文章目录
- 1. 列表是什么, 元组是什么
- 2. 创建列表
- 3. 访问下标
- 4. 切片操作
- 5. 遍历列表元素
- 6. 新增元素
- 7. 查找元素
- 8. 删除元素
- 9. 连接列表
- 10. 关于元组
1. 列表是什么, 元组是什么
编程中, 经常需要使用变量, 来保存/表示数据。
如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可。
num1 = 10
num2 = 20
num3 = 30
......
但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少个数据。这个时候, 就需要用到列表。
列表是一种让程序员在代码中批量表示/保存数据的方式
- 列表类似于一个口袋,可以往里面装东西和拿东西,数量可变。
元组和列表相比, 是非常相似的, 只是列表中放哪些元素可以修改调整, 元组中放的元素是创建元组的时候就设定好的, 不能修改调整。
- 元组类似于真空包装的一个口袋,里面东西是固定的,数量不变的。
2. 创建列表
创建列表主要有两种方式。 [ ] 表示一个空的列表。
alist = [ ]# 方法1
alist = list()# 方法2
print(type(alist))
如果需要往里面设置初始值, 可以直接写在 [ ] 当中。
可以直接使用 print 来打印 list 中的元素内容。
alist = [1, 2, 3, 4]
print(alist)
列表中存放的元素允许是不同的类型。(这一点和 C++/Java 差别较大)。
alist = [1, 'hello', True, [4, 5, 6]]
print(alist)
打印:
[1, 'hello', True, [4, 5, 6]]
因为 list 本身是 Python 中的内建函数, 不宜再使用 list 作为变量名, 因此命名为 alist 。
3. 访问下标
- 可以通过下标访问操作符
[ ]来获取到列表中的任意元素。
把[]放到一个列表变量的后面,同时[]写上一个整数,此时他就是下标访问运算符。
我们把 [ ] 中填写的数字, 称为下标或者索引。
alist = [1, 2, 3, 4]
print(alist[2])
打印:
3
注意: 下标是从 0 开始计数的, 因此下标为 2 , 则对应着 3 这个元素。
- 通过下标不光能读取元素内容, 还能修改元素的值。
alist = [1, 2, 3, 4]
alist[2] = 100
print(alist)
打印:
[1, 2, 100, 4]
- 如果下标超出列表的有效范围, 会抛出异常。
alist = [1, 2, 3, 4]
print(alist[100])
# IndexError: list index out of range
- 因为下标是从 0 开始的, 因此下标的有效范围是
[0, 列表长度 - 1]。 使用len函数可以获取到列表元素个数。
alist = [1, 2, 3, 4]
print(len(alist))
打印:
4
- 下标可以取负数,表示 “倒数第几个元素”
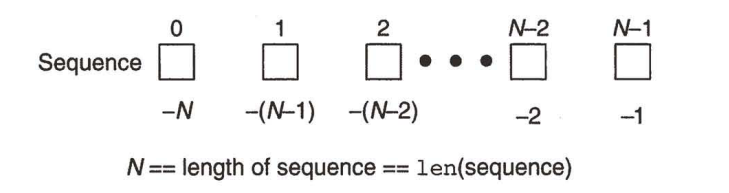
alist = [1, 2, 3, 4]
print(alist[3])
print(alist[-1])
打印:
4
4
