前言
我原本后面打算用李沐老师那本《动手学深度学习》继续“抄书”,他们团队也免费提供了电子版(https://zh-v2.d2l.ai/d2l-zh-pytorch.pdf)。但书里涉及到代码,一方面展示起来不太方便,另一方面我自己也有很多地方看不太懂。
这让我开始思考起我“抄书”的意义了。如果都是文字,我感觉抄起来可以加深印象,在抄的同时理解并思考。
但是如果涉及到代码,我没办法在抄的时候就能理解,就能很顺畅地把代码解释出来。需要自己先去调试一遍,才能心安理得地介绍起来。
于是,我开始停止自己看书,打算先去看看视频。土堆的视频先从加载数据讲起,然后是 TensorBoard,我感觉和前面学到的训练/测试什么的,根本没关系,也不知道为什么要讲这些,就听不下去了,想着先去看看实操。
然后我到看刘二大人的教程,他先讲线性模型和梯度下降等等的原理,再上代码实操,看起来就比较舒服。我把他的代码自己敲了一遍,虽说能跑起来,但还是存在很多疑惑。
控制台不停地打印着训练轮数和损失,看起来有点样子,但是不直观。我想着要是能把训练过程中的 loss 作图出来就好。虽说可以利用 python 的作图包绘制,但我感觉应该会有专门的工具来实现。
我上网搜了下,发现 pytorch 就自带了 tensorboard 这个工具可以可视化训练过程。哎,这不就是土堆视频里讲的那个么。我就又老老实实去看土堆的视频了。
经过这些过程,我早已经变得很挫败,甚至感觉自己不是学这个的料。东看一点,西看一点,最后还是回到了李沐老师的书上。
我感觉自已经走了很多弯路,《动手学深度学习》这本书里最前面一章就是介绍预备知识,我嫌繁琐,跳过没看,直接看后面的内容,但我又看不懂,又要倒回去重新看预备知识,这样就会产生很多挫败情绪。
虽说经过这几天折腾,隐隐约约学到了一些东西,但显然是划不来的。我以后就老老实实跟着李沐老师,先认认真真搞懂基础的几个模型,不去担心可能学了以后用不到之类的问题,之后再重点看看自己导师研究的方向。
下面我们从线性回归开始,先介绍它的关键思想,然后手动实现它,体会这一过程,再借助 pytorch 来实现。
通过对比这两种方式,可以更好地理解 pytorch 的用法。
一、线性回归关键思想
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
线性回归(linear regression)指输入 x \pmb{x} x 和输出 y y y 之间的关系是线性的,即 y y y 可以表示为 x \pmb{x} x 中元素的加权和,如下式: y = w 1 ⋅ x 1 + w 2 ⋅ x 2 + b . y=w_1\cdot x_{1}+w_{2}\cdot x_{2}+b. y=w1⋅x1+w2⋅x2+b. 其中, w 1 w_{1} w1 和 w 2 w_{2} w2 称为权重,其决定了每个 x x x 对 y y y 的影响; b b b 称为偏置(bias)。
偏置是指当所有 x x x 都取 0 时,输出值应该为多少。如果没有偏置项,模型的表达能力将受到限制。
给定一个数据集,我们的目标是寻找模型的权重 w \pmb{w} w 和偏置 b b b,使得根据模型做出的预测大体符合真实情况。
在开始寻找最好的模型参数(model parameters)前,我们还需要两个东西:
- 一种模型质量的度量方式;(怎么判断这个模型好不好?)
- 一种能够更新模型以提高模型质量的方法。(如果模型质量不太行,怎么提高?)
