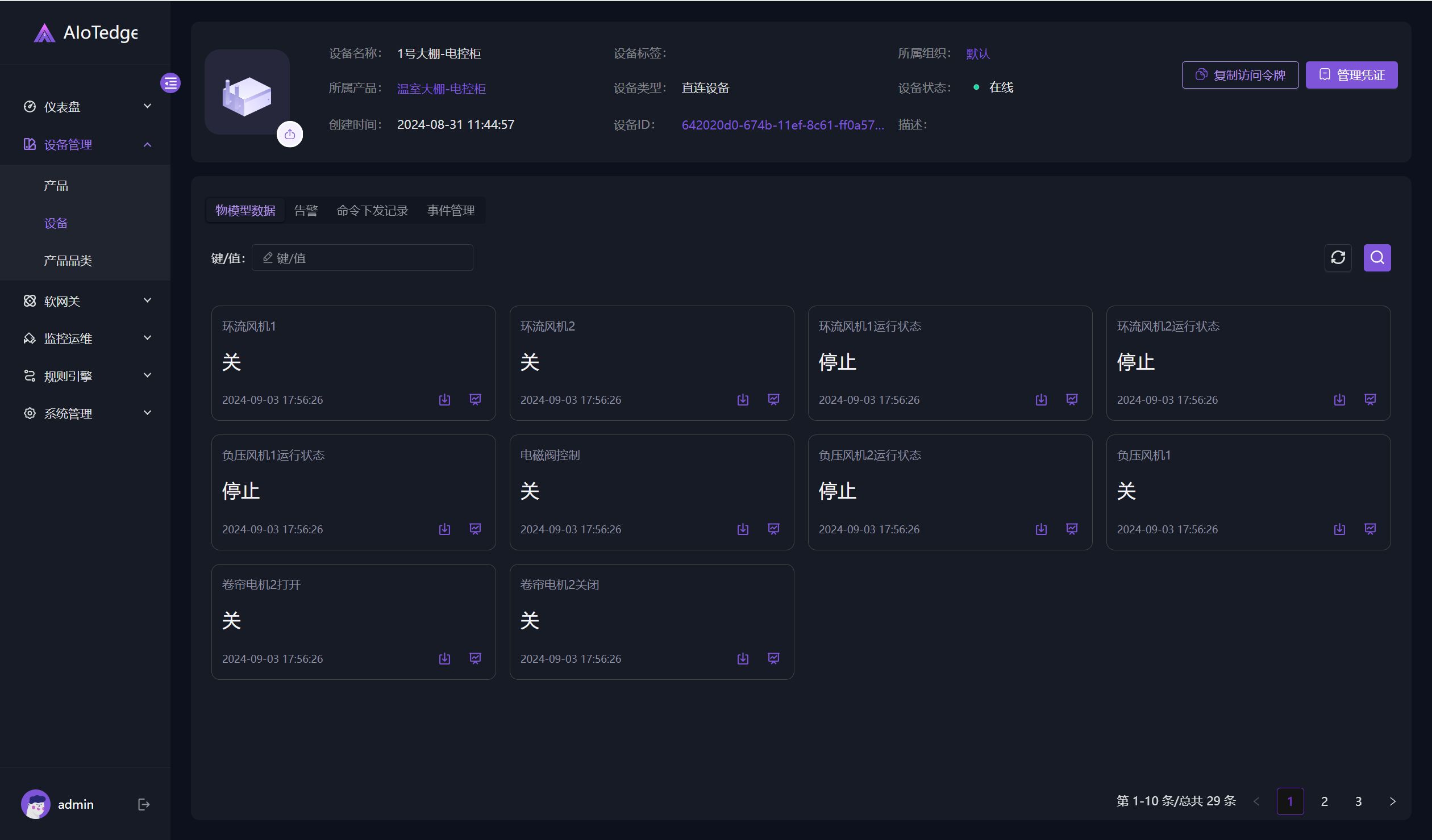
目录
概述
程序计数器
栈
Java虚拟机栈
概述
栈帧的组成
局部变量表
操作数栈
帧数据
栈内存溢出
本地方法栈
堆
方法区
类的元信息
运行时常量池
方法区的实现
方法区的溢出
字符串常量池
直接内存
概述
Java虚拟机在运行Java程序过程中管理的内存区域,称之为运行时数据区
《Java虚拟机规范》中规定了每一部分的作用

程序计数器
程序计数器(Program Counter Register)也叫PC寄存器,每个线程会通过程序计数器记录当前要执行的字节码指令的地址

一个程序计数器的具体案例:

在加载阶段,虚拟机将字节码文件中的指令读取到内存之后,会将原文件中的偏移量转换成内存地址,每一条字节码指令都会拥有一个内存地址

在代码执行过程中,程序计数器会记录下一行字节码指令的地址,执行完当前指令之后,虚拟机的执行引擎根据程序计数器执行下一条指令
比如当前执行的是偏移量为0的指令,那么程序计数器中保存的就是下一条的地址(偏移量1)

程序计数器可以控制程序指令的进行,实现分支、跳转、异常等逻辑
在多线程执行情况下,Java虚拟机需要通过程序计数器记录CPU切换前解释执行到哪一句指令并继续解释运行
程序计数器会出现内存溢出吗?
内存溢出指的是程序在使用某一块内存区域时,存放的数据需要占用的内存大小超过了虚拟机能提供的内存上限;由于每个线程只存储一个固定长度的内存地址,程序计数器是不会发生内存溢出的,程序员无需对程序计数器做任何处理
栈
Java虚拟机栈
概述
Java虚拟机栈(Java Virtual Machine Stack)采用栈的数据结构来管理方法调用中的基本数据,先进后出(First In Last Out),每一个方法的调用使用一个栈帧(Stack Frame)来保存
示例:
public class MethodDemo {
public static void main(String[] args) {
study();
}
public static void study(){
eat();
sleep();
}
public static void eat(){
System.out.println("吃饭");
}
public static void sleep(){
System.out.println("睡觉");
}
}main方法执行时,会创建main方法的栈帧:

接下来执行study方法,会创建study方法的栈帧:

进入eat方法,创建eat方法的栈帧:

eat方法执行完之后,会弹出它的栈帧:

然后调用sleep方法,创建sleep方法栈帧:

最后study方法结束之后弹出栈帧,main方法结束之后弹出main的栈帧
栈帧的组成
- 局部变量表
- 操作数栈
- 帧数据
局部变量表
局部变量表的作用是在方法执行过程中存放所有的局部变量,编译成字节码文件时就可以确定局部变量表的内容
局部变量表保存的内容有:
- 实例方法的this对象
- 方法的参数
- 方法体中声明的局部变量
字节码文件中的局部变量表:

比如i这个变量,它的起始PC是2,代表从lconst_1这句指令开始才能使用i,长度为3,也就是2-4这三句指令都可以使用i,为什么从2才能使用,因为0和1这两句字节码指令还在处理int i = 0这句赋值语句。j这个变量只有等3指令执行完之后也就是long j = 1代码执行完之后才能使用,所以起始PC为4,只能在4这行字节码指令中使用
栈帧中的局部变量表:
栈帧中的局部变量表是一个数组,数组中每一个位置称之为槽(slot),long和double类型占用两个槽,其他类型占用一个槽

i占用数组下标为0的位置,j占用数组下标1-2的位置
实例方法中的序号为0的位置存放的是this,指的是当前调用方法的对象,运行时会在内存中存放实例对象的地址:

方法参数也会保存在局部变量表中,其顺序与方法中参数定义的顺序一致:

问题:以下代码的局部变量表中会占用几个槽?6
public void test4(int k,int m){
{
int a = 1;
int b = 2;
}
{
int c = 1;
}
int i = 0;
long j = 1;
}为了节省空间,局部变量表中的槽是可以复用的,一旦某个局部变量不再生效,当前槽就可以再次被使用
1.方法执行时,实例对象this、k、m 会被放入局部变量表中,占用3个槽

2.将1的值放入局部变量表下标为3的位置上,相当于给a进行赋值

3.将2放入局部变量表下标为4的位置,给b赋值为2

4.a、b已经脱离了生效范围,所以下标为3和4的这两个位置可以复用,此时c的值1就可以放入下标为3的位置

5.脱离c的生效范围之后,给i赋值就可以复用c的位置

6.最后放入j,j是一个long类型,占用两个槽。但是可以复用b所在的位置,所以占用4和5这两个位置

所以,局部变量表数值的长度为6
操作数栈
操作数栈是栈帧中虚拟机在执行指令过程中用来存放中间数据的一块区域,它是一种栈式的数据结构,如果一条指令将一个值压入操作数栈,则后面的指令可以弹出并使用该值
在编译期就可以确定操作数栈的最大深度,从而在执行时正确分配内存大小
示例:加法运算中操作数栈的应用


帧数据
当前类的字节码指令引用了其他类的属性或方法时,需要将符号引用(编号)转换成对应的运行时常量池中的内存地址,动态链接就保存了编号到运行时常量池的内存地址的映射关系