alist[-1] 相当于 alist[len(alist) - 1]
4. 切片操作
通过下标操作是一次取出里面第一个元素。
通过切片, 则是一次取出一组连续的元素, 相当于得到一个子列表。
- 使用
[ : ]的方式进行切片操作。
alist = [1, 2, 3, 4]
print(alist[1:3])
打印:
[2, 3]
alist[1:3] 中的 1:3 表示的是 [1, 3) 这样的由下标构成的前闭后开区间。
也就是从下标为 1 的元素开始(2), 到下标为 3 的元素结束(4), 但是不包含下标为 3 的元素。所以最终结果只有 2, 3
- 切片操作中可以省略前后边界
alist = [1, 2, 3, 4]
print(alist[1:]) # 省略后边界, 表示获取到列表末尾
print(alist[:-1]) # 省略前边界, 表示从列表开头获取
print(alist[:]) # 省略两个边界, 表示获取到整个列表
打印:
[2, 3, 4]
[1, 2, 3]
[1, 2, 3, 4]
- 切片操作还可以指定 “步长” , 也就是 “每访问一个元素后, 下标自增几步”
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::1])
print(alist[::2])
print(alist[::3])
print(alist[::5])
print(alist[1:-1:2])
打印:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[1, 3, 5, 7, 9]
[1, 4, 7, 10]
[1, 6]
[2, 4, 6, 8]
- 切片操作指定的步长还可以是负数, 此时是从后往前进行取元素。表示 “每访问一个元素之后, 下标自减几步”
alist = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(alist[::-1])
print(alist[::-2])
print(alist[::-3])
print(alist[::-5])
打印:
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
[10, 8, 6, 4, 2]
[10, 7, 4, 1]
[10, 5]
- 如果切片中填写的数字越界了, 不会有负面效果。只会尽可能的把满足条件的元素过去到。
alist = [1, 2, 3, 4]
print(alist[100:200])
打印:
[]
alist = [1, 2, 3, 4]
print(alist[3:200])
打印:
[4]
5. 遍历列表元素
“遍历” 指的是把元素一个一个的取出来, 再分别进行处理。
-
最简单的办法就是使用
for循环elem就代表了列表里的每个元素
alist = [1, 2, 3, 4]
for elem in alist:
print(elem)
打印:
1
2
3
4
关于
elem:代码1:
alist = [1, 2, 3, 4] for elem in alist: elem = elem + 10 print(elem)打印:
11 12 13 14为什么会这样呢?
因为
elem就代表了列表里的每个元素,elem = elem + 10相当于1+10;2+10;3+10;4+10。改变的是
