原文
他人的间接经验 -> 自己的直接经验
调度模块在很多系统中都是常用的模块,比如实习生的每天签到邮件,预约银行的业务短信,学习通的上课通知,腾讯视频push中台的任务下发,调度系统在中间起到关键作用。
用户画像:圈一群人
业务场景:短信验证码、优惠券等营销活动消息通知短信、预约银行的业务短信、团课预约上课通知、推荐内容、app里的通知、消息箱、私信
端触达:短信、微信的服务通知、app的通知与消息箱、手机消息通道
用户:用户实操行为、感兴趣的那群人
什么是调度?
本质就是通过一些自定义策略,定时或者周期性的去触发某些事件,和下游进行一次通信。
通用流程
调度行为可以抽象成以下几步:
1.任务生成。
2.任务存储。
3.任务触发。
4.路由实例。
如果能做好这几步,那么一个高性能的调度系统也就诞生了,而每一步的技术选型,都和未来系统想要达成的目标(高精度,高可用),有着密不可分的关系,下面我会针对这几步进行分析。
任务生成
1.单次任务生成:
2.周期性任务生成:周期性任务生成类似于打点计时器。每当任务触发时,系统会计算出未来需要触发的任务时间列表。例如,对于每小时执行的任务,系统会在第二天生成24个整点任务。
3.推送系统任务生成:对于推送系统任务,系统会根据用户过去的行为画像预测其最有可能点击的时间区间。在第二天到来之前,系统会预先计算并生成第二天各个时间点的推送任务。
任务存储
任务存储的思考分为两个方面,第一是用什么数据结构存,第二是用什么类型的db去存。
对于高性能调度系统而言,主要看重范围查询效率,查询的qps,分布式锁的表现。
小总结
对于扫表+触发的模式,其实本质是需要一个能高速范围查询的数据结构。
B+树和跳表都是高效的能范围查询数据结构,但它们各自适用于不同的场景。B+树更适合于磁盘存储和范围查询,而跳表则更适合于内存中的快速查找和分布式环境。
数据库分析
我们举出基于内存的数据库的代表Redis和基于磁盘的数据库MySQL进行分析。
Redis VS MySQL
1.Redis的底层是跳表,而MySQL的底层是B+树。就范围查询而言,两者不分伯仲。
2.但Redis没有事务概念,内部实现是单线程,没有锁竞争,再加上IO多路复用的特性和极其高效的数据结构实现,就注定单机qps要远超过mysql。
3.mysql在这个场景下的优势则是有持久化能力,不容易丢数据,redis可能在RDB和AOF的过程中有丢数据的可能性。
因此,mysql和redis都有可能是作为存储任务的数据库,需要区分场景。
分布式锁的分析
在集群模式下,哪一台实例去执行任务扫描这一过程依赖于分布式锁的抢占。
基于MySQL实现
基于Redis实现
总的而言,mysql的分布式锁实现简单,但性能低。redis实现稍微复杂,性能高,一般用redis的多一点。
任务触发
在构建高效、可靠的分布式任务调度系统时,我们需要考虑多个方面,触发包括定时扫描、状态更新、任务重试等关键环节。
定时扫描
触发的本质就是将数据从db加载进内存中,那么我们可以通过定时任务,按照一定时间间隔去加载。那么
1.谁来扫描?
2.扫描的时间间隔多少合理?
谁来扫描?
负责扫描的实例需将扫描到的任务进行下发,即发起RPC调用。
扫描的时间间隔多少合理?