方法出口指的是方法在正确或者异常结束时,当前栈帧会被弹出,同时程序计数器应该指向上一个栈帧中的下一条指令的地址,所以在当前栈帧中,需要存储此方法出口的地址

异常表存放的是代码中异常的处理信息,包含了异常捕获的生效范围以及异常发生后跳转到的字节码指令位置

如下案例:i=1这行源代码编译成字节码指令之后,会包含偏移量2-4这三行指令,其中2-3是对i进行赋值1的操作,4的没有异常就跳转到10方法结束,如果出现异常的情况下,继续执行到7这行指令,7会将异常对象放入操作数栈中,这样在catch代码块中就可以使用异常对象了,接下来执行8-9,对i进行赋值为2的操作,所以异常表中,异常捕获的起始偏移量就是2,结束偏移量是4,在2-4执行过程中抛出了java.lang.Exception对象或者子类对象,就会将其捕获,然后跳转到偏移量为7的指令

栈内存溢出
Java虚拟机栈如果栈帧过多,占用内存超过栈内存可以分配的最大大小就会出现内存溢出
Java虚拟机栈内存溢出时会出现StackOverflowError的错误
如果不指定栈的大小,JVM将创建一个具有默认大小的栈,大小取决于操作系统和计算机的体系结构:

模拟栈内存溢出:
public static int count = 0;
//递归方法调用自己
public static void recursion(){
System.out.println(++count);
recursion();
}
要修改Java虚拟机栈的大小,可以使用虚拟机参数 -Xss
- 语法:-Xss栈大小
- 单位:字节(默认,必须是 1024 的倍数)、k或者K(KB)、m或者M(MB)、g或者G(GB)
-Xss1048576
-Xss1024K
-Xss1m
-Xss1g注意事项:
1、与-Xss类似,也可以使用 -XX:ThreadStackSize 调整标志来配置堆栈大小
格式为: -XX:ThreadStackSize=1024
2、HotSpot JVM对栈大小的最大值和最小值有要求:
比如测试如下两个参数,会直接报错:
-Xss1k、-Xss1025m
Windows(64位)下的JDK8测试最小值为180k,最大值为1024m
3、局部变量过多、操作数栈深度过大也会影响栈内存的大小
一般情况下,工作中即便使用了递归进行操作,栈的深度最多也只能到几百,不会出现栈的溢出,所以此参数可以手动指定为-Xss256k节省内存
本地方法栈
Java虚拟机栈存储了Java方法调用时的栈帧,而本地方法栈存储的是native本地方法的栈帧
在Hotspot虚拟机中,Java虚拟机栈和本地方法栈实现上使用了同一个栈空间,本地方法栈会在栈内存上生成一个栈帧,临时保存方法的参数同时方便出现异常时也把本地方法的栈信息打印出来

堆
一般Java程序中堆内存是空间最大的一块内存区域,创建出来的对象都存在于堆上
栈上的局部变量表中可以存放堆上对象的引用,静态变量也可以存放堆对象的引用,通过静态变量就可以实现对象在线程之间共享

示例:模拟堆区的溢出
通过new关键字不停创建对象,放入集合中,模拟堆内存的溢出,观察堆溢出之后的异常信息
import java.io.IOException;
import java.util.ArrayList;
/**
* 堆内存的使用和回收
*/
public class Demo1 {
public static void main(String[] args) throws InterruptedException, IOException {
ArrayList<Object> objects = new ArrayList<Object>();
System.in.read();
while (true){
objects.add(new byte[1024 * 1024 * 100]);
Thread.sleep(1000);
}
}
}堆内存大小是有上限的,当对象一直向堆中放入对象达到上限之后,就会抛出OutOfMemory错误,在这段代码中,不停创建100M大小的字节数组并放入ArrayList集合中,最终超过了堆内存的上限,抛出如下错误:

堆空间有三个需要关注的值:
- used指的是当前已使用的堆内存
- total是java虚拟机已经分配的可用堆内存
- max是java虚拟机可以分配的最大堆内存
堆内存used total max三个值可以通过arthas中的dashboard命令看到
手动指定刷新频率(不指定默认5秒一次):dashboard –i 刷新频率(毫秒)
 如果不设置任何的虚拟机参数,max默认是系统内存的1/4,total默认是系统内存的1/64,在实际应用中一般都需要设置total和max的值
如果不设置任何的虚拟机参数,max默认是系统内存的1/4,total默认是系统内存的1/64,在实际应用中一般都需要设置total和max的值
设置堆的大小:
要修改堆的大小,可以使用虚拟机参数 –Xmx(max最大值)和-Xms (初始的total)
语法:-Xmx值 -Xms值
单位:字节(默认,必须是 1024 的倍数)、k或者K(KB)、m或者M(MB)、g或者G(GB)
限制:Xmx必须大于2MB,Xms必须大于1MB
-Xms6291456
-Xms6144k
-Xms6m
-Xmx83886080
-Xmx81920k
-Xmx80m为什么arthas中显示的heap堆大小与设置的值不一样呢?
arthas中的heap堆内存使用了JMX技术中内存获取方式,这种方式与垃圾回收器有关,计算的是可以分配对象的内存,而不是整个内存