elem,不会改变列表元素。
代码2:
alist = [1, 2, 3, 4] for i in range(0, len(alist)): alist[i] = alist[i] + 10 print(alist[i])打印:
11 12 13 14代码2虽然和代码1打印内容一样,实际上有很大的区别:
代码1改变的是
elem,不会改变列表元素。代码2改变的是
alist[i],也就是列表元素,会改变列表元素。
- 也可以使用
for按照范围生成下标, 按下标访问
alist = [1, 2, 3, 4]
for i in range(0, len(alist)):
print(alist[i])
打印:
1
2
3
4
- 还可以使用
while循环。手动控制下标的变化
alist = [1, 2, 3, 4]
i = 0
while i < len(alist):
print(alist[i])
i += 1
打印:
1
2
3
4
6. 新增元素
- 使用
append方法, 向列表末尾插入一个元素(尾插)。
alist = [1, 2, 3, 4]
alist.append('hello')
print(alist)
打印:
[1, 2, 3, 4, 'hello']
- 使用
insert方法, 向任意位置插入一个元素
insert 第一个参数表示要插入元素的下标。
alist = [1, 2, 3, 4]
alist.insert(1, 'hello')
print(alist)
打印:
[1, 'hello', 2, 3, 4]
什么是 “方法” (
method)方法其实就是函数。只不过函数是独立存在的, 而方法往往要依附于某个 “对象”。
像上述代码
alist.append , append就是依附于alist, 相当于是 “针对alist这个列表, 进行尾插操作”。
alist = [1, 2, 3, 4]
alist.insert(100, 'hello')
alist.insert(-100, 'hello')
print(alist)
打印:
['hello', 1, 2, 3, 4, 'hello']
7. 查找元素
- 使用
in操作符, 判定元素是否在列表中存在,返回值是布尔类型。
alist = [1, 2, 3, 4]
print(2 in alist)
print(10 in alist)
print(10 not in alist)
打印:
True
False
True
- 使用
index方法, 查找元素在列表中的下标,返回值是一个整数。
alist = [1, 2, 3, 4]
print(alist.index(2))
打印:
1
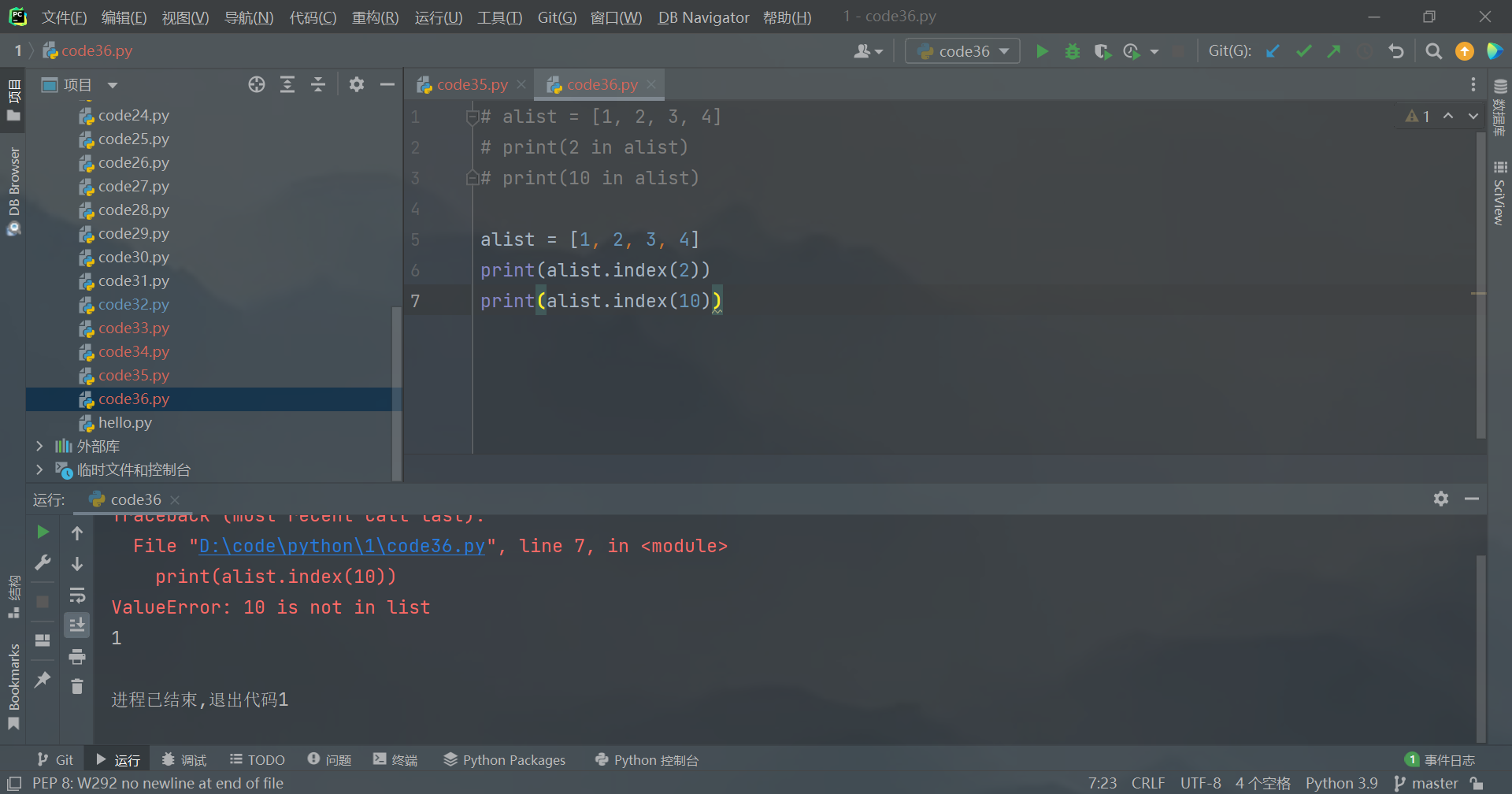
如果元素不存在, 则会抛出异常。
alist = [1, 2, 3, 4]
print(alist.index(2))
print(alist.index(10))
打印:
8. 删除元素
- 使用
pop方法删除最末尾元素
alist = [1, 2, 3, 4]
alist.pop()
print(alist)
打印:
[1, 2, 3]
pop也能按照下标来删除任意位置的元素
alist = [1, 2, 3, 4]
alist.pop(2)
print(alist)
打印:
[1, 2, 4]
- 使用
remove方法, 按照值删除元素.
