Ascend C是CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,兼具开发效率和运行性能。使用Ascend C,开发者可以基于昇腾AI硬件,高效的实现自定义的创新算法。
目前已经有越来越多的开发者使用Ascend C,我们将通过几期“Ascend C算子性能优化”专题分享,围绕开发者最为关心的算子性能优化环节,介绍Ascend C算子常用的优化技巧,帮助开发者自主构建出更优性能的算子。专题内容将围绕流水优化、搬运优化、内存优化、API使用优化以及Tiling优化等优化技巧,从方案讲解、优化案例、性能对比等多角度展开介绍。前期内容回顾:
《Ascend C算子性能优化实用技巧01——流水优化》
《Ascend C算子性能优化实用技巧02——内存优化》
下面进入第三期内容:Ascend C搬运优化,您将了解到以下优化技巧:
- 尽量一次搬运较大的数据块
- GM地址尽量512B对齐
- 高效使用搬运API
尽量一次搬运较大的数据块
搬运不同大小的数据块时,对带宽的利用率(有效带宽/理论带宽)不一样。根据实测经验,单次搬运数据长度16KB以上时,通常能较好地发挥出带宽的最佳性能。因此对于单次搬运,应考虑尽可能的搬运较大的数据块。下图展示了某款AI处理器上实测的不同搬运数据量下带宽的变化图。
测试数据与处理器型号相关,且实际测试时可能会存在略微抖动,具体带宽数值并不一定和下文的测试数据严格一致。
图1 UB->GM方向不同搬运数据量下实际占用带宽的变化

图2 GM->UB方向不同搬运数据量下实际占用带宽的变化

GM地址尽量512B对齐
由于AI处理器内部设计约束,从GM向Local Memory搬运数据时,保证GM地址512B对齐可以最高效的发挥出带宽的效率。如下图示例,展示了在512B对齐以及32B对齐情况下单核的带宽效率:搬运同等数据量,带宽差距最大的情况,32B对齐场景只能达到512B对齐场景的70%。
本性能优化手段仅针对Atlas A2训练系列产品/Atlas 800I A2推理产品生效。
测试数据与处理器型号相关,且实际测试时可能会存在略微抖动,具体带宽数值并不一定和下文的测试数据严格一致。
图3 GM->UB方向512B对齐和32B对齐实测带宽的差异对比

图4 UB->GM方向512B对齐和32B对齐实测带宽的差异对比

高效使用搬运API
使用搬运API时,应该尽可能地使用API的srcStride/dstStride/blockLen/blockCount等参数实现连续搬运或者固定间隔搬运,而不是使用for循环,二者效率差距极大。如下图示例,图片的每一行为16KB,需要从每一行中搬运前2KB,针对这种场景,使用srcStride/dstStride/blockLen/blockCount等参数可以达到一次搬完的效果,每次搬运32KB;如果使用for循环遍历每行,每次仅能搬运2KB。参考“尽量一次搬运较大的数据块”章节介绍的搬运数据量和实际带宽的关系,建议通过DataCopy包含srcStride/dstStride/blockLen/blockCount的接口一次搬完。
图5 待搬运数据排布

【反例】
// 搬运数据存在间隔,从GM上每行16KB中搬运2KB数据, 共16行
LocalTensor<float> tensorIn;
GlobalTensor<float> tensorGM;
...
constexpr int32_t copyWidth = 2 * 1024 / sizeof(float);
constexpr int32_t imgWidth = 16 * 1024 / sizeof(float);
constexpr int32_t imgHeight = 16;
// 使用for循环,每次只能搬运2K,重复16次
for (int i = 0, i < imgHeight; i++) {
DataCopy(tensorIn[i * copyWidth ], tensorGM[i*imgWidth], copyWidth);
}【正例】
LocalTensor<float> tensorIn;
GlobalTensor<float> tensorGM;
...
constexpr int32_t copyWidth = 2 * 1024 / sizeof(float);
constexpr int32_t imgWidth = 16 * 1024 / sizeof(float);
constexpr int32_t imgHeight = 16;
// 通过DataCopy包含srcStride/dstStride/blockLen/blockCount的接口一次搬完
DataCopyParams copyParams;
copyParams.blockCount = imgHeight;
copyParams.blockLen = copyWidth / 8; // 搬运的单位为DataBlock(32Byte),每个DataBlock内有8个float
copyParams.srcStride = (imgWidth - copyWidth ) / 8; // 表示两次搬运src之间的间隔,单位为DataBlock
copyParams.dstStride = 0; // 连续写,两次搬运之间dst的间隔为0,单位为DataBlock
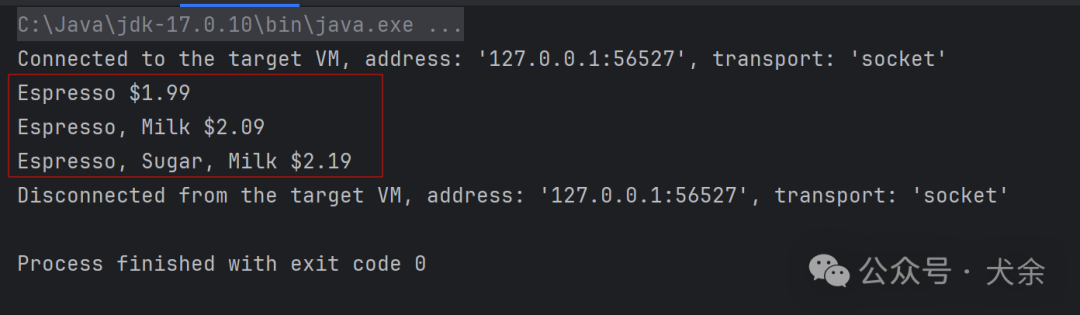
DataCopy(tensorGM, tensorIn, copyParams);更多学习资源
了解更多Ascend C算子性能优化手段和实践案例,请访问:昇腾社区Ascend C信息专区。