建议:Java服务端程序开发时,建议将-Xmx和-Xms设置为相同的值,这样在程序启动之后可使用的总内存就是最大内存,而无需向java虚拟机再次申请,减少了申请并分配内存时间上的开销,同时也不会出现内存过剩之后堆收缩的情况
方法区
方法区是存放基础信息的位置,线程共享,主要包含三部分内容:
- 类的元信息:保存了所有类的基本信息
- 运行时常量池:保存了字节码文件中的常量池内容
- 字符串常量池:保存了字符串常量
类的元信息
方法区是用来存储每个类的基本信息(元信息),一般称之为InstanceKlass对象,在类的加载阶段完成,其中就包含了类的字段、方法等字节码文件中的内容,同时还保存了运行过程中需要使用的虚方法表(实现多态的基础)等信息

运行时常量池
方法区除了存储类的元信息之外,还存放了运行时常量池,常量池中存放的是字节码中的常量池内容
字节码文件中通过编号查表的方式找到常量,这种常量池称为静态常量池
当常量池加载到内存中之后,可以通过内存地址快速的定位到常量池中的内容,这种常量池称为运行时常量池

方法区的实现
方法区是《Java虚拟机规范》中设计的虚拟概念,每款Java虚拟机在实现上都各不相同
Hotspot设计如下:
JDK7及之前的版本将方法区存放在堆区域中的永久代空间,堆的大小由虚拟机参数来控制
JDK8及之后的版本将方法区存放在元空间中,元空间位于操作系统维护的直接内存中,默认情况下只要不超过操作系统承受的上限,可以一直分配

可以通过arthas的memory命令看到方法区的名称以及大小:
JDK7及之前的版本查看ps_perm_gen属性

JDK8及之后的版本查看metaspace属性

方法区的溢出
通过ByteBuddy框架,动态创建类并将字节码数据加载到内存中,通过死循环不停地加载到方法区,观察方法区是否会出现内存溢出的情况,分别在JDK7和JDK8上运行上述代码
ByteBuddy是一个基于Java的开源库,用于生成和操作Java字节码
1.引入依赖
<dependency>
<groupId>net.bytebuddy</groupId>
<artifactId>byte-buddy</artifactId>
<version>1.12.23</version>
</dependency>
2.创建ClassWriter对象
ClassWriter classWriter = new ClassWriter(0);3.调用visit方法,创建字节码数据
classWriter.visit(Opcodes.V1_7,Opcodes.ACC_PUBLIC,name,null ,"java/lang/Object",null);
byte[] bytes = classWriter.toByteArray();
import net.bytebuddy.jar.asm.ClassWriter;
import net.bytebuddy.jar.asm.Opcodes;
import java.io.IOException;
/**
* 方法区的溢出测试
*/
public class Demo1 extends ClassLoader {
public static void main(String[] args) throws IOException {
System.in.read();
Demo1 demo1 = new Demo1();
int count = 0;
while (true) {
String name = "Class" + count;
ClassWriter classWriter = new ClassWriter(0);
classWriter.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, name, null
, "java/lang/Object", null);
byte[] bytes = classWriter.toByteArray();
demo1.defineClass(name, bytes, 0, bytes.length);
System.out.println(++count);
}
}
}实验发现,JDK7上运行大概十几万次,就出现了错误,在JDK8上运行百万次,程序都没有出现任何错误,但是内存会直线升高。这说明JDK7和JDK8在方法区的存放上,采用了不同的设计
- JDK7将方法区存放在堆区域中的永久代空间,堆的大小由虚拟机参数 -XX:MaxPermSize=值来控制
- JDK8将方法区存放在元空间中,元空间位于操作系统维护的直接内存中,默认情况下只要不超过操作系统承受的上限,可以一直分配。可以使用 -XX:MaxMetaspaceSize=值 将元空间最大大小进行限制
字符串常量池
方法区中除了类的元信息、运行时常量池之外,还有一块区域叫字符串常量池(StringTable)
字符型常量池存储在代码中定义的常量字符串内容,比如“123”这个字符串,123就会被放入字符串常量池

s1和s2指向的不是同一个对象,输出为false
字符串常量池和运行时常量池有什么关系?
早期设计时,字符串常量池是属于运行时常量池的一部分,它们存储的位置也是一致的,后续做出了调整,将字符串常量池和运行时常量池做了拆分
JDK7之前在方法区,7之后在堆中