alist = [1, 2, 3, 4]
alist.remove(2)
print(alist)
打印:
[1, 3, 4]
9. 连接列表
-
使用
+能够把两个列表拼接在一起。此处的
+结果会生成一个新的列表。而不会影响到旧列表的内容。
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
print(alist + blist)
打印:
[1, 2, 3, 4, 5, 6, 7]
- 使用
extend方法, 相当于把一个列表拼接到另一个列表的后面。
a.extend(b) , 是把 b 中的内容拼接到 a 的末尾。不会修改 b, 但是会修改 a。
alist = [1, 2, 3, 4]
blist = [5, 6, 7]
c = alist.extend(blist) # extend是没有返回值的。
# 拿一个变量来接收一个没有返回值的方法的返回值就会返回None。类似于C里的NULL(空指针 ),或者Java里面的null(空引用)
print(alist)
print(blist)
print(c)
打印:
[1, 2, 3, 4, 5, 6, 7] # alist
[5, 6, 7] # blist
None # 这是Python里面一个特殊变量的值,表示什么都没有
- 使用
+=来进行拼接
a = [1, 2, 3, 4]
b = [5, 6, 7, 8]
a += b
print(a)
print(b)
打印:
[1, 2, 3, 4, 5, 6, 7, 8]
[5, 6, 7, 8]
虽然这里的+=操作和上面的extend操作有点像,但是本质上是不同的。
a+=b等价于a=a+b,a+b会产生一个大的新的临时列表c,然后把c的值赋值给a,再去销毁c,相当于a的旧的值就不要了。
a.extend(b)则是直接把b的内容拼到了a的后面,更加高效,省去了数据拷贝和数据释放的过程。
10. 关于元组
元组的功能和列表相比, 基本是一致的。
- 元组使用
( )来表示。
a = () # 方法1
b = tuple() # 方法2
print(type(a))
print(type(b))
打印:
<class 'tuple'>
<class 'tuple'>
- 创建元组的时候,指定初始值
a = (1, 2, 3, 4)
print(a)
打印:
(1, 2, 3, 4)
- 元组中的元素也可以是任意类型的
b = (1, 2, 'hello', True, [])
print(b)
打印:
(1, 2, 'hello', True, [])