扫描时间间隔的设定对于确保系统性能和精度至关重要。这个间隔应当基于系统所需的实时精度以及单次扫描所生成的任务数量来合理确定。盲目降低扫描时间间隔并不总是能提高精度;相反,它可能会导致效率降低,甚至增加数据延迟。
因此,在确定扫描时间间隔时,应考虑以下两点:
1.对于精度要求不高且任务量较大的场景:可以适当延长扫描时间间隔,以确保在单次扫描周期内能够完成所有任务的处理下发。这样可以减轻系统负担,提高整体效率。
2.对于精度要求高同时任务量也很大的场景:除了优化RPC处理流程外,还可以考虑改进数据存储结构,将数据分片分桶处理。通过为每个数据分片分配独立的扫描实例,可以实现并行处理,从而在保证高精度的同时提升系统响应速度。
综上所述,合理的扫描时间间隔应当根据具体应用场景和系统需求进行细致调整,以达到最佳的性能和精度平衡点。
状态更新
为了让我们的系统展现出卓越的性能和高精度,我们采用了异步方式来下发任务。异步处理的明显优势在于它能够使任务并发执行,无需等待响应,从而显著提升了系统的信息处理能力。然而,这也带来了一个问题:我们无法确切知道下游系统是否真正收到了任务。即便上游系统竭尽全力发送任务,如果下游系统接收不到,这些努力也将化为泡影。
因此,我们需要下游系统在成功接收到信息后,主动发送一个确认信号(ACK)。一旦系统接收到这个ACK,我们就能记录下触发时间和执行时间等相关信息,以便后续的任务重试模块进行相应的处理。
考虑到任务是并发下发的,返回的信息量可能会非常庞大,每条返回信息都可能触发一次远程过程调用(RPC),这无疑会大量消耗连接资源。为了解决这个问题,我们引入了队列机制。
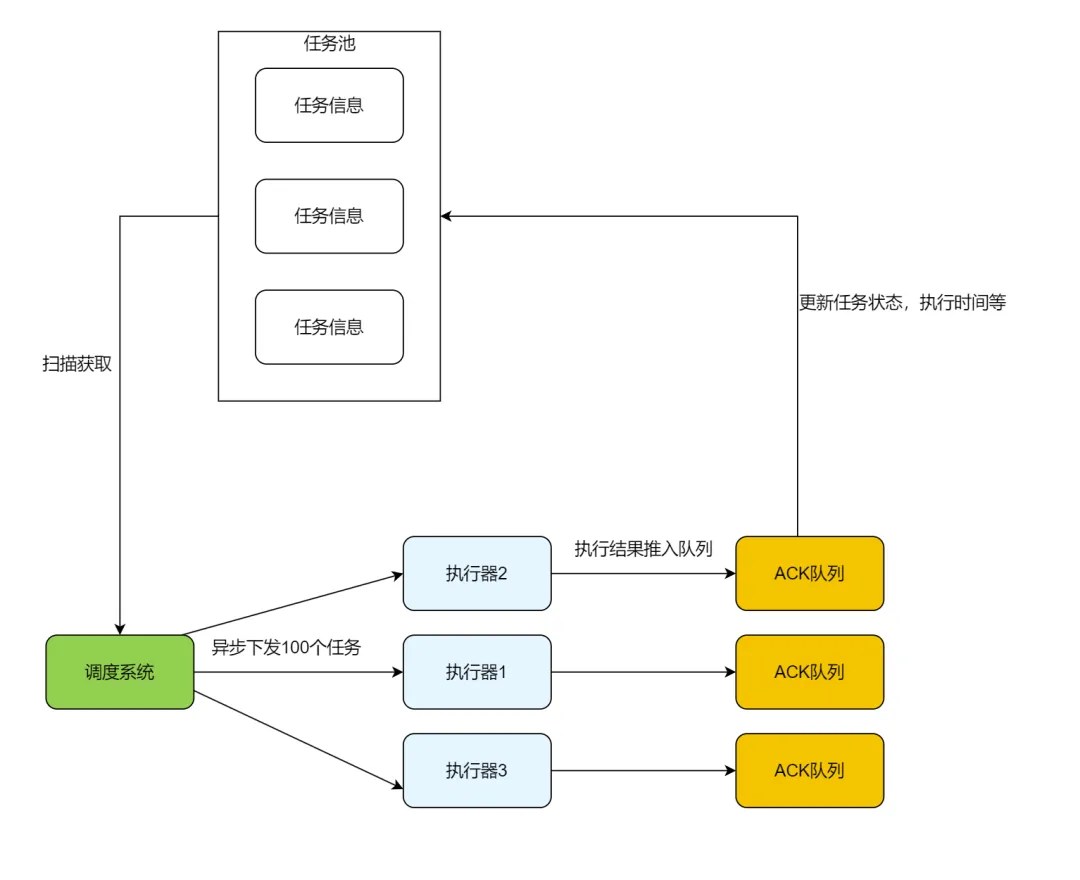
通过这种方式,我们成功地实现了连接复用和即时响应的双重效果,这也是一个写聚合的思想。
这种思想源于Kafka提供的Micro-Batch的概念,他会将相同Topic和Partition的消息聚合成一个批次,然后一次性发送到Kafka集群。
任务重试
上文我们分析了如何让海量任务下发,但仍然做不到能让调度系统拥有可靠性。在分布式环境下,服务器可能因为网络延迟,服务器故障,资源竞争等原因,任务执行可能会失败。那么如何处理这些失败的任务呢?
其实这个问题可以拆解成几个小任务:
1. 如何检测到失败的任务?
2. 如何定义一个失败的任务?
3. 检测到失败任务以后的重试策略?
