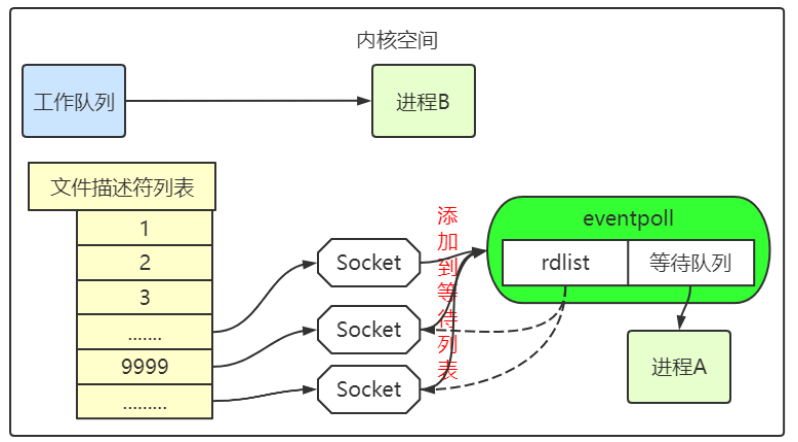
前言
Hive的四种排序包括Sort By、Order By、Distribute By和Cluster By。有关这四种排序的区别,在大数据面试中可能会经常被问到,在我们很多人的实际应用中可能最常用的就是全局排序order by,因此对于其他几个排序理解并不准确,接下来我用简单的案例尽量描述清楚。
数据准备
-
Hive表
create table scores ( name string, class string, score int ); -
插入数据
insert into scores values('Lily','1',72),('Mark','2',77),('Lucy','1',83),('Wade','2',92), ('Jack','1',91),('James','2',84),('Kobe','2',94),('Jay','1',85); -
查询数据
select * from scores;
ORDER BY
ORDER BY 会对全局数据进行排序,这意味着Hive会启动一个单独的reducer来接收所有mapper的输出,并在这个reducer中进行排序。这种方式在数据量很大时效率很低,因为所有数据都需要通过网络传输到一个reducer。
-
需求
查询按照分数从高到低排序整个表的数据。 -
SQL
SELECT name, CLASS, score FROM scores ORDER BY score DESC; -
结果

SORT BY
SORT BY 是在每个reducer内部进行排序的。这意味着如果你使用SORT BY而没有DISTRIBUTE BY(或CLUSTER BY,它包含了DISTRIBUTE BY),Hive可能会随机地将数据分发到不同的reducer,每个reducer内部的数据会按照SORT BY指定的列进行排序。但不同的reducer之间的数据顺序是不确定的。
- 需求
每个班级内部的学生按照分数排序,但不需要全局排序。 - SQL(需要配合DISTRIBUTE BY使用以控制分发)
SELECT name, CLASS, score FROM scores DISTRIBUTE BY CLASS SORT BY score DESC; - 结果

DISTRIBUTE BY
distribute by是控制在map端如何拆分数据给reduce端的。类似于MapReduce中分区partationer对数据进行分区hive会根据distribute by后面列,将数据分发给对应的reducer,默认是采用hash算法+取余数的方式。
sort by为每个reduce产生一个排序文件,在有些情况下,你需要控制某写特定的行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
CLUSTER BY
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
当分区字段和排序字段相同cluster by可以简化distribute by+sort by 的SQL 写法,也就是说当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by。
-
需求
每个班级内部的学生按照分数排序,但不需要全局排序。 -
SQL
SELECT name, CLASS, score FROM scores CLUSTER BY CLASS; -
结果

总结
- order by 是全局排序,可能性能会比较差;
- sort by分区内有序,往往配合distribute by来确定该分区都有那些数据;
- distribute by 确定了数据分发的规则,满足相同条件的数据被分发到一个reducer;
- cluster by 当distribute by和sort by 字段相同时,可以使用cluster by 代替distribute by和sort by,但是cluster by默认是升序,不能指定排序方向;
参考文献
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+SortBy
https://sqlrelease.com/sort-by-order-by-distribute-by-and-cluster-by-in-hive