损失函数(模型质量度量方式)
损失函数(loss function)能够量化目标的实际值与预测值之间的差距。通常我们会选择非负数作为损失,且数值越小表示损失越小。
回归问题中最常用的损失函数是平方误差函数。
可以想想我们以前学直线拟合时的最小二乘法。
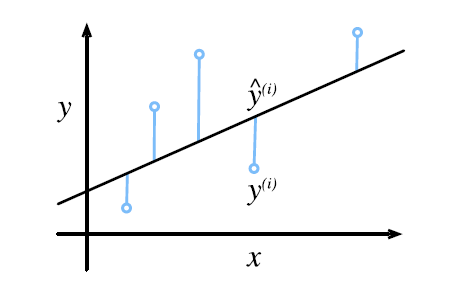
随机梯度下降(提高模型质量方法)
梯度下降(gradient descent)通过不断地在损失函数递减的方向上更新参数来降低误差。
其最简单的方法是计算损失函数(所有样本的损失均值)关于模型参数的导数。但实际中的执行可能会非常慢:
因为在每一次更新参数前,我们必须遍历整个数据集。因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本,这种变体称为小批量随机梯度下降(minibatch stochastic gradient descent)。
在每次迭代中,我们首先随机抽样一个小批量 B B B,它是又固定数量的训练样本组成。然后,我们计算小批量的平均损失关于模型参数的导数。最后,我们将梯度乘以一个预先确定的正数 η \eta η,并从当前参数的值中减掉。
总结起来,算法的步骤为:
- 初始化模型参数;
- 从数据集中随机抽取小批量样本且在负梯度的方向上更新参数,并不断迭代这一步骤。
正态分布与平方损失
正态分布和线性回归之间的关系很密切。正态分布(normal distribution),也称为高斯分布(Gaussian distribution),最早由德国数学家高斯(Gauss)应用于天文学研究。
简单地说,若随机变量 X X X 具有均值 μ \mu μ 和方差 σ 2 \sigma^2 σ2,其正态概率密度函数为: p ( x ) = 1 2 π σ 2 exp ( − 1 2 σ 2 ( x − μ ) 2 ) . p(x)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp\bigg(-\frac{1}{2\sigma^2}(x-\mu)^2\bigg). p(x)=2πσ21exp(−2σ21(x−μ)2). 正态分布的可视化图像如下图所示。改变均值会产生沿 x x x 轴的偏移,增加方差将会分散分布、降低其峰值。
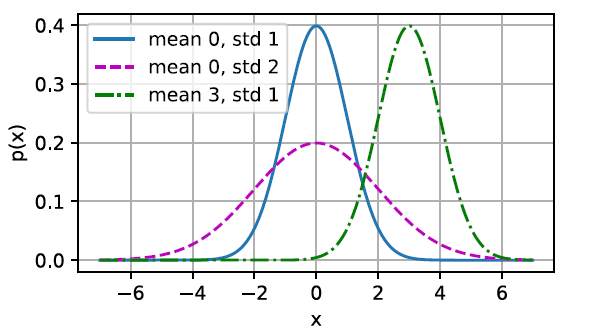
均方误差损失函数可以用于线性回归的一个原因是:我们假设了观测中包含噪声,其中噪声服从正态分布。
在高斯噪声的假设下,最小化均方误差等价于对线性模型的极大似然估计。
二、线性回归的从零开始实现
导入的包有:
import random
import torch
import matplotlib.pyplot as plt
生成数据集
我们可以自己用带有噪声的线性模型生成一系列数据,通过优化算法不断减小损失,最终尽可能恢复用来生成数据的参数。
例如,用 y = 2 x 1 − 3.4 x 2 + 4.2 + ϵ y=2x_1-3.4x_2+4.2+\epsilon y=2x1−3.4x2+4.2+ϵ 来生成一系列数据点,其中 ϵ \epsilon ϵ 服从均值为 0,标准差为 0.01 的正态分布。
为提高计算性能,我们可以用矩阵进行表示,即 [ y 1 y 2 ⋮ y n ] = [ x 1 x 2 x 1 x 2 ⋯ ⋯ x 1 x 2 ] n × 2 [ 2 − 3.4 ] + 4.2 + ϵ \begin{bmatrix} y_1 \\\ y_2 \\\ \vdots \\\ y_n \end{bmatrix} = \begin{bmatrix} x_1 & x_2 \\\ x_1 & x_2 \\\ \cdots & \cdots \\\ x_1 & x_2 \end{bmatrix}_{n\times 2} \begin{bmatrix} 2 \\\ -3.4 \end{bmatrix}+4.2+\epsilon y1 y2 ⋮ yn = x1 x1 ⋯ x1x2x2⋯x2 n×2[2 −3.4]+4.2+ϵ 后面两项常数项可以看成 n × 1 n\times1 n×1 的矩阵,由于张量具有广播机制,可以直接相加。
生成数据并可视化 y y y 与 x 2 x_2 x2 关系的代码如下:
import torch
import matplotlib.pyplot as plt
num_samples = 1000 # 生成的数据点个数
# 原模型的两个参数
w_true = torch.tensor([2, -3.4])
b_true = 4.2
# 设置随机种子,方便验证和复现
random_seed = 326
torch.manual_seed(random_seed)
# 随机生成自变量
X = torch.randn((num_samples, len(w_true)))
# 生成不含噪声的 y
y = torch.matmul(X, w_true) + b_true
# 生成带有噪声的y
y += torch.normal(0, 0.01, y.shape)
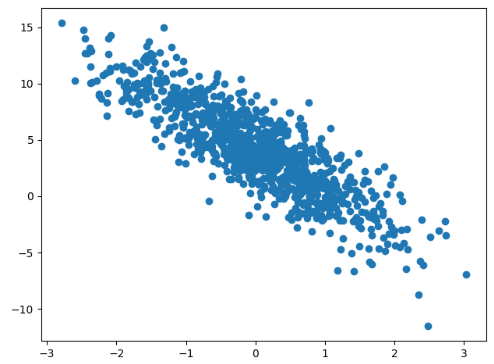
