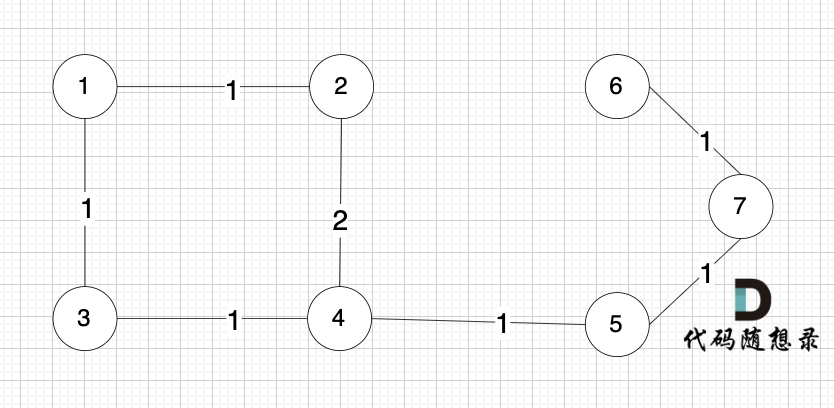
为什么边少的话,使用 Kruskal 更优呢?因为 Kruskal 是对边进行排序的后 进行操作是否加入到最小生成树。
边如果少,那么遍历操作的次数就少。在节点数量固定的情况下,图中的边越少,Kruskal 需要遍历的边也就越少。
而 prim 算法是对节点进行操作的,节点数量越少,prim算法效率就越优。
所以在 稀疏图中,用Kruskal更优。 在稠密图中,用prim算法更优。
边数量较少为稀疏图,接近或等于完全图(所有节点皆相连)为稠密图
Prim 算法 时间复杂度为 O(n^2),其中 n 为节点数量,它的运行效率和图中边树无关,适用稠密图。
Kruskal算法 时间复杂度 为 nlogn,其中n 为边的数量,适用稀疏图。