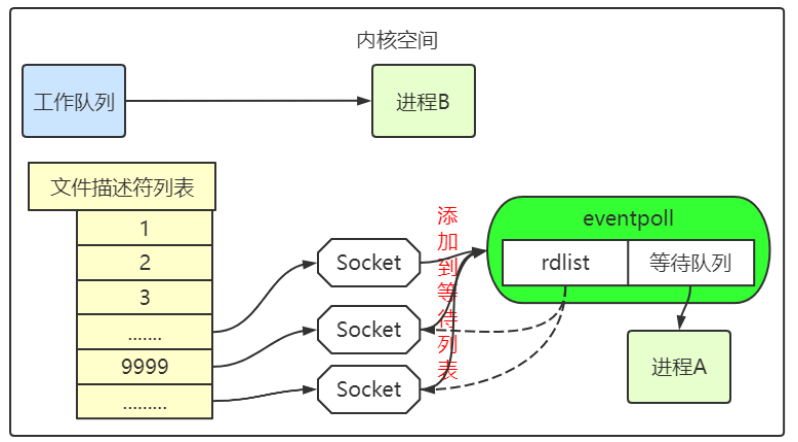
一、机器学习的关键因素
1.1 数据
每个数据集由一 个个样本组成,大多情况下,数据遵循独立同分布。通常每个样本由一组特征属性组成。
好的数据集
{
数据样本多
正确的数据
(
g
a
r
b
a
g
e
i
n
,
g
a
r
b
a
g
e
o
u
t
)
好的数据集 \begin{cases} 数据样本多\\\ 正确的数据(garbage \quad in,\quad garbage \quad out) \end{cases}
好的数据集{数据样本多 正确的数据(garbagein,garbageout)
1.2 模型
与经典机器学习算法模型相比,深度学习的模型由神经网络错综复杂地交织在一起,包含层层数据转换,模型功能更加强大。
1.3 目标函数
在机器学习中,需要定义对模型的优劣程度的度量,并且这个度量在大多数情况下是“可优化的”,这被称为目标函数。
优化的两种思路
{
1
、损失函数,越小越好(例如:平方误差函数)
最常用的方法
2
、设计一种新的函数,优化到其最大值
优化的两种思路 \begin{cases} 1、损失函数,越小越好(例如:平方误差函数)\textcolor{red}{最常用的方法}\\ 2、设计一种新的函数,优化到其最大值 \end{cases}
优化的两种思路{1、损失函数,越小越好(例如:平方误差函数)最常用的方法2、设计一种新的函数,优化到其最大值
1.4 优化算法
当我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。在深度学习中,大多数流行的优化算法通常基于一种基本方法,梯度下降 。梯度下降方法在每个步骤中都会检查每个参数,观察如果仅对该参数进行少量改动,训练集上的损失会朝哪个方向移动。然后,它在可以减少损失的方向上优化参数。
二、各种机器学习的问题
2.1 监督学习
监督学习是在“给定输入特征”的情况下预测标签,每个“特征-标签”对都称为一个样本,即使标签是未知的,样本也可以指代输入特征。监督学习的目标是生成一个模型,该模型能够将任何输入特征映射到标签。
监督学习的学习过程:

1、从已知大量数据样本中随机选取一个子集,为每个样本获取真实标签;
2、选择有监督的学习算法,它将训练数据集作为输入,并输出一个“已完成学习的模型”;
3、将之前没有见过的样本特征放到这个“已完成学习的模型”中,使用模型的输出作为相应标签的预测。
监督学习的应用
{
1
、回归问题:预测一个数值
2
、分类问题:预测是哪一类
3
、标注问题:多标签分类
4
、搜索问题:对搜索查询的结果进行筛选排序
5
、推荐系统:捕捉一个用户的偏好
6
、序列学习:如果是连续的输入,模型需要有记忆功能
监督学习的应用 \begin{cases} 1、回归问题:预测一个数值\\ 2、分类问题:预测是哪一类\\ 3、标注问题:多标签分类\\ 4、搜索问题:对搜索查询的结果进行筛选排序\\ 5、推荐系统:捕捉一个用户的偏好\\ 6、序列学习:如果是连续的输入,模型需要有记忆功能 \end{cases}
监督学习的应用⎩
⎨
⎧1、回归问题:预测一个数值2、分类问题:预测是哪一类3、标注问题:多标签分类4、搜索问题:对搜索查询的结果进行筛选排序5、推荐系统:捕捉一个用户的偏好6、序列学习:如果是连续的输入,模型需要有记忆功能
2.2 无监督学习
数据样本中不含有“目标”的机器学习问题通常被称为无监督学习。
无监督学习
{
1
、聚类问题
2
、主成分分析
3
、因果关系和概率图模型
4
、生成对抗网络
无监督学习 \begin{cases} 1、聚类问题\\ 2、主成分分析\\ 3、因果关系 和概率图模型\\ 4、生成对抗网络 \end{cases}
无监督学习⎩
⎨
⎧1、聚类问题2、主成分分析3、因果关系和概率图模型4、生成对抗网络
2.3 强化学习
在强化学习问题中,智能体(agent)与环境进行交互。在每个特定时间点,智能体从环境接受一些观测(observation),并且必须选择一个动作(action),然后通过某种机制将其输出回环境,最后智能体从环境获得奖励(reward),然后开始新一轮循环,智能体继续从环境中监测,选择后续动作并获得奖励,以此类推。
强化学习的目标是产生一个好的策略(policy),强化学习智能体选择的“动作”受策略控制,即一个从环境观测映射到动作选择的功能。
强化学习框架的通用性极强,一般来说,可以将任何监督学习问题转化为强化学习问题。一个分类问题,可以创建一个强化学习智能体,每个分类对应一个动作,创建一个环境后,该环境给与智能体奖励。这个奖励与原始监督学习问题的损失函数是一致的。
一些特殊情况下的强化学习问题:
1、当环境可被完全观测到时,该问题被称为马尔科夫决策过程;
2、当状态不依赖之前的动作时,该问题被称为上下文老虎机;
3、当没有状态,只有一组最初未知奖励的可用动作时,该问题被称为多臂老虎机。