# 绘制数据点,看看长什么样
# 自变量有两个,只绘制一个自变量与y的关系
plt.scatter(X[:, 1], y)
plt.show()
为提高代码的复用性,可以把生成数据的部分封装成一个函数,这样如果要生成其他参数的数据时就更加方便。后续很多代码都会尽量用函数的形式表达。
# 生成数据集
def generate_data(num_samples, w, b):
# 随机生成自变量
x = torch.randn((num_samples, len(w)))
# 生成不含噪声的 y
y = torch.matmul(x, w) + b
# 生成带有噪声的y
y += torch.normal(0, 0.01, y.shape)
print(y.shape)
return x, y.reshape((-1, 1))
读取数据
如果我们采用小批量随机梯度下降作为优化算法,需要读取数据集并每次抽取一小批。
我们采用随机抽取的方式,即需要将数据集的样本打乱。编写的读取数据函数如下:
def load_data(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 打乱索引顺序
random.shuffle(indices)
# 每次都返回一个小批量样本
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
初始化参数
我们得先有一个最初的参数放进去,这样才可以去改进。如果这个初始参数选的好,可能很快就接近真实参数了。
初始权重 w 我们采用均值为 0,标准差为 0.01 的正态分布随机数,偏置 b 初始设为 0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
requires_grad=True表示需要对这些参数进行梯度的计算。
模型的定义
想想之前学过的拟合,可以用线性拟合,也可以用二次曲线拟合,都是为了将输入与输出关联起来。
可以把模型理解为一个函数,把输入放进去,可以得到一个输出。我们通过对原始数据的可视化分析,选取线性模型。
# 定义模型
def my_linear(x, w, b):
# 线性模型
return torch.matmul(x, w) + b
损失函数
采用平方损失函数来衡量模型好坏。注意需要对 y 使用 reshape,存在行向量与列向量的区别。
# 定义损失函数
def my_loss(y_hat, y):
# 平方损失函数,y_hat为模型预测值
# 这里reshape是因为读取出来的y是行向量,而预测值为列向量
return (y_hat - y)**2 / 2
优化算法
采用小批量随机梯度下降算法进行优化。对参数进行更新,并清零梯度。
# 定义优化器
def my_optimizer(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad(): # 以下操作不计算梯度
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
训练模型
训练是一个反复的过程,从初始的模型参数出发,计算其预测值与损失,随后进行反向传播,得到损失函数对各个参数的梯度,最后利用优化算法对参数进行更新,转入下一轮训练。
学习率lr和训练轮数num_epochs是两个非常重要的超参数,需要反复试验不断调整,以获得较好的训练效果。
# 小批量的大小
batch_size = 10
# 学习率和训练轮数
lr = 0.03
num_epochs = 3
# 开始训练
for epoch in range(num_epochs):
for x, y in load_data(batch_size, features, labels):
l = my_loss(my_linear(x, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。
# l中的所有元素被加到一起,并以此计算关于[w,b]的梯度
l.sum().backward()
my_optimizer([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = my_loss(my_linear(features, w, b), labels)
# 打印出每轮训练的损失
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
# 评估训练效果
print(f'w的估计误差: {w_true - w.reshape(w_true.shape)}')
print(f'b的估计误差: {b_true - b}')
从打印出的结果可以发现,第一轮训练后的损失已经比较小了,且每轮训练后损失都在减小。最终得到的两个参数非常接近于我们用于生成数据的参数了。
epoch 1, loss 0.041334
epoch 2, loss 0.000153
epoch 3, loss 0.000048
w的估计误差: tensor([4.0889e-05, 1.1015e-04], grad_fn=<SubBackward0>)
b的估计误差: tensor([0.0004], grad_fn=<RsubBackward1>)