练习1:
/**
* 字符串常量池案例
*/
public class Demo2 {
public static void main(String[] args) {
String a = "1";
String b = "2";
String c = "12";
String d = a + b;
System.out.println(c == d);
}
}1.首先将1放入字符串常量池,通过局部变量a引用字符串常量池中的1字符串,b、c同理,将a和b指向的字符串进行连接,本质上就是使用StringBuilder进行连接,最后创建了一个新的字符串放入堆中

2.然后将局部变量d指向堆上的对象

所以c和d指向的不是同一个对象,打印出的结果就是false
练习2:
/**
* 字符串常量池案例
*/
public class Demo3 {
public static void main(String[] args) {
String a = "1";
String b = "2";
String c = "12";
String d = "1" + "2";
System.out.println(c == d);
}
}编译之后的字节码指令:
 说明在编译阶段,已经将1和2进行连接,最终生成12的字符串常量池中的结果
说明在编译阶段,已经将1和2进行连接,最终生成12的字符串常量池中的结果
所以返回结果就是true,c和d都指向字符串常量池中的对象
总结:

intern
String.intern()方法是可以手动将字符串放入字符串常量池中,分别在JDK6 JDK8下执行代码,JDK6 中结果是false false ,JDK8中是true false
JDK6中intern()方法会把第一次遇到的字符串实例复制到永久代的字符串常量池中,返回的也是永久代里面这个字符串实例的引用,JVM启动时就会把java加入到常量池
JDK7及之后版本由于字符串常量池在堆上,所以intern()方法会把第一次遇到的字符串的引用放入字符串常量池
后续JDK版本中,如果Java虚拟机不需要使用java字符串,那么字符串常量池中就不会存放java,打印结果有可能会出现两个true
/**
* intern案例
*/
public class Demo4 {
public static void main(String[] args) {
String s1 = new StringBuilder().append("think").append("123").toString();
System.out.println(s1.intern() == s1);
// System.out.println(s1.intern() == s1.intern());
String s2 = new StringBuilder().append("ja").append("va").toString();
System.out.println(s2.intern() == s2);
}
}面试题:静态变量存储在哪里呢?
- JDK6及之前的版本中,静态变量是存放在方法区中的,也就是永久代
- JDK7及之后的版本中,静态变量是存放在堆中的Class对象中,脱离了永久代。具体源码可参考虚拟机源码:BytecodeInterpreter针对putstatic指令的处理
直接内存
直接内存(Direct Memory)并不在《Java虚拟机规范》中存在,所以并不属于Java运行时的内存区域
在 JDK 1.4 中引入了 NIO 机制,使用了直接内存,主要为了解决以下两个问题:
- Java堆中的对象如果不再使用要回收,回收时会影响对象的创建和使用
- IO操作比如读文件,需要先把文件读入直接内存(缓冲区)再把数据复制到Java堆中
现在直接放入直接内存即可,同时Java堆上维护直接内存的引用,减少了数据复制的开销,写文件也是类似的思路
使用堆创建对象的过程:

使用直接内存创建对象的过程,不需要进行复制对象,数据直接存放在直接内存中:

使用方法:
要创建直接内存上的数据,可以使用ByteBuffer
语法: ByteBuffer directBuffer = ByteBuffer.allocateDirect(size);
注意事项: arthas的memory命令可以查看直接内存大小,属性名direct
import java.io.IOException;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.List;
/**
* 直接内存的使用和回收
*/
public class Demo1 {
public static int size = 1024 * 1024 * 100; //100mb
public static List<ByteBuffer> list = new ArrayList<ByteBuffer>();
public static int count = 0;
public static void main(String[] args) throws IOException, InterruptedException {
System.in.read();
while (true) {
//1.创建DirectByteBuffer对象并返回
//2.在DirectByteBuffer构造方法中,向操作系统申请直接内存空间
ByteBuffer directBuffer = ByteBuffer.allocateDirect(size);
//directBuffer = null;
list.add(directBuffer);
System.out.println(++count);
Thread.sleep(5000);
}
}
}如果需要手动调整直接内存的大小,可以使用-XX:MaxDirectMemorySize=大小