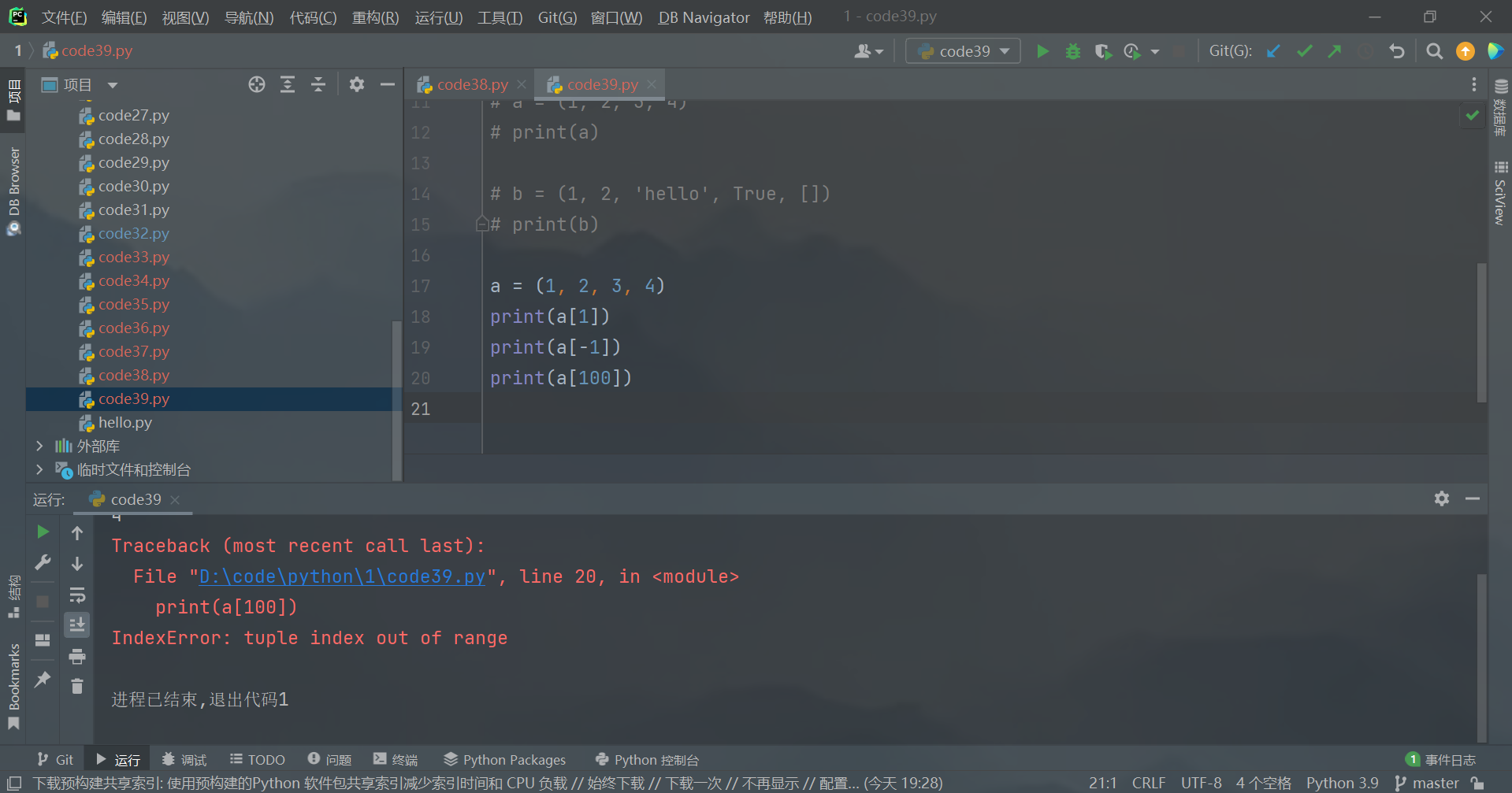
- 通过下标来访问元组中的元素。下标也是从
0开始到len - 1结束。
a = (1, 2, 3, 4)
print(a[1])
print(a[-1])
打印:
2
4
a = (1, 2, 3, 4)
print(a[1])
print(a[-1])
打印:
- 通过切片来获取元组中的一个部分
a = (1, 2, 3, 4)
print(a[1:3])
打印:
(2, 3)
- 元组也同样可以使用
for循环等方式来进行遍历元素
a = (1, 2, 3, 4)
for elem in a:
print(elem)
打印:
1
2
3
4
- 可以使用
in来判定元素是否存在,使用index来查找元素的下标
a = (1, 2, 3, 4)
print(3 in a)
print(a.index(3))
打印:
True
2
- 可以使用
+来拼接两个元组(本质上是创建一个新的大元组)
a = (1, 2, 3, 4)
b = (5, 6, 7, 8)
print(a + b)
打印:
(1, 2, 3, 4, 5, 6, 7, 8)
元组不能修改里面的元素, 列表则可以修改里面的元素
因此, 像读操作,比如访问下标, 切片, 遍历, in, index, + 等, 元组也是一样支持的。
但是, 像写操作, 比如修改元素, 新增元素, 删除元素, extend 等, 元组则不能支持。
另外, 元组在 Python 中很多时候是默认的集合类型。
- 当进行多元函数赋值的时候,其实本质上就是按照元组的方式来进行工作的 。
例如, 当一个函数返回多个值的时候:
def getPoint():
return 10, 20
result = getPoint() # 定义result本质上就是创建一个元组
print(type(result))
打印:
<class 'tuple'>
此处的 result 的类型tuple, 其实是元组。
问题来了, 既然已经有了列表, 为啥还需要有元组?
元组相比于列表来说, 优势有两方面:
你有一个列表, 现在需要调用一个函数进行一些处理。但是你有不是特别确认这个函数是否会把你的列表数据弄乱。那么这时候传一个元组就安全很多。
元组不能被修改->不可变对象。而不可变对象是可以哈希的。
马上要讲的字典, 是一个键值对结构。要求字典的键必须是 “可
hash对象” (字典本质上也是一个hash表)。而一个可
hash对象的前提就是不可变,因此元组可以作为字典的键, 但是列表不行。