需要注意的是,我们不应该认为我们能完美地恢复参数,我们更关心如何高度准确预测参数。
三、线性回归的简洁实现
下面我们利用 pytorch 来实现线性回归模型,它可以帮助避免一些重复性的工作。需要导入的包有:
import torch
from torch.utils import data
from torch import nn
生成数据集
与从零实现同样,我们需要先有一个数据集。由于线性模型所需要的数据较为简单,可以自己生成。
我们采用前面写好的生成数据函数,利用随机种子生成一个相同的数据集。
读取数据集
pytorch 提供了 DataLoader 供我们进行数据读取,我们只需要传入相应格式的数据,传入参数batch_size和shuffle的值,就可以得到一个随机小批量数据迭代器。
def load_data(data_arrays, batch_size, is_train=True): # 读取数据
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
定义模型
在从零实现中,我们明确定义了线性模型的参数,并编写了内部进行计算的代码。如果模型的计算变得复杂,并且每天需要经常使用时,我们就会考虑对这一过程进行简化。
我们可以使用 pytorch 预先定义好的“层”,这样我们就只需要关注使用哪些层来构建我们的模型,而不用去关注怎么实现这个层。
我们首先定义一个模型变量 net,它是一个 Sequential 类的实例。Sequential 类可以将很多个层串联在一起。
当给定输入数据时,net 将数据传入第一层,然后将第一层的输出作为第二层的输入,以此类推。
线性回归可以看作一层的神经网络,实际上是不需要使用 Sequential 的。但由于以后使用的模型都会是很多层的,在这里使用 Sequtntial 可以帮助我们理解。
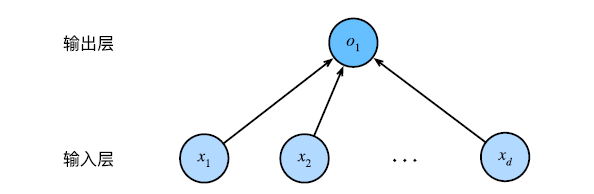
上图中,它的每一个输入都通过矩阵-向量乘法得到它的输出,被称为全连接层(fully-connected layer)。
在 pytorch 中,全连接层在 nn.Linear 类中定义,它的第一参数是输入的形状,我们有两个 x x x ,所以是 2。它的第二个参数是输出的形状,线性模型的 y y y 是标量,所以是 1。
net = nn.Sequential(nn.Linear(2, 1)) # 定义模型
初始化模型参数
可以把 net 看成一个列表,用 net[0] 访问模型中的第一层,用 weight.data 和 bias.data 访问里面的参数。
我们还可以用 noraml_ 和 fill_ 来重写参数值,完成初始化。
同样,初始权重 w 我们采用均值为 0,标准差为 0.01 的正态分布随机数,偏置 b 初始设为 0。
# 初始化模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
定义损失函数
同定义模型类似,我们可以直接调用现成的类,平方误差使用的是 nn.MSELoss 类。
loss = nn.MSELoss() # 损失函数
定义优化器
同样,优化算法直接调用现成的 optim.SGD,利用 net.paremeters() 可以直接获取模型中的参数传入,再传入 lr 值即可定义一个小批量随机梯度下降优化器。
lr = 0.03 # 学习率
optimizer = torch.optim.SGD(net.parameters(), lr=lr) # 优化器
训练模型
和前面的训练逻辑类似,对于每一个小批量,我们会经历以下步骤:
- 出初始的参数出发,将数据代入模型生成输出并计算损失(前向传播);
- 通过反向传播计算梯度;
- 通过调用优化器来更新参数。
num_epochs = 3 # 训练轮数
for epoch in range(num_epochs): # 开始训练
for X, y in data_iter:
l = loss(net(X) ,y) # 前向传播
optimizer.zero_grad() # 避免上一轮影响,清零梯度
l.backward() # 反向传播
optimizer.step() # 更新参数
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
w = net[0].weight.data
print('w的估计误差:', w_true - w.reshape(w_true.shape))
b = net[0].bias.data
print('b的估计误差:', b_true - b)
同样我们可以在每轮训练后输出当前的损失,以及打印训练完成时的参数和真实参数的偏差。
epoch 1, loss 0.000273
epoch 2, loss 0.000096
epoch 3, loss 0.000096
w的估计误差: tensor([0.0004, 0.0002])
b的估计误差: tensor([-0.0002])
和从零开始实现一样,最后估计得到的参数非常接近真实参数。
两种方式实现线性神经网络的完整 py 文件见附件。



