重试策略分为重试次数和重试间隔。
每次重试完成,我们需要去更新这个已经重试次数,并检测他是否等于最大重试次数,之所有有这个最大重试次数,是为了防止他无限重试,造成重试风暴,而超过这个最大重试次数的,我们可以把它塞入死信队列中,让负责这个任务的人手动的去处理。
路由实例
优秀系统的设计
xxl-job的实现
内存中的时间轮算法+MySQL
XXL-JOB是一款知名的分布式任务调度框架,它采用内存中的时间轮算法结合MySQL作为持久化存储来管理调度任务,其调度粒度精准至秒级。
时间轮分为单级时间轮和多级时间轮。xxl-job并没有像kafka那样采用多级时间轮,主要是因为设计理念的不同,他为了简化设计,并且单级时间轮已经满足大部分任务调度的需求。
总体而言,XXL-JOB采用内存结合MySQL的部署方式简单易行,无需额外引入中间件。这种设计在追求调度精度的同时牺牲了一定的水平扩展性。对于任务量适中的场景而言,它仍然是一个值得考虑的优秀调度框架选项。
腾讯视频push中台的实现
腾讯视频push中台为了应对海量的并发,牺牲了调度的精度,以redis作为db,ZSet(跳表)作为底层数据结构来支持任务的范围查询。
Redis的高精度版本实现
分治思想:分片分桶,与多级时间轮类似拆分思想,分而治之,HashMap、LongAddr也使用类似思想。
调度的精度:若使用MQ的延时消息和并发消费,是否也是一种可行的方案?如Kafka、RocketMQ、Pulsar
分片
为了实现更高精度的Redis调度,我们需要确保跳表中的数据量保持在合理范围内。过多的数据可能导致内存占用过高、成本不足以及读写响应时间变长等问题(大Key问题)。因此,为了降低Redis访问的响应时间(即提高精度),我们对数据进行分片处理,使调度器每次只需扫描一个分片的数据。
如下图:

我们可以把一天的数据分为多个分钟级别的数据,虽然搜索的时间复杂度仍为O(logN),但由于N大大减小,搜索效率得到提高,响应速度更快。
然而,这仍然无法解决一个问题:如果某个实例通过抢锁方式获得某一分钟分片的扫描权限,但该分钟内的数据量仍然很大,可能会导致实例的线程数不足,无法实现并发处理。
分桶
为了解决这个问题,我们可以采用分桶策略,将这一分钟的数据划分为多个bucket。
在集群模式的调度器下,每个实例竞争的是各个bucket的锁,获得锁后,只需扫描相应分桶的数据。这种方法可以实现每分钟级别的tasklist调度,多台机器可以同时扫描和下发,避免了单个实例线程不足的问题。
如下图:
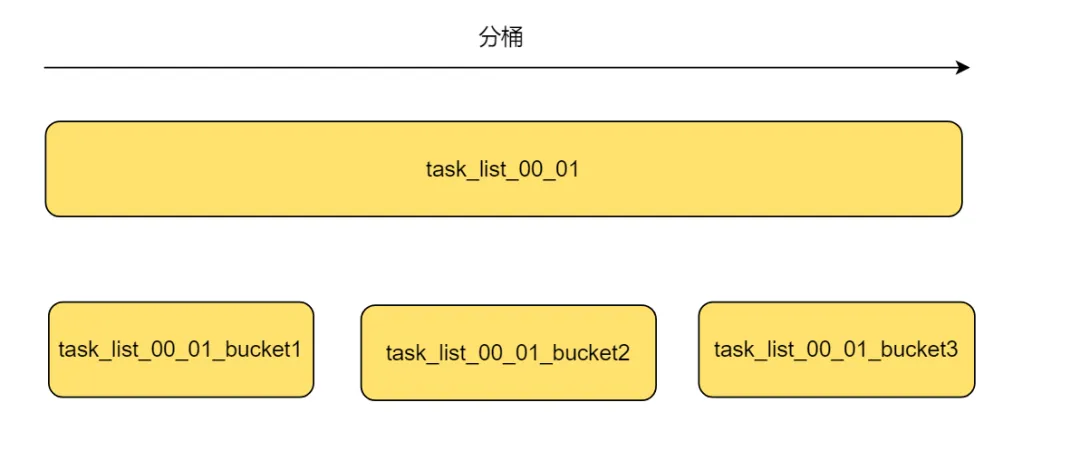
若即使分成三个桶,数据量仍然过大,我们可以引入一个决策服务来监控任务的延时情况。如果任务的延时率持续较高,可以根据实际情况动态调整分桶数量,从而更好地满足实际需求。
总结
本文详细探讨了调度模块在多种系统中的应用及其重要性,并深入分析了调度系统的通用流程,包括任务生成、任务存储、定时扫描和路由实例等关键步骤。
文章针对每个步骤的技术选型进行了探讨,并结合实际系统(如XXL-JOB和腾讯视频push中台)进行了案例分析。此外,还讨论了各种路由算法的实现及其适用场景。
总的来说,一个高性能的调度系统需要综合考虑任务生成策略、存储数据结构的选择、数据库选型、分布式锁的实现以及定时扫描的机制等多个方面。通过合理的技术选型和系统设计,可以实现高精度和高可用的调度目标。同时,根据具体的应用场景和需求,灵活调整调度策略和路由算法,以达到最佳的性能和效率平衡点。